Last updated on January 16th, 2026 at 03:00 pm
Data Warehouse và các hệ thông OLAP được xây dựng theo mô hình dữ liệu đa chiều (multi-dimensional model)
Mục lục
Kiến trúc khối (cube) OLAP
Dữ liệu trong kho dữ liệu được thể hiện dưới dạng đa chiều (Multi Dimension) gọi là khối (cube). Mỗi chiều mô tả một đặc trưng nào đó của dữ liệu. (Nếu số chiều dữ liệu lớn hơn 3, gọi là Hyper Cube)

1. Chiều (Dimension) và Độ đo (Measure)
- Dimension: cung cấp các thông tin, ngữ cảnh cho bảng fact (Muốn truy cập số liệu data warehouse đều phải thông qua chúng).
- Quy mô nhỏ hơn Fact.
- Các dạng lưu trữ bảng dimension (Dim Types):
- Type 0: Retain Original
- Type 1: Overwrite
- Type 2: Add new row
- Type 3: Add new attribute
- Type 4: Add history table
- Type 6: Hybrid
- Measure: Là đại lượng có thể tính toán được trên các thuộc tính của fact table.
- Đây là mục tiêu của OLAP và phải xác định trước khi tiến hành phân tích.
- Ví dụ như tổng tiền bán hàng của một chi nhánh, doanh thu của từng mặt hàng theo quí,…
Ví dụ: với Data Cube bán hàng thì chiều hàng hóa (Product) mô tả chi tiết về hàng hóa, chiều thời gian (time) mô tả về thời gian bán hàng, và các độ đo (Số lượng, Doanh thu,…)

2. Cây phân cấp và số liệu tổng hợp
Mức độ chi tiết của các tiêu chí thể hiện cho người dùng được gọi là mức dữ liệu (data granularity), được quyết định bằng việc kết hợp các mức dữ liệu của từng cắt lớp.

Ví dụ: Người dùng có thể lựa chọn mức độ chi tiết của số liệu:
- Chiều hàng hoá(Product), có các mức: sản phẩm, loại sản phẩm, công nghiệp
- Chiều thị trường, có các mức: khu vực, quốc gia, thành phố, địa điểm
- Chiều thời gian, có các mức: năm, quý, tháng, tuần, ngày
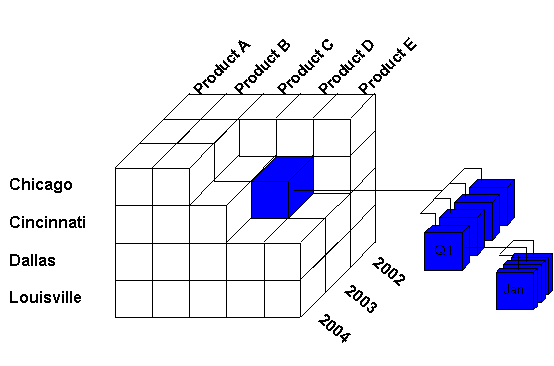
Số liệu tổng hợp: Việc tổng hợp số liệu xảy ra khi người dùng thay đổi mức chi tiết của dữ liệu lấy ra từ cube, bằng cách duyệt qua cây phân cấp của cắt lớp.
Ví dụ: Nếu cắt lớp Thời gian sử dụng ở mức quý thay vì mức ngày thì doanh số của quý sẽ được tổng hợp bằng phép cộng. Tương tự, dữ liệu ở mức Tất cả được tổng hợp bằng giá trị dữ liệu của tất cả các ngày.
Các qui luật tổng hợp số liệu, xem ở đây.
Mô hình thiết kế DW
1. OLAP kiểu quan hệ (Relational OLAP ~ ROLAP)
- Lưu trữ dữ liệu trong cơ sở dữ liệu quan hệ (theo mô hình dữ liệu quan hệ)
- Dùng câu lệnh SQL để thực hiện các tính năng của OLAP
2. OLAP kiểu đa chiều (Multi-dimensional OLAP ~ MOLAP)
- Lưu trữ dữ liệu dưới dạng file có cấu trúc đặc thù (mảng,…)
- Thực hiện các tính năng OLAP trên cấu trúc này
3. OLAP lai (Hybird OLAP ~ HOLAP = ROLAP + MOLAP)
- Tận dụng khả năng lưu trữ của OLAP và khả năng xử lý của MOLAP.
- Ví dụ:
- Lưu dữ liệu chi tiết (details data) trên CSDL quan hệ.
- Dữ liệu tổng hợp được lưu trên không gian MOLAP
| ROLAP | MOLAP | HOLAP | |
|---|---|---|---|
| Lữu trữ dữ liệu cơ sở | Bảng quan hệ | Khối | Bảng quan hệ |
| Lưu trữ dữ liệu tổng hợp | Bảng quan hệ | Khối | Khối |
| Hiệu suất truy vấn | Chậm | Nhanh | Trung bình |
| Không gian lữu trữ | Nhỏ | Lớn | Trung bình |
| Chi phí bảo trì | Thấp | Cao | Trung bình |
Các dạng lược đồ dữ liệu đa chiều
1. Lược đồ hình sao (Star Schema)
Bao gồm:
- Bảng sự kiện (fact): theo dõi biến động dữ liệu
- Các bảng chiều (dimension): mô tả các đặc trưng các chiều như thời gian, hàng hoá,…

- Khoá thay thế (Surrogate Key – SK):
- Là khoá chính bảng chiều(dimension) thường có giá trị là kiểu số.
- Thường được hệ thống DW sinh ra (duy nhất) bằng các luồng ETL
- Được sử dụng trong nội DW.
- Khoá tự nhiên (Natural Key – NK):
- Là khoá chính của dữ liệu trong các hệ thống nghiệp vụ.

2. Lược đồ bông tuyết (Snowflake Schema)
- Giảm dư thừa dữ liệu bằng cách chuẩn hoá các bảng dimension.
- Một thực thể dimension có phân cấp >> được phân thành nhiều bảng dữ liệu khác nhau (mỗi bảng một cấp).

3. Lược đồ ánh sao (Starflake Schema)
- Là sự kết hợp giữa lược đồ hình sao và bông tuyết.
- Một số dimension được chuẩn hoá, một số khác thì không.
- Phân cấp của Star Schema được denormalize,
- Phân cấp của Snowflake Schema được chuẩn hoá (normalize).

- Lược đồ ánh sao được chuẩn hoá để xoá bỏ dư thừa trong các bảng chiều. Các phân cấp chiều dùng chung được đặt trong outriggers.

4. Lược đồ chòm sao (Constellation Schema)
- Các bảng fact dùng chung dimension với nhau

Đánh giá:
- Với lược đồ hình sao, phép JOINS được giảm thiều, Thao tác QUERY nhanh hơn, nhưng kích thước bảng Fact lớn
- Với lược đồ bông tuyết, dữ liệu phân tán, dễ dàng lấy dữ liệu fact-less. Nhiều phép JOINS, thao tác QUERY chậm hơn.
Lược đồ hình sao tốt hơn, nhưng trong thực tế rất khó để xây dựng ứng dụng với Star Schema.
Xu hướng mới về mô hình dữ liệu đa chiều trong Data Warehouse (2025–2026)
Trong nhiều năm qua, mô hình dữ liệu đa chiều – với các khái niệm như star schema, snowflake schema và các khối OLAP – vẫn là nền tảng giúp thiết kế kho dữ liệu phục vụ phân tích. Tuy nhiên, đến giai đoạn 2025–2026, một số xu hướng đáng chú ý trong thực tế triển khai đã và đang định hình lại cách các tổ chức tiếp cận mô hình này.
1. Mở rộng mô hình đa chiều vào kiến trúc Cloud & Lakehouse
Trong kiến trúc cloud data warehouse và lakehouse, dữ liệu phi cấu trúc và bán cấu trúc ngày càng được lưu trữ chung với dữ liệu phân tích. Điều này dẫn tới việc mô hình dữ liệu đa chiều không còn chỉ giới hạn trong các hệ thống OLAP truyền thống mà được tích hợp với:
- Các bảng theo kiểu schema-on-read thay vì schema-on-write
- Hỗ trợ truy vấn JSON/VARIANT trực tiếp trong data warehouse
Điều này phản ánh cách Data Warehouse hiện đại đang kết hợp giữa quy trình phân tích đa chiều và tính linh hoạt của dữ liệu đám mây, thay vì chỉ xây dựng theo cấu trúc cứng nhắc như trước.
2. Tích hợp với pipeline ELT và công cụ hiện đại
Các công cụ như dbt (Data Build Tool) ngày càng được dùng để xây dựng các lớp dữ liệu và chuyển đổi (transform) trực tiếp trong kho dữ liệu, trước khi mô hình dữ liệu đa chiều được áp dụng. Điều này dẫn tới cách suy nghĩ “data modeling không còn là bước cuối cùng duy nhất” mà là một phần của pipeline dữ liệu tổng thể:
- Raw → staging → transformed → dimensional model
Việc sử dụng dbt cho phép tổ chức dễ dàng tái hiện các cấu trúc star/snowflake một cách có kiểm soát hơn và theo dõi lịch sử thay đổi model một cách rõ ràng.
3. Tích hợp dữ liệu phi cấu trúc vào mô hình đa chiều
Ngày nay, nhu cầu phân tích không chỉ dừng ở dữ liệu định dạng bảng; dữ liệu sự kiện, log, JSON từ API hay IoT được tích hợp vào kho dữ liệu lớn. Một số mô hình đa chiều mới đã thử nghiệm tích hợp các thuộc tính bán cấu trúc làm dimension, kết hợp các kỹ thuật như bridge tables hoặc mô hình hybrid schema để:
- Giữ lại ngữ nghĩa của dữ liệu phi cấu trúc
- Vẫn cho phép tổng hợp và phân tích theo chiều
Điều này mở rộng phạm vi ứng dụng của mô hình đa chiều trong môi trường dữ liệu hiện đại.
4. Vẫn giữ nguyên giá trị phương pháp kinh điển
Mặc dù có nhiều biến thể trong kiến trúc dữ liệu hiện đại, cốt lõi của mô hình dữ liệu đa chiều (fact & dimension, hierarchies, granularity) vẫn giữ giá trị vững bền trong việc tổ chức dữ liệu để phân tích. Nhiều chuyên gia trong cộng đồng kỹ thuật vẫn khẳng định các nguyên lý của Ralph Kimball và đa chiều là nền tảng cần nắm vững trước khi mở rộng sang các mô hình phức tạp hơn.
INDA Academy tự hào là đơn vị tiên phong trong việc đào tạo phân tích dữ liệu và AI chuyên sâu, đặc biệt cho khối ngành Ngân hàng – Tài chính – Bảo hiểm tại Việt Nam. Sau hơn 12 năm “thực chiến” cùng những dòng chảy dữ liệu khổng lồ, chúng tôi đã xây dựng nên một hệ sinh thái đào tạo toàn diện, giúp hàng nghìn học viên chuyển mình từ người mới bắt đầu trở thành những chuyên gia lành nghề, sẵn sàng đáp ứng tiêu chuẩn khắt khe của các doanh nghiệp lớn.
Điểm khác biệt lớn nhất tại INDA chính là triết lý đào tạo dựa trên các dự án thực tế (Project-based) và lộ trình cá nhân hóa nhờ ứng dụng AI. Chúng tôi không chỉ dạy bạn cách sử dụng công cụ, mà còn truyền tải tư duy khai phá giá trị từ dữ liệu để đưa ra quyết định kinh doanh chính xác.
Tìm hiểu thêm về các khóa học TẠI ĐÂY:
Lộ trình đào tạo Data Engineer
Lộ trình đào tạo Data Analyst
Lộ trình đào tạo Tester
Khóa học Data Engineer nâng cao – Thực chiến 5 dự án doanh nghiệp
Khóa học Data Analyst nâng cao – Thực chiến 5 dự án doanh nghiệp