
Trong thời đại số hóa, quản lý và tích hợp dữ liệu đóng vai trò quan trọng trong việc duy trì lợi thế cạnh tranh của các doanh nghiệp. ETL (Extract, Transform, Load) là quy trình quan trọng giúp chuyển đổi dữ liệu thô thành thông tin có giá trị. Với nhiều công cụ ETL khác nhau, việc lựa chọn công cụ phù hợp với nhu cầu của doanh nghiệp trở nên cấp thiết.
Mục lục
Nhu cầu doanh nghiệp cần thiết của ETL

Việc lựa chọn các giải pháp tích hợp dữ liệu phù hợp với yêu cầu tổ chức đặc thù là rất quan trọng. Cách tiếp cận này đảm bảo rằng các công cụ ETL tốt nhất sẽ tương thích hoàn hảo với nhu cầu xử lý, chuyển đổi và lưu trữ dữ liệu của doanh nghiệp, tối ưu hóa hiệu suất và hiệu quả trong quản lý dữ liệu.
Tình huống sử dụng cụ thể của công cụ ETL
| Tình huống sử dụng | Nhu cầu kinh doanh | Yêu cầu công cụ ETL |
| Xử lý dữ liệu quy mô lớn | Quản lý lượng dữ liệu lớn hiệu quả | Các công cụ hiệu suất cao như Apache Spark hoặc Hadoop, giúp phân phối, xử lý và quản lý khối lượng dữ liệu lớn. |
| Tích hợp dữ liệu thời gian thực | Xử lý dữ liệu ngay lập tức để có thông tin chi tiết kịp thời | Các công cụ như Apache Kafka hoặc AWS Glue ETL cung cấp khả năng thu thập và phát trực tuyến dữ liệu theo thời gian thực. |
| Tích hợp dữ liệu dựa trên đám mây | Kết nối các ứng dụng và dịch vụ dựa trên đám mây | Các giải pháp ETL gốc đám mây như Google Cloud Dataflow hoặc Azure Data Factory được tối ưu hóa cho môi trường đám mây. |
| Chuyển đổi dữ liệu phức tạp | Biến đổi và chuyển đổi dữ liệu nâng cao | Các công cụ có tính năng chuyển đổi mạnh mẽ như Talend hoặc Informatica PowerCenter, hỗ trợ thao tác dữ liệu phức tạp. |
| Kho dữ liệu | Hợp nhất dữ liệu vào một kho lưu trữ trung tâm để phân tích | Các công cụ ETL có khả năng lưu kho dữ liệu mạnh mẽ như Oracle Data Integrator hoặc AWS Data Pipeline. |
Tối Ưu Hóa Công Cụ ETL Theo Mục Tiêu Kinh Doanh
Việc sắp xếp các chức năng cụ thể của các công cụ ETL với mục tiêu chiến lược và nhu cầu quản lý dữ liệu của doanh nghiệp là rất quan trọng. Quá trình này đòi hỏi đánh giá kỹ lưỡng các công cụ ETL khác nhau dựa trên các ưu tiên của tổ chức như tốc độ xử lý dữ liệu để phân tích thời gian thực, khả năng mở rộng để tăng khối lượng dữ liệu hoặc tích hợp cụ thể cho các nguồn dữ liệu duy nhất. Mục tiêu là chọn một giải pháp ETL đáp ứng nhu cầu xử lý dữ liệu hiện tại và hỗ trợ các mục tiêu kinh doanh tổng thể.
Để cải thiện quy trình ra quyết định, điều quan trọng là chọn các công cụ ETL tích hợp liền mạch với các nền tảng phân tích và Business Intelligence. Việc này tăng cường khả năng trực quan hóa và báo cáo dữ liệu, cho phép các doanh nghiệp thu thập thông tin chi tiết có thể hành động. Đồng thời, để quản lý ngân sách hiệu quả, lựa chọn các công cụ ETL mã nguồn mở hoặc có chi phí hợp lý như Talend Open Studio là một giải pháp khôn ngoan. Những công cụ này cung cấp các tính năng thiết yếu mà không quá tốn kém, phù hợp với các doanh nghiệp quan tâm đến chi tiêu.
Ngoài ra, việc chọn các giải pháp ETL có khả năng mở rộng là cần thiết để đáp ứng nhu cầu thích ứng với khối lượng dữ liệu ngày càng tăng. Các công cụ này có thể xử lý sự phức tạp dữ liệu tăng lên theo thời gian, đảm bảo quy trình ETL vẫn hiệu quả khi doanh nghiệp phát triển. Các công cụ có chất lượng dữ liệu mạnh mẽ, tính năng làm sạch và quản trị dữ liệu đảm bảo độ chính xác và tuân thủ các tiêu chuẩn quy định, rất quan trọng đối với dữ liệu nhạy cảm hoặc quan trọng. Công cụ ETL phù hợp không chỉ giải quyết các khía cạnh kỹ thuật của tích hợp dữ liệu mà còn phải phù hợp với các chiến lược và mục tiêu kinh doanh rộng lớn hơn.
Danh sách các công cụ ETL
Hadoop

Công cụ này chuyên xử lý các khối dữ liệu khổng lồ và giống như một thư viện đủ lớn để chứa tất cả các cuốn sách trên thế giới – đó chính là quy mô dữ liệu mà Hadoop có thể xử lý. Các công cụ ETL của Hadoop là những khung nền tảng cho phép xử lý phân tán các tập dữ liệu lớn trên nhiều máy tính, sử dụng các mô hình lập trình đơn giản. Thiết kế của Hadoop cho phép mở rộng từ một máy chủ đơn lẻ lên tới hàng nghìn máy, mỗi máy cung cấp khả năng tính toán và lưu trữ cục bộ.
Hadoop không phụ thuộc vào phần cứng để đảm bảo tính sẵn sàng cao, mà nó được thiết kế để phát hiện và xử lý lỗi ngay trong phần mềm điều này giúp hệ thống trở nên rất linh hoạt và chịu lỗi tốt. Một trong những điểm mạnh lớn của Hadoop là khả năng lưu trữ và phân tích dữ liệu ở bất kỳ định dạng nào, từ dữ liệu có cấu trúc như cơ sở dữ liệu đến dữ liệu phi cấu trúc như email hoặc video.
Lợi thế
Hadoop nổi bật với khả năng mở rộng và tính linh hoạt cao. Hệ thống này có thể xử lý khối lượng dữ liệu cực lớn, từ hàng trăm terabyte đến petabyte, làm cho nó trở thành giải pháp lý tưởng cho các doanh nghiệp cần xử lý dữ liệu khổng lồ. Việc mở rộng không gặp khó khăn với Hadoop; bạn có thể mở rộng từ một máy chủ đơn lẻ lên hàng nghìn máy mà không gặp phải các vấn đề lớn về hiệu suất.
Tốc độ xử lý của Hadoop cũng là một điểm mạnh đáng chú ý. So với các phương pháp ETL truyền thống, Hadoop cung cấp kết quả nhanh hơn, gần như theo thời gian thực và tùy thuộc vào độ phức tạp của dữ liệu và yêu cầu xử lý. Điều này đặc biệt hữu ích cho các ứng dụng yêu cầu phản hồi nhanh chóng và phân tích dữ liệu tức thì.
Ngoài ra, Hadoop là một khung mã nguồn mở, điều này giúp giảm đáng kể chi phí vận hành và bảo trì. Việc không phải chi trả cho các giấy phép phần mềm đắt đỏ làm cho Hadoop trở thành một lựa chọn hấp dẫn về mặt tài chính. Bản chất mã nguồn mở của Hadoop cũng có sự hỗ trợ từ cộng đồng lớn và năng động, đảm bảo rằng hệ thống luôn được cập nhật và cải thiện liên tục với các bản vá lỗi và nâng cấp bảo mật.
Hadoop còn có khả năng cải thiện hiệu suất kho dữ liệu. Hệ thống này giúp giảm chi phí lưu trữ và tăng tốc độ truy vấn dữ liệu, cho phép xử lý khối lượng dữ liệu lớn hơn trong thời gian ngắn hơn. Điều này không chỉ giúp tiết kiệm chi phí mà còn nâng cao hiệu quả tổng thể của các quy trình phân tích dữ liệu.
Thách thức
Mặc dù có nhiều ưu điểm, Hadoop cũng gặp phải một số thách thức. Dù ngày càng phổ biến, Hadoop vẫn chưa được áp dụng rộng rãi trong các quy trình ETL so với các phương pháp truyền thống. Việc triển khai và vận hành Hadoop đòi hỏi kiến thức chuyên sâu và kinh nghiệm thực tiễn, điều này có thể gây khó khăn cho các tổ chức chưa quen với công nghệ này.
Việc chuyển đổi từ các công cụ ETL truyền thống sang Hadoop cũng có thể gặp nhiều khó khăn. Quá trình này yêu cầu các doanh nghiệp phải thay đổi kỹ năng và tư duy kỹ thuật, điều này có thể gây trở ngại cho những tổ chức chưa sẵn sàng đầu tư vào đào tạo nhân viên hoặc thay đổi quy trình làm việc.
Hadoop hiện còn thiếu một số công cụ được thiết kế đặc biệt cho việc triển khai các quy trình ETL. Số lượng công cụ chuyên dụng cho Hadoop vẫn còn hạn chế, điều này có thể làm tăng mức độ phức tạp khi cố gắng tích hợp Hadoop với các hệ thống hiện có.
Đối với những bạn đã quen với các công cụ ETL dựa trên giao diện người dùng đồ họa (GUI) truyền thống thì việc làm quen với mô hình lập trình của Hadoop có thể là một thử thách. Và ngược lại, đối với những người chưa quen với các công nghệ này thì sẽ yêu cầu một thời gian và nỗ lực đáng kể để làm quen và thành thạo.
Giá cả
Hadoop là một framework mã nguồn mở, vì vậy không kèm theo chi phí trực tiếp. Tuy nhiên, tổng chi phí sử dụng Hadoop cho ETL bao gồm các phần cứng cần thiết để chạy các cụm, phí dịch vụ đám mây nếu sử dụng dịch vụ Hadoop dựa trên đám mây và bất kỳ công cụ hoặc dịch vụ hỗ trợ bổ sung nào cần thiết. Các chi phí này có thể thay đổi rất nhiều tùy thuộc vào quy mô và chi tiết cụ thể của việc triển khai.
Google Cloud Dataflow
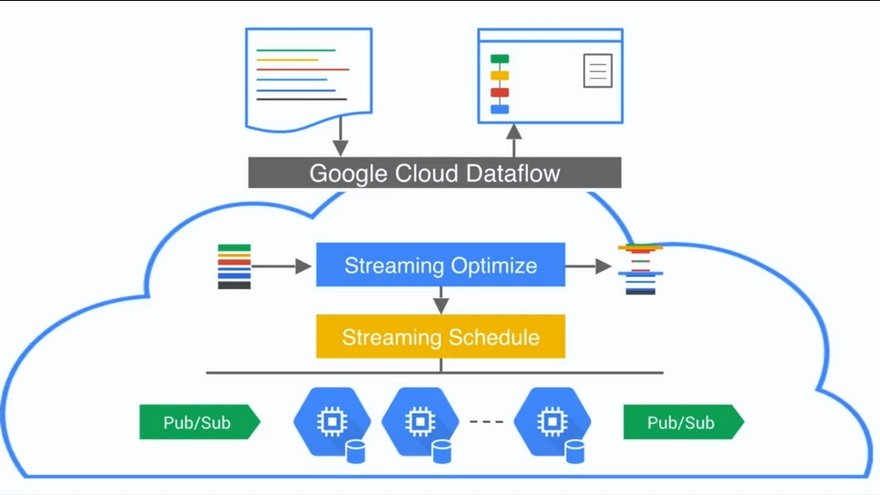
Công cụ này là một dịch vụ hoàn toàn được quản lý, chuyên dùng để xử lý dữ liệu theo luồng, có khả năng xử lý khối lượng dữ liệu rất lớn một cách hiệu quả. Dịch vụ này được thiết kế để làm giảm sự phức tạp trong việc phát triển và thực hiện các mô hình xử lý dữ liệu khác nhau.
Dataflow tựa như một đội ngũ các chuyên gia dữ liệu hàng đầu, tự động hóa và tối ưu hóa các tác vụ như xử lý dữ liệu theo lô, ETL (trích xuất, chuyển đổi, tải) và xử lý dữ liệu theo thời gian thực, giúp đơn giản hóa quy trình cho người dùng.Một điểm mạnh của Dataflow là khả năng tích hợp dễ dàng với các dịch vụ khác của Google Cloud, chẳng hạn như BigQuery, Cloud Storage và Pub/Sub. Hơn nữa, Dataflow có khả năng tự động điều chỉnh quy mô tài nguyên dựa trên khối lượng công việc, giống như một bộ điều chỉnh nhiệt độ thông minh tự động thay đổi nhiệt độ trong nhà dựa trên số lượng người và điều kiện thời tiết.
Lợi thế
Google Cloud Dataflow mang lại nhiều lợi ích đáng chú ý cho doanh nghiệp. Đầu tiên, Dataflow nổi bật với khả năng tích hợp dễ dàng vào hệ sinh thái của Google Cloud. Điều này có nghĩa là nó có thể làm việc mượt mà với các dịch vụ khác như BigQuery, Cloud Storage và Pub/Sub, giúp tối ưu hóa quy trình làm việc và cải thiện khả năng phân tích dữ liệu.
Dataflow được thiết kế để đơn giản hóa quy trình xử lý dữ liệu. Công cụ này giúp giảm thiểu sự phức tạp trong việc phát triển và triển khai các mô hình xử lý dữ liệu, từ việc xử lý theo lô, ETL (trích xuất, chuyển đổi, tải) đến các khối lượng công việc tính toán theo thời gian thực. Điều này giống như việc có một đội ngũ chuyên gia dữ liệu hàng đầu, tự động hóa và tối ưu hóa các tác vụ mà không yêu cầu can thiệp nhiều từ người dùng.
Một điểm mạnh khác của Dataflow là khả năng mở rộng tự động. Hệ thống có thể tự điều chỉnh tài nguyên dựa trên khối lượng công việc, giúp xử lý dữ liệu lớn mà không gặp vấn đề về hiệu suất. Mô hình thanh toán theo mức sử dụng giúp doanh nghiệp chỉ trả tiền cho tài nguyên thực sự sử dụng, từ đó giảm chi phí không cần thiết. Thêm vào đó, công cụ nổi bật tính thân thiện với người dùng. Công cụ này dễ sử dụng và có mô hình giá linh hoạt, giúp doanh nghiệp kiểm soát chi phí hiệu quả hơn. Hơn nữa, Dataflow hỗ trợ nhiều ngôn ngữ lập trình, bao gồm Python, mang lại sự linh hoạt cho các nhà phát triển trong việc xây dựng các giải pháp tùy chỉnh theo nhu cầu cụ thể của họ.
Thách thức
Một trong những thách thức lớn của công cụ này là khả năng tích hợp với các chủ đề Kafka. Hiện tại, khả năng tích hợp giữa Dataflow và Kafka chưa hoàn toàn mượt mà. Điều này có thể gây khó khăn trong việc kết nối giữa các hệ thống khác nhau. Thời gian triển khai của Dataflow cũng có thể cần được cải thiện. Trong một số trường hợp, việc thiết lập và triển khai các quy trình có thể mất thời gian. Nó không đáp ứng nhanh chóng nhu cầu thực tế của người dùng và có thể ảnh hưởng đến hiệu suất công việc. Thêm vào đó, hệ thống còn gặp khó khăn trong việc ghi lại lỗi dẫn tới không được tối ưu hóa. Qua đó làm cho việc gỡ lỗi và khắc phục sự cố trở nên khó khăn hơn. Điều này có thể gây cản trở trong quá trình xử lý các vấn đề phát sinh. Cuối cùng, giao diện người dùng của Dataflow có thể còn phức tạp đối với một số người dùng. Một số người cho rằng giao diện hiện tại chưa được tối ưu hóa. Người dùng cần cải thiện để trở nên trực quan và dễ sử dụng hơn, đặc biệt là những bạn thời gian đầu sử dụng các công cụ ETL.
Giá cả
Chi phí sử dụng Google Cloud Dataflow bao gồm các khoản phí cho tài nguyên công nhân, xử lý dữ liệu Dataflow Shuffle và xử lý dữ liệu Streaming Engine. Dưới đây là các mức giá cho các loại công việc khác nhau:
| Loại công việc | CPU (vCPU/giờ) | Bộ nhớ (GB/giờ) | Dữ liệu được xử lý trong quá trình xử lý (GB) |
| Batch | $0.0672 (1,598 VNĐ) | $0.0042684 (101 VNĐ) | $0.01322 (315 VNĐ) |
| FlexRS | $0.0404(957 VNĐ) | $0.0025655(60 VNĐ) | $0.01322(315 VNĐ) |
| Streaming | $0.0828(1,977 VNĐ) | $0.0042684(101 VNĐ) | $0.02164(510 VNĐ) |
Azure Data Factory

Azure Data Factory (ADF) là dịch vụ tích hợp dữ liệu dựa trên đám mây của Microsoft. Bạn có thể tưởng tượng nó như một dây chuyền lắp ráp khổng lồ và hiệu quả trong đám mây, được thiết kế để thu thập dữ liệu từ nhiều nguồn khác nhau. Khi dữ liệu đã được thu thập, ADF sẽ chuyển đổi dữ liệu này bằng các dịch vụ như Azure HDInsight Hadoop, công cụ ETL Spark và Azure Data Lake Analytics.
Điểm nổi bật của Azure Data Factory là giao diện trực quan của nó, cho phép người dùng tạo, lập lịch và giám sát các quy trình dữ liệu. Nó giống như một bảng điều khiển công nghệ cao, nơi bạn có thể nhanh chóng và chính xác theo dõi và quản lý các quy trình dữ liệu của mình. ADF cũng có khả năng tích hợp với nhiều công cụ ETL khác của Microsoft Azure, làm cho nó trở nên linh hoạt trong hệ sinh thái Azure. Bạn có thể hình dung nó như một trung tâm kết nối trong một mạng lưới rộng lớn, liên kết các điểm dữ liệu khác nhau để tạo ra những thông tin giá trị cho doanh nghiệp, tương tự như việc kết nối các điểm trong một câu đố phức tạp.
Lợi thế
Azure Data Factory mang lại nhiều lợi ích nổi bật với kiến trúc đa đám mây. ADF rất hữu ích trong việc tích hợp và tập trung dữ liệu từ nhiều nguồn lưu trữ đám mây khác nhau, làm cho nó trở thành lựa chọn tốt cho các môi trường lưu trữ dữ liệu đa dạng. ADF cho phép người dùng thu thập và tích hợp dữ liệu từ các nguồn phổ biến mà không cần phải viết mã, giúp những người không có kỹ năng kỹ thuật cũng có thể sử dụng.
Thêm vào đó, ADF cung cấp lộ trình chuyển đổi dễ dàng với nỗ lực tối thiểu cho các doanh nghiệp đã sử dụng Microsoft SQL Server Integration Services (SSIS). Ngoài ra gần 100 kết nối dữ liệu được xây dựng sẵn cho các nguồn dữ liệu bên ngoài, làm cho việc tích hợp trở nên dễ dàng. Đi kèm với các tính năng tích hợp sẵn, ADF giám sát hoạt động tích hợp dữ liệu và thiết lập cảnh báo cho các lỗi xảy ra.
Thách thức
Tuy nhiên, Azure Data Factory gặp khó khăn trong việc tích hợp với các nguồn dữ liệu không chuẩn, yêu cầu phải viết mã tùy chỉnh. Hơn nữa, mặc dù ADF hỗ trợ một số nguồn dữ liệu bên ngoài, nhưng nó chủ yếu được thiết kế cho các môi trường tập trung vào Azure, có thể là một hạn chế đối với các chiến lược đa đám mây. Mặc dù mô hình giá theo sử dụng của ADF rất hấp dẫn, chi phí lâu dài có thể cao hơn so với các giải pháp tại chỗ.
Giá cả
Sử dụng công cụ này dựa trên mô hình tiêu thụ và chi trả cho những gì bạn sử dụng. Chi tiết giá cả phụ thuộc vào các dịch vụ và tài nguyên sử dụng trong ADF.
| Thể loại | Azure Integration Runtime | Azure Managed VNET Integration Runtime | Self-Hosted Integration Runtime |
| Orchestration | $1/ 1,000 lượt chạy(23.800 VNĐ) | $1/ 1,000 lượt chạy(23.800 VNĐ) | $1.50/ 1,000 lượt chạy(35.700 VNĐ) |
| Data movement Activity | $0.25/DIU – giờ(5.950 VNĐ) | 0,25 USD/DIU-giờ(5.950 VNĐ) | $ 0.10 / giờ(2.380 VNĐ) |
| Pipeline Activity | $0.005/giờ(119 VNĐ) | $ 1 / giờ(23.800 VNĐ) | 0,002 USD/giờ(47.6 VNĐ) |
| External Pipeline Activity | $0.00025/giờ(5.95 VNĐ) | $ 1 / giờ(23.800 VNĐ) | 0,0001 USD/giờ(2.38 VNĐ) |
AWS Data Pipeline
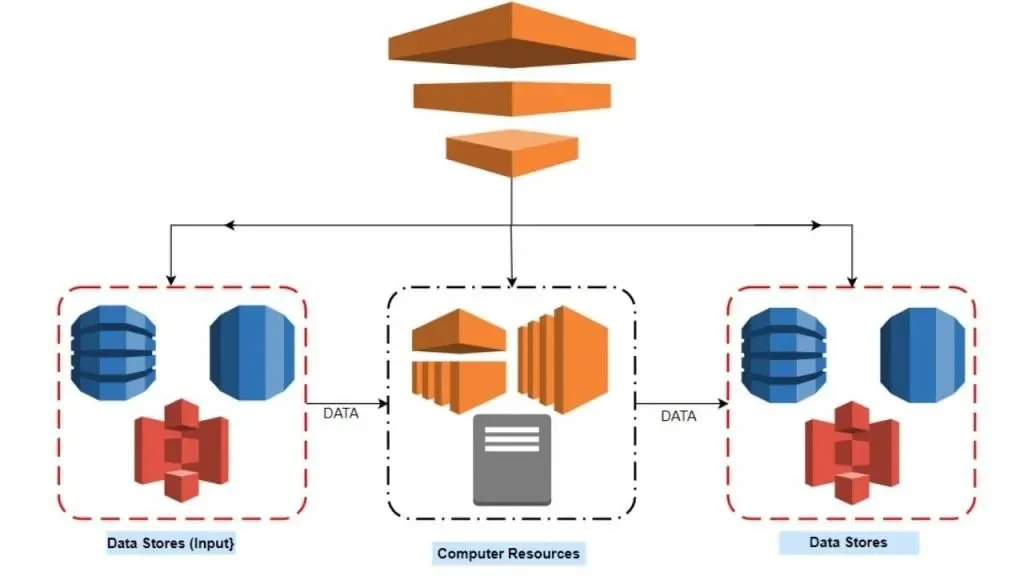
Công cụ này cung cấp giải pháp hiệu quả để xử lý và di chuyển dữ liệu giữa các dịch vụ ETL của AWS và các nguồn dữ liệu tại chỗ theo các khoảng thời gian đã định. Với dịch vụ này, bạn có thể truy cập dữ liệu của mình định kỳ, thực hiện các phép biến đổi và xử lý dữ liệu theo quy mô lớn, đồng thời chuyển giao kết quả một cách hiệu quả đến các công cụ ETL của AWS như Amazon S3, RDS, DynamoDB và EMR.
Một trong những quan trọng của AWS Data Pipeline là tính khả dụng cao và hiệu suất đáng tin cậy, giống như một cỗ máy hoạt động trơn tru và liên tục đáp ứng đúng hạn. Dịch vụ này được thiết kế để xử lý các phụ thuộc giữa các tác vụ một cách hiệu quả, đảm bảo rằng chúng được thực hiện theo đúng thứ tự và thời gian cần thiết. Dịch vụ cũng rất tùy chỉnh, cho phép bạn xác định các nguồn dữ liệu, lịch trình và tài nguyên cần thiết cho các tác vụ xử lý. Sự tùy chỉnh này giống như việc có một bộ đồ may đo hoàn hảo theo số đo của bạn, đảm bảo phù hợp với nhu cầu dữ liệu cụ thể của bạn.
Lợi thế
Một trong những lợi thế chính của AWS Data Pipeline là khả năng tích hợp liền mạch với các dịch vụ AWS khác như S3, RDS và Redshift, làm cho nó trở thành một giải pháp toàn diện trong hệ sinh thái AWS. Nó cho phép tự động hóa các tác vụ di chuyển và xử lý dữ liệu, tiết kiệm thời gian và giảm thiểu lỗi do con người. Dịch vụ này hỗ trợ nhiều nguồn dữ liệu, định dạng và hoạt động xử lý khác nhau, cung cấp sự linh hoạt cho các nhu cầu tích hợp dữ liệu đa dạng. Là một dịch vụ của AWS, nó có khả năng mở rộng dễ dàng để xử lý khối lượng dữ liệu lớn.
Thách thức
Tuy nhiên, việc thiết lập và quản lý các quy trình dữ liệu có thể trở nên phức tạp, đặc biệt đối với những người mới bắt đầu làm quen với AWS hoặc kỹ thuật dữ liệu. Mặc dù nó tích hợp tốt với các dịch vụ của AWS, nhưng có thể không linh hoạt khi làm việc với các nguồn dữ liệu bên ngoài hoặc tại chỗ. Quản lý chi phí cũng có thể là một thách thức do tính biến động của giá dịch vụ AWS.
Giá cả
Chi phí của AWS Data Pipeline dựa trên tài nguyên máy tính được tiêu thụ và tần suất hoạt động của các quy trình. Giá cả cụ thể phụ thuộc vào một số yếu tố như số lượng điều kiện tiên quyết và các hoạt động được thực hiện trong quy trình, cũng như tần suất các lần chạy quy trình. Bên cạnh đó, chi phí cũng chịu ảnh hưởng bởi khu vực triển khai quy trình. AWS Data Pipeline áp dụng mô hình giá theo sử dụng, có nghĩa là bạn chỉ phải trả tiền cho tài nguyên mà bạn thực sự sử dụng, giúp linh hoạt hơn trong việc quản lý ngân sách.
Oracle Data Integrator (ODI)

ODI là một nền tảng toàn diện chuyên về các quy trình tải hàng loạt hiệu suất cao, chuyển đổi dữ liệu và ETL. Đây là một công cụ mạnh mẽ và linh hoạt giúp đơn giản hóa các tác vụ tích hợp dữ liệu phức tạp trên các hệ thống khác nhau.
ODI như một dịch giả thành thạo trong việc kết hợp các ngôn ngữ (định dạng dữ liệu) và văn hóa (hệ thống) khác nhau dưới một mái nhà để tạo ra sự giao tiếp liền mạch. Thay vì chuyển đổi dữ liệu trước khi tải vào hệ thống đích, ODI tải dữ liệu thô trước và thực hiện các chuyển đổi trực tiếp trong cơ sở dữ liệu đích. Phương pháp này tận dụng sức mạnh của cơ sở dữ liệu để xử lý, giúp cải thiện hiệu suất và hiệu quả.
ODI rất linh hoạt, hỗ trợ nhiều nguồn dữ liệu và đích đến: từ hệ thống big data, ứng dụng đám mây đến kho dữ liệu truyền thống. Điểm mạnh của ODI là khả năng duy trì tính toàn vẹn của dữ liệu ngay cả trong các môi trường CNTT không đồng nhất. Đây là một công cụ hữu ích cho các tổ chức muốn tích hợp tài sản dữ liệu của mình một cách hiệu quả và với chi phí thấp nhất.
Lợi thế
Công cụ này mang đến nhiều lợi thế cho người dùng thông qua sự đa dạng trong tích hợp dữ liệu là một điểm nổi bật. ODI có thể kết nối và hài hòa các nguồn dữ liệu khác nhau, từ cơ sở dữ liệu truyền thống đến các giải pháp big data. Hiệu suất cao là một lợi thế khác. Công nghệ ELT của ODI được thiết kế để đạt hiệu suất và hiệu quả tối đa, đặc biệt trong việc xử lý khối lượng dữ liệu lớn. Quản trị dữ liệu tiên tiến cũng là một điểm mạnh của ODI. Các khả năng mạnh mẽ của nó đảm bảo rằng quản lý dữ liệu hiệu quả và tuân thủ các tiêu chuẩn quy định khác nhau.
Thách thức
Dù có nhiều lợi thế, Oracle Data Integrator cũng đối mặt với một số thách thức. ODI có thể giống như học chơi một nhạc cụ phức tạp – mạnh mẽ nhưng không hề dễ dàng cho người mới bắt đầu. Sự phức tạp trong tích hợp cũng là một thách thức. Phạm vi chức năng rộng lớn của ODI có thể gây choáng ngợp, và việc thiết lập các quy trình tích hợp dữ liệu phức tạp có thể khó khăn. Ngoài ra, tài nguyên cần thiết cũng là một vấn đề. Trong một số trường hợp, ODI có thể yêu cầu hệ thống tài nguyên lớn, đặc biệt đối với các triển khai quy mô lớn. Điều này giống như việc chạy một trò chơi cao cấp trên một máy tính cơ bản.
Giá cả
Đối với người dùng cá nhân, nếu bạn chọn Named User Plus License thì sẽ có giá là 21.600.000 VND. Để duy trì cập nhật và nhận hỗ trợ, có thêm một khoản phí hàng năm là 4.752.000 VND mỗi người dùng.
Đối với các doanh nghiệp lớn (Processor License), bạn sử dụng Processor License với giá 720.000.000 VND, phù hợp cho việc sử dụng rộng rãi và chuyên sâu hơn. Giống như bảo trì ô tô, có một khoản phí hàng năm cho Giấy phép Cập nhật Phần mềm và Hỗ trợ là 158.400.000 VND cho tùy chọn này.
Cần có một chút lưu ý ở phần giá cả của công cụ này là cần có tối thiểu 25 người dùng được chỉ định cho mỗi bộ xử lý.
Kết Luận
Việc áp dụng các công cụ ETL như Hadoop, Google Data Flow, Azure Data Factory, AWS Data Pipeline và Oracle Data Integration không chỉ giúp doanh nghiệp tối ưu hóa quy trình xử lý dữ liệu mà còn nâng cao hiệu suất làm việc. Lựa chọn công cụ phù hợp với nhu cầu là yếu tố then chốt để doanh nghiệp khai thác tối đa tiềm năng nguồn dữ liệu. Từ đó đạt được sự phát triển bền vững và thành công lâu dài.
Mời các bạn tham khảo thêm:
KHOÁ HỌC TRUY VẤN VÀ THAO TÁC DỮ LIỆU SQL TỪ CƠ BẢN ĐẾN NÂNG CAO
KHÓA HỌC DATA WAREHOUSE : TỔNG HỢP, CHUẨN HÓA VÀ XÂY DỰNG KHO DỮ LIỆU TRONG DOANH NGHIỆP
LỘ TRÌNH TRỞ THÀNH DATA ENGINEER CHO NGƯỜI MỚI BẮT ĐẦU
