

Trong thế giới của dữ liệu, nếu ví đường ống dẫn (pipeline) là mạch máu, thì mô hình dữ liệu (Data Model) chính là bộ khung xương định hình nên vóc dáng của toàn bộ hệ thống. Hãy thử tưởng tượng bạn đang xây dựng một thư viện số khổng lồ: Bạn sẽ phân loại sách theo từng phòng chuyên biệt (Dimensional), lưu giữ từng bản nháp lịch sử của tác giả (Data Vault), hay in tất cả thông tin vào một cuốn bách khoa toàn thư duy nhất để ai cũng có thể tra cứu ngay lập tức (Wide Table)?
Quyết định này không chỉ nằm ở sở thích cá nhân của người kỹ sư, mà nó trực tiếp quyết định việc một chuyên viên phân tích (Data Analyst) sẽ mất 5 giây hay 5 phút để chạy một báo cáo. Nó cũng là ranh giới giữa một hệ thống “khỏe mạnh”, dễ dàng mở rộng, với một mớ hỗn độn những bảng biểu chồng chéo khiến chi phí vận hành tăng vọt. Trong bài viết này, chúng ta sẽ cùng giải mã ba “đại phái” trong thiết kế mô hình dữ liệu analytics để tìm ra đâu là lựa chọn tối ưu cho doanh nghiệp của bạn.
Mục lục
I. Triết lý thiết kế: Mục tiêu của Data Modeling trong Analytics
Khác với các cơ sở dữ liệu vận hành (OLTP) vốn ưu tiên việc ghi dữ liệu nhanh và tránh trùng lặp, mô hình dữ liệu trong Analytics (OLAP) hướng tới một mục tiêu tối thượng: Khả năng đọc và phân tích.
Một mô hình dữ liệu tốt phải cân bằng được bốn yếu tố: Tốc độ truy vấn, tính dễ hiểu đối với con người, sự ổn định của pipeline và khả năng thích ứng khi quy mô dữ liệu tăng lên. Lịch sử ngành dữ liệu đã chứng kiến sự phân tranh giữa hai triết lý lớn: Ralph Kimball với tư duy “lấy người dùng làm trung tâm” (Star Schema) và Bill Inmon với tư duy “lấy kho dữ liệu làm trung tâm”.
Ngày nay, sự trỗi dậy của các kho dữ liệu đám mây (Cloud Data Warehouse) như BigQuery hay Snowflake đã khai sinh thêm những biến thể hiện đại như Data Vault và Wide Table để giải quyết các bài toán quy mô lớn.
II. Star Schema: Ngôi sao sáng của thế giới Business Intelligence
Ra đời từ những năm 90 dưới bàn tay của Ralph Kimball, Star Schema (Mô hình sao) vẫn là tiêu chuẩn vàng cho các hệ thống báo cáo truyền thống. Đúng như tên gọi, mô hình này đặt một bảng sự kiện (Fact Table) ở trung tâm, bao quanh là các bảng danh mục (Dimension Tables).
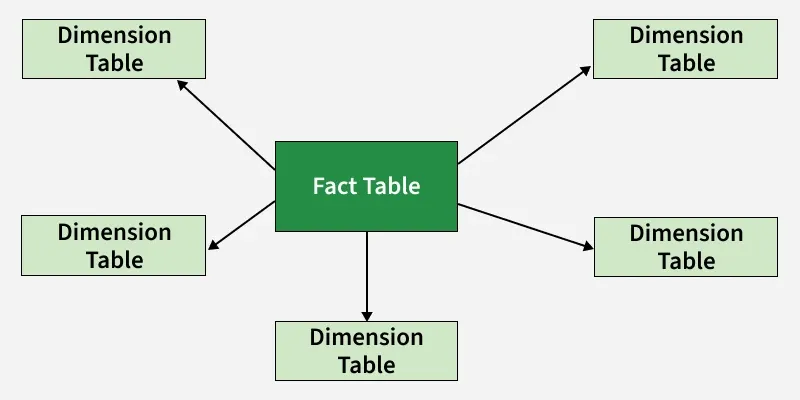
Cấu trúc và ưu điểm
Bảng Fact chứa các con số có thể đo lường (như doanh thu, số lượng đơn hàng), trong khi các bảng Dimension chứa thông tin mô tả (khách hàng, sản phẩm, thời gian). Sự tách biệt này giúp các câu lệnh SQL trở nên vô cùng đơn giản và trực quan. Một analyst chỉ cần nối (Join) bảng doanh thu với bảng khách hàng là có thể biết ngay ai là người mua nhiều nhất. Hầu hết các công cụ BI như Power BI hay Tableau đều được tối ưu hóa để “đọc” cấu trúc hình sao này một cách hiệu quả nhất.
Điểm yếu cần lưu ý
Tuy nhiên, Star Schema không phải là không có nhược điểm. Khi logic kinh doanh trở nên phức tạp hoặc dữ liệu đến từ quá nhiều nguồn khác nhau, việc duy trì các bảng Dimension luôn nhất quán (Consistent) trở thành một bài toán ETL hóc búa. Ngoài ra, Star Schema cũng gặp khó khăn trong việc lưu trữ lịch sử thay đổi phức tạp của dữ liệu mà không làm phình to kích thước các bảng.
III. Data Vault: Pháo đài của sự linh hoạt và Audit
Nếu Star Schema là một thư viện được sắp xếp ngăn nắp để người đọc dễ tra cứu, thì Data Vault lại giống như một kho lưu trữ văn thư chuyên nghiệp, nơi mọi thay đổi nhỏ nhất đều được ghi chép và bảo tồn. Đây là mô hình được thiết kế để giải quyết bài toán tích hợp dữ liệu từ hàng trăm nguồn khác nhau trong các tập đoàn lớn.
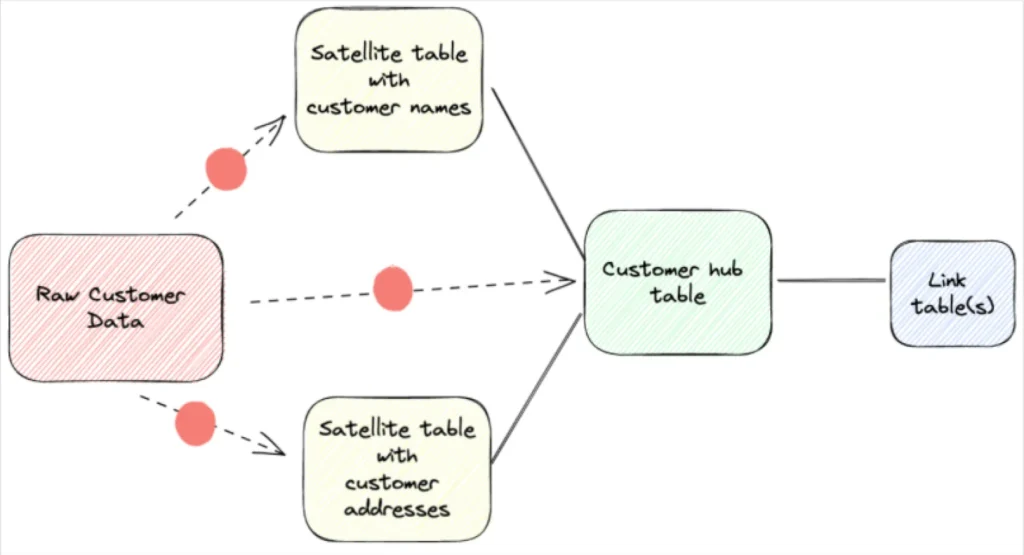
Ba trụ cột của Data Vault
Data Vault phá vỡ cấu trúc dữ liệu thành ba thành phần riêng biệt:
- Hub: Lưu trữ các mã định danh kinh doanh duy nhất (như Mã khách hàng, Mã sản phẩm).
- Link: Lưu trữ mối quan hệ giữa các Hub (ví dụ: Khách hàng A mua Sản phẩm B).
- Satellite: Lưu trữ tất cả các thuộc tính mô tả và lịch sử thay đổi của Hub hoặc Link.
Sức mạnh của sự thích ứng
Ưu điểm lớn nhất của Data Vault là khả năng mở rộng schema cực tốt. Bạn có thể thêm một nguồn dữ liệu mới vào hệ thống mà không cần phải thay đổi cấu trúc của các bảng hiện có. Nó cũng là “vô địch” trong việc Audit – giúp bạn biết chính xác dữ liệu tại một thời điểm trong quá khứ trông như thế nào. Tuy nhiên, cái giá phải trả là sự phức tạp. Một analyst không thể query trực tiếp trên Data Vault vì số lượng bảng cần Join là quá lớn. Thông thường, người ta phải xây dựng thêm một lớp Star Schema bên trên Data Vault để phục vụ mục đích báo cáo.
IV. Wide Table: Tốc độ tối thượng trong kỷ nguyên Cloud
Trong vài năm gần đây, một xu hướng mạnh mẽ khác đã trỗi dậy: Wide Table (Bảng rộng). Thay vì chia nhỏ dữ liệu ra nhiều bảng để tiết kiệm không gian, chúng ta gộp tất cả thông tin liên quan vào một bảng duy nhất có hàng trăm, thậm chí hàng nghìn cột.
Triết lý “Phi chuẩn hóa” (Denormalization)
Tại sao chúng ta lại chấp nhận sự trùng lặp dữ liệu? Câu trả lời nằm ở chi phí. Trong các kho dữ liệu hiện đại như Google BigQuery, việc quét dữ liệu theo cột (Columnar Storage) cực nhanh, trong khi phép nối (Join) lại là thao tác tốn kém nhất. Bằng cách khử bỏ phép Join, Wide Table cho phép các câu lệnh truy vấn chạy với tốc độ “xé gió”, đặc biệt phù hợp cho các bài toán phân tích hành vi người dùng (Clickstream) hoặc làm đầu vào cho các mô hình Machine Learning.
Thách thức về bảo trì
Dù cực nhanh cho truy vấn, Wide Table lại là “cơn ác mộng” nếu bạn cần cập nhật thông tin. Nếu một khách hàng đổi tên, bạn sẽ phải cập nhật hàng triệu dòng trong Wide Table thay vì chỉ một dòng duy nhất trong bảng Dimension của Star Schema. Ngoài ra, việc quản lý một bảng có quá nhiều cột cũng dễ dẫn đến tình trạng sai lệch dữ liệu nếu không có quy trình kiểm soát chất lượng chặt chẽ.
V. So sánh trực diện: Đâu là lựa chọn cho bạn?
Để giúp bạn có cái nhìn tổng quan, hãy cùng đặt ba mô hình này lên bàn cân:
| Tiêu chí | Star Schema | Data Vault | Wide Table |
| Mục đích chính | Báo cáo BI & Dashboard | Tích hợp dữ liệu đa nguồn | Hiệu suất query & ML |
| Tốc độ truy vấn | Nhanh | Chậm (do nhiều Join) | Nhanh nhất |
| Độ phức tạp ETL | Trung bình | Cao | Thấp |
| Khả năng Audit | Trung bình | Rất tốt | Thấp |
| Dễ hiểu (Analyst) | Rất dễ | Khó | Rất dễ |
VI. Kiến trúc hiện đại: Sự kết hợp hoàn hảo
Thực tế ngày nay, các Data Engineer không còn chọn “một mất một còn”. Thay vào đó, họ kết hợp cả ba mô hình vào một kiến trúc phân tầng (Layered Architecture) để tận dụng thế mạnh của từng loại:
- Raw Layer: Lưu dữ liệu nguyên bản từ nguồn.
- Integration Layer (Data Vault): Dùng Data Vault để tích hợp và lưu giữ lịch sử từ nhiều nguồn khác nhau, đảm bảo tính nhất quán và khả năng audit.
- Presentation Layer (Star Schema): Chuyển đổi dữ liệu từ Data Vault sang Star Schema để cung cấp một giao diện dễ hiểu cho các công cụ BI.
- Performance Layer (Wide Tables): Tạo ra các Wide Table từ Star Schema cho các nhu cầu phân tích đặc biệt cần tốc độ cao hoặc phục vụ Machine Learning.
Cách tiếp cận này giúp hệ thống vừa bền bỉ ở “trụ cột” bên trong, vừa linh hoạt và nhanh chóng ở “giao diện” bên ngoài.
VII. Những sai lầm cần tránh khi thiết kế mô hình
Chọn sai mô hình dữ liệu có thể dẫn đến những “món nợ kỹ thuật” khổng lồ. Sai lầm phổ biến nhất là ép buộc sử dụng Data Vault cho các dự án nhỏ – điều này chỉ làm tăng độ phức tạp không cần thiết. Ngược lại, việc lạm dụng Wide Table cho các báo cáo tài chính cần sự chính xác tuyệt đối và thay đổi thường xuyên sẽ khiến việc kiểm soát dữ liệu trở nên cực kỳ khó khăn.
Hãy luôn bắt đầu từ Query Pattern (Cách người dùng sẽ truy vấn). Nếu Analyst của bạn chỉ dùng Excel và Power BI, Star Schema là lựa chọn không thể bàn cãi. Nếu bạn đang xây dựng một nền tảng dữ liệu cho toàn tập đoàn với hàng chục hệ thống ERP khác nhau, hãy cân nhắc Data Vault.
VIII. Kết luận
Mô hình dữ liệu không phải là một cấu trúc tĩnh, nó là một chiến lược. Star Schema mang lại sự thân thiện, Data Vault mang lại sự an tâm về lịch sử, và Wide Table mang lại sức mạnh về tốc độ. Hiểu rõ ưu và nhược điểm của từng loại sẽ giúp bạn xây dựng được một hệ thống analytics không chỉ chạy nhanh ngày hôm nay mà còn có thể phát triển mạnh mẽ trong tương lai.
Bạn đang đứng trước ngưỡng cửa của một dự án dữ liệu mới? Đừng vội vàng code ngay. Hãy dành thời gian để vẽ nên “khung xương” phù hợp nhất, vì đó chính là nền tảng cho mọi thành công của dữ liệu sau này.
INDA Academy tự hào là đơn vị tiên phong trong việc đào tạo phân tích dữ liệu và AI chuyên sâu, đặc biệt cho khối ngành Ngân hàng – Tài chính – Bảo hiểm tại Việt Nam. Sau hơn 12 năm “thực chiến” cùng những dòng chảy dữ liệu khổng lồ, chúng tôi đã xây dựng nên một hệ sinh thái đào tạo toàn diện, giúp hàng nghìn học viên chuyển mình từ người mới bắt đầu trở thành những chuyên gia lành nghề, sẵn sàng đáp ứng tiêu chuẩn khắt khe của các doanh nghiệp lớn.
Điểm khác biệt lớn nhất tại INDA chính là triết lý đào tạo dựa trên các dự án thực tế (Project-based) và lộ trình cá nhân hóa nhờ ứng dụng AI. Chúng tôi không chỉ dạy bạn cách sử dụng công cụ, mà còn truyền tải tư duy khai phá giá trị từ dữ liệu để đưa ra quyết định kinh doanh chính xác.
Tìm hiểu thêm về các khóa học TẠI ĐÂY:
Lộ trình đào tạo Data Engineer
Lộ trình đào tạo Data Analyst
Lộ trình đào tạo Tester
Khóa học Data Engineer nâng cao – Thực chiến 5 dự án doanh nghiệp
Khóa học Data Analyst nâng cao – Thực chiến 5 dự án doanh nghiệp
