Các ứng dụng kinh doanh, tích hợp dữ liệu, quản lý dữ liệu chủ, lưu trữ dữ liệu, dữ liệu lớn, hồ dữ liệu và học máy – tất cả đều có (hoặc nên có) một thành phần phổ biến và thiết yếu: mô hình dữ liệu .
Mô hình dữ liệu là xương sống của hầu hết các giải pháp kinh doanh quan trọng, có giá trị cao – từ thương mại điện tử và điểm bán hàng đến quản lý tài chính, sản phẩm và quản lý khách hàng và tất cả các con đường thông qua kinh doanh và IoT. Nếu không có một mô hình dữ liệu phù hợp, dữ liệu kinh doanh ở đâu? Có lẽ đã mất!
Các mô hình dữ liệu và phương pháp mô hình hóa dữ liệu đã xuất hiện từ đầu thời gian (dù sao, kể từ khi bắt đầu tính toán, dù sao đi nữa). Dữ liệu cần cấu trúc để có ý nghĩa và cung cấp một cách để máy tính xử lý các bit và byte của nó. Chắc chắn, chúng tôi cũng đối phó với dữ liệu phi cấu trúc và bán cấu trúc, nhưng đối với tôi, điều này đơn giản có nghĩa là chúng tôi đã phát triển đến các mô hình phức tạp hơn so với người tiền nhiệm máy tính của chúng tôi phải đối phó. Do đó, mô hình dữ liệu vẫn duy trì và cung cấp cơ sở để chúng tôi xây dựng các ứng dụng kinh doanh tiên tiến.
Nhìn lại lịch sử mô hình hóa dữ liệu có thể khai sáng chúng tôi, vì vậy tôi đã thực hiện một số nghiên cứu để làm mới bản thân.
Mục lục
Bài học lịch sử tóm tắt về mô hình dữ liệu

Trong Thời đại điện toán tối, chúng tôi đã sử dụng bố cục / mảng bản ghi phẳng: tất cả dữ liệu được lưu vào băng hoặc ổ đĩa lớn để truy xuất tiếp theo. Tuy nhiên, vào năm 1958, JW Young và HK Kent đã mô tả các hệ thống thông tin mô hình hóa là một cách chính xác và trừu tượng để xác định các đặc điểm thông tin và thời gian của một vấn đề xử lý dữ liệu. Ngay sau đó, vào năm 1959, CODASYL (Hội nghị / Ủy ban về Ngôn ngữ hệ thống dữ liệu ) được thành lập bởi Viện Charles Babbage tại Đại học Minnesota, dẫn đến các ngôn ngữ lập trình tiêu chuẩn như COBOL và Kho dữ liệu tích hợp (IDS), một công nghệ cơ sở dữ liệu ban đầu được thiết kế vào những năm 1960 tại GE / Honeywell bởi Charles Bachman .

IDS tỏ ra khó sử dụng, do đó, nó đã phát triển để trở thành Hệ thống quản lý cơ sở dữ liệu tích hợp (IDMS) được phát triển tại BF Goodrich (một công ty hàng không vũ trụ của Mỹ vào thời điểm đó, vâng, công ty lốp xe mà chúng ta biết ngày nay) và được tiếp thị bởi Cullinane Database Systems (bây giờ thuộc sở hữu của Computer Associates). Hai phương pháp mô hình hóa dữ liệu này – được gọi là mô hình dữ liệu phân cấp và mô hình mạng dữ liệu tương ứng – đều rất phổ biến trên máy tính máy tính lớn trong 50 năm tới. Bạn vẫn có thể tìm thấy chúng được sử dụng ngày hôm nay!
Vào cuối những năm 1960, khi làm việc tại IBM, EF Codd phối hợp với CJ Date (tác giả của Giới thiệu về Hệ thống cơ sở dữ liệu ), đã ánh xạ các lý thuyết mô hình hóa dữ liệu sáng tạo của Codd dẫn đến Mô hình dữ liệu quan hệ cho ấn phẩm Ngân hàng dữ liệu chia sẻ lớn vào năm 1970. Codd chiến dịch để đảm bảo các nhà cung cấp thực hiện phương pháp luận đã xuất bản đúng 12 Quy tắc mô hình quan hệ nổi tiếng của ông vào năm 1985. Trên thực tế, mười ba quy tắc được đánh số từ 0 đến 12; Codd rõ ràng là một người đam mê máy tính trong ngày của anh ấy. 
Mô hình quan hệ cũng đưa ra khái niệm chuẩn hóa với định nghĩa Năm hình thức bình thường. Nhiều người trong chúng ta nói về 3NF (Mẫu thường thứ ba), nhưng bạn có biết cách định nghĩa nó không?
Phương pháp mô hình hóa dữ liệu quan trọng tiếp theo xuất hiện vào năm 1996, được đề xuất bởi Ralph Kimball (đã nghỉ hưu) trong cuốn sách đột phá của ông, đồng tác giả bởi Margy Ross, Bộ công cụ kho dữ liệu: Hướng dẫn hoàn chỉnh về mô hình hóa chiều . Mô hình dữ liệu lược đồ sao

được áp dụng rộng rãi của Kimball được áp dụng trong mô hình kho dữ liệu được đề xuất lần đầu tiên vào những năm 1970 bởi WH (Bill) Inmon (được đặt tên vào năm 2007 bởi Computerworld là một trong mười người có ảnh hưởng nhất trong 40 năm đầu tiên trong điện toán). Xây dựng kho dữ liệu của Inmon, được xuất bản vào năm 1991, đã trở thành tiêu chuẩn defacto cho tất cả các tính toán kho dữ liệu. Mặc dù đã có một số lịch sử bất đồng giữa Inmon và Kimball về cách tiếp cận đúng đắn đối với việc triển khai kho dữ liệu, Margy Ross của Kimball Group đưa ra một lời giải thích công bằng và cân bằng cho sự cân nhắc xứng đáng của bạn trong bài viết Khác biệt về ý kiến của cô .

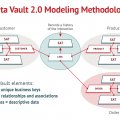
Gần đây, một phương pháp mô hình hóa dữ liệu mới đã nổi lên như một ứng cử viên mạnh mẽ: kho dữ liệu ! Tác giả và nhà phát minh của nó, Dan Linsdedt , lần đầu tiên đã hình thành kho dữ liệu vào năm 1990 và phát hành một ấn phẩm cho miền công cộng vào năm 2001. Mô hình kho dữ liệu giải quyết nhiều đối số Inmon và Kimball cạnh tranh, kết hợp dòng dữ liệu lịch sử và cung cấp khả năng thích ứng cao, mô hình có thể nghe được, và có thể mở rộng. Tôi mời bạn đọc bài viết của tôi, Cái gì là Vault dữ liệu và tại sao chúng ta cần nó? Kho dữ liệu của Linstedt tỏ ra vô giá đối với một số dự án quan trọng của DOD, NSA và Corporate. Năm 2013, Linsdedt đã phát hành Data Vault 2.0giải quyết vấn đề Big Data, NoQuery, không cấu trúc, tích hợp dữ liệu bán cấu trúc cùng với các thực tiễn tốt nhất về SDLC về cách sử dụng nó. Thời gian hoàn hảo, tôi muốn nói. Vì thế chúng ta ở đây…
Tóm tắt mô hình dữ liệu
Tóm tắt nhanh về các phương pháp mô hình hóa dữ liệu khác nhau:
- Mô hình phẳng : Một mảng hai chiều của các phần tử dữ liệu.
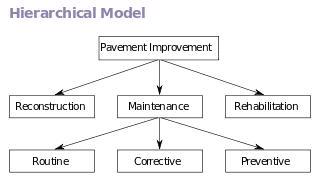
- Mô hình phân cấp : Bản ghi chứa các trường và bộ xác định phân cấp cha / con.
- Mô hình mạng : Tương tự như mô hình phân cấp cho phép các mối quan hệ một-nhiều bằng cách sử dụng ánh xạ bảng ‘liên kết’.
- Mô hình quan hệ : Tập hợp các biến vị ngữ qua một tập hợp hữu hạn các biến vị ngữ được xác định bằng các ràng buộc về các giá trị có thể và kết hợp các giá trị.
- Mô hình lược đồ sao : Bảng thực tế và kích thước được chuẩn hóa loại bỏ các thuộc tính cardinality thấp cho các tập hợp dữ liệu.
- Mô hình kho dữ liệu : Ghi lại dữ liệu lịch sử dài hạn từ nhiều nguồn dữ liệu bằng cách sử dụng bảng trung tâm, vệ tinh và liên kết.
Vòng đời phát triển cơ sở dữ liệu: DDLC
Cuộc đối thoại ngày nay dường như tập trung hoàn toàn vào sự phức tạp và khối lượng dữ liệu tuyệt đối. Quan trọng, chắc chắn, nhưng một lần nữa tôi muốn nhắc bạn rằng mô hình dữ liệu nên là một phần quan trọng của cuộc thảo luận. Khi các yêu cầu phát triển, lược đồ (một mô hình dữ liệu) phải tuân theo – hoặc thậm chí dẫn đường. Bất kể, nó cần phải được quản lý. Vì vậy, tôi trình bày cho bạn Vòng đời phát triển cơ sở dữ liệu!
Đối với mọi môi trường có dữ liệu liên quan, các nhà phát triển cần điều chỉnh và điều chỉnh mã phù hợp với đột biến cấu trúc không thể tránh khỏi của nó. Tương tự như Vòng đời phát triển phần mềm (SDLC), cơ sở dữ liệu cần nắm lấy thiết kế mô hình dữ liệu phù hợp và thực tiễn tốt nhất. Trong số nhiều mô hình dữ liệu mà tôi đã thiết kế, các giới luật rõ ràng đã xuất hiện, bao gồm:
- Khả năng thích ứng : Tạo các lược đồ chịu được sự tăng cường hoặc hiệu chỉnh.
- Khả năng mở rộng : Tạo các lược đồ phát triển ngoài mong đợi.
- Nguyên tắc cơ bản : Tạo các lược đồ cung cấp các tính năng và chức năng.
- Tính di động : Tạo các lược đồ có thể được lưu trữ trên các hệ thống khác nhau.
- Khai thác : Tạo các lược đồ tối đa hóa công nghệ máy chủ.
- Lưu trữ hiệu quả : Tạo dấu chân đĩa lược đồ tối ưu hóa.
- Hiệu suất cao : Tạo các lược đồ tối ưu hóa vượt trội.
Những giới luật thiết kế này kết hợp bản chất của bất kỳ phương pháp mô hình hóa được chọn nào – một số mâu thuẫn với những người khác. Theo kinh nghiệm của tôi, bất kể những sự phân đôi này, một mô hình dữ liệu chỉ có ba giai đoạn của cuộc đời:
- Cài đặt mới : Dựa trên phiên bản hiện tại của lược đồ.
- Áp dụng nâng cấp : Thả / tạo / thay đổi các đối tượng cơ sở dữ liệu nâng cấp một phiên bản lên phiên bản tiếp theo.
- Di chuyển dữ liệu : Trường hợp nâng cấp đột phá xảy ra (như chia bảng hoặc nền tảng).
Thiết kế mô hình dữ liệu có thể là một công sức của tình yêu kéo theo cả sự chú ý tẻ nhạt đến chi tiết được tôi luyện với sự trừu tượng sáng tạo của sự mơ hồ. Cá nhân bị lôi cuốn vào các lược đồ đầy thách thức, tôi tìm kiếm các vết nứt và kẽ hở để sửa, thường xuất hiện theo nhiều cách khác nhau. Ví dụ:
- Khóa chính tổng hợp : Tránh chúng, hiếm khi hiệu quả hoặc phù hợp; có một số trường hợp ngoại lệ tùy thuộc vào mô hình dữ liệu
- Khóa chính xấu : Thông thường datetime và / hoặc chuỗi (ngoại trừ GUID hoặc Hash) không phù hợp
- Lập chỉ mục xấu : Hoặc quá ít hoặc quá nhiều.
- Kiểu dữ liệu cột : Khi bạn chỉ cần một Số nguyên không sử dụng Số dài (hoặc Số nguyên lớn), đặc biệt là trên khóa chính.
- Phân bổ lưu trữ : Không liên quan đến kích thước dữ liệu và tiềm năng tăng trưởng
- Tham chiếu tròn : Trường hợp bảng A có mối quan hệ với bảng B, bảng B có mối quan hệ với bảng C và bảng C có mối quan hệ với bảng A; Đây đơn giản là thiết kế tồi.
Sau đó, hãy xem xét một thực tiễn tốt nhất về thiết kế cơ sở dữ liệu: Quá trình thiết kế và phát hành mô hình dữ liệu. Tôi tin rằng khi chế tạo một mô hình dữ liệu, người ta phải tuân theo một quy trình quy định tương tự như sau:

Tự giải thích cho hầu hết có lẽ, nhưng hãy để tôi nhấn mạnh tầm quan trọng của việc áp dụng quy trình này. Mặc dù các thay đổi lược đồ là không thể tránh khỏi, việc sớm có được một mô hình dữ liệu vững chắc trong bất kỳ dự án phát triển phần mềm nào là điều cần thiết. Chắc chắn giảm thiểu tác động đến mã ứng dụng là mong muốn để cung cấp các dự án phần mềm thành công. Thay đổi lược đồ có thể là một đề xuất đắt tiền vì vậy hiểu được vòng đời cơ sở dữ liệu và vai trò của nó trở nên rất quan trọng. Phiên bản mô hình cơ sở dữ liệu của bạn là rất quan trọng. Sử dụng sơ đồ đồ họa để minh họa các thiết kế. Tạo một từ điển dữ liệu hoặc bảng chú giải và theo dõi dòng dõi cho những thay đổi lịch sử. Đó là một kỷ luật cao hơn, nhưng nó hoạt động!
Phương pháp mô hình hóa dữ liệu
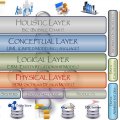
Hiểu lịch sử của mô hình dữ liệu và quy trình tốt nhất để thiết kế chúng chỉ là điểm khởi đầu. Là một kiến trúc sư cơ sở dữ liệu cho cả hai mô hình giao dịch (OLTP) và phân tích (OLAP) , tôi đã phát hiện ra rằng ba bước đầu tiên được minh họa ở trên đại diện cho khoảng 80% công việc. Hãy xem xét điều đó tiếp theo.
Đôi khi, các mô hình dữ liệu rất dễ dàng, thường là do sự đơn giản và / hoặc tầm vóc nhỏ. Các mô hình dữ liệu cũng có thể rất khó, thường là do sự phức tạp, đa dạng và / hoặc kích thước và hình dạng tuyệt đối của dữ liệu và nhiều nơi trong toàn doanh nghiệp nơi nó được sử dụng. Tôi tin rằng chúng ta nên hiểu càng sớm càng tốt toàn bộ dữ liệu là gì và ở đâu, nó bị ảnh hưởng như thế nào hoặc ảnh hưởng đến các ứng dụng và hệ thống sử dụng nó như thế nào và tại sao nó lại ở đó ngay từ đầu. Bắt đầu xung quanh những người cần những gì và làm thế nào để cung cấp nó là thách thức. Ánh xạ nó ra để đảm bảo Mô hình Dữ liệu vững chắc là mục tiêu. Chọn phương pháp mô hình hóa dữ liệu phù hợp là tối quan trọng.
Phần kết luận
Trong Phần 2 của loạt bài này, tôi sẽ minh họa và kiểm tra các khái niệm cơ bản và giá trị của mô hình dữ liệu logic và vật lý. Inda cũng sẽ đề xuất một bản mở rộng về cách chúng tôi phân biệt dữ liệu của mình: trước tiên, sau đó tách ra các chi tiết khái niệm, trước khi chúng tôi thậm chí thử thiết kế logic hoặc vật lý. Những điều này giúp chúng tôi hiểu rõ hơn về dữ liệu, mô hình hóa dữ liệu và xác thực mô hình thiết kế cơ sở dữ liệu của chúng tôi.