

Hãy tưởng tượng một buổi sáng thứ Hai rạng rỡ, CEO của công ty mở Dashboard doanh thu để chuẩn bị cho cuộc họp chiến lược quan trọng. Thay vì nhìn thấy những biểu đồ tăng trưởng đều đặn, con số hiển thị trên màn hình lại là số 0 tròn trĩnh, hoặc tệ hơn, doanh thu bỗng dưng tăng vọt gấp 10 lần một cách vô lý. Ngay lập tức, điện thoại của đội ngũ Data đổ chuông liên hồi. Đó không chỉ là một lỗi phần mềm; đó là một Data Incident – một sự cố dữ liệu có khả năng làm lung lay niềm tin của toàn bộ tổ chức vào hệ thống Analytics.
Trong kỷ nguyên ra quyết định dựa trên dữ liệu (Data-driven), Dashboard chính là “đôi mắt” của doanh nghiệp. Khi đôi mắt ấy nhìn sai, toàn bộ hành động phía sau sẽ đi lệch hướng. Xử lý một sự cố dữ liệu không giống như sửa một con bug trong code; nó là một cuộc chạy đua với thời gian để khôi phục sự thật và bảo vệ uy tín của đội ngũ Data.
Mục lục
I. Data Incident: Những bóng ma thầm lặng trong hệ thống Analytics
Data Incident là tình trạng dữ liệu trong hệ thống trở nên không chính xác, không đầy đủ hoặc không kịp thời. Khác với những lỗi sập hệ thống (System Outage) vốn rất dễ nhận biết, sự cố dữ liệu thường mang tính thầm lặng. Dashboard vẫn tải được, biểu đồ vẫn hiện ra, nhưng giá trị bên trong đã bị “nhiễm độc”.
Một số sự cố phổ biến mà bất kỳ Data Engineer nào cũng từng gặp phải:
- Pipeline “xanh” nhưng dữ liệu “rỗng”: Job ETL chạy thành công nhưng không có bản ghi nào được nạp vào do API nguồn trả về rỗng.
- Cơn ác mộng Schema Evolution: Hệ thống nguồn thay đổi tên cột hoặc kiểu dữ liệu mà không thông báo, làm gãy các bước biến đổi (Transformation) hạ nguồn.
- Logic “trôi dạt”: Một thay đổi nhỏ trong câu lệnh SQL khiến dữ liệu bị nhân đôi (Duplicate) hoặc lọc nhầm các khách hàng quan trọng.
Sự nguy hiểm của Data Incident nằm ở chỗ nó tấn công trực tiếp vào Data Trust (Niềm tin vào dữ liệu). Một khi các Stakeholders đã nghi ngờ tính chính xác của Dashboard, họ sẽ quay lại với cách ra quyết định bằng “cảm giác”, và mọi nỗ lực xây dựng hạ tầng dữ liệu hiện đại của bạn sẽ trở nên vô nghĩa.
II. Truy tìm nguồn gốc: Tại sao Dashboard hiển thị sai?
Để xử lý sự cố, trước hết ta phải hiểu rõ “kẻ thủ ác”. Dữ liệu đi từ nguồn đến Dashboard là một hành trình dài, và sai số có thể xuất hiện ở bất kỳ layer nào.
1. Sự sụp đổ của các “đường ống” (Pipeline Failure)
Đây là nguyên nhân trực diện nhất. Các job Ingestion có thể bị treo, bị lỗi kết nối mạng hoặc gặp vấn đề về tài nguyên hạ tầng. Khi một mắt xích trong chuỗi cung ứng dữ liệu bị đứt, Dashboard sẽ rơi vào tình trạng “đói” dữ liệu, dẫn đến các chỉ số Freshness bị lỗi thời.
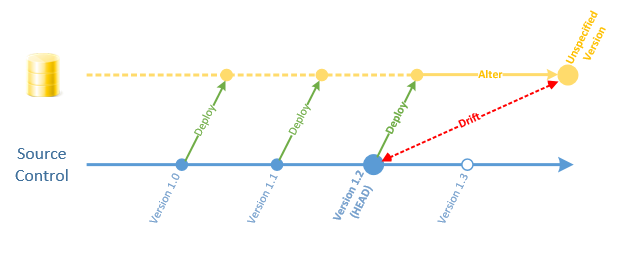
2. Sự biến đổi bất ngờ của cấu trúc (Schema Drift)
Hệ thống dữ liệu hiện đại cực kỳ nhạy cảm với những thay đổi ở thượng nguồn. Nếu đội ngũ Backend thêm một cột mới hoặc thay đổi kiểu dữ liệu từ Integer sang String, các pipeline hạ nguồn không được thiết kế để thích ứng (Schema Evolution) sẽ ngay lập tức bị đổ vỡ.
3. Dữ liệu đến muộn (Late-arriving Data)
Đôi khi dữ liệu không sai, nó chỉ là chưa đến kịp. Các sự kiện (events) từ ứng dụng di động có thể bị nghẽn và đổ vào kho dữ liệu muộn hơn vài tiếng so với thực tế. Nếu Dashboard của bạn không được thiết kế để xử lý Late-arriving Data, nó sẽ hiển thị những con số thiếu hụt, gây hoang mang cho người xem.
4. Lỗi logic trong tầng biến đổi (Transformation Logic)
Đây là loại lỗi khó phát hiện nhất. Nó thường xảy ra sau khi một thành viên trong team cập nhật logic SQL để tính toán một metric mới nhưng vô tình làm sai phép Join, dẫn đến việc dữ liệu bị nhân bản (fan-out) hoặc bị mất mát do phép Inner Join không khớp.
III. Quy trình Data Incident Management: 6 bước giành lại sự thật
Xử lý sự cố dữ liệu cần sự bình tĩnh và một quy trình chuẩn hóa tương tự như cách các kỹ sư DevOps quản lý Incident hệ thống.
Bước 1: Phát hiện và Cảnh báo (Detection)
Lý tưởng nhất là hệ thống Monitoring Data Pipeline sẽ phát hiện ra lỗi trước khi người dùng nhận ra. Các bộ kiểm tra chất lượng (Data Quality Checks) sẽ kích hoạt cảnh báo khi thấy số lượng record giảm đột ngột hoặc tỷ lệ Null tăng cao. Tuy nhiên, nếu sự cố do Stakeholders báo cáo, team Data cần ngay lập tức ghi nhận và đánh dấu mức độ nghiêm trọng.
Bước 2: Xác nhận và Đánh giá phạm vi ảnh hưởng
Trước khi bắt tay vào sửa, bạn cần xác định: Có bao nhiêu Dashboard bị ảnh hưởng? Dữ liệu bị sai từ thời điểm nào? Liệu đây là lỗi hiển thị của BI Tool hay lỗi từ kho dữ liệu (Data Warehouse)? Việc xác định phạm vi giúp bạn đưa ra thông báo chính xác cho các bên liên quan.
Bước 3: Điều tra nguyên nhân gốc rễ (Root Cause Analysis)
Đây là lúc công cụ Data Lineage phát huy tác dụng. Bằng cách nhìn vào sơ đồ dòng chảy dữ liệu, bạn có thể truy ngược từ Dashboard bị sai về các bảng Staging, rồi đến các job ETL và cuối cùng là hệ thống nguồn. Bạn cần trả lời được câu hỏi: Lỗi bắt đầu từ đâu và tại sao nó xảy ra?

Bước 4: Khắc phục và Làm sạch (Fixing & Recovery)
Sau khi đã tìm ra nguyên nhân (ví dụ: sửa lại câu lệnh SQL bị sai logic), bước tiếp theo là khôi phục dữ liệu. Đây thường là lúc bạn phải thực hiện Data Backfill – chạy lại pipeline cho khoảng thời gian bị ảnh hưởng để ghi đè dữ liệu đúng lên dữ liệu sai.
Bước 5: Xác minh (Validation)
Đừng vội thông báo “đã fix xong” ngay khi job Backfill vừa chạy xong. Team Data cần thực hiện các câu query đối soát giữa hệ thống nguồn và kho dữ liệu để đảm bảo các con số trên Dashboard đã khớp hoàn toàn với thực tế.
Bước 6: Postmortem và Cải tiến
Mỗi sự cố là một bài học. Sau khi sóng gió qua đi, team cần ngồi lại để phân tích: Tại sao hệ thống monitoring không phát hiện ra sớm hơn? Chúng ta cần thêm những Data Quality check nào để ngăn chặn lỗi này lặp lại? Kết quả của bước này thường là các đầu việc cập nhật playbook và tăng cường lớp phòng thủ cho pipeline.
IV. Nghệ thuật giao tiếp trong sự cố dữ liệu
Trong Data Incident Management, kỹ năng code chỉ chiếm 50%, 50% còn lại nằm ở khả năng giao tiếp. Khi dữ liệu sai, stakeholders sẽ cảm thấy lo lắng và mất phương hướng.
Một nguyên tắc vàng là: Luôn chủ động thông báo. Đừng để CEO là người đầu tiên phát hiện ra doanh thu bằng 0. Khi phát hiện sự cố, hãy gửi một thông báo rõ ràng: “Chúng tôi đã phát hiện sự cố dữ liệu trên Dashboard X ảnh hưởng đến các chỉ số Y. Team đang điều tra và dự kiến sẽ có cập nhật trong 2 giờ tới.” Việc này giúp duy trì sự chuyên nghiệp và giữ chân niềm tin của stakeholders ngay cả khi hệ thống đang gặp lỗi.
V. Xây dựng “hệ miễn dịch” cho Data Platform
Để giảm thiểu tần suất của các Data Incident, các tổ chức cần tiến hóa từ việc “đi chữa cháy” sang “phòng cháy”.
- Data Quality Checks tại mọi tầng: Đừng chỉ kiểm tra dữ liệu ở cuối đường ống. Hãy đặt các chốt chặn (assertions) ngay từ khi dữ liệu vừa nạp vào (Ingestion) cho đến khi nó được tổng hợp (Aggregation). Kiểm tra số dòng, kiểm tra tính duy nhất (uniqueness) và kiểm tra các giá trị Null là những bước cơ bản nhưng cực kỳ hiệu quả.
- Tận dụng Data Observability: Các công cụ hiện đại có khả năng học máy để tự động nhận diện các bất thường (Anomaly Detection) mà không cần bạn phải viết code cho từng trường hợp.
- Version Control cho mọi thứ: Từ code ETL đến logic của Dashboard, tất cả nên được quản lý qua Git. Điều này giúp bạn rollback (quay xe) về phiên bản ổn định gần nhất chỉ trong vài giây khi có sự cố xảy ra.
VI. Kết luận
Data Incident là một phần tất yếu của bất kỳ hệ thống dữ liệu phức tạp nào. Tuy nhiên, sự khác biệt giữa một Data Team xuất sắc và một team trung bình nằm ở cách họ phản ứng khi Dashboard hiển thị sai.
Bằng cách xây dựng một quy trình Data Incident Management bài bản, kết hợp với hệ thống Monitoring mạnh mẽ và tư duy Postmortem cầu tiến, bạn không chỉ xử lý được sự cố mà còn biến những sai lầm thành nền tảng để xây dựng một Data Platform đáng tin cậy hơn. Suy cho cùng, giá trị của dữ liệu không nằm ở những dòng code, mà nằm ở niềm tin của con người khi họ nhìn vào những con số đó.
INDA Academy tự hào là đơn vị tiên phong trong việc đào tạo phân tích dữ liệu và AI chuyên sâu, đặc biệt cho khối ngành Ngân hàng – Tài chính – Bảo hiểm tại Việt Nam. Sau hơn 12 năm “thực chiến” cùng những dòng chảy dữ liệu khổng lồ, chúng tôi đã xây dựng nên một hệ sinh thái đào tạo toàn diện, giúp hàng nghìn học viên chuyển mình từ người mới bắt đầu trở thành những chuyên gia lành nghề, sẵn sàng đáp ứng tiêu chuẩn khắt khe của các doanh nghiệp lớn.
Điểm khác biệt lớn nhất tại INDA chính là triết lý đào tạo dựa trên các dự án thực tế (Project-based) và lộ trình cá nhân hóa nhờ ứng dụng AI. Chúng tôi không chỉ dạy bạn cách sử dụng công cụ, mà còn truyền tải tư duy khai phá giá trị từ dữ liệu để đưa ra quyết định kinh doanh chính xác.
Tìm hiểu thêm về các khóa học TẠI ĐÂY:
Lộ trình đào tạo Data Engineer
Lộ trình đào tạo Data Analyst
Lộ trình đào tạo Tester
Khóa học Data Engineer nâng cao – Thực chiến 5 dự án doanh nghiệp
Khóa học Data Analyst nâng cao – Thực chiến 5 dự án doanh nghiệp
Bài viết liên quan:
 Data Pipeline Debugging: Nghệ Thuật Tìm Root Cause Khi Hệ Thống Dữ Liệu “Gãy Đổ”
Data Pipeline Debugging: Nghệ Thuật Tìm Root Cause Khi Hệ Thống Dữ Liệu “Gãy Đổ”
 Data Pipeline Thực Tế: Cách Doanh Nghiệp Xử Lý Dữ Liệu Từ A-Z
Data Pipeline Thực Tế: Cách Doanh Nghiệp Xử Lý Dữ Liệu Từ A-Z
 Monitoring chiến lược cho Data Pipeline: Bảo chứng niềm tin cho hệ thống dữ liệu hiện đại
Monitoring chiến lược cho Data Pipeline: Bảo chứng niềm tin cho hệ thống dữ liệu hiện đại
 Star Schema, Data Vault hay Wide Table: Đâu là “xương sống” hoàn hảo cho hệ thống Analytics?
Star Schema, Data Vault hay Wide Table: Đâu là “xương sống” hoàn hảo cho hệ thống Analytics?
 Late-arriving Data: Khi dữ liệu “đi lạc” và bài toán về tính chính xác trong Data Warehouse
Late-arriving Data: Khi dữ liệu “đi lạc” và bài toán về tính chính xác trong Data Warehouse
 [Series: Những hiểu lầm về nghề Data] Bài 2: Những hiểu lầm về Data Engineer khiến người mới chọn sai nghề
[Series: Những hiểu lầm về nghề Data] Bài 2: Những hiểu lầm về Data Engineer khiến người mới chọn sai nghề