
AI đang trở thành trọng tâm chiến lược của nhiều doanh nghiệp. Nhưng để AI hoạt động hiệu quả, yếu tố nền tảng quan trọng nhất chính là dữ liệu. Nếu dữ liệu không sạch, không đầy đủ, không được quản lý đúng cách, mọi mô hình AI – dù mạnh đến đâu – cũng sẽ cho ra kết quả sai lệch hoặc không thể triển khai.
Vì vậy, trước khi bước vào hành trình AI, câu hỏi đầu tiên cần trả lời là: Doanh nghiệp đã sẵn sàng về mặt dữ liệu chưa? Và Data Engineer cần làm gì trước khi triển khai AI?
Dưới đây là quy trình chuẩn giúp Data Engineer xây dựng một nền tảng dữ liệu vững chắc để doanh nghiệp có thể triển khai AI thành công.
Mục lục
Kiểm tra chất lượng dữ liệu (Data Quality Audit)
Chất lượng dữ liệu là yếu tố tiên quyết quyết định mô hình AI có hoạt động đúng hay không. Một audit toàn diện sẽ giúp doanh nghiệp biết họ đang sở hữu loại dữ liệu gì và mức độ “sạch” đến đâu.

Những lỗi phổ biến cần kiểm tra:
- Thiếu dữ liệu (missing values)
- Dữ liệu trùng lặp (duplicate records)
- Giá trị bất thường (outliers)
- Sai định dạng (date format, category formatting)
- Không đồng nhất giữa các nguồn
Tools hỗ trợ:
- dbt tests
- Great Expectations
- Soda
- Metaplane
Kết quả mang lại:
- Xác định được dữ liệu sẵn sàng cho AI hay chưa
- Biết rõ phải làm sạch gì trước khi huấn luyện mô hình
- Giảm rủi ro mô hình học sai do dữ liệu lỗi
Nếu dữ liệu bẩn → AI bẩn.
Data Engineer chính là người đầu tiên “lọc nước” trước khi đưa vào mô hình.
Chuẩn hóa dữ liệu (Data Standardization)
Trước khi triển khai AI, dữ liệu phải được chuẩn hóa để đảm bảo tính nhất quán:
Chuẩn hóa gồm những gì?
- Chuẩn hóa tên cột, bảng
- Thống nhất định dạng ngày, số, chuỗi
- Chuẩn hóa đơn vị đo lường (kg, m2, USD…)
- Chuẩn hóa danh mục (category mapping)

Vì sao cần chuẩn hóa?
- Mô hình AI cần dữ liệu đồng nhất để học chính xác
- Giảm lỗi khi kết hợp nhiều nguồn dữ liệu
- Tối ưu pipeline và hạn chế lỗi transform
Ví dụ tình huống thực tế:
Hai hệ thống bán hàng khác nhau ghi dữ liệu sản phẩm theo 2 dạng:
- “SP-001”
- “sp_001”
Nếu không chuẩn hóa, mô hình có thể hiểu đây là 2 sản phẩm khác nhau → sai hoàn toàn.
Xây dựng nguồn dữ liệu tập trung (Single Source of Truth)
AI chỉ hoạt động hiệu quả khi dữ liệu được tổng hợp về một nền tảng duy nhất và nhất quán.
Data Engineer cần làm gì?
- Xây dựng Data Warehouse hoặc Lakehouse
- Gộp dữ liệu từ nhiều nguồn vào cùng cấu trúc
- Loại bỏ sự trùng lặp và mâu thuẫn giữa các hệ thống
- Đảm bảo lineage rõ ràng
Tại sao SSOT quan trọng cho AI?
- Mô hình AI cần dữ liệu đầy đủ và đồng bộ
- Tránh tình trạng “mỗi bộ phận một kiểu dữ liệu”
- Giảm xung đột giá trị, đặc biệt trong dữ liệu giao dịch, khách hàng
Hầu hết các doanh nghiệp thất bại khi triển khai AI không phải do mô hình, mà vì dữ liệu nằm rải rác ở quá nhiều hệ thống.
Làm sạch và tiền xử lý dữ liệu (Data Cleaning & Preprocessing)
Đây là bước tốn thời gian nhất (chiếm 60–80% công sức của dự án AI) nhưng cũng quan trọng nhất.
Các bước preprocessing cần thực hiện:
- Loại bỏ outlier không hợp lý
- Impute giá trị thiếu bằng mean/median/model-based
- Chuẩn hóa dữ liệu dạng numeric
- Encoding dữ liệu dạng categorical
- Remove noise và xử lý dữ liệu text (nếu liên quan đến NLP)
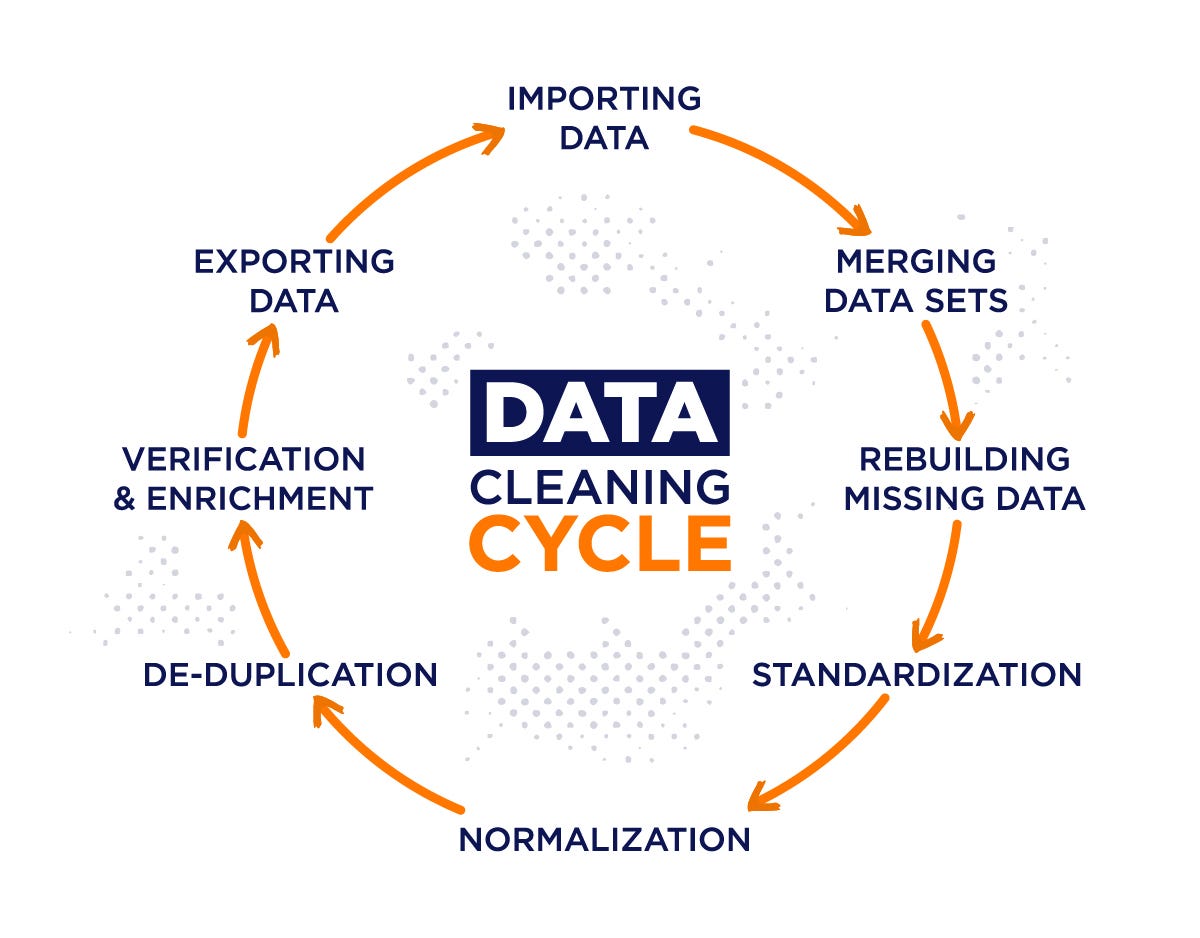
Lợi ích:
- Mô hình AI học nhanh hơn
- Kết quả dự đoán chính xác hơn
- Giảm chi phí compute khi training
Một mô hình AI chỉ tốt bằng chất lượng dữ liệu đưa cho nó.
Thiết lập Data Governance trước khi triển khai AI
AI cần dữ liệu đầy đủ – đúng lúc – đúng quyền. Điều này phụ thuộc vào Data Governance.
Data Engineer phải thiết lập:
- Chính sách quyền truy cập dữ liệu
- Danh mục dữ liệu (data catalog)
- Quy chuẩn lưu trữ & phiên bản
- Quy trình cập nhật dữ liệu
- Quy định bảo mật và tuân thủ (GDPR, PCI, HIPAA)
Công cụ hỗ trợ:
- Collibra
- Alation
- Amundsen
- DataHub
Nếu không có Data Governance, AI có thể truy cập dữ liệu sai hoặc bị vi phạm bảo mật — rủi ro rất lớn.
Xây dựng Data Pipeline ổn định, tự động và incremental
AI chỉ hoạt động tốt khi dữ liệu liên tục được cập nhật. Vì vậy pipeline phải bền vững và tự động.
Data Engineer cần làm gì?
- Bảo đảm pipeline chạy tự động (Airflow, Prefect, Dagster)
- Tối ưu ingest theo dạng incremental thay vì full load
- Xây dựng monitoring & alerting
- Tạo các tầng data rõ ràng: raw → staging → clean → model-ready
Vì sao pipeline quan trọng cho AI?
- Mô hình AI cần dữ liệu mới liên tục
- Tránh tình trạng pipeline lỗi → mô hình không có data để chạy
- Giảm chi phí và minimize công sức vận hành
AI không thể chạy bằng dữ liệu “cũ”. Pipeline chính là mạch máu của hệ thống AI.
Xác định và chuẩn bị tập dữ liệu phục vụ AI (Feature Store)
Đây là giai đoạn nâng cao hơn, giúp AI hoạt động ổn định và tái sử dụng dữ liệu dễ dàng.
Data Engineer cần chuẩn bị:
- Tập hợp các feature quan trọng (feature extraction)
- Chuẩn hóa và lưu trữ chúng trong Feature Store
- Thiết kế sao cho phục vụ cả training & inference
Công cụ phổ biến:
- Feast
- Tecton
- Vertex AI Feature Store (Google)
Lợi ích:
- Feature nhất quán giữa training và production
- Triển khai AI dễ dàng hơn rất nhiều
- Giảm trùng lặp và sai lệch dữ liệu
Đảm bảo bảo mật dữ liệu trước khi đưa vào AI
Bảo mật là ưu tiên hàng đầu vì AI thường sử dụng nhiều dữ liệu nhạy cảm.
Data Engineer cần:
- Mã hóa dữ liệu trong quá trình lưu trữ và truyền tải
- Ẩn danh dữ liệu nhạy cảm (anonymization, tokenization)
- Thiết lập role-based access control (RBAC)
- Chặn dữ liệu không hợp lệ trước khi vào mô hình
![]()
Không ít doanh nghiệp bị rò rỉ dữ liệu từ chính pipeline huấn luyện AI. Đây là rủi ro có thể tránh được nếu Data Engineer thực hiện đúng từ đầu.
Kết luận
Việc chuẩn bị dữ liệu để triển khai AI là bước quan trọng nhất trong toàn bộ quá trình chuyển đổi số. Data Engineer là người đóng vai trò trung tâm, đảm bảo dữ liệu:
- Sạch
- Chuẩn hóa
- Đầy đủ
- Được quản lý chặt chẽ
- Cập nhật liên tục
- An toàn và tuân thủ
Một mô hình AI tốt không thể tồn tại nếu không có nền tảng dữ liệu vững chắc. Khi Data Engineer làm tốt phần chuẩn bị, doanh nghiệp không chỉ tiết kiệm thời gian, giảm chi phí mà còn tăng khả năng triển khai AI thành công ngay từ lần đầu tiên.
INDA Academy là học viện đào tạo Data & AI theo định hướng thực chiến, nơi học viên được học từ chuyên gia đang làm việc trong ngành và phát triển kỹ năng qua các dự án mô phỏng bài toán doanh nghiệp. Với lộ trình cá nhân hoá và phương pháp “học để làm được”, INDA đồng hành cùng bạn từ nền tảng đến nghề nghiệp, giúp bạn tự tin bước vào thị trường Data & AI đầy cạnh tranh.
Tìm hiểu thêm về các khóa học tại đây.
Công ty TNHH Giải pháp Phân tích Dữ liệu Insight Data (INDA) là đơn vị hàng đầu cung cấp các dịch vụ và giải pháp về dữ liệu và trí tuệ nhân tạo (AI). Với chuyên môn sâu trong lĩnh vực Big Data và Data Analytics, chúng tôi cung cấp danh mục dịch vụ toàn diện bao gồm tư vấn và triển khai, thuê ngoài nhân sự IT, đào tạo và cung cấp bản quyền phần mềm.
Tìm hiểu về các dịch vụ của chúng tôi tại đây.


