
Mục lục
Tổng quan
Spark Streaming là một bộ mở rộng của core Spark API cho phép mở rộng, thông lượng cao, có khả năng chịu lỗi. Spark Streaming được thiết kế để xử lý dữ liệu dạng streams.
Dữ liệu đầu vào từ Spark có thể lấy từ Kafka, Flume, Kinesis hoặc TCP sockets là các dữ liệu động được gửi vào liên tục và có thể được xử lý sử dụng các thuật toán phức tạp với các hàm high-level như map, reduce, join và window. Cuối cùng, dữ liệu sau khi xử lý có thể lưu trữ tại các hệ thống file system như HDFS, databases, hoặc hiển thị trực tiếp trên dashboards.

Spark Streaming nhận dữ liệu đầu vào và chia chúng thành các batches, sau đó chúng được xử lý bởi Spark engine để tạo ra luồng kết quả cuối cùng theo lô.
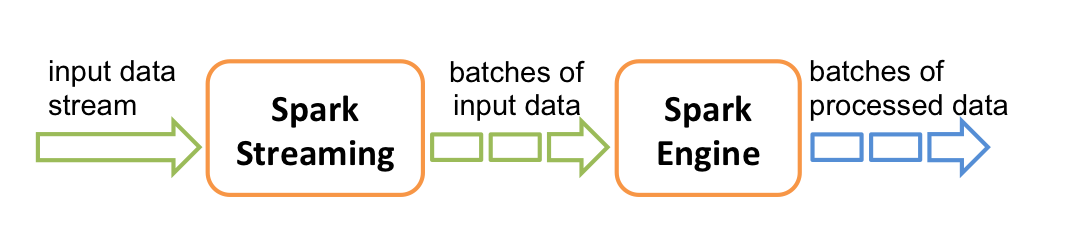
Với core Spark chúng ta được biết và làm quen với RDD, tuy nhiên với Spark Streaming chúng ta không thể làm việc với RDD được mà thay vào đó Spark Streaming cung cấp một high-level abstraction được gọi là DStream (discretized stream).
Về bản chất, DStream là 1 chuỗi các RDD liên tiếp.
Ý kiến của bản thân mình
Để nói về Spark Streaming thì cũng là khá nhiều, các bạn có thể bụp cái đọc ngay con docs của Spark Streaming hoặc mình cũng có thể dịch hết con docs ra để các bạn đọc nhưng nói chung nhiều kiến thức mới và khó để hiểu ngay lập tức, vì thế trong bài viêt này mình cũng chỉ muốn mang tới cho mọi người cái nhìn tổng quan nhất về Spark Streaming và chúng ta sẽ hình dung dần dần về Spark Streaming này qua những bài viết tiếp theo của mình khi chúng ta bắt đầu vào làm các job về Spark Streaming. Chúng ta sẽ đi từng bước, nhưng tới đâu sẽ chắc tới đó.
DStream Operation
Có 3 loại Operation là:
- Input operation
- Transformation operation
- Output operation
Input Operation
Mọi Input Operation đều được liên kết trực tiếp với 1 đối tượng nào đó, có 2 loại streaming source là:
- Basic source: Socket, file,…
- Advanced source: Kafka, Twitter,…
Ví dụ Basic source – socket connection:
| 1 | JavaReceiverInputDStream<String> lines = jsc.socketTextStream(“localhost”, 9999); |
Ví dụ Advanced source – Kafka:
| 1 2 3 4 5 | JavaInputDStream<ConsumerRecord<String, String>> stream; stream = KafkaUtils.createDirectStream(jssc,LocationStrategies.PreferConsistent() ,ConsumerStrategies.Subscribe(topics, SSKafkaProperties.getInstance())); |
Transformations
Cũng giống với Spark RDD, transformations giúp biến đổi dữ liệu đầu vào để đưa ra dữ liệu phù hợp với yêu cầu đâu ra. DStream hỗ trợ nhiều transformations có sẵn hơn so với Spark RDD.
map(func) Trả về một tập dữ liệu mới bằng cách chuyển đổi mỗi phần tử cũ sang từng phần tử mới thông qua func.
Ví dụ chương trình sau viết hoa toàn bộ chuỗi kí tự đầu vào:
| 1 2 3 4 5 6 7 8 9 10 11 | JavaReceiverInputDStream<String> input = jsc.socketTextStream(“localhost”, 9999); JavaDStream<String> upcase = input.map(new Function<String, String>() { private static final long serialVersionUID = 1L; @Override public String call(String value) throws Exception { return value.toUpperCase(); } }); upcase.print(); |
Sự biến đổi của map là 1-1 khi một đầu vào xin chao toi la sẽ cho ra một đầu ra XIN CHAO TOI LA.
flatMap(func) Giống mới map, tuy nhiên map là chuyển đổi 1-1 còn với flatMap thì có thể là chuyển đổi 1-N, 1-1, 1-0.
Ví dụ trong chương trình dưới đây sẽ tách một chuỗi kí tự đầu vào thành danh sách các từ:
| 1 2 3 4 5 6 7 8 9 10 11 12 | JavaReceiverInputDStream<String> input = jsc.socketTextStream(“localhost”, 9999); JavaDStream<String> words = input.flatMap(new FlatMapFunction<String, String>() { private static final long serialVersionUID = 1L; @Override public Iterator<String> call(String value) throws Exception { List<String> listString = Arrays.asList(value.split(” “)); return listString.iterator(); } }); words.print(); |
Sự biến đổi ở đây không còn là 1-1 nữa, khi chuỗi kí tự đầu vào là xin chao toi la trannguyenhan thì ta sẽ được một danh sách gồm 5 đầu ra lần lượt là xin, chao, toi, la, trannguyenhan.
filter(func)
Trả về một DStream mới bằng việc lấy ra một số giá trị được chọn lọc qua hàm func.
Ví dụ trong chương trình dưới đây lọc và trả ra những dòng đầu vào có chứa từ error:
| 1 2 3 4 5 6 7 8 9 10 11 | JavaReceiverInputDStream<String> input = jsc.socketTextStream(“localhost”, 9999); JavaDStream<String> lines = input.filter(new Function<String, Boolean>() { private static final long serialVersionUID = 1L; @Override public Boolean call(String value) throws Exception { return value.contains(“error”); } }); lines.print(); |
Về cơ bản thì tính chất và cách sử dụng cũng như các RDD Transformations thế nên mình cũng chỉ demo 3 hàm map, flatMap và filter như trên, các bạn có thể xem thêm các DStream transformations tại https://spark.apache.org/docs/2.2.0/streaming-programming-guide.html#transformations-on-dstreams
Output Operation
Output Operation cho phép dữ liệu của DStream được đẩy ra các hệ thống bên ngoài như cơ sở dữ liệu hoặc hệ thống tệp. Một số các output operation ví dụ như là print() mà chúng ta đã sử dụng ở 3 ví dụ trong Transformations Operation bên trên để in dữ liệu ra ngoài terminal.
Ngoài ra, chúng ta còn một số các Output Operation khác như:
- saveAsTextFiles
- saveAsObjectFiles
- saveAsHadoopFiles
- foreachRDD
Nguồn: Internet
