
Databricks Delta Live Tables đơn giản hóa triệt để việc phát triển quy trình xử lý dữ liệu mạnh mẽ. Bằng cách giảm lượng mã mà các kỹ sư dữ liệu cần viết và duy trì. Và cũng làm giảm nhu cầu bảo trì dữ liệu & vận hành cơ sở hạ tầng. Đồng thời cho phép người dùng quảng bá liền mạch cấu hình mã & đường ống giữa các môi trường.
Trong bài đăng trên blog này, chúng tôi sẽ đề cập đến các mục sau:
- Áp dụng các phương pháp hay nhất của DevOps cho DLT.
- Cấu trúc mã của đường dẫn DLT để hỗ trợ thử nghiệm tích hợp và đơn vị.
- Thực hiện kiểm tra đơn vị các chuyển đổi riêng lẻ của đường dẫn DLT của bạn.
- Thực hiện kiểm tra tích hợp bằng cách thực hiện đường ống DLT đầy đủ.
- Quảng bá tài sản DLT giữa các giai đoạn.
- Kết hợp mọi thứ lại với nhau để tạo thành một quy trình CI/CD (với Azure DevOps làm ví dụ).
Mục lục
Áp dụng các phương pháp DevOps cho Databricks Delta Live Tables: Bức tranh toàn cảnh
Các phương pháp DevOps nhằm mục đích rút ngắn vòng đời phát triển phần mềm (SDLC). Đồng thời cung cấp chất lượng cao. Thông thường, chúng bao gồm các bước dưới đây:
- Kiểm soát phiên bản của mã nguồn & cơ sở hạ tầng.
- Đánh giá mã.
- Tách môi trường (phát triển/dàn dựng/sản xuất).
- Kiểm tra tự động các thành phần phần mềm riêng lẻ & toàn bộ sản phẩm với các bài kiểm tra đơn vị & tích hợp.
- Tích hợp liên tục (thử nghiệm) & triển khai liên tục các thay đổi (CI/CD).
Tất cả các phương pháp này cũng có thể được áp dụng cho các đường ống Databricks Delta Live Tables:
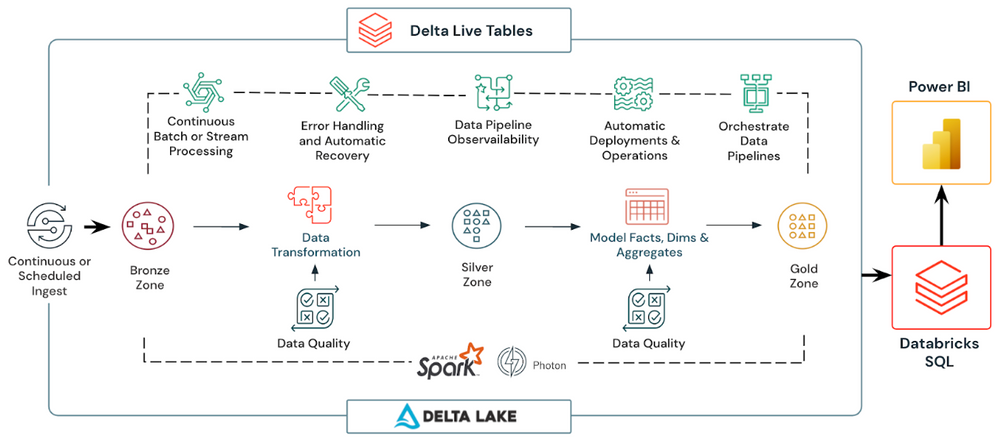
Quy trình phát triển Databricks Delta Live Tables
Để đạt được điều này, chúng tôi sử dụng các tính năng sau của danh mục sản phẩm Databricks:
- Databricks Repos cung cấp giao diện cho các dịch vụ Git khác nhau, vì vậy chúng tôi có thể sử dụng chúng để lập phiên bản mã, tích hợp với hệ thống CI/CD và quảng bá mã giữa các môi trường.
- CLI (hoặc Databricks REST API ) để triển khai các quy trình CI/CD.
- Để triển khai tất cả cơ sở hạ tầng cần thiết và luôn cập nhật sử dụng Databricks Terraform Provider
Quy trình phát triển cấp cao
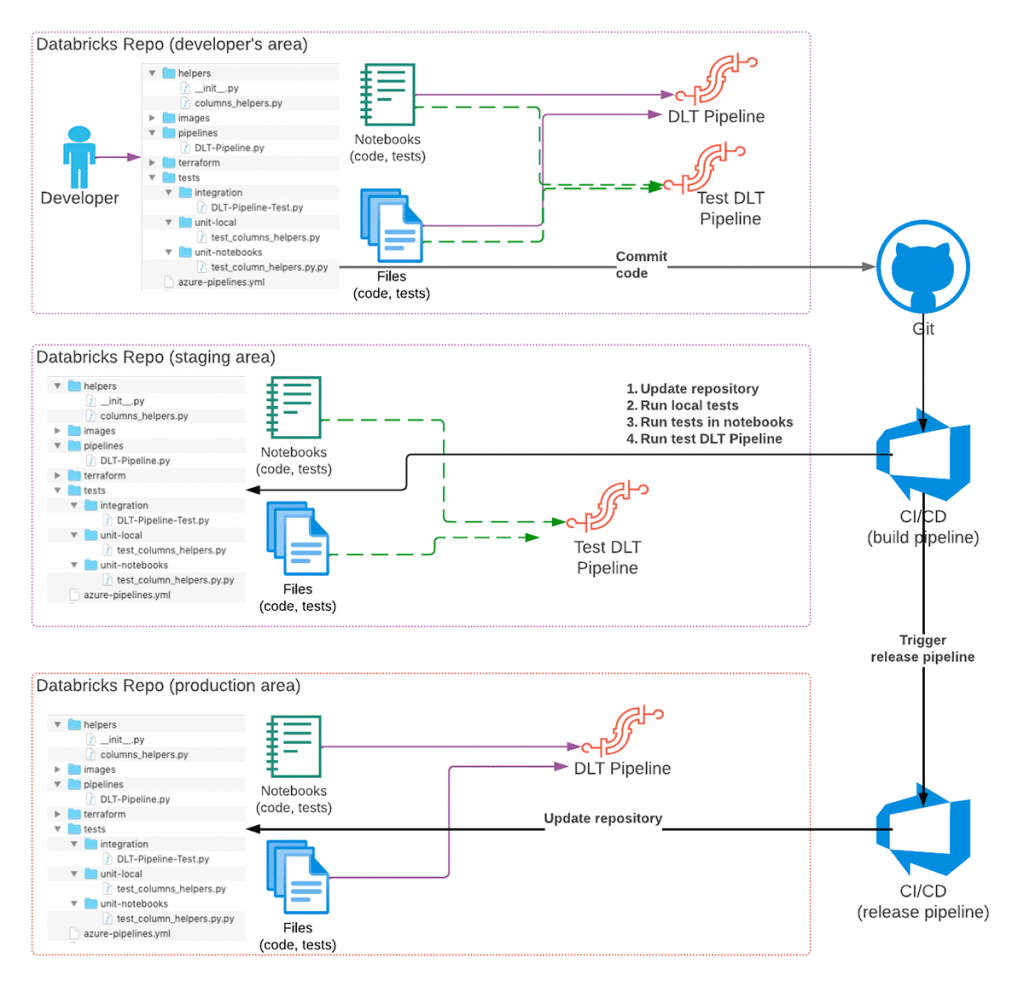
Quy trình phát triển cấp cao được đề xuất của đường ống Databricks Delta Live Tables như sau:
- Một nhà phát triển đang phát triển mã DLT trong kho lưu trữ Git của riêng họ bằng cách sử dụng một nhánh Git riêng để thay đổi.
- Khi mã đã sẵn sàng và được kiểm tra, mã được cam kết với Git và yêu cầu kéo được tạo.
- Hệ thống CI/CD phản ứng với cam kết và bắt đầu quy trình xây dựng (phần CI của CI/CD) sẽ cập nhật Repo Databricks theo giai đoạn với các thay đổi và kích hoạt thực thi các thử nghiệm đơn vị.
Thử nghiệm tích hợp
Theo tùy chọn, các thử nghiệm tích hợp cũng có thể được thực hiện. Mặc dù trong một số trường hợp, điều này chỉ có thể được thực hiện đối với một số nhánh. Hoặc dưới dạng một đường ống riêng biệt.
- Nếu tất cả các thử nghiệm đều thành công và mã được xem xét, các thay đổi sẽ được hợp nhất vào chính (hoặc một nhánh chuyên dụng) của kho lưu trữ Git.
- Việc hợp nhất các thay đổi vào một nhánh cụ thể (ví dụ: bản phát hành) có thể kích hoạt quy trình phát hành (phần CD của CI/CD) sẽ cập nhật Databricks Repo trong môi trường sản xuất, vì vậy các thay đổi về mã sẽ có hiệu lực khi quy trình chạy lần sau.
Để minh họa cho phần còn lại ,ta sẽ sử dụng một đường dẫn Databricks Delta Live Tables. Nó rất đơn giản chỉ bao gồm hai bảng. Chúng minh họa các lớp đồng/bạc điển hình của kiến trúc Lakehouse điển hình . Toàn bộ mã nguồn cùng với hướng dẫn triển khai có sẵn trên GitHub .

Ví dụ đường ống DLT
Lưu ý : DLT cung cấp cả API SQL và Python. Chúng tôi tập trung vào việc triển khai Python. Mặc dù bạn có thể áp dụng hầu hết các phương pháp hay nhất cho các quy trình dựa trên SQL.
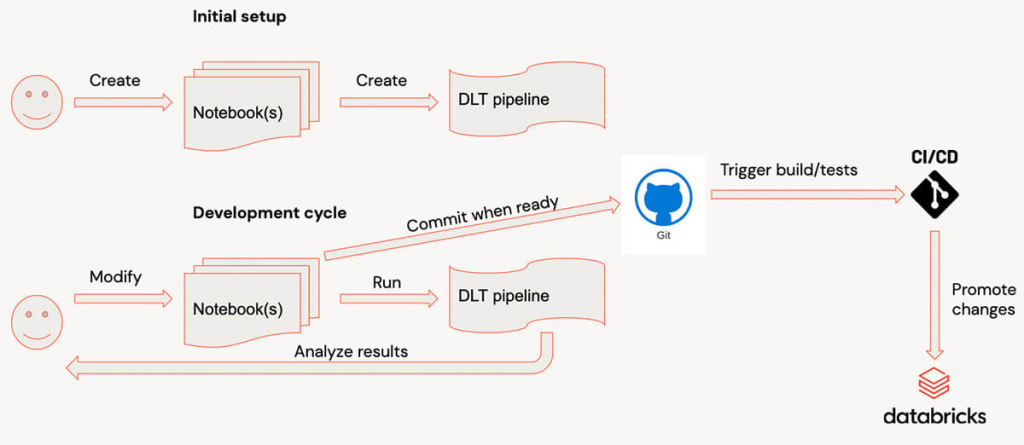
Chu kỳ phát triển với Databricks Delta Live Tables
Khi phát triển với Delta Live Tables, quy trình phát triển điển hình như sau:
- Mã được viết trong (các) sổ ghi chép.
- Khi một đoạn mã khác đã sẵn sàng, người dùng sẽ chuyển sang giao diện người dùng và bắt đầu quy trình. (Để làm cho quá trình này nhanh hơn, bạn nên chạy quy trình trong chế độ Phát triển , vì vậy bạn không cần phải đợi tài nguyên nhiều lần).
- Nếu một quy trình kết thúc hoặc không thành công do lỗi, người dùng sẽ phân tích kết quả và thêm/sửa đổi mã, lặp lại quy trình.
- Khi mã đã sẵn sàng, nó đã được cam kết.
Đối với các quy trình phức tạp, chu kỳ phát triển có thể có chi phí hoạt động đáng kể. Vì việc khởi động quy trình có thể tương đối dài đối với các quy trình phức tạp có hàng chục bảng/khung nhìn và khi có nhiều thư viện được đính kèm. Đối với người dùng, việc nhận phản hồi rất nhanh sẽ dễ dàng hơn bằng cách đánh giá các biến đổi riêng lẻ. Thử nghiệm chúng với dữ liệu mẫu trên các cụm tương tác.
Cấu trúc mã của đường ống Databricks Delta Live Tables
Để có thể đánh giá các chức năng riêng lẻ và làm cho chúng có thể kiểm tra được. Điều rất quan trọng là phải có cấu trúc mã chính xác. Cách tiếp cận thông thường là xác định tất cả các phép biến đổi dữ liệu dưới dạng các hàm riêng lẻ nhận và trả về Spark DataFrames và gọi các hàm này từ các hàm đường ống DLT sẽ tạo thành biểu đồ thực thi Databricks Delta Live Tables.
Sử dụng tệp chức năng repos
Cách tốt nhất để đạt được điều này là sử dụng tệp trong chức năng repos cho phép hiển thị tệp Python dưới dạng mô-đun Python bình thường có thể được nhập vào sổ ghi chép Databricks hoặc mã Python khác.
DLT vốn hỗ trợ các tệp trong repos cho phép nhập tệp Python dưới dạng mô-đun Python. Lưu ý rằng khi sử dụng các tệp trong kho lưu trữ. Hai mục nhập được thêm vào sys.path của Python. Một cho thư mục gốc của kho lưu trữ. Một cho thư mục hiện tại của sổ ghi chép người gọi.
Với điều này, chúng ta có thể bắt đầu viết mã của mình dưới dạng một tệp Python riêng. Nó nằm trong thư mục chuyên dụng bên dưới gốc repos sẽ được nhập dưới dạng mô-đun Python:

Mã nguồn cho một gói Python
Và mã từ gói Python này có thể được sử dụng bên trong mã đường dẫn Databricks Delta Live Tables:
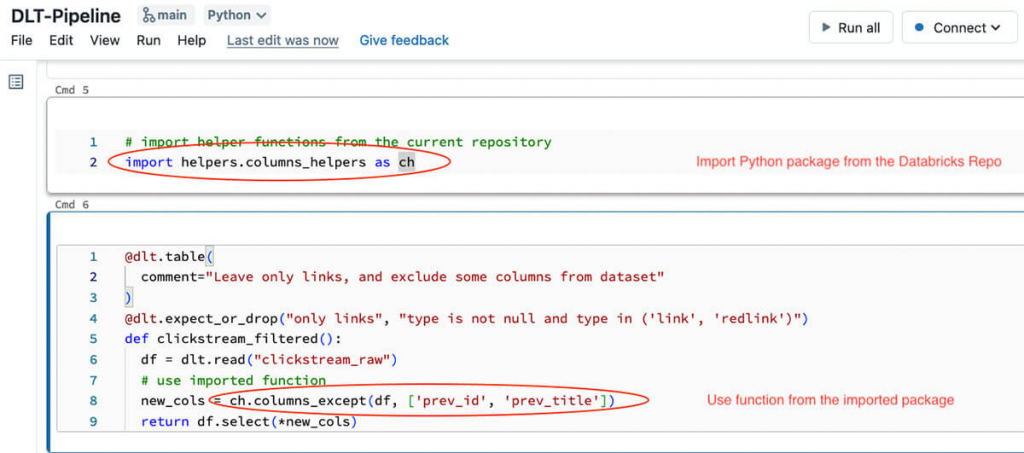
Sử dụng các hàm từ gói Python trong mã DLT
Lưu ý
Chức năng đó trong đoạn mã DLT cụ thể này rất nhỏ. Tất cả những gì nó làm chỉ là đọc dữ liệu từ bảng ngược dòng. Áp dụng phép biến đổi của chúng tôi được xác định trong mô-đun Python. Với cách tiếp cận này, chúng tôi có thể làm cho mã Databricks Delta Live Tables trở nên dễ hiểu. Nó cũng dễ kiểm tra cục bộ hơn. Chúng ta có thể sử dụng một sổ ghi chép riêng được gắn vào một cụm tương tác. Việc tách logic chuyển đổi thành một mô-đun Python riêng biệt cho phép chúng tôi kiểm tra tương tác các phép biến đổi từ sổ ghi chép, viết các bài kiểm tra đơn vị cho các phép biến đổi này và cũng kiểm tra toàn bộ quy trình (chúng ta sẽ nói về thử nghiệm trong các phần tiếp theo).
Bố cục cuối cùng của Databricks Repo, với các bài kiểm tra đơn vị & tích hợp, có thể trông như sau:
Hình: Bố cục mã đề xuất trong Databricks Repos
Cấu trúc mã này đặc biệt quan trọng đối với các dự án lớn hơn có thể bao gồm nhiều đường ống DLT chia sẻ các phép biến đổi chung.
Thực hiện kiểm tra đơn vị
Như đã đề cập ở trên, việc tách các phép biến đổi thành một mô-đun Python riêng biệt cho phép chúng ta viết các bài kiểm tra đơn vị dễ dàng hơn. Với mục đích kiểm tra hành vi của các chức năng riêng lẻ. Chúng ta có một sự lựa chọn để thực hiện các bài kiểm tra đơn vị này:
Chúng ta có thể định nghĩa chúng là các tệp Python có thể được thực thi cục bộ. Chẳng hạn như sử dụng pytest .
Ưu điểm
Cách làm này có những ưu điểm sau:
- chúng ta có thể phát triển và kiểm tra các chuyển đổi này bằng IDE và ví dụ: đồng bộ hóa mã cục bộ với kho lưu trữ Databricks bằng tiện ích mở rộng Databricks cho Visual Studio Code hoặc lệnh đồng bộ hóa dbx nếu bạn sử dụng IDE khác.
- các thử nghiệm như vậy có thể được thực thi bên trong quy trình xây dựng CI/CD mà không cần sử dụng tài nguyên Databricks (mặc dù điều này có thể phụ thuộc vào việc một số chức năng dành riêng cho Databricks có được sử dụng hay mã có thể được thực thi với PySpark ) .
- Bạn có quyền truy cập vào nhiều công cụ liên quan đến phát triển hơn – mã tĩnh và phân tích phạm vi mã, công cụ tái cấu trúc mã, gỡ lỗi tương tác, v.v.
- chúng tôi thậm chí có thể đóng gói mã Python của mình dưới dạng thư viện và đính kèm vào nhiều dự án.
- có thể định nghĩa chúng trong sổ ghi chép – với phương pháp này:
- chúng tôi có thể nhận phản hồi nhanh hơn vì chúng tôi luôn có thể chạy mã mẫu và thử nghiệm một cách tương tác.
- Sử dụng các công cụ bổ sung như Nutter để kích hoạt thực thi sổ ghi chép từ quy trình xây dựng CI/CD (hoặc từ máy cục bộ) và thu thập kết quả để báo cáo.
Chú ý
Kho demo chứa mã mẫu cho cả hai cách tiếp cận này – để thực thi cục bộ các bài kiểm tra và thực hiện các bài kiểm tra dưới dạng sổ ghi chép . Đường ống CI cho thấy cả hai cách tiếp cận.
Xin lưu ý rằng cả hai cách tiếp cận này chỉ áp dụng cho mã Python. Nếu bạn đang triển khai các quy trình DLT của mình bằng SQL. Bạn cần thực hiện theo cách tiếp cận được mô tả trong phần tiếp theo.
Triển khai kiểm thử tích hợp
Mặc dù các thử nghiệm đơn vị đảm bảo cho chúng tôi rằng các chuyển đổi riêng lẻ đang hoạt động như bình thường. Nhưng chúng ta vẫn cần đảm bảo rằng toàn bộ quy trình cũng hoạt động. Thông thường, điều này được triển khai dưới dạng thử nghiệm tích hợp chạy toàn bộ quy trình. Thông thường nó được thực thi trên lượng dữ liệu nhỏ hơn và cần xác thực kết quả thực thi. Với Delta Live Tables, có nhiều cách để triển khai thử nghiệm tích hợp:
- Triển khai nó dưới dạng Quy trình làm việc của Databricks với nhiều tác vụ – tương tự như những gì thường được thực hiện đối với mã không phải DLT.
- Sử dụng kỳ vọng DLT để kiểm tra kết quả của đường ống.
Triển khai các thử nghiệm tích hợp với Databricks Workflows
Trong trường hợp này, chúng tôi có thể triển khai các thử nghiệm tích hợp với Databricks Workflows với nhiều tác vụ (thậm chí chúng tôi có thể chuyển dữ liệu, chẳng hạn như vị trí dữ liệu, v.v. giữa các tác vụ bằng cách sử dụng giá trị tác vụ ). Thông thường, một quy trình làm việc như vậy bao gồm các nhiệm vụ sau:
- Thiết lập dữ liệu cho đường ống DLT.
- Thực hiện đường ống trên dữ liệu này.xác nhận các kết quả sản xuất.
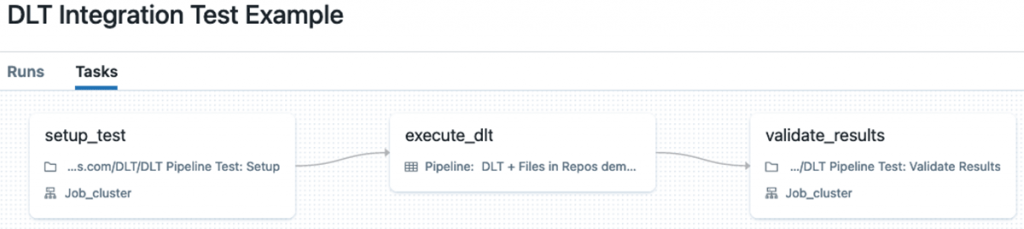
Triển khai thử nghiệm tích hợp với Databricks Workflows
Hạn chế chính của phương pháp này là nó yêu cầu viết một lượng đáng kể mã phụ trợ cho các tác vụ thiết lập và xác thực. Ngoài ra, nó yêu cầu tài nguyên điện toán bổ sung để thực hiện các tác vụ thiết lập và xác thực.
Nguồn: Internet
>>Tìm hiểu thêm các khóa học tại đây!
Bài viết liên quan:
 Triển khai khôi phục Databricks Workspace
Databricks – Bảo mật
Triển khai khôi phục Databricks Workspace
Databricks – Bảo mật
 Azure Databricks – Ví dụ cụ thể về cơ chế xử lý linh động (Kèm Tips)
Danh mục Unity (Unity Catalog) – Mô hình đặc quyền dữ liệu và kiểm soát truy cập
Azure Databricks – Ví dụ cụ thể về cơ chế xử lý linh động (Kèm Tips)
Danh mục Unity (Unity Catalog) – Mô hình đặc quyền dữ liệu và kiểm soát truy cập
 Databricks đã cải thiện hiệu suất truy vấn lên tới 2.2 lần bằng cách nào?
Databricks đã cải thiện hiệu suất truy vấn lên tới 2.2 lần bằng cách nào?
 Databricks Vs Snowflake
Databricks Vs Snowflake