

Khi hệ thống dữ liệu phát triển từ một vài script đơn lẻ thành một mạng lưới chằng chịt các luồng ingestion, transformation và data warehouse, việc quản lý sự thay đổi trở thành một bài toán đau đầu. Bạn đã bao giờ trải qua cảm giác “thót tim” khi vừa cập nhật một đoạn code SQL trên môi trường production và cầu nguyện rằng nó không làm sập toàn bộ hệ thống analytics của công ty?
Deploy thủ công không chỉ là nguồn cơn của những lỗi sơ đẳng mà còn là rào cản lớn nhất ngăn cản sự linh hoạt của một đội ngũ dữ liệu. Đây chính là lúc CI/CD pipeline – “vương miện” của văn hóa DevOps – bước chân vào thế giới của Data Engineering để thiết lập một tiêu chuẩn mới về sự an toàn và tốc độ.
Mục lục
1. CI/CD Pipeline là gì? Khi tự động hóa trở thành tiêu chuẩn
Trong phát triển phần mềm hiện đại, CI/CD (Continuous Integration / Continuous Deployment) là một chu trình tự động hóa giúp các thay đổi về mã nguồn được kiểm thử và triển khai một cách liên tục. Thay vì gom một lượng lớn tính năng rồi mới “phát hành” một lần, CI/CD khuyến khích việc tích hợp các thay đổi nhỏ, thường xuyên để giảm thiểu rủi ro.
Cơ chế hoạt động của một CI/CD Pipeline
Một chu trình cơ bản thường diễn ra theo trình tự:
- Commit: Data Engineer đẩy code mới vào hệ thống quản lý phiên bản (Git).
- Test: Hệ thống tự động kích thực các bài kiểm tra để xác minh tính đúng đắn của code.
- Build: Đóng gói các thành phần thành các gói có thể triển khai (ví dụ: Docker Image).
- Deploy: Tự động đưa mã nguồn đã qua kiểm duyệt lên môi trường staging hoặc production.
Sự khác biệt giữa Software Engineering và Data Engineering
Dù có chung triết lý, nhưng việc áp dụng CI/CD cho dữ liệu có những sắc thái rất riêng. Nếu như trong Software Engineering, bạn tập trung vào việc deploy một ứng dụng (Application), thì trong Data Engineering, đối tượng chính là các Data Pipelines.
Thay vì chỉ kiểm tra logic code, Data Engineer còn phải đối mặt với việc kiểm tra tính toàn vẹn của dữ liệu (Data Quality) và cấu trúc bảng (Schema). Nếu code chạy đúng nhưng dữ liệu đầu vào bị sai, toàn bộ hệ thống vẫn thất bại. Đây chính là lý do khiến CI/CD trong dữ liệu trở nên phức tạp và thú vị hơn rất nhiều.
2. Tại sao Data Pipeline không thể sống thiếu CI/CD?
Việc duy trì một hệ thống dữ liệu theo cách truyền thống giống như việc lái xe mà không có dây an toàn. CI/CD cung cấp cho bạn lớp bảo vệ đó thông qua 4 lợi ích cốt lõi:
Tăng tốc độ triển khai (Velocity): Thay vì mất cả buổi để cấu hình thủ công, kiểm tra từng dòng SQL trên môi trường thật, bạn chỉ cần một lệnh git push. Toàn bộ quy trình còn lại sẽ được máy móc thực hiện, giúp rút ngắn thời gian từ lúc có ý tưởng đến lúc dữ liệu sẵn sàng trên Dashboard.
Giảm thiểu lỗi Production: Những lỗi như thiếu dấu phẩy trong SQL, sai tên cột, hay logic tính toán doanh thu bị nhầm lẫn sẽ được phát hiện ngay từ bước Automated Testing. Dữ liệu sai lệch thường gây hậu quả nghiêm trọng hơn một ứng dụng bị sập, vì nó dẫn đến các quyết định kinh doanh sai lầm.
Chuẩn hóa workflow phát triển: CI/CD buộc mọi thành viên trong team phải tuân thủ một quy trình duy nhất. Điều này loại bỏ tình trạng “trên máy tôi chạy bình thường” – cơn ác mộng của mọi dự án kỹ thuật.
Hỗ trợ làm việc nhóm (Collaboration): Khi nhiều Engineer cùng tác động vào một pipeline, hệ thống Version Control và CI/CD sẽ đóng vai trò trọng tài, đảm bảo các thay đổi không xung đột và luôn giữ cho mã nguồn ở trạng thái “sẵn sàng triển khai”.
3. Các thành phần không thể tách rời của CI/CD cho dữ liệu
Để xây dựng một hệ thống CI/CD hoàn chỉnh, bạn cần lắp ghép các “mảnh ghép” công nghệ một cách đồng bộ:
3.1. Version Control – Gốc rễ của mọi thay đổi
Tất cả code xử lý dữ liệu, cấu hình pipeline phải được lưu trữ tại Git (GitHub, GitLab hoặc Bitbucket). Đây là “nguồn sự thật” duy nhất (Single Source of Truth). Nếu nó không nằm trong Git, nó không tồn tại.
3.2. Continuous Integration (CI) – Bộ lọc chất lượng
Mỗi khi có code mới, hệ thống CI (như GitHub Actions hoặc Jenkins) sẽ tự động chạy các script kiểm tra. Trong Data Engineering, bước này bao gồm:
- Unit Tests: Kiểm tra các hàm xử lý Python/Scala đơn lẻ.
- SQL Linting: Đảm bảo code SQL tuân thủ chuẩn định dạng.
- Data Quality Tests: Sử dụng các tool như dbt để kiểm tra tính duy nhất (Unique), không rỗng (Not Null) của dữ liệu mẫu.
3.3. Continuous Deployment (CD) – Cánh cửa ra thế giới
Khi code đã vượt qua “vòng gửi xe” của CI, hệ thống CD sẽ đảm nhiệm việc cập nhật các thành phần trên môi trường vận hành. Ví dụ: tự động cập nhật các file DAG trên Apache Airflow hoặc cập nhật các model trong dbt Cloud.
3.4. Monitoring và Alerting – Con mắt canh gác
CI/CD không kết thúc sau khi deploy. Hệ thống cần giám sát xem pipeline mới có chạy ổn định không, hiệu suất có bị sụt giảm không và sẵn sàng bắn cảnh báo nếu có sự cố xảy ra ngay lập tức.
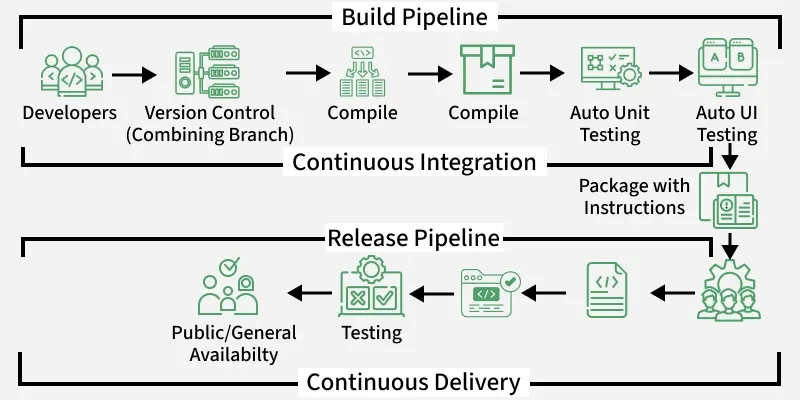
4. Workflow triển khai Data Pipeline tự động hóa
Hãy cùng đi sâu vào một quy trình thực tế mà các chuyên gia dữ liệu thường áp dụng để biến một ý tưởng thành dữ liệu trên kho:
- Lập trình và Thử nghiệm cục bộ: Engineer viết code biến đổi dữ liệu bằng SQL hoặc Python, sử dụng các môi trường phát triển riêng biệt để không ảnh hưởng đến dữ liệu chung.
- Commit và Push: Code được đẩy lên một nhánh (branch) mới trên Git.
- Kích hoạt CI Pipeline: Ngay lập tức, GitHub Actions sẽ khởi tạo một môi trường tạm thời (Container), cài đặt các thư viện cần thiết và chạy toàn bộ bộ test. Nếu một bài test thất bại, quy trình dừng lại và báo lỗi cho Engineer.
- Code Review: Sau khi CI báo xanh, các thành viên khác trong team sẽ vào kiểm tra code để đảm bảo logic nghiệp vụ chính xác.
- Build Artifacts: Hệ thống đóng gói code thành các Docker Image hoặc các file nén sẵn sàng để thực thi.
- Deployment: Hệ thống tự động đẩy các gói này lên môi trường Staging để kiểm tra cuối cùng với dữ liệu thật, sau đó mới đưa lên Production.
5. Ví dụ thực tế: Bộ ba Airflow – dbt – Snowflake
Giả sử doanh nghiệp của bạn đang sử dụng Snowflake làm Data Warehouse, dbt để biến đổi dữ liệu và Airflow để điều phối (Orchestration). Một quy trình CI/CD lý tưởng sẽ trông như sau:
- Khi một Engineer cập nhật một model tính toán lợi nhuận trong dbt, họ push code lên GitHub.
- GitHub Actions sẽ khởi tạo một schema tạm thời trên Snowflake (ví dụ: ci_schema_123).
- Nó chạy lệnh dbt build trên schema này để đảm bảo code SQL không bị lỗi cú pháp và các bài test chất lượng dữ liệu đều vượt qua.
- Sau khi thành công, GitHub Actions sẽ gọi API của Airflow để cập nhật file DAG mới nhất, đảm bảo lịch trình chạy hàng ngày sẽ sử dụng logic tính toán lợi nhuận mới vừa được duyệt.
6. Best Practices để CI/CD không trở thành gánh nặng
Triển khai CI/CD là một nghệ thuật cân bằng. Nếu làm quá sơ sài, bạn sẽ gặp lỗi; nếu làm quá phức tạp, bạn sẽ làm chậm tốc độ của team.
Tách biệt tuyệt đối các môi trường: Bạn cần ít nhất 3 môi trường: Dev (để nghịch), Staging (giống hệt Production nhưng dữ liệu ít hơn) và Production (nơi dữ liệu phục vụ kinh doanh). Tuyệt đối không bao giờ được phép dùng CI/CD để deploy thẳng từ máy cá nhân lên Production mà không qua Staging.
Ưu tiên Automated Testing: Một CI/CD pipeline mà không có test thì chỉ là một cách để bạn deploy lỗi nhanh hơn mà thôi. Hãy tập trung vào Data Quality Checks – đây là xương sống của sự tin cậy trong dữ liệu.
Infrastructure as Code (IaC): Đừng chỉ deploy code pipeline, hãy deploy cả hạ tầng (như tạo bảng, cấp quyền truy cập database) bằng code thông qua các công cụ như Terraform. Điều này giúp bạn có thể tái tạo lại toàn bộ hệ thống dữ liệu từ con số 0 chỉ trong vài phút.
7. Thách thức: “Con đường không trải hoa hồng”
Dù mang lại lợi ích khổng lồ, nhưng việc triển khai CI/CD cho dữ liệu vẫn vấp phải những rào cản đặc thù:
- Sự phụ thuộc dữ liệu (Data Dependencies): Pipeline của bạn có thể chạy đúng, nhưng nếu một pipeline khác cung cấp dữ liệu đầu vào bị lỗi, hệ thống của bạn cũng sẽ sai theo. Việc quản lý sự phụ thuộc này trong CI/CD đòi hỏi tư duy hệ thống rất cao.
- Dữ liệu thử nghiệm: Việc tạo ra một tập dữ liệu mẫu (Sample Data) đủ tốt để chạy test mà không vi phạm các quy định bảo mật (như GDPR hay PII) là một bài toán hóc búa.
- Chi phí tài nguyên: Việc chạy các pipeline CI/CD trên các nền tảng Cloud Warehouse lớn như Snowflake hay BigQuery có thể tiêu tốn rất nhiều tiền nếu không được tối ưu hóa.
8. Kết luận
CI/CD cho Data Pipelines không còn là một lựa chọn “có thì tốt”, mà đã trở thành một kỹ năng bắt buộc đối với bất kỳ đội ngũ dữ liệu nào muốn hướng tới sự chuyên nghiệp và ổn định. Bằng cách tự động hóa quy trình kiểm thử và triển khai, bạn không chỉ giải phóng các Data Engineer khỏi những tác vụ thủ công nhàm chán mà còn xây dựng được một nền tảng dữ liệu vững chắc, nơi mọi thay đổi đều được kiểm soát và mọi sự cố đều có thể dự báo.
Hãy bắt đầu từ những bước nhỏ nhất: đưa code vào Git, viết bài unit test đầu tiên và tự động hóa việc deploy lên môi trường Dev. Thành quả bạn nhận lại sẽ là sự tự tin tuyệt đối mỗi khi nhấn nút deploy và sự hài lòng từ phía doanh nghiệp khi dữ liệu luôn chính xác và đúng hạn.
FAQ (Những câu hỏi thường gặp)
CI/CD pipeline có làm chậm tốc độ phát triển không?
Trong ngắn hạn, bạn sẽ mất thời gian để xây dựng hệ thống. Nhưng trong dài hạn, nó giúp bạn tránh được hàng giờ (thậm chí hàng ngày) đi sửa lỗi trên Production. CI/CD chính là “lùi một bước để tiến ba bước”.
Tôi nên bắt đầu từ đâu nếu team chưa có gì?
Hãy bắt đầu với Version Control (Git). Sau đó, hãy tích hợp một công cụ kiểm tra chất lượng dữ liệu đơn giản như dbt tests. Khi team đã quen với việc chạy test, hãy tiến tới tự động hóa việc deploy bằng GitHub Actions.
CI/CD có tốn nhiều chi phí không?
Chi phí lớn nhất thường nằm ở tài nguyên tính toán khi chạy test trên Warehouse. Bạn có thể tối ưu bằng cách chỉ chạy test trên các tập dữ liệu nhỏ (sampling) và chỉ chạy CI khi thực sự cần thiết (ví dụ: khi mở Pull Request).
INDA Academy tự hào là đơn vị tiên phong trong việc đào tạo phân tích dữ liệu và AI chuyên sâu, đặc biệt cho khối ngành Ngân hàng – Tài chính – Bảo hiểm tại Việt Nam. Sau hơn 12 năm “thực chiến” cùng những dòng chảy dữ liệu khổng lồ, chúng tôi đã xây dựng nên một hệ sinh thái đào tạo toàn diện, giúp hàng nghìn học viên chuyển mình từ người mới bắt đầu trở thành những chuyên gia lành nghề, sẵn sàng đáp ứng tiêu chuẩn khắt khe của các doanh nghiệp lớn.
Điểm khác biệt lớn nhất tại INDA chính là triết lý đào tạo dựa trên các dự án thực tế (Project-based) và lộ trình cá nhân hóa nhờ ứng dụng AI. Chúng tôi không chỉ dạy bạn cách sử dụng công cụ, mà còn truyền tải tư duy khai phá giá trị từ dữ liệu để đưa ra quyết định kinh doanh chính xác.
Tìm hiểu thêm về các khóa học TẠI ĐÂY:
Lộ trình đào tạo Data Engineer
Lộ trình đào tạo Data Analyst
Lộ trình đào tạo Tester
Khóa học Data Engineer nâng cao – Thực chiến 5 dự án doanh nghiệp
Khóa học Data Analyst nâng cao – Thực chiến 5 dự án doanh nghiệp
Bài viết liên quan:
 Docker for Data Pipelines: Chuẩn hóa môi trường và tối ưu hóa triển khai trong Data Engineering
Docker for Data Pipelines: Chuẩn hóa môi trường và tối ưu hóa triển khai trong Data Engineering
 Data Pipeline Testing: Chiến lược kiểm thử để bảo vệ “mạch máu” dữ liệu doanh nghiệp
Data Pipeline Testing: Chiến lược kiểm thử để bảo vệ “mạch máu” dữ liệu doanh nghiệp
 Data Pipeline Debugging: Nghệ Thuật Tìm Root Cause Khi Hệ Thống Dữ Liệu “Gãy Đổ”
Data Pipeline Debugging: Nghệ Thuật Tìm Root Cause Khi Hệ Thống Dữ Liệu “Gãy Đổ”
 Data Incident Management: Khi Dashboard không còn nói lời thật lòng
Data Incident Management: Khi Dashboard không còn nói lời thật lòng
 Data Pipeline Thực Tế: Cách Doanh Nghiệp Xử Lý Dữ Liệu Từ A-Z
Data Pipeline Thực Tế: Cách Doanh Nghiệp Xử Lý Dữ Liệu Từ A-Z
 Late-arriving Data: Khi dữ liệu “đi lạc” và bài toán về tính chính xác trong Data Warehouse
Late-arriving Data: Khi dữ liệu “đi lạc” và bài toán về tính chính xác trong Data Warehouse