
Last updated on January 12th, 2026 at 02:56 pm
Chọn một ngôn ngữ lập trình giữa hàng chục ngôn ngữ khác trong lĩnh vực Big Data là phụ thuộc rất nhiều vào mục tiêu và từng dự án cụ thể. Tuy nhiên, với bất cứ mục tiêu nào. Khi xem xét chọn một ngôn ngữ lập trình cho dự án phát triển Big Data thì bạn luôn cần nhớ đến Python đầu tiên. Đây là một quyết định quan trọng bởi vì, một khi bạn bắt đầu phát triển dự án của mình bằng ngôn ngữ nào đó, rất khó để di chuyển sang ngôn ngữ khác. Hơn nữa, không phải tất cả các dự án Big Data đều có cùng một mục tiêu.
Ví dụ: Trong một dự án Big Data, mục tiêu có thể chỉ đơn giản là trích xuất dữ liệu hoặc phân tích là xong, trong khi ở các dự án khác có thể là phục vụ cho IOT.
Vì vậy, một ngôn ngữ có thể sử dụng được trong nhiều lĩnh vực kỹ thuật sẽ là một giải pháp nhất quán, phục vụ Big Data tốt hơn. Hôm nay, chúng ta sẽ thảo luận kỹ hơn về một số lý do tại sao Python lại là lựa chọn yêu thích của các Chuyên gia Big Data.

Mục lục
1. Python và Big Data: Sự kết hợp hoàn hảo
Python là ngôn ngữ lập trình có mục đích chung cho phép các lập trình viên viết ít dòng code hơn và dễ đọc hơn. Nó có các tính năng kịch bản và bên cạnh đó sử dụng nhiều thư viện tiên tiến như NumPy, Matplotlib và SciPy… giúp ích cho Khoa học máy tính.
1.1. Mã nguồn mở
Python là ngôn ngữ lập trình nguồn mở được phát triển bằng mô hình dựa trên cộng đồng. Nó có thể chạy trên môi trường Windows và Linux. Ngoài ra, bạn có thể chuyển nó sang các nền tảng khác vì nó hỗ trợ đa nền tảng.
1.2. Thư viện hỗ trợ đa dạng
Python được sử dụng rộng rãi cho Khoa học máy tính trong Học thuật và Ứng dụng trong nhiều ngành công nghiệp. Python có một số lượng lớn các thư viện phân tích được thử nghiệm tốt bao gồm:
- Numerical computing
- Data analysis
- Statistical analysis
- Visualization
- Machine learning
Tính năng của các Thư viện Python
1.3. Tốc độ
Vì Python là ngôn ngữ bậc cao (high – level), nó có nhiều lợi thế giúp tăng tốc dự án. Nó cho phép phác họa ra các ý tưởng, hiện thực hóa nó một cách nhanh chóng trong khi vẫn đảm bảo tính dễ hiểu.
Do tính dễ hiểu của code, việc duy trì và tiếp tục phát triển dự án với nhiều lập trình viên là hoàn toàn khả thi.
1.4. Phạm vi
Python là ngôn ngữ lập trình hướng đối tượng (OOP), nó cũng hỗ trợ các cấu trúc dữ liệu nâng cao như list, sets, tuples, dictionaries và nhiều hơn nữa. Nó hỗ trợ nhiều hoạt động tính toán khoa học như matrix, data frames, v.v.
Những khả năng này trong Python giúp Python tăng cường phạm vi để đơn giản hóa và tăng tốc hoạt động của dữ liệu.
1.5. Hỗ trợ xử lý dữ liệu
Python cung cấp hỗ trợ nâng cao cho dữ liệu hình ảnh và giọng nói do các tính năng sẵn có của nó là hỗ trợ xử lý dữ liệu phi cấu trúc và dữ liệu đặc thù.
Đây là nhu cầu phổ biến trong Big Data khi phân tích dữ liệu trên các mạng xã hội. Đây cũng là một lý do khác để làm cho Python và Big Data trở thành “Sự kết hợp hoàn hảo”.
2. 5 lý tại sao nên chọn Python cho dự án Big data
.jpg)
2.1. Lý do chọn Python cho Big Data
Python được coi là một trong những ngôn ngữ hỗ trợ tốt nhất cho Big Data và Python và Big Data là sự kết hợp hoàn hảo khi có nhu cầu tích hợp giữa phân tích dữ liệu và Ứng dụng web hoặc code thống kê với Cơ sở dữ liệu. Với thư viện tiên tiến hỗ trợ, Python giúp việc thực hiện các thuật toán học máy trở nên đơn giản. Do đó, trong nhiều khía cạnh của Big Data, Python và Big Data bổ sung cho nhau.
2.2. Python có nhiều Package /Thư viện về Khoa học dữ liệu mạnh mẽ
Python có các thư viện mạnh mẽ đáp ứng nhu cầu khoa học dữ liệu và phân tích. Chính điều này đã làm cho nó trở thành lựa chọn phổ biến trong các ứng dụng Big Data. Một số thư viện phổ biến của Python hữu ích cho Big Data là:
- Pandas: Là một thư viện giúp phân tích dữ liệu. Bên cạnh đó, nó cung cấp cấu trúc dữ liệu và các thao tác cần thiết cho thao tác dữ liệu trên chuỗi thời gian và bảng số.
- NumPy: Là package cơ bản của Python giúp tính toán khoa học. Nó cung cấp sự hỗ trợ cho đại số tuyến tính, số ngẫu nhiên, biến đổi Fourier… Ngoài ra, nó hỗ trợ các mảng đa chiều, ma trận với thư viện rộng lớn của các hàm toán học cấp cao.
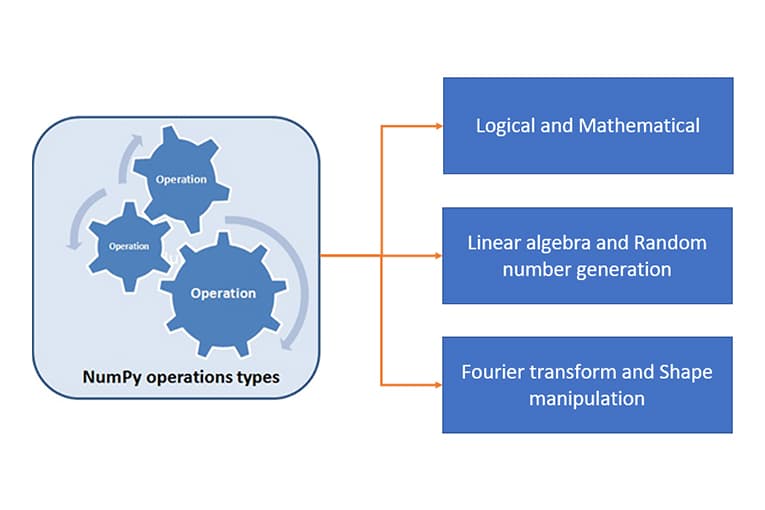
- SciPy: Là một thư viện được sử dụng rộng rãi trong Big Data cho Khoa học máy tính và Kỹ thuật máy tính. SciPy chứa các module khác nhau cho:
- Tối ưu hóa
- Đại số tuyến tính
- Tích phân
- Nội suy
- Chức năng đặc biệt
- FFT
- Xử lý tín hiệu và hình ảnh
- ODE solvers
- Các nhiệm vụ phổ biến khác
- Mlpy: Là một thư viện Học máy hoạt động trên NumPy / SciPy. Mlpy cung cấp nhiều phương thức học máy cho các vấn đề và giúp tìm ra sự hợp lý giữa tính module, khả năng tái tạo, khả năng bảo trì, khả năng sử dụng và sự hiệu quả.
- Matplotlib là một thư viện python giúp vẽ đồ thị 2D cho các định dạng xuất bản bản cứng với môi trường tương tác đa nền tảng. Matplotlib cho phép tạo các ô, biểu đồ thanh, biểu đồ tần suất, biểu đồ lỗi, phổ công suất, biểu đồ phân tán, v.v.
- Theano: Là một thư viện Python để tính toán số học. Nó cho phép tối ưu hóa, xác định và cho phép đánh giá các biểu thức toán học có thể liên quan đến các mảng đa chiều.
- NetworkX: là một thư viện để nghiên cứu các biểu đồ giúp bạn tạo, thao tác và nghiên cứu cấu trúc, linh hoạt và chức năng mạng phức tạp.
- Sympy: Là một thư viện hiệu quả cho tính toán đại số bao gồm các tính năng như:
- Đại số cơ bản
- Giải tích
- Đại số học
- Toán học rời rạc
- Vật lý lượng tử
- Các khả năng đại số của máy tính ở các định dạng khác nhau như là một ứng dụng độc lập hoặc như một thư viện cho các ứng dụng khác hoặc ứng dụng trực tiếp trên web.
- Dask là một thư viện Big Data của Python giúp tính toán song song linh hoạt cho mục đích phân tích. Từ bối cảnh Big Data, nó hoạt động với các bộ sưu tập Big Data như data frames, list và mảng song song hoặc với các vòng lặp Python lớn hơn bộ nhớ trong môi trường phân tán.
- Dmelt hoặc DataMelt là một thư viện hoặc phần mềm dựa trên Python, được sử dụng trong phân tích dữ liệu lớn để tính toán số và phân tích thống kê dữ liệu lớn và trực quan hóa dữ liệu.
- Scikit-learn: Là một thư viện Học máy bổ sung cho NumPy và SciPy thư viện. Nó có các tính năng như:
- Hồi quy
- Các thuật toán phân cụm cho các máy vectơ, gradient boosting, random forests-means và DBSCAN.
- Tương tác với các thư viện Python như NumPy và SciPy.
- TensorFlow: Là một thư viện phần mềm nguồn mở được Python hỗ trợ cho một loạt nhiệm vụ Học máy. Thư viện này có khả năng xây dựng và đào tạo mạng lưới thần kinh để:
- Phát hiện các Pattern
- Giải mã Pattern
- Tương quan
- Phục vụ việc học tập và lý luận.
Với các thư viện Python được đề cập ở trên, các nhà khoa học dữ liệu lớn có cuộc sống dễ dàng hơn nhiêu. Ví dụ, với tích hợp thư viện Python với Spark và Scikit-learn, các nhà khoa học dữ liệu có thể viết code và kiểm tra với các tập dữ liệu nhỏ trước khi nó được triển khai trên cụm Spark.
Khi code được chứng minh và hoạt động như mong muốn, họ có thể thực hiện tương tự trên cụm Spark với một bộ dữ liệu lớn. Điều này giúp thoát khỏi các chu kỳ lặp đi lặp lại và đẩy nhanh quyết định kinh doanh.
Để sử dụng bất kỳ thư viện nào, các bạn chỉ cần lên Google và gõ “Python + [thư viện gì?]”. Đảm bảo hơn 90% bạn sẽ nhận được đầy đủ tài liệu hướng dẫn, ví dụ đi kèm.
2.3. Python kết hợp tốt với Hadoop
Vì Python tương thích với Big Data, Hadoop. Do đó, Python cũng tương thích với Hadoop để làm việc tốt với Big Data.
Python có package Pydoop giúp truy cập API HDFS và cũng viết chương trình MapReduce của Hadoop. Bên cạnh đó, Pydoop cho phép lập trình MapReduce để giải quyết các vấn đề dữ liệu lớn phức tạp với công sức tối thiểu.
2.4. Python là dễ học
Python rất dễ học vì các tính năng của nó đơn giản hóa nhiều thứ trừu tượng. Do đó, lập trình viên cần viết ít dòng code hơn.
Python cho phép bạn có nhiều thời gian vào những thứ phức tạp hơn là gặp rắc rối với vấn đề cơ bản.
Bên cạnh đó, Python có tính năng kịch bản là tốt. Python được kết hợp với các tính năng thân thiện với người dùng như khả năng đọc, cú pháp đơn giản, nhận dạng tự động và liên kết các loại dữ liệu và triển khai dễ dàng.
2.5. Khả năng mở rộng dễ dàng
Khả năng mở rộng rất quan trọng khi bạn đang xử lý dữ liệu lớn. Không giống như các ngôn ngữ khoa học dữ liệu khác như R, MatLab hay Stata, Python nhanh hơn nhiều.
Mặc dù ban đầu tốc độ của python có hơi chậm, tuy nhiên, với Anaconda, hiệu suất tốc độ của nó đã tăng lên rất nhiều. Điều này làm cho Python và Big Data tương thích với nhau với quy mô lớn hơn và linh hoạt hơn.
2.6. Python có cộng đồng hỗ trợ lớn
Phân tích dữ liệu lớn thường xử lý các vấn đề phức tạp và cần nhiều giải pháp / sự hỗ trợ từ cộng đồng.
Python là một ngôn ngữ có một cộng đồng rộng lớn và tích cực giúp các nhà khoa học dữ liệu và lập trình viên có được sự hỗ trợ từ các chuyên gia trên toàn thế giới. Đây là một vòng tuần hoàn đi lên giúp nó tiếp tục phổ biến hơn.
3. Xu hướng Python cho Big Data đến năm 2026
Trong bối cảnh dữ liệu ngày càng đa dạng và phức tạp, Python không chỉ giữ vai trò là ngôn ngữ xử lý Big Data phổ biến, mà còn đang mở rộng sang các lớp giá trị cao hơn như tự động hóa phân tích, machine learning và kiến trúc dữ liệu hiện đại. Đến giai đoạn 2025–2026, xu hướng sử dụng Python cho Big Data có thể nhìn nhận rõ qua một số điểm nổi bật sau.
3.1. Python trở thành “ngôn ngữ cầu nối” giữa Big Data và AI/ML
Thay vì chỉ dùng để xử lý dữ liệu thô, Python ngày càng được sử dụng để xây dựng pipeline dữ liệu hoàn chỉnh, từ thu thập – xử lý – phân tích đến triển khai mô hình machine learning. Các thư viện quen thuộc như pandas, PySpark, scikit-learn hay PyTorch giúp người làm dữ liệu không phải chuyển đổi ngôn ngữ khi bài toán mở rộng sang dự báo, phân loại hoặc tối ưu hoá.
Trong thực tế doanh nghiệp, điều này giúp rút ngắn khoảng cách giữa đội phân tích dữ liệu và đội AI/ML, đồng thời giảm chi phí vận hành hệ thống phân tích dữ liệu lớn.
3.2. Python giữ vai trò trung tâm trong DataOps và MLOps
Một xu hướng rõ rệt khác là việc doanh nghiệp quan tâm nhiều hơn đến tính ổn định và khả năng lặp lại của pipeline Big Data. Python được sử dụng rộng rãi để định nghĩa và vận hành các workflow dữ liệu thông qua các công cụ orchestration như Apache Airflow.
Thay vì xử lý dữ liệu theo cách thủ công, các pipeline Big Data ngày càng được tự động hóa: dữ liệu được kiểm tra, làm sạch, cập nhật và giám sát theo lịch trình. Python đóng vai trò là ngôn ngữ giúp kết nối các bước này thành một quy trình liền mạch, dễ bảo trì và dễ mở rộng.
3.3. Python thích nghi tốt với kiến trúc dữ liệu hiện đại
Các kiến trúc dữ liệu mới như data lakehouse, data mesh hay data fabric đang được nhiều tổ chức áp dụng để giải quyết bài toán dữ liệu phân tán. Trong bối cảnh đó, Python thường được dùng để:
- Kết nối nhiều nguồn dữ liệu khác nhau
- Xây dựng các dịch vụ và API phục vụ phân tích
- Tích hợp với các hệ thống lưu trữ và xử lý dữ liệu lớn trên cloud
Nhờ tính linh hoạt và hệ sinh thái thư viện phong phú, Python phù hợp với cách tiếp cận dữ liệu phân quyền nhưng vẫn đảm bảo khả năng khai thác dữ liệu thống nhất.
3.4. Hỗ trợ ngày càng tốt cho phân tích dữ liệu thời gian thực
Bên cạnh xử lý dữ liệu theo lô (batch processing), nhiều doanh nghiệp bắt đầu chú trọng đến phân tích dữ liệu thời gian thực từ hệ thống giao dịch, hành vi người dùng hoặc IoT. Python tiếp tục được sử dụng như một lớp xử lý và phân tích phía trên các nền tảng streaming.
Xu hướng đến 2026 cho thấy Python không chỉ phục vụ các bài toán Big Data truyền thống, mà còn đóng vai trò quan trọng trong việc kết nối giữa dữ liệu lịch sử và dữ liệu real-time.
3.5. Hệ sinh thái Python tiếp tục là lợi thế cạnh tranh
Một yếu tố khó thay thế của Python trong Big Data chính là cộng đồng và hệ sinh thái. Từ xử lý dữ liệu lớn, phân tích nâng cao đến triển khai trên cloud và container, Python đều có sẵn công cụ và tài liệu hỗ trợ.
Điều này giúp doanh nghiệp và người làm dữ liệu:
- Dễ tiếp cận công nghệ mới
- Dễ mở rộng hệ thống khi nhu cầu tăng
- Dễ đào tạo và chuyển giao kiến thức nội bộ
4. Lời kết
Python và Big Data kết hợp cùng nhau cung cấp khả năng tính toán mạnh mẽ trong nền tảng phân tích dữ liệu lớn. Nếu bạn muốn tham gia các lĩnh vực mang lại lợi thế mạnh mẽ cho trong tương lai thì Python là một lựa chọn hoàn hảo cho sự nghiệp Lập trình viên của bạn. Tuy nhiên, nếu bạn là người mới, đầu tiên hãy học Python cơ bản thật vững chắc rồi mới tính đến việc học Big Data, AI, Machine Learning, Deep Learning…
INDA Academy tự hào là đơn vị tiên phong trong việc đào tạo phân tích dữ liệu và AI chuyên sâu, đặc biệt cho khối ngành Ngân hàng – Tài chính – Bảo hiểm tại Việt Nam. Sau hơn 12 năm “thực chiến” cùng những dòng chảy dữ liệu khổng lồ, chúng tôi đã xây dựng nên một hệ sinh thái đào tạo toàn diện, giúp hàng nghìn học viên chuyển mình từ người mới bắt đầu trở thành những chuyên gia lành nghề, sẵn sàng đáp ứng tiêu chuẩn khắt khe của các doanh nghiệp lớn.
Điểm khác biệt lớn nhất tại INDA chính là triết lý đào tạo dựa trên các dự án thực tế (Project-based) và lộ trình cá nhân hóa nhờ ứng dụng AI. Chúng tôi không chỉ dạy bạn cách sử dụng công cụ, mà còn truyền tải tư duy khai phá giá trị từ dữ liệu để đưa ra quyết định kinh doanh chính xác.
Tìm hiểu thêm về các khóa học TẠI ĐÂY:
Lộ trình đào tạo Data Engineer
Lộ trình đào tạo Data Analyst
Lộ trình đào tạo Tester
Khóa học Data Engineer nâng cao – Thực chiến 5 dự án doanh nghiệp
Khóa học Data Analyst nâng cao – Thực chiến 5 dự án doanh nghiệp
Nguồn: Internet – Thangtn
Bài viết liên quan:
 Hướng Dẫn Học Python Trong 30 Ngày: Lộ Trình Chi Tiết Cho Người Mới Bắt Đầu
Python – Ưu điểm và nhược điểm nhìn từ trải nghiệm thực tế (Cập nhật 2026)
Danh sách chứng chỉ lập trình Python mới nhất 2022
Phân tích dữ liệu với Python: 4 bước đơn giản
Thiết lập tự động hóa Python Excel: 5 bước đơn giản
Tích hợp Power BI Python
Hướng Dẫn Học Python Trong 30 Ngày: Lộ Trình Chi Tiết Cho Người Mới Bắt Đầu
Python – Ưu điểm và nhược điểm nhìn từ trải nghiệm thực tế (Cập nhật 2026)
Danh sách chứng chỉ lập trình Python mới nhất 2022
Phân tích dữ liệu với Python: 4 bước đơn giản
Thiết lập tự động hóa Python Excel: 5 bước đơn giản
Tích hợp Power BI Python