Last updated on January 21st, 2026 at 02:16 pm
Với thế giới kinh doanh luôn trong trạng thái thay đổi liên tục, tính linh hoạt là quan trọng hơn bao giờ hết đối với các tổ chức của mọi lĩnh vực. Các tổ chức dựa trên dữ liệu đã hoạt động tốt nhất; những người có kiến trúc dữ liệu doanh nghiệp cho phép họ hiểu được sự thay đổi và thích ứng với sự biến động của thị trường hiện tại và những thay đổi về nguồn cung sẽ linh hoạt hơn so với các đối tác của họ.
Tuy nhiên, hầu hết các kỹ thuật lập mô hình dữ liệu theo chiều và dữ liệu chuẩn hóa không được thiết kế để đáp ứng với những thay đổi nhanh như thế này. Mặt khác, mô hình Data Vault giúp giải quyết vấn đề này – trang bị cho các tổ chức tốc độ và tính linh hoạt cao hơn cho nhu cầu phân tích của họ.
Mục lục
Nguồn gốc của mô hình Data Vault
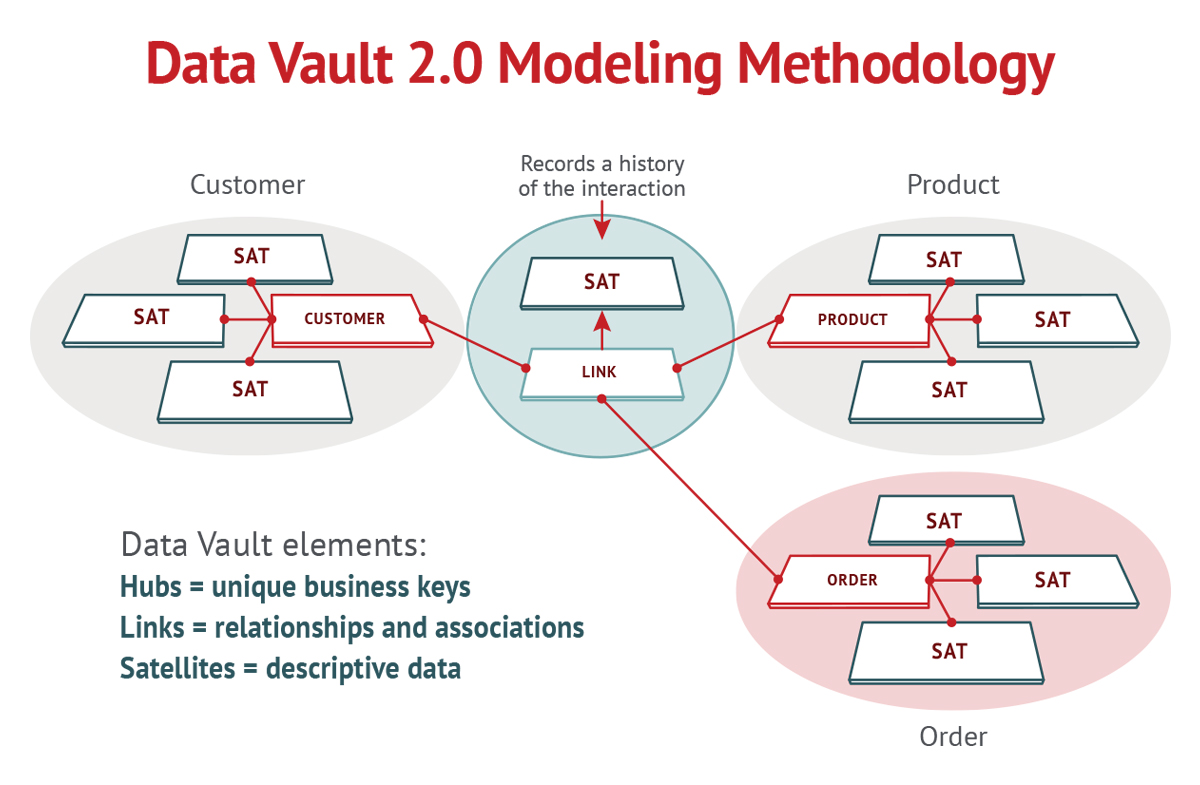
Data Vault là phương pháp tiếp cận mô hình hóa dữ liệu hướng chi tiết được thiết kế để cung cấp tính linh hoạt và nhanh nhẹn khi khối lượng dữ liệu tăng lên và / hoặc khi chúng trở nên phân tán và phức tạp hơn. Các doanh nghiệp có thể giải quyết những thách thức này trong mô hình dữ liệu của họ, được đặt tốt hơn để đưa ra các quyết định kinh doanh nhanh hơn, sáng suốt hơn.
Cách tiếp cận Data Vault, được Dan Linstedt tạo ra vào những năm 1990, được thiết kế để giúp mọi người có thể tiếp cận những lợi ích này. Tiếp theo là Data Vault 2.0 vào năm 2013, cung cấp một bộ cải tiến tập trung vào NoSQL và Dữ liệu lớn cũng như giới thiệu tích hợp cho dữ liệu phi cấu trúc và bán cấu trúc.
Mục đích của Linstedt là cho phép các kiến trúc sư và kỹ sư dữ liệu xây dựng Kho dữ liệu nhanh hơn, tức là với khung thời gian triển khai ngắn hơn và theo cách giải quyết hiệu quả hơn nhu cầu của doanh nghiệp.
Lợi ích kinh doanh trong cách tiếp cận Data Vault là gì?
Lợi ích chính ở đây là hiển nhiên: chu kỳ thực hiện càng ngắn, càng tiết kiệm được nhiều thời gian và tiền bạc. Chu kỳ ngắn hơn cũng giúp các yêu cầu kinh doanh đối với Kho dữ liệu và các cải tiến đang diễn ra (ví dụ: thông qua việc giới thiệu các nguồn mới) duy trì hiệu lực cho đến khi hoàn thành, tránh thay đổi các mục tiêu có thể ảnh hưởng đến ngân sách.
Nhiều tổ chức cũng sẽ chọn cách tiếp cận Data Vault vì tính linh hoạt và khả năng mở rộng mà nó mang lại. Cách tiếp cận nhanh để quản lý dự án rất phổ biến và phù hợp chặt chẽ với các khái niệm làm nền tảng cho mô hình Data Vault. Kết hợp lại, cả hai có thể mang lại sự linh hoạt thực sự cho chiến lược dữ liệu của bất kỳ doanh nghiệp nào, loại bỏ các chi phí liên quan đến việc phải mở rộng khả năng lưu trữ và xử lý dữ liệu bằng cách mở rộng quy mô khi cần thiết.
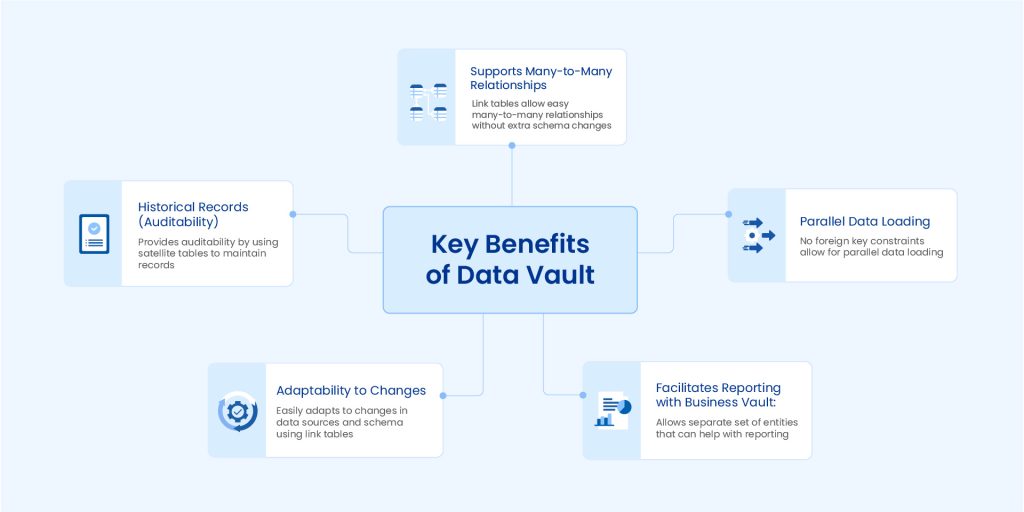
Song song cũng là một điểm cần xem xét. Việc tải dữ liệu vào Kho dữ liệu có nghĩa là nó cần được đồng bộ hóa ở ít điểm hơn. Điều này có nghĩa là quy trình tải dữ liệu nhanh hơn, giúp giải quyết khối lượng dữ liệu lớn và chèn dữ liệu thời gian thực.
Việc theo dõi lịch sử dữ liệu vốn có trong phương pháp Data Vault cũng có nghĩa là các mô hình dữ liệu có thể được kiểm tra mà không có những phức tạp không cần thiết. Cấu trúc của Kho dữ liệu phức tạp có nghĩa là dữ liệu này có thể được kiểm tra dễ dàng và có thể cung cấp các cơ chế bảo mật tích hợp giúp việc tuân thủ các yêu cầu bảo mật dữ liệu trở nên đơn giản.
Những thách thức là gì?
Mặc dù những điểm mạnh này là một điểm thu hút chính, giống như các phương pháp tiếp cận mô hình dữ liệu khác, Data Vault cũng có một số hạn chế mà các tổ chức cần xem xét.
Rõ ràng nhất là số lượng đối tượng dữ liệu tuyệt đối so với các cách tiếp cận khác – ví dụ: bảng và cột. Điều này là do cách tiếp cận Data Vault phân tách các loại thông tin.
Do đó, nỗ lực lập mô hình phía trước có thể lớn hơn và có thể có số lượng lớn hơn các tác vụ thủ công hoặc máy móc liên quan để thiết lập mô hình dữ liệu linh hoạt và chi tiết với tất cả các thành phần của nó.
Những thách thức này cần được giải quyết cụ thể nếu các tổ chức muốn tránh lao động thủ công tốn thời gian trong quá trình lập mô hình. Chìa khóa của điều này là tự động hóa.
Tự động hóa có thể giải quyết chúng như thế nào?
Trong Data Vault, có các lớp dữ liệu:
- Hệ thống nguồn, nơi dữ liệu sẽ được tạo hoặc bắt nguồn;
- Một khu vực tổ chức nhận dữ liệu từ hệ thống nguồn và mô hình hóa nó theo cấu trúc ban đầu của nó;
- Một kho dữ liệu cốt lõi chứa kho tiền thô, một lớp cho phép dữ liệu được truy nguyên trở lại dữ liệu hệ thống nguồn ban đầu;
- Kho tiền kinh doanh, về cơ bản là một lớp ngữ nghĩa nơi các quy tắc nghiệp vụ được thực hiện;
- Marts dữ liệu, được cấu trúc theo yêu cầu của tổ chức. Ví dụ: siêu thị dữ liệu tài chính hoặc tiếp thị sẽ giữ dữ liệu có liên quan cho các mục đích phân tích cụ thể.
Khu vực dàn dựng và kho tiền thô là các lớp phù hợp nhất với tự động hóa. Việc triển khai tự động hóa ở đây có thể tiết kiệm rất nhiều thời gian cho các kiến trúc sư dữ liệu và cải thiện hiệu quả tổng thể của cách tiếp cận Data Vault.
Làm thế nào để các doanh nghiệp xây dựng trên phương pháp Data Vault?
Dữ liệu không hiệu quả sẽ không còn kìm hãm các tổ chức nữa. Giờ đây, có thể xây dựng một hệ sinh thái dữ liệu bền vững, tích hợp công nghệ và phần mềm, hỗ trợ chiến lược dữ liệu tổng thể trong nhiều năm. Các công cụ bổ sung cho kỹ thuật lập mô hình dữ liệu đã chọn có thể là chất xúc tác thực sự để cải thiện khi nói đến công việc của các nhóm phân tích và các chuyên gia cá nhân, những người phụ thuộc vào môi trường dữ liệu hiệu quả cho công việc hàng ngày của họ.
Mô hình Data Vault có thể chứng minh một phần không thể thiếu của môi trường đó. Với cách tiếp cận mạnh mẽ được thiết kế để tối đa hóa lợi ích mà cách tiếp cận Data Vault mang lại, những người ở mặt than sẽ được hưởng lợi từ hiệu suất được cải thiện đáng kể khi chạy các mô hình phân tích hoặc quy trình làm việc – cho phép các tổ chức tối ưu hóa giá trị dữ liệu của họ ở tốc độ cao.
Các chuyên gia dữ liệu có thể yên tâm rằng dữ liệu của họ có thể được kiểm tra tại bất kỳ thời điểm nào, họ có thể tải khối lượng lớn dữ liệu mà không gặp bất kỳ sự cố nào và họ có thể tái tạo các truy vấn lịch sử khi cần. Điều này sẽ cho phép các tổ chức đưa ra các quyết định kinh doanh sáng suốt dẫn đến kết quả tốt hơn cho doanh nghiệp và khách hàng mà tổ chức phục vụ.
Xu hướng và vai trò của Data Vault trong kiến trúc dữ liệu hiện đại
Trong bối cảnh doanh nghiệp ngày càng phải xử lý dữ liệu lớn, đa nguồn và thay đổi nhanh, Data Vault vẫn giữ vai trò quan trọng trong thiết kế Data Warehouse hiện đại, đặc biệt với các tổ chức cần tính linh hoạt, khả năng mở rộng và yêu cầu cao về quản trị dữ liệu. Thay vì cạnh tranh trực tiếp với Dimensional Modeling, Data Vault ngày càng được sử dụng như lớp tích hợp dữ liệu trung tâm, trong khi các mô hình sao hoặc data mart được xây dựng ở tầng phục vụ phân tích.
Một xu hướng rõ rệt là Data Vault 2.0 gắn chặt với cloud và modern data stack. Việc triển khai Data Vault trên các nền tảng cloud data warehouse như Snowflake, BigQuery hay Redshift giúp tận dụng khả năng mở rộng linh hoạt, chi phí theo nhu cầu và hiệu năng xử lý lớn. Bên cạnh đó, nhiều tổ chức áp dụng cách tiếp cận “Data Vault logic” thay vì materialize toàn bộ bảng vật lý, nhằm tối ưu chi phí và tốc độ phát triển.
Song song với đó, tự động hóa đang trở thành yếu tố gần như bắt buộc khi triển khai Data Vault ở quy mô lớn. Thay vì thiết kế và viết pipeline thủ công cho từng hub, link, satellite, các doanh nghiệp ưu tiên sử dụng framework hoặc công cụ hỗ trợ để chuẩn hóa mô hình, giảm lỗi và tăng tốc độ delivery. Điều này phản ánh thực tế rằng Data Vault không chỉ là mô hình dữ liệu, mà là một phương pháp luận cần được triển khai có hệ thống.
Một điểm mạnh ngày càng được đánh giá cao của Data Vault là khả năng audit, truy vết nguồn gốc và quản lý lịch sử dữ liệu. Trong các ngành chịu ràng buộc chặt về tuân thủ như tài chính, ngân hàng, bảo hiểm hay y tế, việc lưu lại record source, load date và lịch sử thay đổi giúp Data Vault trở thành nền tảng đáng tin cậy cho governance và compliance.
Tuy nhiên, xu hướng hiện nay cũng cho thấy Data Vault không phải lựa chọn mặc định cho mọi bài toán. Với các hệ thống nhỏ, yêu cầu phân tích đơn giản hoặc đội ngũ chưa có kinh nghiệm, việc triển khai Data Vault có thể gây phức tạp không cần thiết. Do đó, Data Vault ngày càng được xem là giải pháp phù hợp cho hệ thống dữ liệu lớn, nhiều nguồn, thay đổi liên tục và có yêu cầu cao về quản trị, thay vì là mô hình “one-size-fits-all”.
INDA Academy tự hào là đơn vị tiên phong trong việc đào tạo phân tích dữ liệu và AI chuyên sâu, đặc biệt cho khối ngành Ngân hàng – Tài chính – Bảo hiểm tại Việt Nam. Sau hơn 12 năm “thực chiến” cùng những dòng chảy dữ liệu khổng lồ, chúng tôi đã xây dựng nên một hệ sinh thái đào tạo toàn diện, giúp hàng nghìn học viên chuyển mình từ người mới bắt đầu trở thành những chuyên gia lành nghề, sẵn sàng đáp ứng tiêu chuẩn khắt khe của các doanh nghiệp lớn.
Điểm khác biệt lớn nhất tại INDA chính là triết lý đào tạo dựa trên các dự án thực tế (Project-based) và lộ trình cá nhân hóa nhờ ứng dụng AI. Chúng tôi không chỉ dạy bạn cách sử dụng công cụ, mà còn truyền tải tư duy khai phá giá trị từ dữ liệu để đưa ra quyết định kinh doanh chính xác.
Tìm hiểu thêm về các khóa học TẠI ĐÂY:
Môn học DWH/ETL
Lộ trình đào tạo Data Engineer
Lộ trình đào tạo Data Analyst
Lộ trình đào tạo Tester
Khóa học Data Engineer nâng cao – Thực chiến 5 dự án doanh nghiệp
Khóa học Data Analyst nâng cao – Thực chiến 5 dự án doanh nghiệp

Với hơn 15 năm kinh nghiệm trong lĩnh vực Data Engineering, Business Intelligence (BI) và Data Analytics, Ha Vu Phuong không chỉ là một chuyên gia trong ngành mà còn là người tiên phong trong việc triển khai hệ thống dữ liệu lớn cho các ngân hàng và doanh nghiệp tại Việt Nam.