

Databricks là một nền tảng xử lý và phân tích dữ liệu trung tâm đơn giản, nhanh chóng, hợp tác dựa trên Apache Spark, được xây dựng trên hệ thống đám mây. Các thành phần Databricks cơ bản bao gồm: Cluster, Workplace, Notebook, Jobs, Libraries, Database and Tables
Dữ liệu được phân phối và xử lý song song trong bộ nhớ của nhiều nút trong một cụm vượt trội vì nó được hỗ trợ bởi Spark Execution Engine.
Nó hỗ trợ tất cả các trường hợp sử dụng Spark như máy học, thực thi chỉ dẫn, xử lý luồng, phân tích tiên tiến, vv. và tương tự như Spark, Databricks cũng hỗ trợ tất cả các ngôn ngữ như Scala, Python, SQL, R, hoặc Java.
Bài viết sẽ giúp bạn hiểu hơn về Databricks và các thành phần Databricks cơ bản bạn cần biêt. Đọc kĩ thông tin phía bên dưới!
Mục lục
Các thành phần Databricks cơ bản
1. Cluster
Đây là thành phần quan trọng nhất trong Database và Spark để thực thi dữ liệu ở một không gian nhanh hơn rất nhiều. Trong một cụm Spark, có hai loại nút, nút worker, các nút thực hiện nhiệm vụ xử lý dữ liệu.
Vì dữ liệu trong Spark được xử lý song song, việc có nhiều nút worker hơn có thể giúp xử lý nhanh hơn.
Và nút driver chịu trách nhiệm gửi yêu cầu, phân phối nhiệm vụ cho các nút worker và điều phối thực thi.
Có hai loại cụm bạn có thể tạo trong Databricks, một cụm tương tác cho phép nhiều người dùng khám phá và phân tích dữ liệu theo cách tương tác, và một cụm công việc được sử dụng để chạy các công việc nhanh chóng và tự động.
2. Workspace
Workspace là một trong các thành phần Databricks. Một workspace là một nơi bạn có thể quản lý tất cả dữ liệu hoặc tệp tin theo định dạng thư mục, có thể là các notebook, các thư viện khác nhau, bảng điều khiển trực quan, thử nghiệm ML, vv.
Bạn có thể xác định kiểm soát truy cập chi tiết trên tất cả các đối tượng này, cho phép người dùng sử dụng cùng một workspace, nhưng chỉ cung cấp hạn chế quyền truy cập cho họ.
Có nhiều tùy chọn quản lý phiên bản có sẵn trong workspace của DataBricks như GitHub, Bitbucket, Azure DevOps, vv.”
3. Notebook
Đây là một trong các thành phần Databricks. Notebook là công cụ cho phép bạn viết và clusthực thi mã. Hoặc nó có thể thực hiện các biến đổi dữ liệu khác nhau trên dữ liệu với các ngôn ngữ được hỗ trợ bởi Spark.
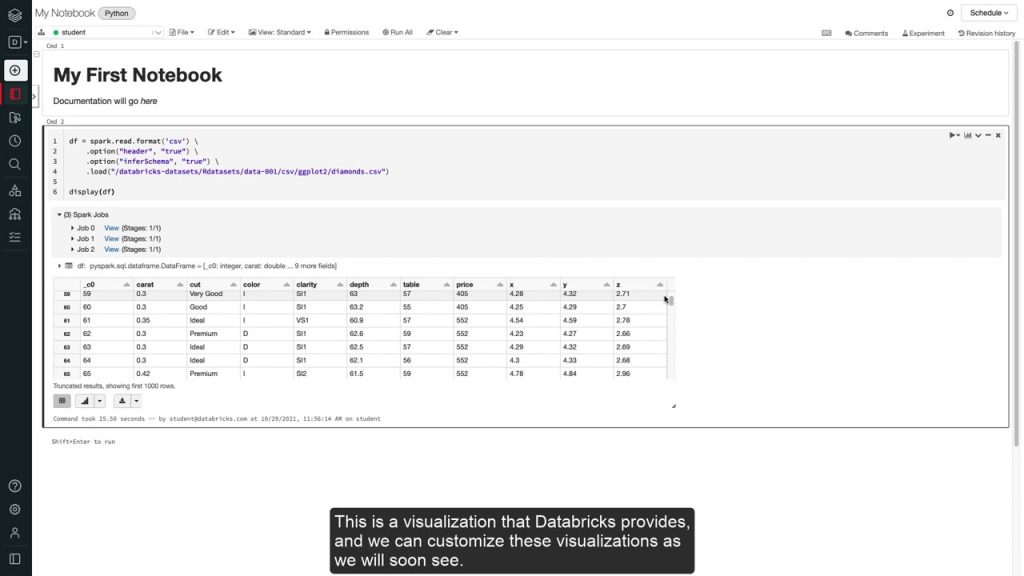
Trong notebook của DataBricks, bạn có thể viết mã bằng python, SQL, Scala, R, hoặc Java, trong cùng một notebook có thể viết mã bằng các ngôn ngữ khác nhau này trong cùng một notebook.
Vì vậy, bạn có thể viết logic biến đổi bằng python hoặc SQL và trích xuất dữ liệu bằng Scala, python trong cùng một notebook.
Bạn có thể xây dựng quy trình làm việc với dữ liệu bằng cách gọi các notebook với nhau. Điều này có thể giúp tạo ra quy trình làm việc từ đầu đến cuối. Bằng cách sử dụng một cụm tương tác, bạn có thể chạy các truy vấn hoặc chạy các notebook hoàn chỉnh bằng cách sử dụng các Job và notebook cũng hỗ trợ việc trực quan hóa tích hợp sẵn.
4. Jobs
Job cho phép thực thi một notebook. Nếu bạn có một tệp JAR bên ngoài mà bạn muốn thực thi trên một cụm Spark. Bạn có thể làm điều đó bằng cách sử dụng các Job.
Một công việc có thể chạy ngay lập tức hoặc có thể được lập lịch. Và như bạn đã biết, Job có thể chạy trên các cụm công việc (job clusters).
Các cụm công việc (job clusters) được tạo ra và kết thúc cùng với công việc, nhưng nếu bạn có một cụm tương tác đang chạy, bạn cũng có thể chạy các công việc này trên đó.
Mỗi công việc cũng có thể có một cấu hình cụm khác nhau để chạy. Điều này cho phép sử dụng một cụm nhỏ cho các công việc nhỏ hơn và một cụm lớn cho các công việc lớn hơn.
Và cuối cùng, bạn có thể hoàn toàn theo dõi việc chạy của công việc này, thử lại khi gặp lỗi và thiết lập cảnh báo để nhận thông báo. Chúng ta có thể thấy Jobs là một trong các thành phần Databricks quan trọng.
5. Libraries
Đôi khi bạn cần sử dụng các thư viện của bên thứ ba trong dự án dữ liệu của mình. Bạn có thể cài đặt các thư viện này trên cụm Spark và chúng có thể ở bất kỳ ngôn ngữ được hỗ trợ bởi Spark nào.
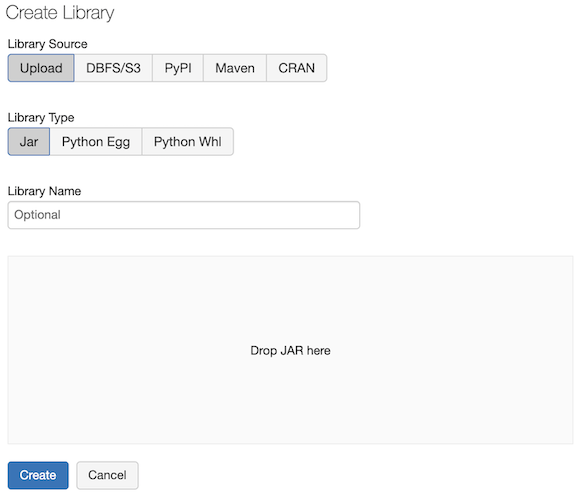
Sau khi cài đặt các thư viện trên cụm, bạn có thể sử dụng các thư viện này trong các notebook của bạn. Một thư viện có thể có phạm vi tại cấp cụm. Điều này có nghĩa là nó chỉ tồn tại trong ngữ cảnh của một cụm, hoặc bạn có thể cài đặt và xác định phạm vi của thư viện tại cấp notebook
6. Databases and tables
Databases và tables cũng là các thành phần Databricks. Nếu bạn có kinh nghiệm với cơ sở dữ liệu quan hệ, bạn sẽ thực sự thích thú khi thấy rằng bạn có thể tạo cơ sở dữ liệu và bảng trong các cơ sở dữ liệu này.
Cơ sở dữ liệu và bảng khác biệt so với cơ sở dữ liệu quan hệ. Một bảng trong Databricks đại diện cho một tập hợp dữ liệu có cấu trúc.
Điều này có nghĩa là bảng có một cấu trúc, nó có các cột và các cột có một kiểu dữ liệu. Bảng này tương đương với một DataFrame vì DataFrame cũng có một cấu trúc.
Điều này có nghĩa là bất kỳ hoạt động nào bạn có thể thực hiện trên DataFrame. Bạn cũng có thể làm tương tự trên một bảng. Một bảng được tạo bằng cách sử dụng tệp có sẵn trên lưu trữ.
Vì vậy, thực tế là nó chỉ là một biểu diễn của một tệp dưới lying mà bạn biết cấu trúc. Bất kỳ thay đổi nào trong tệp cũng sẽ ảnh hưởng đến bảng.
Các tính năng quan trọng của Databricks
Hợp tác
Khi làm việc với Databricks, bạn cũng nhận được một không gian làm việc với các người dùng khác nhau. Những người này thuộc các nhóm phân tích dữ liệu như kỹ sư dữ liệu, nhà khoa học dữ liệu và nhà phân tích kinh doanh.
Nnhững người này có thể làm việc cùng nhau ở đây và chia sẻ mã code, tập dữ liệu. Họ cùng khám phá, trực quan hóa thông tin, đăng bình luận và tích hợp với quản lý mã nguồn.
Quản lý Cơ sở hạ tầng
Ngoài tất cả các chức năng của Spark, Databricks mang đến nhiều tính năng quản lý hạ tầng. Đầu tiên một trong những điểm quan trọng nhất là quản lý cơ sở hạ tầng.
Vì Spark là một công cụ xử lý, để làm việc với nó, bạn cần thiết lập một cụm. Ngoài ra, bạn cần cài đặt Spark, xử lý khả năng mở rộng, lỗi phần cứng vật lý, nâng cấp và nhiều hơn nữa.
Nhưng với Databricks, bạn có thể khởi chạy một môi trường Spark tối ưu chỉ với vài cú nhấp chuột. Nó sẽ tự động mở rộng khi cần thiết.
Bảo mật tích hợp
Bảo mật là một phần quan trọng của bất kỳ công cụ liên quan đến dữ liệu nào. Databricks đi kèm với kiểm soát truy cập tích hợp và bảo mật cấp doanh nghiệp.
Nó tuân thủ các tiêu chuẩn bảo mật hệ thống cao. Mục đích để bạn có thể triển khai ứng dụng của mình một cách an toàn trên Databricks.
Tự động hóa các tác vụ
Tự động hóa, thực thi các tác vụ là yếu tố quan trọng trong bất kỳ tác vụ liên quan đến dữ liệu nào. Nguyên nhân là nó tránh lỗi của con người và tiết kiệm thời gian triển khai.
Sau khi hoàn thành quá trình khám phá dữ liệu và xây dựng đường ống dữ liệu, nó có thể tự động thực hiện kế hoạch thực thi.
Ngoài ra, bạn có thể đơn giản là thực hiện chúng dựa trên yêu cầu của bạn. Bạn có thể tự động thực thi theo lịch trình.

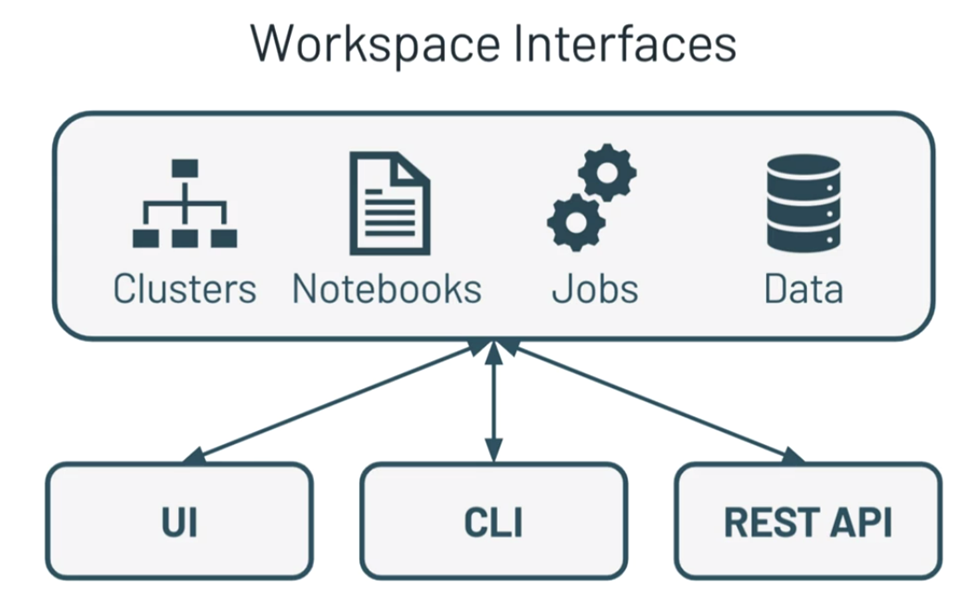
Không gian làm việc Databricks (Databricks Workspace)
Trong không gian làm việc Databricks, đã được tạo ra hai phần riêng biệt. Mục đích để xử lý không gian làm việc và sản xuất các công việc thực thi Spark.
Phần đầu tiên là không gian làm việc tương tác. Phần thứ hai là Databricks Production, hãy kiểm tra từng phần một cách chi tiết.
Không gian làm việc tương tác (Interactive workspace)
Trong môi trường này, bạn có thể tương tác khám phá và phân tích dữ liệu. Việc này giống như bạn mở một tệp Excel, áp dụng công thức và xem kết quả ngay lập tức.
Tương tự, bạn có thể thực hiện các phép tính phức tạp. Ngoài ra, bạn có thể xem kết quả một cách tương tác trong không gian làm việc. Bạn cũng có thể hiển thị và trực quan hóa dữ liệu dưới dạng biểu đồ.
Trong Databricks Workspace, bạn có một môi trường làm việc hợp tác. Nhiều người có thể viết mã trong cùng một notebook. Họ theo dõi các thay đổi của mã và đẩy chúng vào quản lý mã nguồn khi hoàn thành.
Và các tập dữ liệu mà bạn đã xử lý có thể được tổ chức trong một bảng điều khiển. Nó có thể dành cho người dùng cuối hoặc bảng điều khiển này cũng có thể được sử dụng để giám sát hệ thống. Bạn sẽ tìm hiểu về các thành phần cho phép các tính năng này chỉ trong một phút.
Databricks Production
Sau khi hoàn thành việc khám phá dữ liệu, bạn có thể xây dựng quy trình làm việc từ đầu đến cuối bằng cách sắp xếp các notebook.
Các quy trình làm việc này sau đó có thể triển khai như các công việc Spark. Chúng có thể được lập lịch sử dụng lịch công việc. Sau đó bạn có thể giám sát các công việc này, kiểm tra nhật ký và thiết lập cảnh báo.
Tương tự, trong cùng không gian làm việc, bạn không chỉ có thể tương tác khám phá dữ liệu. Bạn còn có thể chuyển nó vào môi trường sản xuất với rất ít công sức.
Kết luận
Databricks cung cấp dịch vụ thực thi dữ liệu trong một phiên bản tối ưu của Spark. Nó an toàn trên nền tảng đám mây.
Với sự trợ giúp của Databricks, bạn có thể tạo nhiều cụm. Tài nguyên của cụm được chia sẻ hiệu quả với nhiều người dùng và khối công việc khác nhau.
Nó kết nối hoặc tích hợp không gian làm việc và hoạt động của các kỹ sư dữ liệu, nhà khoa học dữ liệu, nhà phân tích, v.v. để tăng năng suất công việc.
Nguồn: Internet
>>Tìm hiểu thêm các khóa học tại đây!
Bài viết liên quan:
 Databricks Delta Live Tables – Áp dụng các phương pháp hay nhất về phát triển phần mềm & DevOps
Databricks Delta Live Tables – Áp dụng các phương pháp hay nhất về phát triển phần mềm & DevOps
 Azure Databricks – Ví dụ cụ thể về cơ chế xử lý linh động
Azure Databricks – Ví dụ cụ thể về cơ chế xử lý linh động
 Danh mục Unity (Unity Catalog) – Mô hình đặc quyền dữ liệu và kiểm soát truy cập
Danh mục Unity (Unity Catalog) – Mô hình đặc quyền dữ liệu và kiểm soát truy cập
 Databricks đã cải thiện hiệu suất truy vấn lên tới 2.2 lần bằng cách nào?
Databricks đã cải thiện hiệu suất truy vấn lên tới 2.2 lần bằng cách nào?
 Databricks Vs Snowflake
Databricks Vs Snowflake
 Triển khai Databricks
Triển khai Databricks