
Spark SQL, DataFrame chính là những thành phần được sử dụng nhiều nhất trong tổng thể Framework Apache Spark. Có thể nói Spark SQL đã “phổ cập” tính toán phân tán cho 1 tập người dùng lớn hơn nhiều những Developer chỉ hằng ngày ngồi code, gọi những API nào là map, nào là reduce…

Con đường đến với Big Data với các Data Analyst — những người không biết code trở nên dễ dàng hơn nhờ có Spark SQL
Mục lục
1. Spark SQL
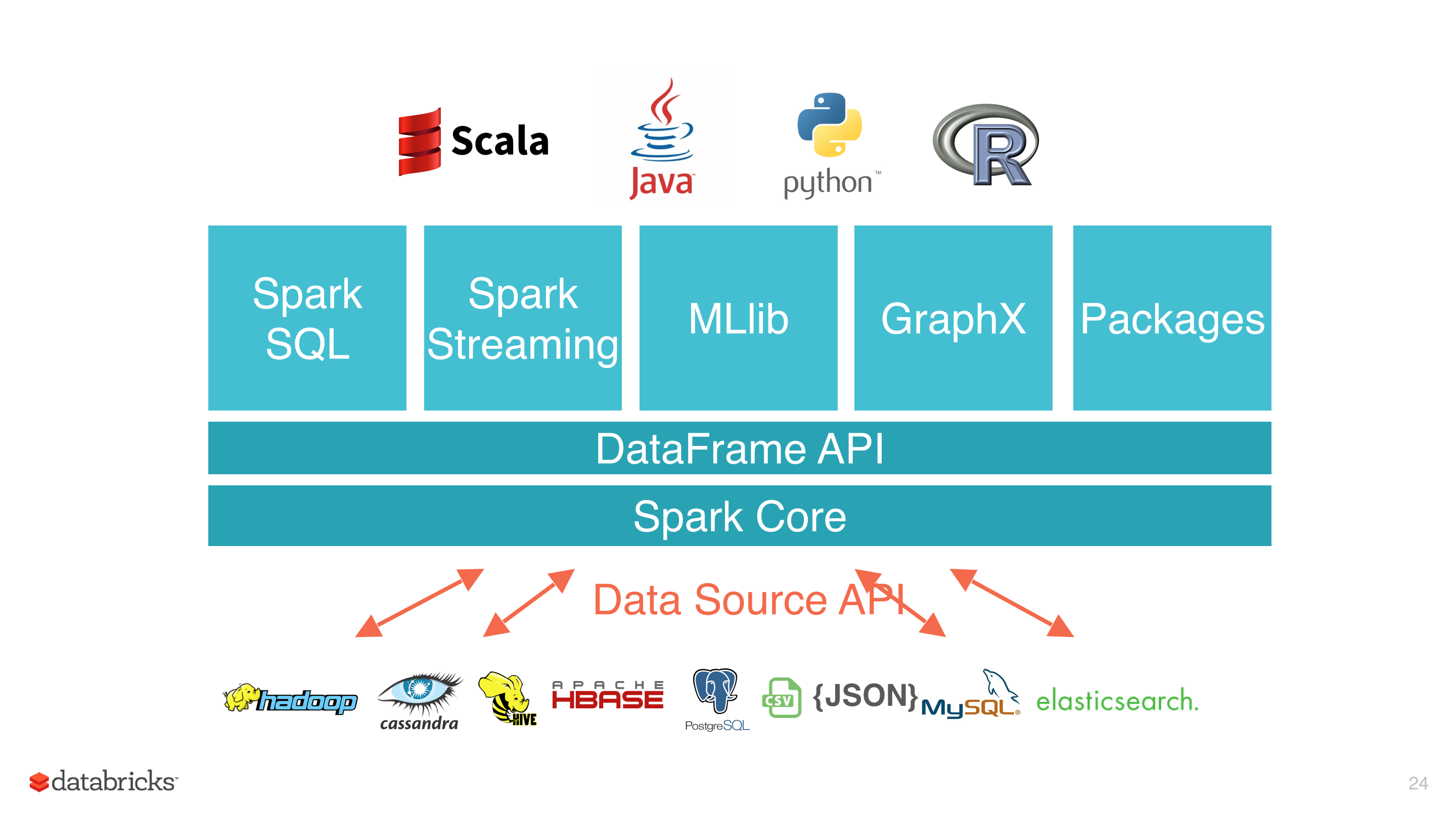
Nếu lên trang chủ của Spark tại địa chỉ: https://spark.apache.org/, các bạn sẽ thấy có 1 phần giới thiệu rất lớn nói rằng Spark bao gồm rất nhiều thư viện trên nền Spark Core và Spark SQL là 1 trong số đó.
Apache Spark là framework xử lý xư liệu phân tán, tập hợp nhiều thư viện cho các mục đích khác nhau và build on-top Spark Core. Điều này giúp Spark có tính nhất quán lớn, thay vì mỗi mục đích bạn phải tìm 1 thư viện riêng thì với việc có sẵn như Spark, trong 1 project bạn vừa có thể sử dụng Spark Core kết hợp với Spark SQL hay Mllib một cách linh hoạt, tối ưu các công việc theo đúng mục đích của chúng.
Khi thực thi, Spark SQL vẫn sẽ gọi xuống lớp Core bên dưới, sử dụng RDD để tính toán.
Có thể tóm gọn một số đặc điểm quan trọng của Spark SQL như sau:
- Được xây dựng phía trên tầng Spark Core, thừa hưởng tất cả các tính năng mà RDD có.
- Làm việc với tập dữ liệu là DataSet hoặc DataFrame (tập dữ liệu phân tán, có cấu trúc)
- Hiệu năng cao, khả năng mở rộng và chịu lỗi tốt
- Tương tích với các thành phần khác trong tổng thể Spark Framework (như Streaming/ Mllib, GraphX)
- Bao gồm 2 thành phần là DataSet API và Catalyst Optimizer.
2. Spark SQL Performance
Không quá khi nói rằng, trong việc biến đổi và tổng hợp dữ liệu, Spark SQL với DataFrame luôn có hiệu năng cao hơn rất nhiều so với sử dung RDD. Còn so với các công nghệ tương tự khác như Impala hay Shark thì thời gian thực thi với Spark SQL cũng luôn rất ấn tượng.
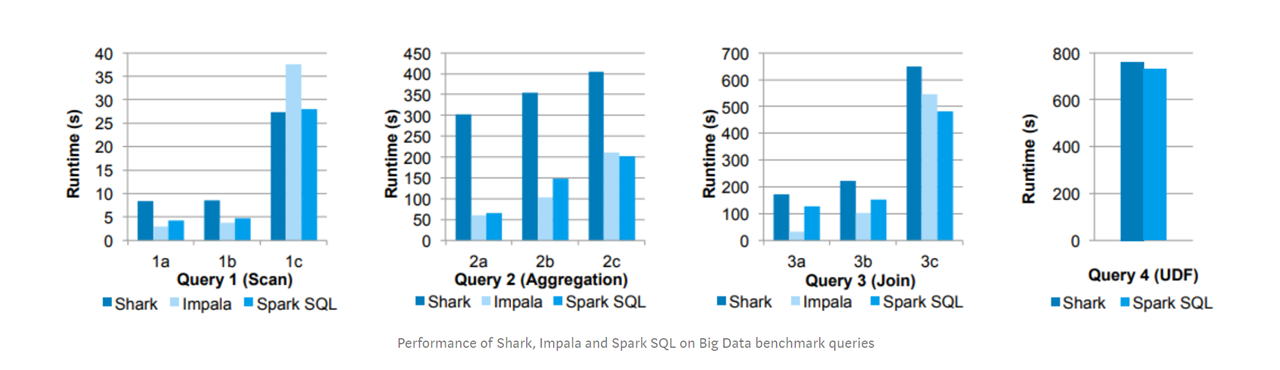
Spark SQL, 1 thư viện nguồn mở có hiệu năng ngang ngửa với Impala, 1 query engine rất “xịn” đến từ Cloudera và tốt hơn Shark trong phần lớn các bài thử nghiêm.
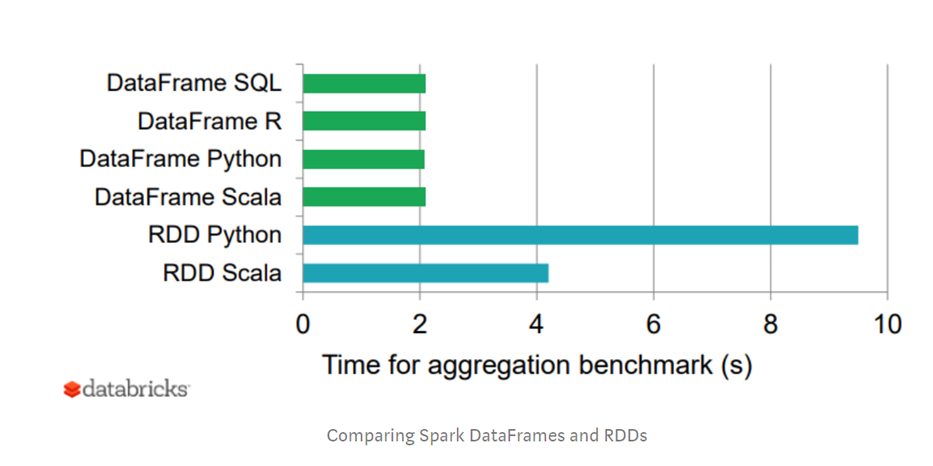
So với người anh là RDD trên cùng 1 công việc tổng hợp, Spark SQL với DF cho thời gian chạy nhanh hơn ít nhất 2 lần. Nếu chạy qua RDD python là tới gần 5 lần.
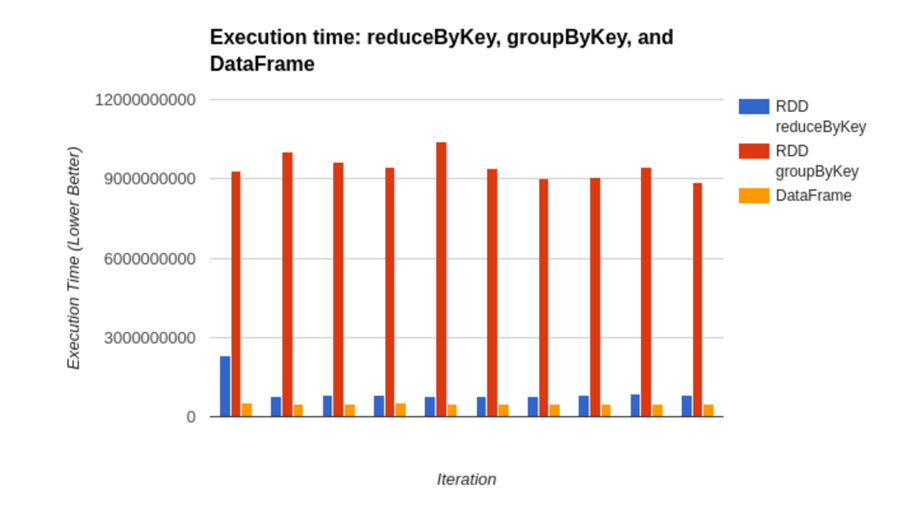
Một bài thử nghiệm nữa là thực thi các aggregation thông qua RDD với 2 api là reduceByKey và RDD groupByKey với DataFrame và kết quả là DF có thời gian xử lý nhanh hơn cả.
3. DataFrame
Vậy là có thể thấy Spark SQL thực sự hiệu quả trong việc xử lý dữ liệu như nào. Cốt lõi của Spark SQL chính là DataFrame và các API tương tác. Vậy DataFrame là gì?
Theo định nghĩa:
“A DataFrame is an immutable, distributed collection of data that is organized into rows, where each one consists a set of columns and each column has a name and an associated type”.
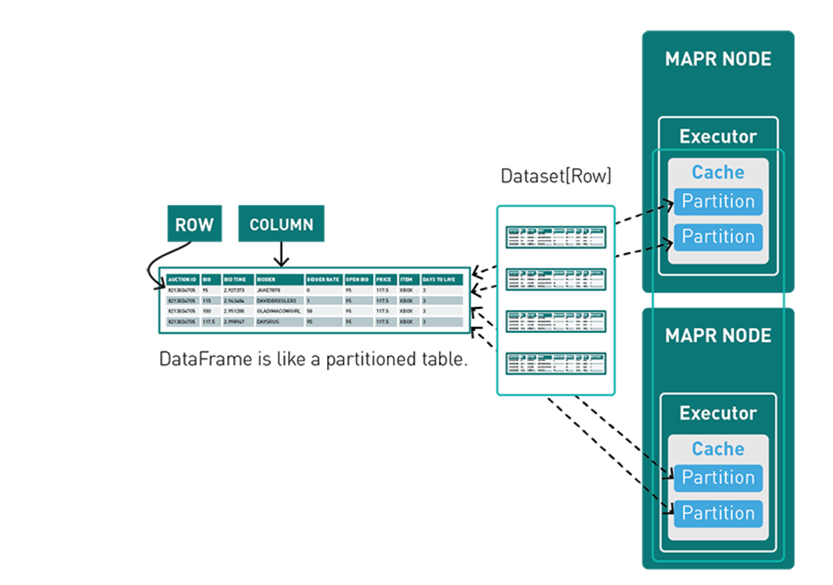
Hiểu đơn giản DF giống như 1 bảng trong hệ CSDL quan hệ. Có các trường, được định sẵn kiểu dữ liệu, và tập hợp các bản ghi. Tuy nhiên 1 DF có thể đại diện cho lượng dữ liệu lớn hơn rất nhiều so với các bảng trong DB, bản thân mình đã xử lý các DF lên tới hàng chục tỉ row.
Các đặc điểm bao gồm:
- immutable: tính bất biến, dữ liệu của 1 DF sau khi tạo ra sẽ không thay đổi, nếu muốn chỉnh sửa ta cần tạo ra DF mới từ DF ban đầu, thông qua DF api.
- rows: là đối tượng đại diện cho 1 bản ghi dữ liệu. 1 DF = tập các row phân tán
- set of columns has name and an associated type: Ý nói về việc dữ liệu của DF là có cấu trúc, gồm tên là kiểu dữ liệu.
Spark SQL hỗ trợ rất nhiều nguồn dữ liệu như file, DB…. Với DataFrameReader, bạn có thể dễ dàng đọc dữ liệu từ nhiều nguồn, nhiều định dạng để rạo ra 1 DataFrame, từ đó có thể sử dụng các API của Spark SQL tương tác với chúng.
4. DataFrame or DataSet
Có 1 vấn đề rất nhiều bạn băn khoăn khi bắt đầu đọc về Spark và Spark SQL là không hiểu về 2 khái niệm DataFrame, DataSet. Hãy cùng xem hình đươi đây:
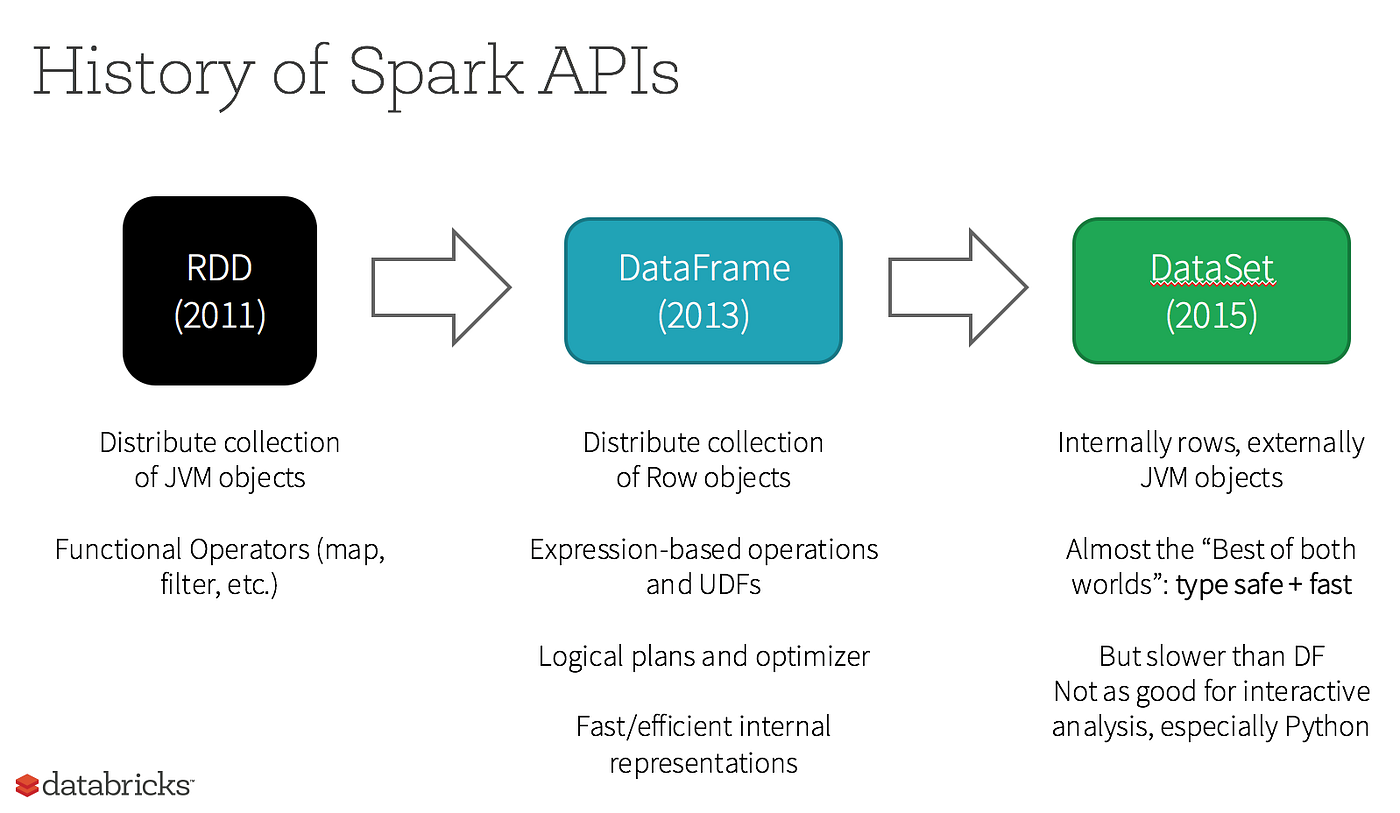
Bỏ qua về RDD do nó nằm ở tầng Spark Core, DataFrame được giới thiệu vào năm 2013 và DataSet là 2015. Sau khi tồn tại độc lập được 1 năm, tới 2016, Spark 2.0 ra mắt và gộp DF và DS lại, chỉ còn duy nhất DS.
Cả DF và DS đều là tập dữ liệu trong Spark SQL, tuy nhiên điểm khác biệt là các bản ghi trong DF được fix luôn là đối tượng Row, còn DS thì có thể tùy chỉnh được kiểu dữ liệu của bản ghi thông qua định nghĩa case class.
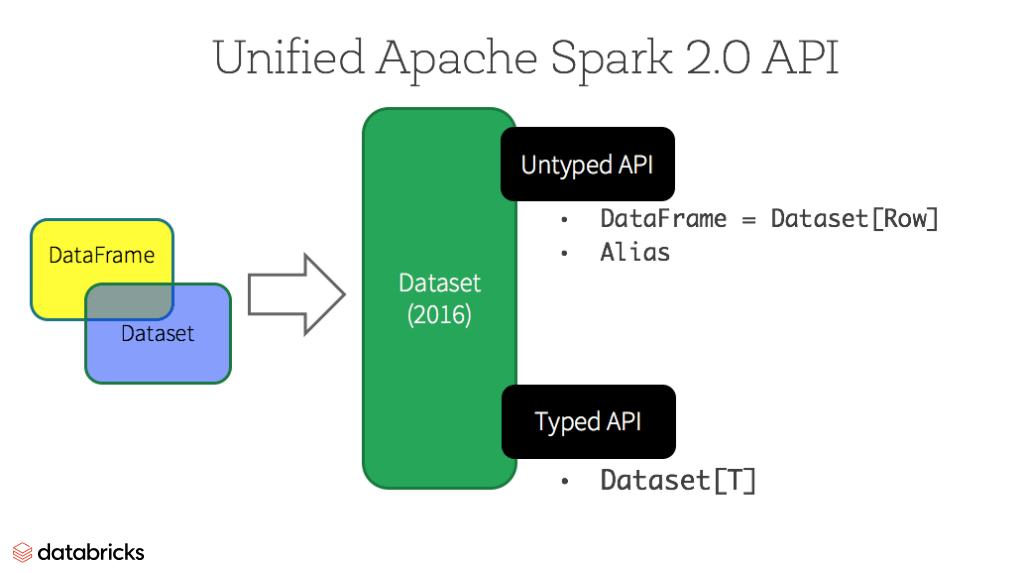
- DataFrame = Dataset [Row] (Untyped API)
- DataSet = Dataset [Type]
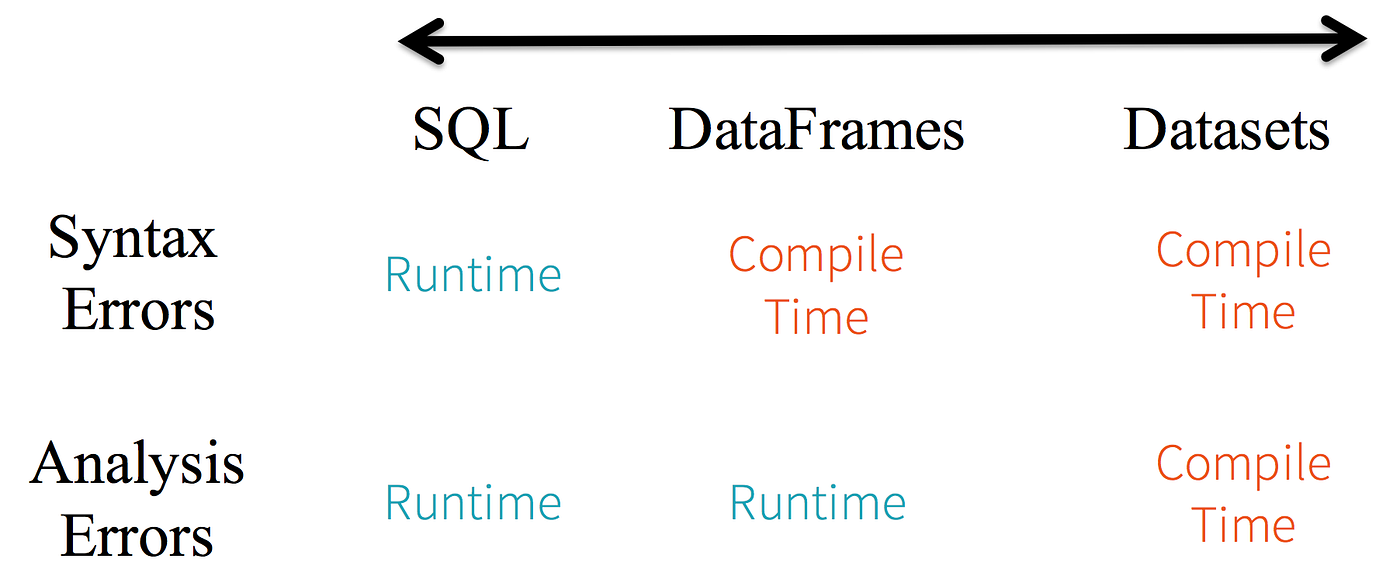
Một nhược điểm của DF là do kiểu dữ liệu được fix là row và truy cập dữ liệu trong DF thông qua row name nên nếu có sai sót trong việc truyền tên cột, trình biên dịch sẽ không thể phát hiện ra lỗi mà khi thực thi mới có exeption (Runtime exception). DS có thể khắc phục nhược điểm này do có sẵn định nghĩa của 1 bản ghi, dữ liệu trong DS truy cập thông qua member của case class chứ không phải truyển tên như DF.
Hãy xem 1 ví dụ:
Giả sử có tập dữ liệu như sau:
Dữ liệu cột movie_title là kiểu string, thử dùng toán tử trừ với cột dữ liệu này, sử dụng DF và DS:
Có thể thấy rằng khi dùng DF, ta vẫn build được code nhưng khi run, ứng dụng sẽ báo lỗi do khi chạy, DF mới biết được kiểu dữ liệu thật của cột movie_title là string cho dùng ở schema bạn đã chỉ định cột đó là string, trong khi nếu đã định nghĩa 1 class có thuộc tính movie_title là string thì ứng dụng sẽ báo lỗi ngay tại thời điểm complie, đó là 1 VD về sự khác biệt của DS và DF.
Nguồn: Internet
