

Có bao giờ bạn rơi vào tình huống: Vừa chốt xong báo cáo doanh thu tháng cho ban giám đốc vào tối hôm trước, thì sáng hôm sau, một tệp dữ liệu từ chi nhánh vùng sâu vùng xa mới bắt đầu “đổ” về hệ thống, làm thay đổi hoàn toàn con số bạn vừa công bố?
Cảm giác đó giống như việc bạn đã đóng gói xong một kiện hàng để gửi đi, nhưng đúng lúc xe tải lăn bánh thì lại có thêm vài món đồ quan trọng xuất hiện. Trong kỹ thuật dữ liệu, chúng ta gọi đây là hiện tượng Late-arriving Data (Dữ liệu đến muộn). Đây không chỉ là một lỗi kỹ thuật đơn thuần, mà là một phép thử đối với độ bền vững và khả năng chịu lỗi của bất kỳ hệ thống Data Warehouse nào.
Làm thế nào để chúng ta vẫn có thể đưa ra những phân tích tức thời (Real-time) mà không phải đánh đổi bằng sự sai lệch của những con số trong quá khứ?
Mục lục
I. Giải mã hiện tượng dữ liệu “đi lạc”
Trong một hệ thống dữ liệu hoàn hảo, thời điểm sự kiện xảy ra (Event Time) và thời điểm hệ thống nhận được dữ liệu (Ingestion Time) sẽ trùng khớp hoặc chỉ cách nhau vài mili giây. Tuy nhiên, thế giới thực không vận hành như vậy. Một chiếc smartphone mất sóng khi người dùng đi vào hầm kim loại, một thiết bị IoT tại công xưởng bị nghẽn mạng, hay đơn giản là một hệ thống nguồn thực hiện đồng bộ dữ liệu theo lô (batch) chậm trễ.
Sự trễ nải này tạo ra một “hố đen” về thời gian. Một giao dịch diễn ra lúc 23:55 ngày hôm trước nhưng mãi đến 00:15 ngày hôm sau mới bò vào đến kho dữ liệu. Nếu hệ thống của bạn chỉ quét dữ liệu dựa trên lúc nó “vừa đến”, bản ghi đó sẽ trở thành kẻ vô danh: nó không thuộc về ngày hôm trước vì lúc đó nó chưa có mặt, và nó cũng không đúng cho ngày hôm nay vì nó mang nhãn thời gian của quá khứ.
II. Vì sao Late-arriving Data là “cơn đau đầu” của mọi Data Engineer?
Nếu không được xử lý đúng cách, dữ liệu đến muộn sẽ gây ra hiệu ứng Domino, làm sụp đổ tính nhất quán của toàn bộ hệ thống analytics.
Vấn đề nhức nhối nhất nằm ở các Incremental Pipeline. Để tiết kiệm chi phí, kỹ sư thường thiết lập logic: “Chỉ lấy những dữ liệu mới hơn lần chạy cuối cùng”. Khi một bản ghi của ngày hôm trước đến muộn, nó sẽ bị logic này bỏ qua vì thời gian của nó đã cũ hơn mốc chốt sổ gần nhất.
Hậu quả là các chỉ số (metrics) trên dashboard sẽ liên tục thay đổi. Hôm nay sếp thấy doanh thu là 1 tỷ, nhưng ba ngày sau con số đó lại tự động nhảy lên 1 tỷ 100 triệu do dữ liệu muộn được nạp bổ sung. Sự “nhảy múa” này không chỉ gây hoang mang cho người dùng cuối mà còn làm mất đi uy tín của đội ngũ làm dữ liệu.
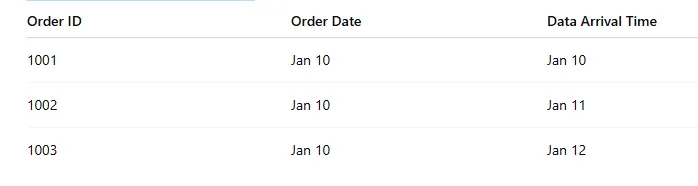
(Một ví dụ từ Medium – LAXMINARAYANA LIKKI) Nếu pipeline dữ liệu của bạn xử lý dữ liệu theo ngày, thì một bản ghi được gửi đến vào ngày 12/01 nhưng thực tế thuộc về dữ liệu của ngày 10/01 sẽ được xem là dữ liệu đến muộn (late-arriving data).
Nếu không có cơ chế xử lý phù hợp, dữ liệu đến muộn có thể gây ra nhiều vấn đề trong hệ thống phân tích, chẳng hạn như:
- Báo cáo doanh thu có thể không chính xác
- Dashboard hiển thị dữ liệu chưa đầy đủ
- Các phép tổng hợp dữ liệu (aggregation) trở nên không nhất quán
III. Các chiến lược “thu phục” dữ liệu đến muộn
Để chung sống hòa bình với những bản ghi trễ nải, các chuyên gia dữ liệu thường áp dụng 3 chiến lược kiến trúc then chốt:
1. Cửa sổ chạy lại (Reprocessing Window)
Thay vì chỉ xử lý dữ liệu của đúng ngày hôm nay, pipeline sẽ luôn quét lại dữ liệu của một khoảng thời gian ngắn trong quá khứ (ví dụ 3 hoặc 7 ngày gần nhất). Bằng cách này, bất kỳ bản ghi nào “đi lạc” trong vòng một tuần qua đều sẽ được hệ thống bắt lại và cập nhật vào báo cáo. Dù tốn thêm một chút chi phí tính toán (compute), nhưng đây là cách đơn giản và an toàn nhất để đảm bảo tính đầy đủ.
2. Xử lý theo Event-time thay vì Ingestion-time
Mọi phép tính toán, phân vùng (partitioning) và báo cáo trong kho dữ liệu nên được thực hiện dựa trên thời điểm sự kiện thực sự xảy ra. Khi một bản ghi đến muộn được nạp vào, nó sẽ tự động tìm về đúng “ngôi nhà” của nó – ví dụ phân vùng của ngày 10/03 – thay vì nằm ở ngày hôm nay. Điều này giúp dữ liệu luôn nằm đúng vị trí của nó trên trục thời gian lịch sử.
3. Ngưỡng chấp nhận (Watermark Strategy)
Đây là một khái niệm mượn từ các hệ thống streaming như Apache Flink hay Google Cloud Dataflow. Watermark đóng vai trò như một “hạn chót” cho dữ liệu muộn. Ví dụ, bạn đặt Watermark là 24 giờ; hệ thống sẽ sẵn sàng chờ đợi và cập nhật các báo cáo của hôm qua. Nhưng bất kỳ dữ liệu nào đến muộn hơn 24 giờ sẽ bị coi là quá hạn và được xử lý theo một luồng riêng để bảo vệ tính ổn định của các số liệu đã chốt.
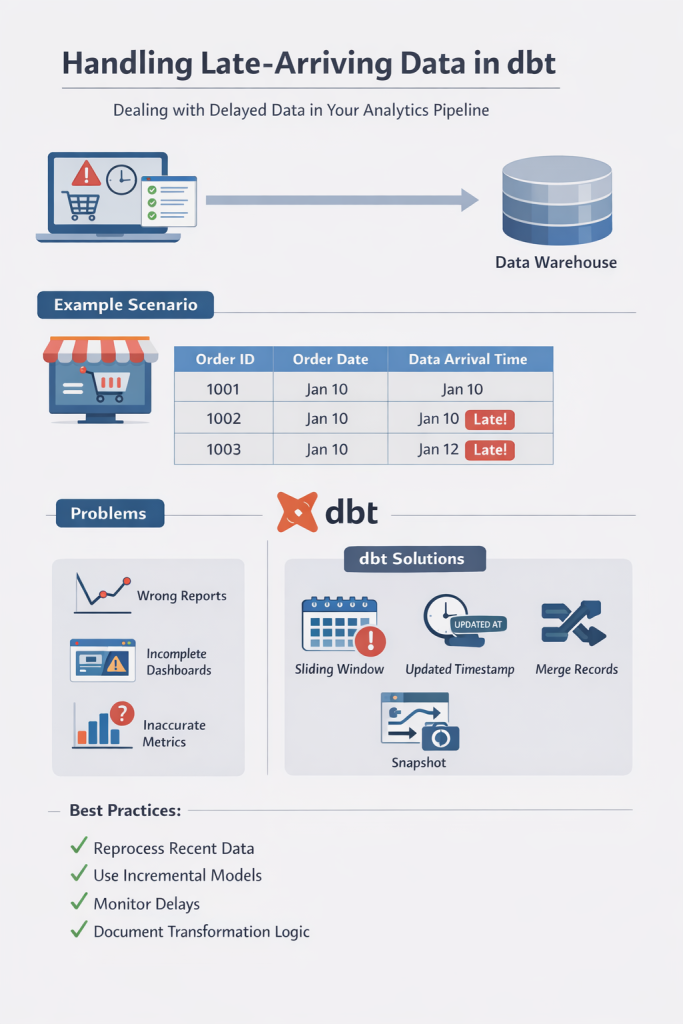
IV. Xây dựng Pipeline chống chịu Late Data trong thực tế
Một hệ thống dữ liệu thực chiến không chỉ đơn thuần là nạp dữ liệu, mà là quản lý sự thay đổi. Quy trình chuẩn thường bắt đầu bằng việc lưu trữ toàn bộ dữ liệu thô (Raw Data) bao gồm cả hai mốc thời gian: lúc xảy ra và lúc nhận được.
Tiếp theo, thay vì dùng lệnh chèn (Insert), chúng ta sử dụng chiến lược Upsert (Merge). Khi một bản ghi muộn xuất hiện, lệnh MERGE sẽ kiểm tra khóa duy nhất (Primary Key). Nếu bản ghi chưa có, nó sẽ thêm mới; nếu đã có nhưng thông tin cũ chưa đầy đủ, nó sẽ cập nhật giá trị mới nhất. Theo tài liệu từ Databricks về Delta Lake, việc sử dụng Merge là cách tối ưu nhất để xử lý dữ liệu thay đổi và đến muộn mà vẫn giữ được tính lũy đẳng (Idempotency).
V. Những đánh đổi (Trade-offs) cần cân nhắc
Trong kỹ thuật dữ liệu, sự chính xác tuyệt đối thường đi kèm với chi phí. Bạn cần thảo luận rõ ràng với các phòng ban về hai yếu tố:
- Chi phí vs. Độ chính xác: Việc chạy lại cửa sổ dữ liệu càng dài (ví dụ 30 ngày) thì hóa đơn Cloud càng cao. Bạn cần xác định xem 95% dữ liệu thường đến trong bao lâu để đặt một khung thời gian hợp lý.
- Tính ổn định của báo cáo: Bạn cần trả lời câu hỏi: “Khi nào một con số được coi là cuối cùng (Finalized)?”. Thông thường, các hệ thống sẽ có mốc chốt số (ví dụ sau 7 ngày sẽ không cập nhật lại nữa) để đảm bảo các báo cáo kế toán không bị thay đổi vĩnh viễn vào quá khứ.
VI. Best Practices dành cho kỹ sư dữ liệu
- Luôn lưu Raw Data: Đây là “phao cứu sinh” giúp bạn tái cấu trúc dữ liệu nếu sau này phát hiện ra một nguồn dữ liệu quan trọng bị trễ nải hàng tháng trời.
- Thiết kế Idempotent: Pipeline phải an toàn khi chạy lại nhiều lần. Một hệ thống xử lý dữ liệu muộn tốt bản chất phải là một hệ thống không sợ việc chạy lại.
- Giám sát tỷ lệ Late Data: Thiết lập cảnh báo nếu số lượng bản ghi đến muộn vượt quá một ngưỡng nhất định (ví dụ > 5%). Đây thường là dấu hiệu của lỗi hệ thống nguồn hoặc nghẽn mạng.
- Thông báo minh bạch: Hãy để người dùng Dashboard biết rằng dữ liệu của 48 giờ gần nhất là “số liệu tạm tính” và sẽ được chốt sau 3 ngày.
VII. Kết luận
Dữ liệu đến muộn không phải là lỗi, đó là một thuộc tính tự nhiên của mọi hệ thống phân tán hiện đại. Một kỹ sư dữ liệu giỏi không phải là người cố gắng ngăn chặn sự chậm trễ, mà là người thiết kế được một “bến cảng” đủ linh hoạt để đón chờ và sắp xếp những bản ghi đi lạc về đúng vị trí của chúng.
Khi bạn làm chủ được kỹ thuật xử lý Late-arriving data, bạn không chỉ nâng cao chất lượng hệ thống mà còn xây dựng được niềm tin bền vững cho những người sử dụng dữ liệu để đưa ra các quyết định kinh doanh quan trọng.
INDA Academy tự hào là đơn vị tiên phong trong việc đào tạo phân tích dữ liệu và AI chuyên sâu, đặc biệt cho khối ngành Ngân hàng – Tài chính – Bảo hiểm tại Việt Nam. Sau hơn 12 năm “thực chiến” cùng những dòng chảy dữ liệu khổng lồ, chúng tôi đã xây dựng nên một hệ sinh thái đào tạo toàn diện, giúp hàng nghìn học viên chuyển mình từ người mới bắt đầu trở thành những chuyên gia lành nghề, sẵn sàng đáp ứng tiêu chuẩn khắt khe của các doanh nghiệp lớn.
Điểm khác biệt lớn nhất tại INDA chính là triết lý đào tạo dựa trên các dự án thực tế (Project-based) và lộ trình cá nhân hóa nhờ ứng dụng AI. Chúng tôi không chỉ dạy bạn cách sử dụng công cụ, mà còn truyền tải tư duy khai phá giá trị từ dữ liệu để đưa ra quyết định kinh doanh chính xác.
Tìm hiểu thêm về các khóa học TẠI ĐÂY:
Lộ trình đào tạo Data Engineer
Lộ trình đào tạo Data Analyst
Lộ trình đào tạo Tester
Khóa học Data Engineer nâng cao – Thực chiến 5 dự án doanh nghiệp
Khóa học Data Analyst nâng cao – Thực chiến 5 dự án doanh nghiệp
Bài viết liên quan:
 Data Backfill: Khi Pipeline cần “ngược dòng thời gian” xử lý dữ liệu lịch sử
Data Backfill: Khi Pipeline cần “ngược dòng thời gian” xử lý dữ liệu lịch sử
 [Series: Checklist Ra Quyết Định] Bài 2: Bạn Đã Thực Sự Sẵn Sàng Học Data Engineer?
Data Engineer và Data Analyst Khác Nhau Thế Nào? So Sánh Dễ Hiểu Cho Sinh Viên Năm 3–4
Kỹ Năng Mềm Cho Data Engineer: Những Kỹ Năng Mềm Cơ Bản Nhất Để Giao Tiếp Hiệu Quả Với Product Manager và Data Scientist
Hướng Dẫn Viết CV Data Engineer Đúng Chuẩn 2026
[Series: Checklist Ra Quyết Định] Bài 2: Bạn Đã Thực Sự Sẵn Sàng Học Data Engineer?
Data Engineer và Data Analyst Khác Nhau Thế Nào? So Sánh Dễ Hiểu Cho Sinh Viên Năm 3–4
Kỹ Năng Mềm Cho Data Engineer: Những Kỹ Năng Mềm Cơ Bản Nhất Để Giao Tiếp Hiệu Quả Với Product Manager và Data Scientist
Hướng Dẫn Viết CV Data Engineer Đúng Chuẩn 2026
 Data Analyst, Data Engineer và Tester: Khác nhau điểm nào và ai phù hợp? (Cập nhật 2026)
Data Analyst, Data Engineer và Tester: Khác nhau điểm nào và ai phù hợp? (Cập nhật 2026)