
Last updated on June 11th, 2025 at 10:16 am

Khi chuẩn bị cho một buổi phỏng vấn Data Engineer, việc nắm vững các câu hỏi phổ biến về Python, SQL, và các kiến thức cơ bản về data engineering là vô cùng quan trọng. Những câu hỏi này không chỉ giúp bạn làm quen với các khía cạnh thực tế của công việc mà còn giúp bạn tự tin thể hiện năng lực trước nhà tuyển dụng.
Trong bài viết này, chúng tôi sẽ chia sẻ 22 câu hỏi phỏng vấn Data Engineer 2025 được chọn lọc kỹ lưỡng. Kèm theo đó là những gợi ý hữu ích để bạn sẵn sàng chinh phục cơ hội nghề nghiệp trong lĩnh vực dữ liệu. Cùng tìm hiểu dưới đây nhé!
Tham khảo: Lộ trình đào tạo Data Engineer cam kết việc làm – INDA Academy
Mục lục
Phần 1 – Câu hỏi làm quen cho Data Engineer 2025
1. Điều gì khiến bạn trở thành ứng viên tốt nhất cho vị trí này?
Nếu nhà tuyển dụng đã chọn bạn để phỏng vấn, điều đó cho thấy hồ sơ của bạn có điểm nổi bật. Hãy tự tin trình bày kinh nghiệm làm việc và sự phát triển sự nghiệp của mình.
Hãy nghiên cứu hồ sơ công ty và mô tả công việc trước khi phỏng vấn để hiểu rõ nhà tuyển dụng mong đợi điều gì, từ đó đưa ra câu trả lời phù hợp. Tập trung vào những kỹ năng và kinh nghiệm cụ thể liên quan đến yêu cầu công việc, chẳng hạn như thiết kế và quản lý data pipeline, mô hình hóa dữ liệu, và quy trình ETL. Đừng quên nhấn mạnh sự kết hợp độc đáo giữa kỹ năng, kinh nghiệm, và kiến thức giúp bạn nổi bật hơn các ứng viên khác.
2. Các nhiệm vụ hằng ngày của một Data Engineer là gì?
Dù không có câu trả lời cố định, bạn có thể tham khảo kinh nghiệm từ các công việc trước và mô tả công việc để đưa ra câu trả lời toàn diện. Thông thường, các nhiệm vụ hằng ngày của một Data Engineer bao gồm:
- Phát triển, kiểm thử, và duy trì cơ sở dữ liệu.
- Tạo các giải pháp dữ liệu theo yêu cầu kinh doanh.
- Thu thập và tích hợp dữ liệu.
- Xây dựng và duy trì các data pipeline cho các quy trình ETL, mô hình hóa, chuyển đổi và phục vụ dữ liệu.
- Quản lý và triển khai các mô hình máy học (trong một số trường hợp).
- Đảm bảo chất lượng dữ liệu thông qua làm sạch, kiểm tra và giám sát luồng dữ liệu.
- Cải thiện độ tin cậy, hiệu suất và chất lượng hệ thống.
- Tuân thủ các hướng dẫn về quản trị và bảo mật dữ liệu để đảm bảo tính toàn vẹn và tuân thủ.
3. Bạn thấy điều khó khăn nhất khi làm Data Engineer là gì?
Câu trả lời sẽ phụ thuộc vào kinh nghiệm cá nhân, nhưng những khó khăn phổ biến thường bao gồm:
- Theo kịp tốc độ phát triển công nghệ nhanh chóng và tích hợp các công cụ mới để cải thiện hiệu suất, bảo mật, độ tin cậy và ROI của hệ thống dữ liệu.
- Hiểu và triển khai các quy trình quản trị và bảo mật dữ liệu phức tạp.
- Quản lý kế hoạch phục hồi dữ liệu và đảm bảo tính khả dụng trong các trường hợp khẩn cấp.
- Cân bằng yêu cầu kinh doanh với hạn chế kỹ thuật, đồng thời dự đoán nhu cầu dữ liệu trong tương lai.
- Xử lý hiệu quả lượng dữ liệu lớn và đảm bảo chất lượng, tính nhất quán của dữ liệu.
4. Bạn đã từng sử dụng công cụ hoặc framework nào trong công việc? Bạn thích công cụ nào hơn?
Câu trả lời của bạn sẽ dựa trên kinh nghiệm thực tế. Việc quen thuộc với các công cụ hiện đại sẽ giúp bạn tự tin trả lời câu hỏi này. Bạn có thể đề cập đến các công cụ như:
- Quản lý cơ sở dữ liệu: MySQL, PostgreSQL, MongoDB.
- Kho dữ liệu: Amazon Redshift, Google BigQuery, Snowflake.
- Điều phối dữ liệu: Apache Airflow, Prefect.
- Data pipeline: Apache Kafka, Apache NiFi.
- Quản lý đám mây: AWS, Google Cloud Platform, Microsoft Azure.
- Làm sạch, mô hình hóa và chuyển đổi dữ liệu: pandas, dbt, Spark.
- Xử lý dữ liệu hàng loạt và theo thời gian thực: Apache Spark, Apache Flink.
Hãy nhớ rằng không có câu trả lời đúng hoặc sai; nhà tuyển dụng đang muốn đánh giá kỹ năng và kinh nghiệm của bạn.
5. Làm thế nào bạn cập nhật xu hướng và tiến bộ mới nhất trong ngành Data Engineering?
Câu hỏi này nhằm đánh giá cam kết học hỏi liên tục của bạn.
Bạn có thể đề cập đến việc đăng ký nhận bản tin ngành, theo dõi các blog uy tín, tham gia diễn đàn và cộng đồng trực tuyến, tham dự hội thảo và khóa học trực tuyến. Đừng quên nêu tên một số nguồn hoặc nền tảng cụ thể bạn sử dụng để cập nhật thông tin.
6. Bạn có thể mô tả một lần hợp tác với đội ngũ liên phòng ban để hoàn thành dự án không?
Công việc của một Data Engineer thường yêu cầu làm việc với nhiều nhóm như data scientist, data analyst và nhân viên IT.
Hãy chia sẻ một ví dụ cụ thể, tập trung vào kỹ năng giao tiếp, khả năng hiểu các quan điểm khác nhau, và cách bạn đóng góp vào sự thành công của dự án. Mô tả các thách thức bạn gặp phải và cách bạn vượt qua để đạt được kết quả mong muốn.
Phần 2 – Câu hỏi phỏng vấn kỹ thuật (technical) cho Data Engineer 2025
Data Engineering là một lĩnh vực mang tính kỹ thuật cao, vì vậy không ngạc nhiên khi phần lớn quá trình phỏng vấn của bạn sẽ liên quan đến các câu hỏi và bài tập kỹ thuật. Trong phần này, chúng ta sẽ thảo luận các loại câu hỏi kỹ thuật khác nhau, tập trung vào cấp độ cơ bản, xoay quanh Python và SQL.
7. Bạn có thể giải thích các thiết kế mô hình dữ liệu phổ biến không?
Có ba mô hình thiết kế dữ liệu chính: Star Schema (Mô hình ngôi sao), Snowflake Schema (Mô hình bông tuyết) và Galaxy Schema (Mô hình thiên hà).
- Mô hình ngôi sao: Bao gồm các bảng chiều liên kết với một bảng sự kiện trung tâm. Nó đơn giản, dễ hiểu, phù hợp với các truy vấn đơn giản.
- Mô hình bông tuyết: Là mở rộng của mô hình ngôi sao, với bảng sự kiện và các bảng chiều có thêm các lớp chuẩn hóa, tạo thành cấu trúc như bông tuyết. Nó giúp giảm trùng lặp và cải thiện tính toàn vẹn dữ liệu.
- Mô hình thiên hà: Còn gọi là Fact Constellation Schema, gồm hai hoặc nhiều bảng sự kiện chia sẻ các bảng chiều. Phù hợp với hệ thống cơ sở dữ liệu phức tạp cần nhiều bảng sự kiện.
8. Bạn đã sử dụng những công cụ ETL nào? Công cụ nào bạn thích nhất và vì sao?
Khi trả lời câu hỏi này, hãy đề cập đến các công cụ ETL bạn đã thành thạo và giải thích lý do chọn các công cụ cụ thể cho từng dự án. Thảo luận ưu và nhược điểm của từng công cụ và cách chúng phù hợp với quy trình làm việc của bạn. Một số công cụ ETL mã nguồn mở phổ biến:
- dbt (data build tool): Tốt cho việc biến đổi dữ liệu trong kho dữ liệu bằng SQL.
- Apache Spark: Tuyệt vời cho xử lý dữ liệu lớn và xử lý hàng loạt.
- Apache Kafka: Sử dụng cho các luồng dữ liệu thời gian thực.
- Airbyte: Công cụ tích hợp dữ liệu mã nguồn mở hỗ trợ trích xuất và tải dữ liệu.
Nếu cần làm mới kiến thức về ETL, bạn nên tham khảo khóa học Giới thiệu về Kỹ thuật Dữ liệu.
9. Data orchestration là gì? Bạn sử dụng những công cụ nào để thực hiện nó?
Data orchestration (điều phối dữ liệu) là quy trình tự động để truy cập dữ liệu thô từ nhiều nguồn, thực hiện các bước làm sạch, biến đổi và mô hình hóa, rồi cung cấp dữ liệu cho các nhiệm vụ phân tích. Quá trình này đảm bảo dữ liệu lưu chuyển mượt mà giữa các hệ thống và giai đoạn xử lý.
Một số công cụ phổ biến:
- Apache Airflow: Dùng để lập lịch và giám sát các luồng công việc.
- Prefect: Công cụ hiện đại tập trung vào luồng dữ liệu.
- Dagster: Thiết kế cho các tác vụ dữ liệu phức tạp.
- AWS Glue: Dịch vụ ETL được quản lý, đơn giản hóa việc chuẩn bị dữ liệu cho phân tích.
10. Bạn sử dụng công cụ nào cho kỹ thuật phân tích?
Kỹ thuật phân tích liên quan đến việc biến đổi dữ liệu đã qua xử lý, áp dụng các mô hình thống kê và trực quan hóa chúng qua các báo cáo và bảng điều khiển.
Các công cụ phổ biến cho kỹ thuật phân tích bao gồm:
- dbt (data build tool): Công cụ này được sử dụng để biến đổi dữ liệu trong kho dữ liệu của bạn bằng SQL.
- BigQuery: Kho dữ liệu không máy chủ được quản lý đầy đủ, phục vụ cho phân tích dữ liệu quy mô lớn.
- Postgres: Hệ quản trị cơ sở dữ liệu quan hệ mã nguồn mở mạnh mẽ.
- Metabase: Công cụ mã nguồn mở cho phép bạn đặt câu hỏi về dữ liệu và hiển thị câu trả lời dưới các định dạng dễ hiểu.
- Google Data Studio: Dùng để tạo các bảng điều khiển và báo cáo trực quan.
- Tableau: Nền tảng hàng đầu cho trực quan hóa dữ liệu.
Các công cụ này giúp truy cập, biến đổi và trực quan hóa dữ liệu để rút ra các thông tin có ý nghĩa và hỗ trợ quá trình ra quyết định.
Phần 3 – Câu hỏi phỏng vấn Python cho Data Engineer
Python là ngôn ngữ phổ biến nhất trong kỹ thuật dữ liệu nhờ tính linh hoạt và hệ sinh thái phong phú của các thư viện có sẵn cho xử lý dữ liệu, phân tích và tự động hóa. Dưới đây là một số câu hỏi liên quan đến Python mà bạn có thể gặp phải trong buổi phỏng vấn kỹ sư dữ liệu.
11. Những thư viện Python nào hiệu quả nhất cho việc xử lý dữ liệu?
Các thư viện xử lý dữ liệu phổ biến nhất trong Python bao gồm:
- pandas: Lý tưởng cho việc thao tác và phân tích dữ liệu, cung cấp các cấu trúc dữ liệu như DataFrame.
- NumPy: Cần thiết cho các phép toán số học, hỗ trợ các mảng và ma trận đa chiều lớn.
- Dask: Hỗ trợ tính toán song song và có thể xử lý các phép toán lớn hơn bộ nhớ thông qua cú pháp giống pandas.
- PySpark: API Python cho Apache Spark, hữu ích cho việc xử lý dữ liệu quy mô lớn và phân tích thời gian thực.
Mỗi thư viện này có những ưu điểm và nhược điểm riêng, và sự lựa chọn phụ thuộc vào yêu cầu dữ liệu cụ thể và quy mô của các tác vụ xử lý dữ liệu.
12. Làm thế nào để thực hiện web scraping trong Python?
Web scraping trong Python thường bao gồm các bước sau:
- Truy cập trang web bằng thư viện requests.
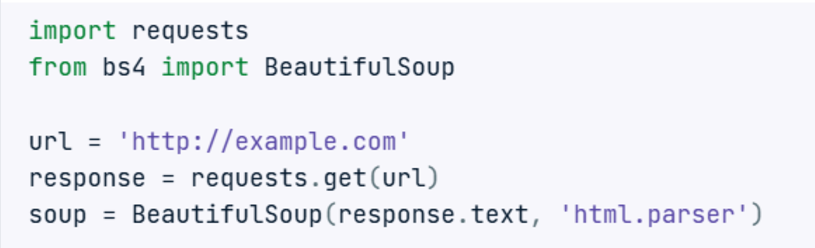
- Trích xuất bảng và thông tin sử dụng thư viện BeautifulSoup.

- Chuyển đổi thông tin thành định dạng có cấu trúc bằng pandas.
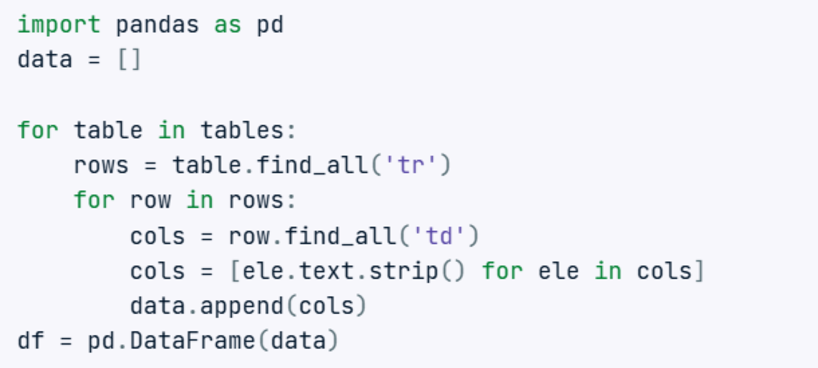
- Làm sạch dữ liệu bằng cách sử dụng pandas và NumPy.

- Lưu trữ dữ liệu dưới dạng tệp CSV.

Trong một số trường hợp, pandas.read_html có thể đơn giản hóa quy trình này bằng cách trực tiếp đọc bảng HTML từ trang web và chuyển đổi chúng thành DataFrame của pandas.

13. Làm thế nào để xử lý các tập dữ liệu lớn trong Python mà không vừa với bộ nhớ?
Xử lý các tập dữ liệu lớn không vừa với bộ nhớ yêu cầu sử dụng các công cụ và kỹ thuật thiết kế cho tính toán ngoài bộ nhớ:
- Dask: Cho phép tính toán song song và làm việc với các tập dữ liệu lớn hơn bộ nhớ thông qua cú pháp tương tự pandas.

- PySpark: Hỗ trợ xử lý dữ liệu phân tán, hữu ích cho việc xử lý dữ liệu quy mô lớn.

- Chia nhỏ dữ liệu với pandas: Đọc các tập dữ liệu lớn theo từng phần.

14. Làm thế nào để đảm bảo mã Python của bạn hiệu quả và tối ưu hóa hiệu suất?
Để đảm bảo mã Python hiệu quả và tối ưu hóa hiệu suất, hãy cân nhắc những thực hành sau:
- Profiling: Sử dụng các công cụ profiling như cProfile, line_profiler, hoặc memory_profiler để xác định các điểm nghẽn trong mã của bạn.

- Vectorization: Sử dụng numpy hoặc pandas cho các phép toán vector thay vì vòng lặp (loops).

- Cấu trúc dữ liệu hiệu quả: Lựa chọn cấu trúc dữ liệu phù hợp (ví dụ: danh sách, tập hợp, từ điển) dựa trên trường hợp sử dụng của bạn.

- Xử lý song song: Sử dụng đa luồng hoặc đa tiến trình cho các tác vụ có thể song song hóa.

- Tránh tính toán dư thừa: Lưu trữ kết quả của các phép toán tốn kém nếu chúng cần được sử dụng lại.

15. Làm thế nào để đảm bảo tính toàn vẹn và chất lượng dữ liệu trong các pipeline dữ liệu của bạn?
Tính toàn vẹn và chất lượng dữ liệu rất quan trọng để đảm bảo sự đáng tin cậy trong kỹ thuật dữ liệu. Các thực hành tốt bao gồm:
- Xác thực dữ liệu (Data validation): Thực hiện các kiểm tra tại các giai đoạn khác nhau trong pipeline dữ liệu để xác nhận định dạng, phạm vi và tính nhất quán của dữ liệu.

- Làm sạch dữ liệu (Data cleaning): Sử dụng các thư viện như pandas để làm sạch và tiền xử lý dữ liệu, bao gồm xử lý các giá trị bị thiếu, loại bỏ bản sao và sửa chữa các lỗi.

- Kiểm thử tự động: Phát triển các bài kiểm tra đơn vị cho các hàm xử lý dữ liệu bằng các framework như pytest.

- Giám sát và cảnh báo: Thiết lập giám sát cho các pipeline dữ liệu của bạn để phát hiện sự bất thường và gửi cảnh báo khi có sự cố về chất lượng dữ liệu.

16. Làm thế nào để xử lý dữ liệu bị thiếu trong các tập dữ liệu của bạn?
Xử lý dữ liệu bị thiếu là một nhiệm vụ phổ biến trong kỹ thuật dữ liệu. Các phương pháp bao gồm:
- Loại bỏ: Loại bỏ các dòng hoặc cột có dữ liệu bị thiếu nếu chúng không quan trọng.

- Điền giá trị: Điền các giá trị thiếu bằng các biện pháp thống kê (trung bình, trung vị) hoặc sử dụng các phương pháp phức tạp hơn như điền giá trị KNN.

- Biến chỉ thị: Thêm một biến chỉ thị để xác định các giá trị bị thiếu.

- Điền giá trị dựa trên mô hình: Sử dụng mô hình dự đoán để ước tính các giá trị bị thiếu.

Phần 4 – Câu hỏi phỏng vấn SQL cho Data Engineer 2025
Lập trình SQL là một phần quan trọng trong quá trình tuyển dụng Data Engineer. Việc thực hành các câu lệnh đơn giản và phức tạp có thể giúp bạn chuẩn bị tốt hơn cho phần đó. Các câu hỏi phỏng vấn có thể yêu cầu bạn viết các truy vấn cho phân tích dữ liệu, các CTE, xếp hạng, thêm tổng phụ và các hàm tạm thời.
17. CTE (Common Table Expressions) là gì trong SQL?
CTE được sử dụng để đơn giản hóa các phép nối phức tạp và chạy các truy vấn con. Chúng giúp các câu truy vấn SQL trở nên dễ đọc và dễ bảo trì hơn. Ví dụ về CTE hiển thị tất cả sinh viên chuyên ngành Khoa học và có điểm A:

Khi bạn sử dụng CTE, câu truy vấn trở nên dễ hiểu hơn:

CTE có thể được sử dụng cho các vấn đề phức tạp hơn và có thể kết hợp nhiều CTE với nhau.
18. Làm thế nào để xếp hạng dữ liệu trong SQL?
Kỹ sư dữ liệu thường xếp hạng các giá trị dựa trên các tham số như doanh thu và lợi nhuận. Hàm RANK() được sử dụng để xếp hạng dữ liệu theo một cột cụ thể:

Ngoài ra, bạn có thể sử dụng DENSE_RANK() mà không bỏ qua các thứ hạng tiếp theo nếu giá trị là giống nhau.
19. Bạn có thể tạo một hàm tạm thời đơn giản và sử dụng nó trong một truy vấn SQL không?
Tương tự như Python, bạn có thể tạo hàm trong SQL để làm cho các truy vấn của bạn trở nên thanh lịch hơn và tránh việc lặp lại các câu lệnh CASE.
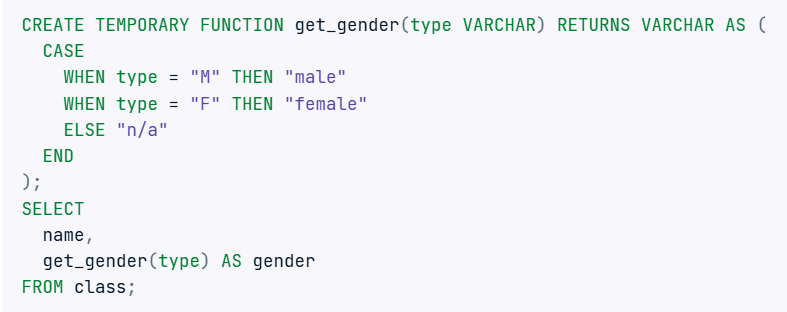
Cách tiếp cận này giúp mã SQL của bạn trở nên gọn gàng và dễ bảo trì.
20. Làm thế nào để thêm subtotal trong SQL?
Việc thêm tổng phụ có thể đạt được bằng cách sử dụng các hàm GROUP BY và ROLLUP(). Ví dụ:
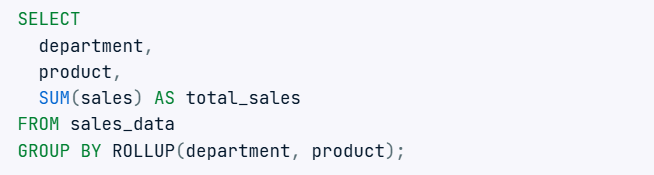
Câu truy vấn này sẽ cung cấp tổng phụ cho mỗi phòng ban và tổng cuối cùng ở cuối.
21. Làm thế nào để xử lý dữ liệu bị thiếu trong SQL?
Xử lý dữ liệu bị thiếu rất quan trọng để duy trì tính toàn vẹn của dữ liệu. Các phương pháp phổ biến bao gồm:
- Sử dụng COALESCE(): Hàm này trả về giá trị không null đầu tiên trong danh sách.

- Sử dụng các câu lệnh CASE: Để xử lý các giá trị thiếu theo điều kiện.

22. Làm thế nào để thực hiện tổng hợp dữ liệu trong SQL?
Tổng hợp dữ liệu bao gồm việc sử dụng các hàm tổng hợp như SUM(), AVG(), COUNT(), MIN() và MAX(). Ví dụ:

Giải quyết các bài tập lập trình SQL là cách tốt nhất để luyện tập và ôn lại các khái niệm đã quên. Bạn có thể đánh giá kỹ năng SQL của mình bằng cách tham gia bài kiểm tra Data Analysis in SQL từ DataCamp (bạn sẽ cần một tài khoản để truy cập bài kiểm tra này).
TẠM KẾT
Chuẩn bị cho phỏng vấn vị trí Data Engineer đòi hỏi bạn phải nắm vững các kiến thức cơ bản về Python, SQL, và các khái niệm quan trọng trong lĩnh vực data engineering. Với 22 câu hỏi phỏng vấn Data Engineer 2025 mà bài viết đã cung cấp, bạn không chỉ làm quen với các dạng câu hỏi thường gặp mà còn tự tin hơn khi đối mặt với nhà tuyển dụng nữa đó.
Để tự tin trở thành một kỹ sư dữ liệu, hãy tham khảo khóa học khóa học Data Engineer Full Track – Cam kết việc làm của chúng tôi nhé! Với
- Giảm 40% học phí khi đăng ký trước 2025
- Lộ trình 7 module cơ bản – nâng cao
- Hoàn thành 8 Project liên quan tới các mảng như: Banking, FMCG, Retails,…
- Ký cam kết đào tạo bằng văn bản, hỗ trợ dấu mộc, làm đồ án, thực tập
- Mentor 1:1, hỗ trợ và 24/7 và cá nhân hóa lộ trình học với từng học viên
- Dự án thực tế từ ngân hàng, doanh nghiệp lớn
- Cam kết thực tập và việc làm sau khi hoàn thành khóa học tại INDA
INDA Academy tự hào sẽ đi cùng bạn trên hành trình xây dựng sự nghiệp Data Engineer như ý.
>> Đọc thêm:
KHOÁ HỌC SQL NÂNG CAO
KHÓA HỌC DATA WAREHOUSE : TỔNG HỢP, CHUẨN HÓA VÀ XÂY DỰNG KHO DỮ LIỆU
KHÓA HỌC DATA MODEL – THIẾT KẾ MÔ HÌNH DỮ LIỆU
LỘ TRÌNH TRỞ THÀNH KỸ SƯ DỮ LIỆU (DATA ENGINEER)
Bài viết liên quan:
 Lợi ích của AI: Khám phá ưu điểm và giá trị mà trí tuệ nhân tạo mang lại
Lợi ích của AI: Khám phá ưu điểm và giá trị mà trí tuệ nhân tạo mang lại
 Hướng dẫn thực hiện quy trình tiền xử lý dữ liệu bằng Python
Các công cụ Data Engineer hàng đầu năm 2025
Top 5 kỹ năng Data Engineer cần biết trong 2025
Lộ trình Data Engineer cam kết việc làm 2025
Hướng dẫn thực hiện quy trình tiền xử lý dữ liệu bằng Python
Các công cụ Data Engineer hàng đầu năm 2025
Top 5 kỹ năng Data Engineer cần biết trong 2025
Lộ trình Data Engineer cam kết việc làm 2025
 Data Engineer là gì? Trở thành Data Engineer cần học gì?
Data Engineer là gì? Trở thành Data Engineer cần học gì?