

Bạn đã bao giờ tự hỏi: Tại sao một đơn hàng vừa được bấm “Thanh toán” trên ứng dụng điện thoại lại có thể xuất hiện trên Dashboard của Giám đốc tài chính vào sáng hôm sau? Đằng sau khoảnh khắc “kỳ diệu” đó là cả một hệ thống chằng chịt các đường ống dẫn dữ liệu, nơi mà các dòng code SQL, Python và các công cụ Cloud phối hợp với nhau không nghỉ. Đó chính là Data Pipeline.
Thế nhưng, có một sự thật phũ phàng: Data Pipeline thực tế ngoài doanh nghiệp không hề “sạch sẽ” như trong các khóa học ETL cơ bản. Nó đầy rẫy những lỗi kết nối API, dữ liệu bị trùng lặp, sai định dạng ngày tháng, hoặc tệ hơn là nguồn dữ liệu đột ngột thay đổi cấu trúc mà không báo trước. Bài viết này không đi sâu vào định nghĩa lý thuyết suông, mà sẽ mô phỏng một quy trình triển khai thực chiến để bạn hiểu cách dữ liệu thực sự “chảy” trong doanh nghiệp.
Mục lục
1. Bản Chất Của Data Pipeline: Không Chỉ Là Những Bước Đi
Về mặt kỹ thuật, một hệ thống dẫn dữ liệu thường được hiểu là quy trình chuyển chuyển dữ liệu từ điểm A đến điểm B và biến đổi nó trên đường đi. Tuy nhiên, trong thực tế triển khai, Data Pipeline được ví như một hệ thống tuần hoàn. Nếu hệ thống này “tắc nghẽn”, toàn bộ báo cáo của công ty sẽ bị sai lệch, dẫn đến những quyết định kinh doanh sai lầm trị giá hàng tỷ đồng.
Một Data Pipeline thực tế thường bao gồm bốn giai đoạn xương sống:
- Ingestion (Thu thập): Gom dữ liệu thô từ API, Database, hoặc các file phẳng.
- Processing (Xử lý): Làm sạch, chuẩn hóa và lọc bỏ những “rác” dữ liệu.
- Storage (Lưu trữ): Đổ dữ liệu đã tinh chế vào các kho chứa hiện đại (Data Warehouse).
- Serving (Phục vụ): Kết nối kho chứa với các công cụ phân tích hoặc Dashboard.
Điểm khác biệt lớn nhất giữa một chuyên gia và một người mới học chính là cách họ xử lý các vấn đề phát sinh ở từng bước này. Pipeline không phải là một chuỗi các bước chạy một lần là xong, mà là một thực thể sống cần được giám sát (Monitoring) liên tục.
2. Case Study Xuyên Suốt: Hệ Thống Báo Cáo Cho Doanh Nghiệp E-commerce
Để dễ hình dung, hãy lấy ví dụ về một công ty thương mại điện tử tầm trung. Mục tiêu của họ là theo dõi doanh thu theo thời gian thực (hoặc theo ngày) để tối ưu hóa chi phí quảng cáo. Tuy nhiên, dữ liệu của họ không nằm tập trung một chỗ:
- Dữ liệu đơn hàng nằm ở Database hệ thống (MySQL).
- Dữ liệu khách hàng và tư vấn nằm ở phần mềm CRM (Hubspot/Salesforce).
- Chi phí quảng cáo nằm ở API của Facebook Ads và Google Ads.
Thử thách đặt ra là làm sao để kéo tất cả đống dữ liệu “tam sao thất bản” này về một nơi, trộn chúng lại và tạo ra một báo cáo: “Hôm nay bỏ ra 10 triệu tiền Ads thì thu về bao nhiêu đơn hàng và lợi nhuận thực tế là bao nhiêu?”. Đây chính là lúc Data Pipeline thực tế thể hiện vai trò của mình.
3. Giai Đoạn 1: Thu Thập Dữ Liệu (Data Ingestion) – Khi API Không Phải Là Màu Hồng
Bước đầu tiên của Pipeline là Ingestion. Trong lý thuyết, bạn chỉ cần kết nối và tải dữ liệu về. Nhưng trong thực tế, đây là giai đoạn “đau đầu” nhất. API của các nền tảng quảng cáo có thể bị giới hạn số lượng yêu cầu (Rate limit), hoặc đột ngột thay đổi phiên bản khiến code của bạn bị lỗi.
Một quyết định kỹ thuật quan trọng ở đây là chọn giữa Batch Processing (Xử lý theo lô) hay Real-time (Thời gian thực). Đối với phần lớn doanh nghiệp nhỏ và vừa, xử lý theo lô (ví dụ: cứ 1 tiếng hoặc 1 ngày chạy một lần) là lựa chọn tối ưu vì chi phí rẻ và dễ quản lý. Chỉ những hệ thống cực kỳ đặc thù như phát hiện gian lận ngân hàng hay sàn chứng khoán mới thực sự cần đến Pipeline thời gian thực.
Trong Case Study của chúng ta, đội ngũ kỹ sư dữ liệu sẽ thiết lập các Job tự động để mỗi đêm, hệ thống tự động gọi vào các API và “kéo” dữ liệu thô về một vùng đệm (Staging Area).
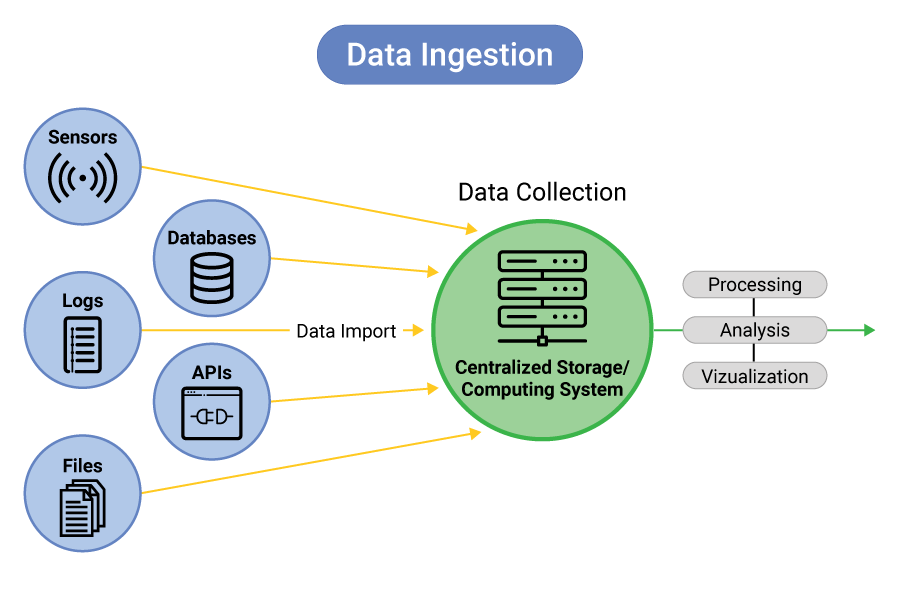
4. Giai Đoạn 2: Làm Sạch & Chuẩn Hóa Dữ Liệu (Data Cleaning)
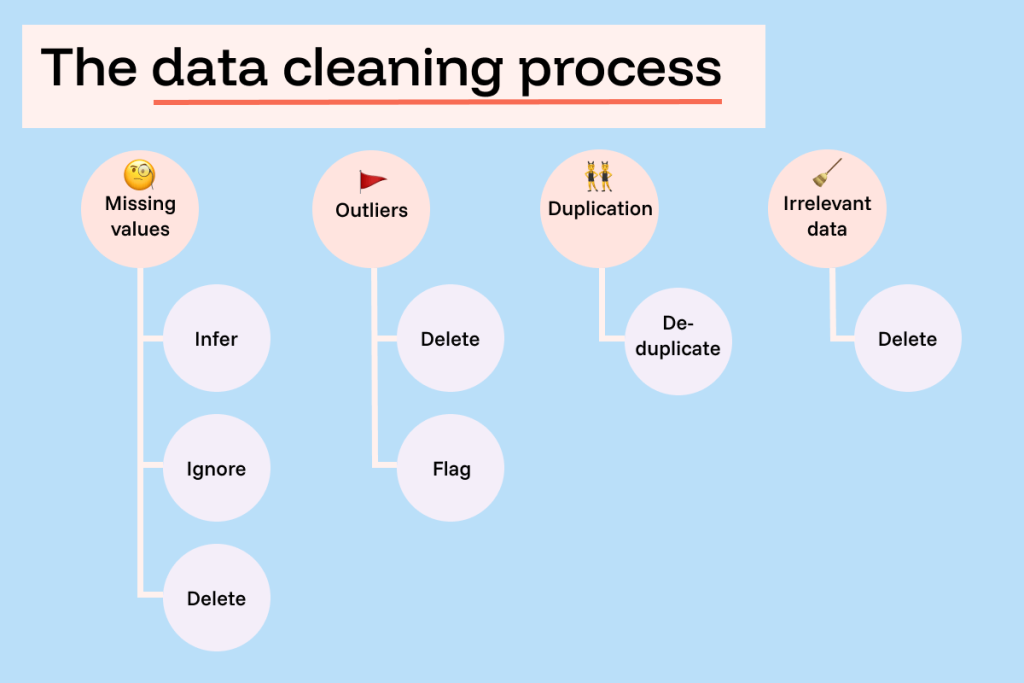
Dữ liệu thô sau khi kéo về thường cực kỳ “bẩn”. Ví dụ: Hệ thống website ghi nhận ngày tháng định dạng DD/MM/YYYY, nhưng API của Facebook lại trả về YYYY-MM-DD. Nếu bạn không chuẩn hóa, Pipeline sẽ bị gãy ngay lập tức khi thực hiện các phép tính cộng dồn.
Vấn đề thực tế thường gặp ở bước này bao gồm dữ liệu bị khuyết (Missing data), dữ liệu trùng lặp do lỗi hệ thống nguồn, hoặc các giá trị ngoại lai (ví dụ đơn hàng trị giá 0 đồng hoặc âm). Tư duy của người làm Data Pipeline thực tế không phải là “làm sạch cho đẹp”, mà là “làm sạch để dùng được”. Bạn phải quyết định: Nếu dữ liệu thiếu, chúng ta sẽ bỏ qua hay điền một giá trị mặc định? Mọi quyết định ở đây đều ảnh hưởng trực tiếp đến kết quả kinh doanh hiển thị trên Dashboard sau này.
5. Giai Đoạn 3: Biến Đổi Dữ Liệu (Transformation) – Từ Dữ Liệu Thô Đến Thông Tin Ý Nghĩa
Đây là giai đoạn “phù phép” dữ liệu. Từ những bảng ghi chép đơn hàng rời rạc, bạn phải tính toán ra các chỉ số mà sếp quan tâm. Ví dụ, bạn cần kết hợp (Join) bảng Đơn hàng với bảng Chi phí quảng cáo để tính chỉ số ROAS (Doanh thu trên chi phí quảng cáo).
Trong mô hình hiện đại, người ta thường dùng phương pháp ELT (Extract – Load – Transform). Nghĩa là dữ liệu được đổ thẳng vào kho lưu trữ (Data Warehouse) rồi mới dùng sức mạnh của kho này (thường là SQL) để transform. Sai lầm phổ biến của những người mới là cố gắng biến đổi quá phức tạp ngay từ đầu, khiến code cực kỳ khó bảo trì. Lời khuyên là hãy giữ dữ liệu thô (Raw data) lại một bản và thực hiện biến đổi qua từng lớp (Layering) để dễ dàng kiểm tra khi có sai sót.
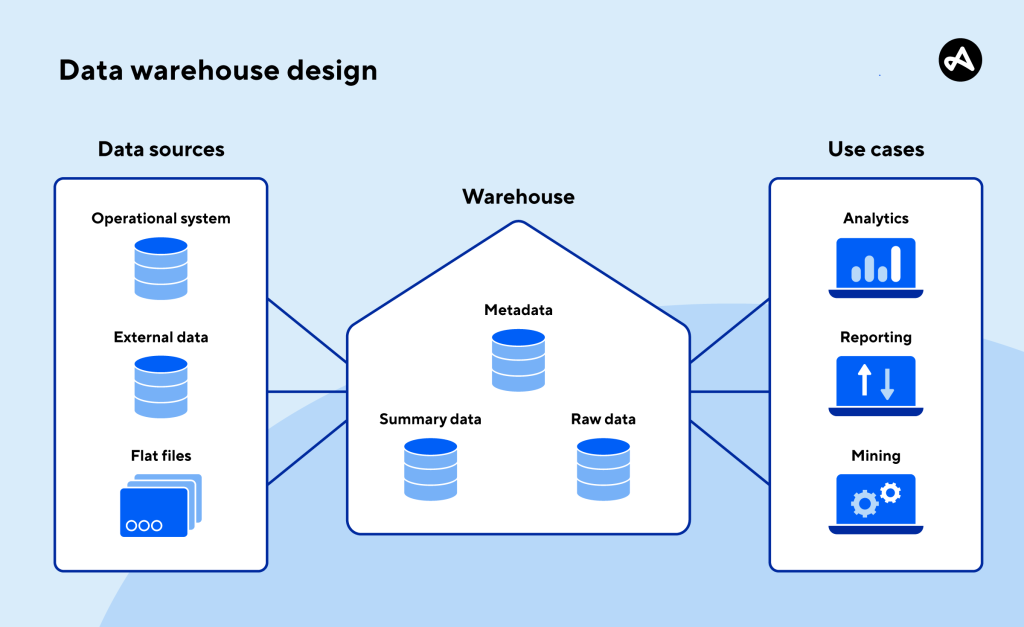
6. Giai Đoạn 4: Lưu Trữ Tại Data Warehouse – Tại Sao Không Dùng Excel?
Câu hỏi mà nhiều bạn Fresher thường đặt ra là: “Tại sao không lưu vào Excel hay Google Sheets cho nhanh?”. Câu trả lời nằm ở khả năng mở rộng (Scalability) và tính đồng bộ. Khi dữ liệu lên đến hàng triệu dòng, Excel sẽ “đứng hình”, trong khi các hệ thống như Google BigQuery hay Snowflake có thể xử lý trong vài giây.
Trong Data Warehouse thực tế, dữ liệu được tổ chức thành các bảng Fact (chứa các sự kiện như giao dịch, cú click) và các bảng Dimension (chứa thông tin định danh như tên khách hàng, tên sản phẩm). Việc tổ chức này giúp các câu lệnh truy vấn chạy nhanh hơn và Dashboard của bạn không bị “quay vòng tròn” mỗi khi sếp bấm lọc dữ liệu.
7. Những “Cơn Ác Mộng” Vận Hành Pipeline Ngoài Đời Thực
Một bài viết về Data Pipeline thực tế sẽ không trọn vẹn nếu không nhắc đến những thất bại. Theo các báo cáo từ Gartner, một phần lớn các dự án dữ liệu thất bại do vấn đề về quản trị và vận hành hơn là do công cụ.
Một số vấn đề “xương máu” bao gồm:
- Pipeline bị gãy (Pipeline Failure): Một sáng thức dậy, Dashboard trắng trơn vì Job đêm qua bị lỗi do mất mạng hoặc Database nguồn bảo trì.
- Dữ liệu không đáng tin (Data Drift): Dashboard vẫn chạy, con số vẫn nhảy nhưng sếp phát hiện số liệu báo cáo lệch 20% so với thực tế. Nguyên nhân có thể do logic SQL bị sai hoặc nguồn dữ liệu thay đổi cấu trúc.
- Nợ kỹ thuật (Technical Debt): Pipeline được xây dựng vội vã, không có tài liệu hướng dẫn (Documentation), khiến người đến sau không dám sửa vì sợ làm hỏng toàn bộ hệ thống.
Để giải quyết, các doanh nghiệp thường áp dụng các công cụ giám sát như Airflow để điều phối (Orchestration) và thiết lập các cảnh báo tự động qua Slack hoặc Email mỗi khi Pipeline có vấn đề.
8. Công Cụ Nào Phổ Biến Cho Một Data Pipeline Hiện Đại?
Để xây dựng một hệ thống như Case Study E-commerce trên, các công cụ thường được kết hợp như sau:
- Thu thập & Điều phối: Apache Airflow hoặc các công cụ No-code như Fivetran, Airbyte.
- Biến đổi (Transformation): SQL là “vua”, có thể kết hợp thêm Python và công cụ dbt (data build tool).
- Lưu trữ: BigQuery (Google Cloud), Snowflake, hoặc Amazon Redshift.
- Hiển thị: Power BI, Tableau hoặc Looker.
Hãy nhớ rằng, công cụ chỉ là phương tiện. Một Data Pipeline thực tế tốt là một hệ thống giải quyết được bài toán kinh doanh với chi phí vận hành thấp nhất và độ tin cậy cao nhất.
9. Data Pipeline: Học Và Thực Tế Khác Nhau Thế Nào?
Khi bạn học trên Coursera hay Udemy, dữ liệu thường được chuẩn bị sẵn trong các file CSV sạch sẽ, logic đơn giản. Bạn chỉ cần viết vài dòng code là ra kết quả. Nhưng trong thực tế:
- Dữ liệu bẩn hơn bạn tưởng: Bạn sẽ dành 80% thời gian để làm sạch và xử lý lỗi dữ liệu.
- Nhiều nguồn dữ liệu phức tạp: Bạn phải làm việc với các bộ phận IT, Marketing, Sale để hiểu ý nghĩa của từng cột dữ liệu.
- Tính ổn định là tiên quyết: Một Pipeline chạy chậm một chút vẫn tốt hơn một Pipeline thi thoảng lại cho ra kết quả sai.
Đối với một Data Analyst nâng cao hoặc một người muốn chuyển hướng sang Data Engineer, hiểu về Data Pipeline là điều bắt buộc. Bạn không cần phải là người trực tiếp xây dựng mọi đường ống, nhưng bạn phải biết dữ liệu mình đang dùng được lấy từ đâu và nó đã qua những bước xử lý nào để có thể giải trình con số của mình một cách tự tin nhất.
Kết luận:
Xây dựng Data Pipeline thực tế là một công việc thầm lặng nhưng cực kỳ quan trọng. Nó là cầu nối giữa thế giới kỹ thuật hỗn độn và những quyết định kinh doanh chiến lược. Nếu bạn muốn thăng tiến trong nghề dữ liệu, hãy bắt đầu bằng việc tìm hiểu cách dữ liệu di chuyển trong tổ chức của mình. Hãy nhớ rằng: Dữ liệu là vàng, nhưng chỉ khi nó được dẫn qua những đường ống chuẩn xác đến đúng người cần dùng.
INDA Academy tự hào là đơn vị tiên phong trong việc đào tạo phân tích dữ liệu và AI chuyên sâu, đặc biệt cho khối ngành Ngân hàng – Tài chính – Bảo hiểm tại Việt Nam. Sau hơn 12 năm “thực chiến” cùng những dòng chảy dữ liệu khổng lồ, chúng tôi đã xây dựng nên một hệ sinh thái đào tạo toàn diện, giúp hàng nghìn học viên chuyển mình từ người mới bắt đầu trở thành những chuyên gia lành nghề, sẵn sàng đáp ứng tiêu chuẩn khắt khe của các doanh nghiệp lớn.
Điểm khác biệt lớn nhất tại INDA chính là triết lý đào tạo dựa trên các dự án thực tế (Project-based) và lộ trình cá nhân hóa nhờ ứng dụng AI. Chúng tôi không chỉ dạy bạn cách sử dụng công cụ, mà còn truyền tải tư duy khai phá giá trị từ dữ liệu để đưa ra quyết định kinh doanh chính xác.
Tìm hiểu thêm về các khóa học TẠI ĐÂY:
Lộ trình đào tạo Data Engineer
Lộ trình đào tạo Data Analyst
Lộ trình đào tạo Tester
Khóa học Data Engineer nâng cao – Thực chiến 5 dự án doanh nghiệp
Khóa học Data Analyst nâng cao – Thực chiến 5 dự án doanh nghiệp


