

Hãy tưởng tượng bạn đang quản lý một hệ thống dữ liệu cho một tập đoàn đa quốc gia. Mỗi ngày, bạn phải tiếp nhận thêm hàng chục nguồn dữ liệu mới từ các chi nhánh khác nhau, mỗi nguồn lại có cấu trúc, định dạng và lịch trình riêng biệt. Nếu áp dụng phương pháp truyền thống, đội ngũ kỹ sư của bạn sẽ phải ngồi viết hàng trăm script ETL (Extract, Transform, Load) riêng lẻ.
Theo thời gian, hệ thống này sẽ trở thành một “mạng lưới chằng chịt” những dòng code cứng nhắc (hard-coded), nơi mà chỉ cần một sự thay đổi nhỏ ở phía nguồn cũng đủ để gây ra hiệu ứng domino làm sập toàn bộ các báo cáo hạ nguồn.
Sự bùng nổ về số lượng dataset trong các hệ thống Big Data đã đẩy phương pháp viết code thủ công vào ngõ cụt. Để thoát khỏi vòng lặp bảo trì vô tận, các tổ chức hàng đầu đã chuyển dịch sang một tư duy mới: Metadata-Driven Architecture. Đây là chìa khóa để biến các pipeline từ những cỗ máy chạy bằng “cơm” (viết code tay) thành những hệ thống tự động hóa thông minh, nơi mà logic xử lý được điều khiển bởi dữ liệu mô tả (metadata) thay vì những dòng lệnh cố định.
Mục lục
1. Metadata trong Data Engineering: Không chỉ là những thông tin mô tả
Trong lĩnh vực kỹ thuật dữ liệu, Metadata thường được ví như “dữ liệu về dữ liệu”. Tuy nhiên, nếu chỉ hiểu metadata là những thông tin mang tính chất mục lục thì chúng ta đã bỏ lỡ sức mạnh thực sự của nó. Metadata là một tập hợp các chỉ dẫn kỹ thuật giúp hệ thống hiểu được bản chất, vị trí và hành trình của dữ liệu.
Phân loại Metadata trong hệ thống dữ liệu hiện đại
Để xây dựng một kiến trúc linh hoạt, chúng ta cần phân loại metadata thành các nhóm chức năng rõ rệt:
- Technical Metadata (Metadata kỹ thuật): Mô tả cấu trúc vật lý của dữ liệu như tên bảng, tên cột, kiểu dữ liệu (Data Type), độ dài trường thông tin và các chỉ mục (Indexes).
- Operational Metadata (Metadata vận hành): Lưu trữ thông tin về lịch trình chạy (Schedule), trạng thái của các job (Success/Fail), thời gian xử lý và lịch sử các lần chạy pipeline.
- Lineage Metadata (Metadata nguồn gốc): Ghi lại dấu chân của dữ liệu – nó đến từ đâu, đi qua những bước transform nào và đích đến cuối cùng là dashboard hay ứng dụng nào.
Tầm quan trọng của metadata không dừng lại ở việc tra cứu. Trong một hệ thống quy mô lớn, metadata chính là “bản đồ” giúp các kỹ sư hiểu rõ sự phụ thuộc giữa các dataset, từ đó quản lý rủi ro và thực hiện các thay đổi một cách an toàn.
2. Metadata-Driven Architecture: Khi Metadata nắm quyền điều khiển
Metadata-Driven Architecture là một kiến trúc hệ thống nơi mà logic xử lý dữ liệu không được viết cố định trong mã nguồn. Thay vào đó, mã nguồn được thiết kế như một “khung sườn” chung (Generic Engine). Engine này sẽ truy vấn thông tin từ một kho lưu trữ metadata để biết mình cần phải làm gì tiếp theo.
Cách thức vận hành của một Metadata-Driven Pipeline
Thay vì một file Python chỉ dành riêng cho việc lấy dữ liệu từ bảng Orders, chúng ta xây dựng một Pipeline Engine chung. Khi Engine này bắt đầu chạy, nó sẽ thực hiện các bước:
- Truy vấn Metadata: Engine hỏi kho lưu trữ: “Hôm nay tôi cần xử lý những bảng nào?”.
- Đọc chỉ dẫn: Metadata trả về danh sách các bảng kèm theo thông tin về kết nối (Source), quy tắc biến đổi (Transformation Rules) và vị trí đích (Target).
- Thực thi động: Engine tự động tạo ra logic xử lý dựa trên các tham số nhận được và thực hiện công việc.
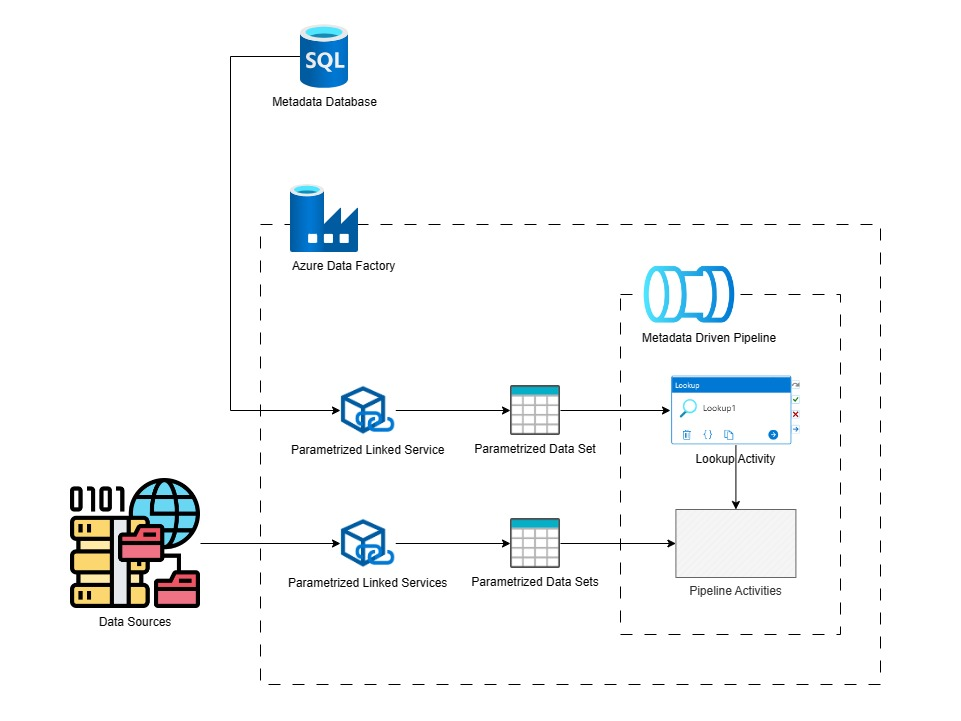
So sánh Pipeline truyền thống và Metadata-Driven Pipeline
Sự khác biệt lớn nhất nằm ở khả năng mở rộng (Scalability). Trong khi pipeline truyền thống yêu cầu bạn phải viết thêm code cho mỗi dataset mới (tỷ lệ thuận với công sức và lỗi), thì với metadata-driven, bạn chỉ cần thêm một dòng cấu hình vào database metadata. Logic xử lý vẫn giữ nguyên, giúp giảm thiểu tối đa rủi ro sai sót do con người.
3. Các thành phần then chốt của Metadata-Driven Data Pipeline
Để triển khai kiến trúc này một cách chuyên nghiệp, bạn cần xây dựng một hệ sinh thái gồm 4 thành phần cốt lõi:
3.1. Metadata Repository (Kho lưu trữ Metadata)
Đây là “bộ não” của toàn bộ hệ thống. Nó thường là một Database quan hệ (như PostgreSQL) hoặc một Metadata Catalog chuyên dụng. Nơi này lưu trữ tất cả các quy tắc, tham số và cấu hình của các pipeline. Việc thiết kế schema cho repository này cực kỳ quan trọng vì nó quyết định độ linh hoạt của toàn hệ thống.
3.2. Pipeline Engine (Công cụ thực thi)
Đây là “trái tim” thực hiện công việc. Engine này có thể là các Spark Jobs được viết dưới dạng thư viện chung, hoặc các workflow được điều phối bởi Apache Airflow. Điểm đặc biệt là Engine này không chứa các thông tin cụ thể về bảng hay cột, nó hoàn toàn sống dựa trên các tham số (parameters) truyền vào từ kho metadata.
3.3. Transformation Logic (Logic biến đổi động)
Trong kiến trúc này, các quy tắc biến đổi như lọc dữ liệu, tính toán hay mapping cột được định nghĩa dưới dạng các biểu thức SQL hoặc JSON trong metadata. Khi chạy, Engine sẽ “phiên dịch” các quy tắc này thành các câu lệnh thực thi thực tế trên Data Warehouse hoặc Data Lake.
3.4. Data Storage Layer (Tầng lưu trữ dữ liệu)
Nơi dữ liệu thực tế trú ngụ, từ Data Lake (S3, GCS) cho đến các Data Warehouse (BigQuery, Snowflake). Hệ thống metadata phải liên kết chặt chẽ với tầng này để biết chính xác vị trí dữ liệu và các phân vùng (partitions) cần xử lý.
4. Workflow thực thi: Hành trình của một Pipeline thông minh
Quy trình vận hành của một hệ thống metadata-driven thường diễn ra theo 4 bước chặt chẽ:
- Định nghĩa Metadata: Data Engineer hoặc Data Steward nhập thông tin về dataset mới vào repository. Ví dụ: Tên bảng là Customers, nguồn là Salesforce API, tần suất chạy là Hàng giờ.
- Truy vấn và Lập lịch: Pipeline Engine (thông qua công cụ điều phối như Airflow) định kỳ truy vấn repository để nhận diện các task cần thực hiện.
- Tạo luồng xử lý động: Dựa trên metadata, Engine khởi tạo các kết nối đến hệ thống nguồn, áp dụng các quy tắc kiểm tra chất lượng (Data Quality) và thực hiện biến đổi dữ liệu.
- Ghi nhận kết quả: Sau khi hoàn thành, Engine cập nhật lại trạng thái vào Metadata Repository (Operational Metadata), ghi lại log và bắn thông báo nếu có lỗi xảy ra.
5. Lợi ích đột phá của việc ứng dụng Metadata-Driven Pipeline
Tại sao các doanh nghiệp công nghệ lớn đều chuyển hướng sang kiến trúc này? Câu trả lời nằm ở 4 lợi ích mang tính chiến lược:
Tăng tốc độ mở rộng hệ thống (Scalability): Bạn có thể bổ sung hàng trăm pipeline mới chỉ bằng cách cập nhật metadata mà không cần deploy lại mã nguồn. Điều này đặc biệt quan trọng trong các dự án di cư dữ liệu (Data Migration) quy mô lớn.
Giảm thiểu tối đa lượng Code (DRY – Don’t Repeat Yourself): Việc duy trì một bộ code chung cho hàng nghìn pipeline giúp giảm bớt gánh nặng bảo trì. Khi có một lỗi logic trong Engine, bạn chỉ cần sửa ở một nơi duy nhất thay vì phải rà soát hàng trăm script khác nhau.
Hỗ trợ quản trị dữ liệu (Data Governance): Vì mọi thông tin về pipeline đều được lưu tập trung, việc theo dõi Lineage (nguồn gốc) và Ownership (người sở hữu) trở nên minh bạch. Bạn có thể dễ dàng trả lời câu hỏi: “Bảng dữ liệu này đến từ đâu và ai chịu trách nhiệm về nó?”.
Khả năng tự phục hồi (Self-healing): Với metadata vận hành chi tiết, hệ thống có thể tự động quyết định việc chạy lại (Retry) các job bị lỗi dựa trên các quy tắc đã định nghĩa trước mà không cần sự can thiệp thủ công của kỹ sư.
6. Thách thức và Những điều cần lưu ý
Dù mang lại sức mạnh to lớn, nhưng “với quyền lực lớn lao là trách nhiệm nặng nề”. Kiến trúc metadata-driven không phải là không có những rào cản:
- Độ phức tạp trong thiết kế ban đầu: Việc xây dựng một Pipeline Engine đủ mạnh và linh hoạt để xử lý mọi trường hợp (Edge cases) đòi hỏi kỹ năng lập trình và tư duy hệ thống rất cao.
- Debug trở nên khó khăn hơn: Vì pipeline được tạo ra động lúc runtime, việc truy vết lỗi không còn đơn giản là đọc một file code. Bạn cần một hệ thống logging cực tốt để biết chính xác tham số nào đã gây ra lỗi.
- Rủi ro từ Metadata Repository: Nếu kho metadata bị lỗi hoặc dữ liệu trong đó bị sai, toàn bộ hệ thống pipeline sẽ “mù quáng” thực hiện theo những chỉ dẫn sai lệch đó. Bảo vệ và kiểm soát chất lượng chính cho kho metadata là nhiệm vụ ưu tiên hàng đầu.
7. Kết luận
Metadata-Driven Data Pipeline không chỉ là một xu hướng kỹ thuật, nó là biểu hiện của sự trưởng thành trong tư duy Data Engineering. Nó dịch chuyển trọng tâm từ việc “viết code để xử lý dữ liệu” sang việc “xây dựng hệ thống tự động hóa xử lý dữ liệu”.
Trong tương lai, khi các hệ thống dữ liệu ngày càng trở nên phức tạp và khối lượng thông tin không ngừng gia tăng, việc sở hữu một kiến trúc linh hoạt dựa trên metadata chính là lợi thế cạnh tranh cốt lõi. Nó cho phép các tổ chức phản ứng nhanh hơn với các thay đổi kinh doanh, quản trị dữ liệu tốt hơn và quan trọng nhất là giải phóng các Data Engineer khỏi những công việc thủ công lặp lại để tập trung vào những giá trị sáng tạo thực sự.
FAQ (Câu hỏi thường gặp)
Công cụ nào tốt nhất để xây dựng Metadata-Driven Pipeline?
Không có một công cụ duy nhất. Thông thường là sự kết hợp: Apache Airflow để điều phối, Spark hoặc dbt để xử lý, và một Database như PostgreSQL để lưu trữ metadata. Các công cụ quản lý metadata chuyên nghiệp như DataHub hay Amundsen cũng là những lựa chọn tuyệt vời để bổ trợ.
Kiến trúc này có phù hợp với các công ty nhỏ không?
Nếu bạn chỉ có dưới 10 pipeline ổn định, việc xây dựng metadata-driven có thể là “overkill” (quá mức cần thiết). Tuy nhiên, nếu bạn dự kiến hệ thống sẽ mở rộng nhanh chóng trong tương lai, việc đặt nền móng bằng metadata ngay từ đầu sẽ giúp bạn tiết kiệm rất nhiều công sức về sau.
Làm sao để đảm bảo an toàn cho Metadata Repository?
Hãy coi kho metadata như một hệ thống production quan trọng nhất. Áp dụng các biện pháp: Backup định kỳ, kiểm soát quyền truy cập chặt chẽ (RBAC), và quan trọng nhất là áp dụng chính chính sách Data Validation cho chính các bản ghi metadata trước khi chúng được đưa vào sử dụng.
INDA Academy tự hào là đơn vị tiên phong trong việc đào tạo phân tích dữ liệu và AI chuyên sâu, đặc biệt cho khối ngành Ngân hàng – Tài chính – Bảo hiểm tại Việt Nam. Sau hơn 12 năm “thực chiến” cùng những dòng chảy dữ liệu khổng lồ, chúng tôi đã xây dựng nên một hệ sinh thái đào tạo toàn diện, giúp hàng nghìn học viên chuyển mình từ người mới bắt đầu trở thành những chuyên gia lành nghề, sẵn sàng đáp ứng tiêu chuẩn khắt khe của các doanh nghiệp lớn.
Điểm khác biệt lớn nhất tại INDA chính là triết lý đào tạo dựa trên các dự án thực tế (Project-based) và lộ trình cá nhân hóa nhờ ứng dụng AI. Chúng tôi không chỉ dạy bạn cách sử dụng công cụ, mà còn truyền tải tư duy khai phá giá trị từ dữ liệu để đưa ra quyết định kinh doanh chính xác.
Tìm hiểu thêm về các khóa học TẠI ĐÂY:
Lộ trình đào tạo Data Engineer
Lộ trình đào tạo Data Analyst
Lộ trình đào tạo Tester
Khóa học Data Engineer nâng cao – Thực chiến 5 dự án doanh nghiệp
Khóa học Data Analyst nâng cao – Thực chiến 5 dự án doanh nghiệp
Bài viết liên quan:
 Docker for Data Pipelines: Chuẩn hóa môi trường và tối ưu hóa triển khai trong Data Engineering
Docker for Data Pipelines: Chuẩn hóa môi trường và tối ưu hóa triển khai trong Data Engineering
 Data Pipeline Testing: Chiến lược kiểm thử để bảo vệ “mạch máu” dữ liệu doanh nghiệp
Data Pipeline Testing: Chiến lược kiểm thử để bảo vệ “mạch máu” dữ liệu doanh nghiệp
 CI/CD for Data Pipelines: Cách tự động hóa triển khai và tối ưu vận hành hệ thống dữ liệu
CI/CD for Data Pipelines: Cách tự động hóa triển khai và tối ưu vận hành hệ thống dữ liệu
 Data Incident Management: Khi Dashboard không còn nói lời thật lòng
Data Incident Management: Khi Dashboard không còn nói lời thật lòng
 Data Pipeline Thực Tế: Cách Doanh Nghiệp Xử Lý Dữ Liệu Từ A-Z
Data Pipeline Thực Tế: Cách Doanh Nghiệp Xử Lý Dữ Liệu Từ A-Z
 Monitoring chiến lược cho Data Pipeline: Bảo chứng niềm tin cho hệ thống dữ liệu hiện đại
Monitoring chiến lược cho Data Pipeline: Bảo chứng niềm tin cho hệ thống dữ liệu hiện đại