

Trong thế giới của các quyết định dựa trên dữ liệu, Dashboard và báo cáo kinh doanh chính là “la bàn” dẫn đường cho doanh nghiệp. Nhưng chuyện gì sẽ xảy ra nếu chiếc la bàn đó chỉ sai hướng? Một lỗi nhỏ trong quá trình biến đổi dữ liệu (Transformation) hay một sự thay đổi cấu trúc bảng (Schema Change) âm thầm từ phía hệ thống nguồn có thể khiến con số doanh thu trên Dashboard bị thổi phồng hoặc sụt giảm ảo.
Nếu code của một ứng dụng bị lỗi, người dùng có thể nhận thấy ngay lập tức qua các thông báo crash. Nhưng nếu dữ liệu bị lỗi, hệ thống vẫn “chạy xanh”, chỉ có kết quả là rác (Garbage In, Garbage Out). Đây chính là lúc Data Pipeline Testing trở thành chốt chặn sống còn, đảm bảo rằng mỗi byte dữ liệu đi qua hệ thống đều giữ được tính vẹn toàn và độ tin cậy tuyệt đối.
Mục lục
1. Bản chất của Data Pipeline Testing là gì?
Nói một cách thực dụng nhất, Data Pipeline Testing là quá trình xác minh và kiểm chứng tính đúng đắn của dữ liệu khi nó di chuyển qua các giai đoạn từ Ingestion (Thu thập), Transformation (Biến đổi) cho đến Load (Nạp vào kho). Khác với việc kiểm thử phần mềm truyền thống vốn tập trung vào logic của code và giao diện người dùng, kiểm thử pipeline dữ liệu tập trung vào chính “vật chất” bên trong: Dữ liệu.
Sự khác biệt mang tính hệ thống giữa Software Testing và Data Testing
Chúng ta cần phân biệt rõ hai khái niệm này để có chiến lược tiếp cận đúng đắn:
- Software Testing: Kiểm tra xem một chức năng (Function) có trả về kết quả mong đợi với một đầu vào nhất định hay không. Nó mang tính tĩnh và dễ dự đoán.
- Data Pipeline Testing: Đối mặt với sự biến thiên liên tục. Bạn không chỉ test code (ví dụ: script Python hay SQL), mà bạn còn test sự biến động của dữ liệu. Dữ liệu thực tế thường “lộn xộn”, không hoàn hảo và có thể thay đổi cấu trúc bất cứ lúc nào mà không báo trước.
2. Tại sao chúng ta không thể bỏ qua bước Testing trong Pipeline?
Việc duy trì một hệ thống dữ liệu không có kiểm thử giống như xây một cây cầu mà không kiểm tra khả năng chịu lực của vật liệu.
Đảm bảo tính chính xác của logic biến đổi: Khi bạn thực hiện các phép JOIN giữa hàng chục bảng hay tính toán các chỉ số phức tạp như LTV (Lifetime Value), chỉ cần một sơ suất nhỏ trong câu lệnh SQL cũng có thể làm sai lệch hoàn toàn bản chất của dữ liệu. Testing giúp xác nhận logic này hoạt động đúng với mọi trường hợp biên.
Phát hiện lỗi sớm (Shift Left Testing): Chi phí để sửa một lỗi dữ liệu trên môi trường Production thường cao gấp nhiều lần so với việc phát hiện nó ngay từ lúc phát triển. Khi dữ liệu sai đã lan vào Warehouse và được các Stakeholders sử dụng, việc “dọn dẹp” và khôi phục niềm tin là một quá trình cực kỳ tốn kém.
Tăng độ tin cậy cho hệ thống Analytics: Một đội ngũ Data Engineering giỏi không chỉ xây dựng pipeline nhanh, mà còn phải xây dựng pipeline đáng tin. Khi Dashboard luôn hiển thị số liệu chuẩn xác, niềm tin của Ban lãnh đạo vào dữ liệu sẽ được củng cố, từ đó thúc đẩy văn hóa Data-driven trong doanh nghiệp.
3. Các loại hình kiểm thử “vàng” trong chiến lược Data Testing
Để bao quát toàn bộ rủi ro, một chiến lược Data Pipeline Testing toàn diện cần được chia nhỏ thành các lớp bảo vệ sau:
3.1. Schema Testing (Kiểm thử cấu trúc)
Đây là lớp phòng thủ đầu tiên. Nó đảm bảo rằng “hình hài” của dữ liệu không bị thay đổi đột ngột.
Mục tiêu: Kiểm tra tên cột, kiểu dữ liệu (Data Type), và sự tồn tại của các trường bắt buộc.
Ví dụ: Nếu hệ thống Backend bỗng dưng đổi cột user_id từ kiểu Integer sang String, Schema Test sẽ bắn cảnh báo ngay lập tức để ngăn pipeline bị crash ở các bước phía sau.
3.2. Data Completeness Testing (Kiểm thử tính đầy đủ)
Đảm bảo rằng không có bản ghi nào bị “bốc hơi” trong quá trình di chuyển.
Mục tiêu: So khớp số lượng dòng dữ liệu (Row Count) giữa hệ thống nguồn và Warehouse.
Tình huống thực tế: Nếu nguồn có 1.000 đơn hàng nhưng đích đến chỉ nhận được 950, bạn cần biết 50 đơn hàng kia đã đi đâu.
3.3. Data Accuracy Testing (Kiểm thử độ chính xác)
Đây là phần khó nhất, yêu cầu sự am hiểu sâu sắc về nghiệp vụ (Business Logic).
Mục tiêu: Xác minh các phép tính toán (SUM, AVG, MIN, MAX) và các quy tắc nghiệp vụ.
Ví dụ: Tổng doanh thu trên báo cáo phải bằng tổng giá trị của từng đơn hàng cộng lại sau khi trừ đi khuyến mãi.
3.4. Data Consistency Testing (Kiểm thử tính nhất quán)
Dữ liệu về một thực thể phải giống nhau dù bạn truy vấn từ bất kỳ hệ thống nào.
Mục tiêu: Đảm bảo cùng một khách hàng không có hai địa chỉ khác nhau trong hai bảng báo cáo khác nhau do lỗi đồng bộ.
3.5. Data Freshness Testing (Kiểm thử độ tươi mới)
Trong phân tích hiện đại, dữ liệu cũ là dữ liệu vô giá trị.
Mục tiêu: Đo lường độ trễ (Data Delay). Nếu dữ liệu hôm nay vẫn chưa được nạp xong vào lúc 8h sáng, hệ thống phải tự động thông báo cho đội ngũ kỹ thuật.
4. Quy trình triển khai Data Pipeline Testing chuẩn chuyên gia
Việc kiểm thử không nên diễn ra một cách ngẫu hứng. Bạn cần một quy trình có tính lặp lại và tự động hóa cao.
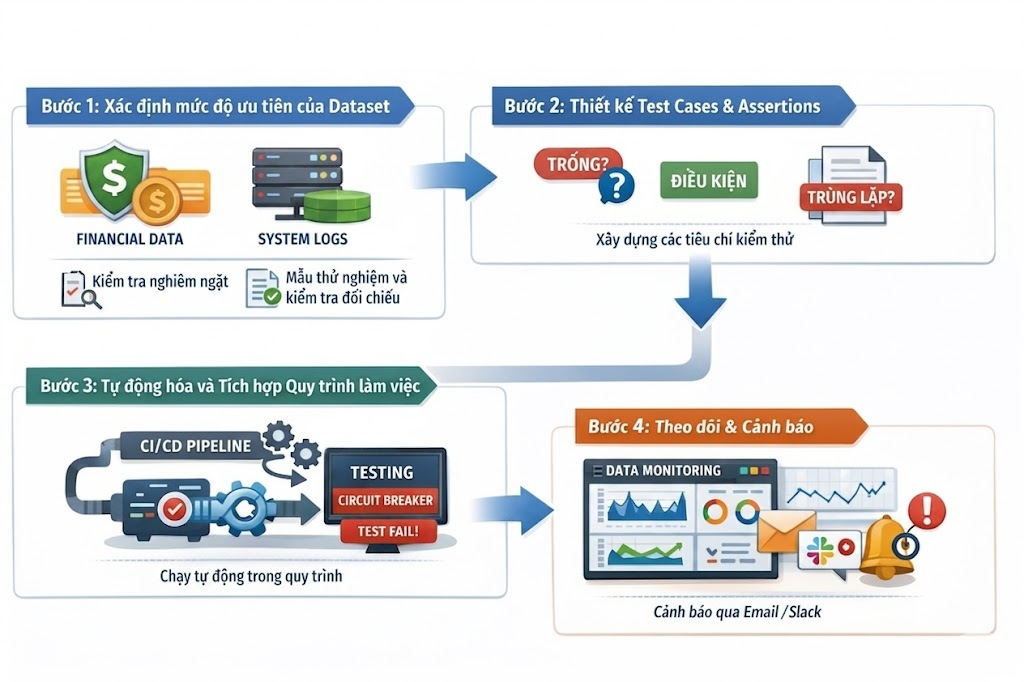
Bước 1: Xác định mức độ ưu tiên của Dataset
Không phải mọi dữ liệu đều bình đẳng. Dữ liệu tài chính (Financial Data) cần được test ở mức độ nghiêm ngặt nhất (kiểm tra từng dòng), trong khi dữ liệu Log hệ thống có thể chỉ cần test mẫu hoặc kiểm tra tính đầy đủ ở mức độ tương đối.
Bước 2: Thiết kế Test Cases và Assertions
Hãy bắt đầu bằng những câu hỏi:
- Cột này có được phép Null không?
- Giá trị trong cột này có nằm trong khoảng từ A đến B không?
- Có bản ghi nào bị trùng lặp (Duplicate) không? Việc thiết lập các “chốt chặn” (Assertions) này ngay trong mã nguồn sẽ giúp hệ thống tự động kiểm tra mỗi khi chạy.
Bước 3: Tự động hóa và tích hợp vào Workflow
Testing không nên là một bước tách rời thực hiện bằng tay. Nó phải là một phần của CI/CD pipeline. Sau khi dữ liệu được transform, các bài test sẽ tự động chạy. Nếu test fail, pipeline sẽ dừng lại (Circuit Breaker) để ngăn rác lan vào hệ thống hạ tầng phía sau.
Bước 4: Theo dõi và Cảnh báo (Monitoring & Alerting) Mọi kết quả test cần được ghi lại (Log) và hiển thị trên Dashboard giám sát sức khỏe dữ liệu. Khi có lỗi nghiêm trọng, hệ thống phải gửi thông báo qua Slack hoặc Email cho đội trực kỹ thuật.
5. Những “trợ thủ” đắc lực trong làng Data Testing
Để hiện thực hóa chiến lược kiểm thử, bạn không cần phải “phát minh lại bánh xe”. Có rất nhiều công cụ mạnh mẽ hỗ trợ:
- dbt Tests: Tuyệt vời cho việc kiểm thử ngay trong quá trình biến đổi dữ liệu bằng SQL. Hỗ trợ sẵn các test cơ bản như unique, not_null, relationships.
- Great Expectations: Một thư viện Python cực kỳ mạnh mẽ cho phép bạn định nghĩa các “kỳ vọng” về dữ liệu dưới dạng code và tự động tạo ra các báo cáo chất lượng dữ liệu chuyên nghiệp.
- Soda: Công cụ hiện đại giúp kết nối giữa đội ngũ Data và Business để cùng định nghĩa các tiêu chuẩn về dữ liệu thông qua ngôn ngữ dễ hiểu.
- Apache Airflow: Công cụ điều phối (Orchestration) cho phép bạn lồng ghép các bước kiểm tra vào giữa các task xử lý dữ liệu.
6. Thách thức: Con đường không trải hoa hồng
Triển khai Data Pipeline Testing là một cuộc chiến dài kỳ với nhiều trở ngại:
- Khối lượng dữ liệu khổng lồ: Việc so sánh từng dòng dữ liệu trên hàng tỷ bản ghi sẽ làm chậm pipeline và tiêu tốn cực kỳ nhiều tài nguyên tính toán (Cost). Giải pháp là áp dụng chiến lược Sampling (lấy mẫu) hoặc kiểm tra các chỉ số tổng hợp (Aggregated Metrics).
- Sự phức tạp của phụ thuộc (Dependencies): Một thay đổi ở upstream có thể làm hỏng hàng loạt bài test ở downstream. Bạn cần có một hệ thống Data Lineage rõ ràng để biết lỗi bắt đầu từ đâu.
- Môi trường Test (Test Environments): Việc tạo ra một môi trường có dữ liệu giống hệt Production nhưng vẫn đảm bảo bảo mật thông tin khách hàng là một thách thức về mặt kỹ thuật.
7. Kết luận
Data Pipeline Testing không phải là một công việc nhàm chán; đó là nghệ thuật bảo vệ sự thật trong doanh nghiệp. Một hệ thống dữ liệu không được kiểm thử cũng giống như một dây chuyền sản xuất thực phẩm không có khâu kiểm soát vệ sinh – sớm muộn gì nó cũng sẽ gây ra sự cố.
Bằng cách tự động hóa các bài kiểm tra cấu trúc, tính đầy đủ và độ chính xác, bạn không chỉ giúp đội ngũ Data Engineering làm việc hiệu quả hơn mà còn cung cấp cho doanh nghiệp một nền tảng dữ liệu vững chắc. Hãy nhớ: Niềm tin vào dữ liệu rất khó để xây dựng nhưng lại cực kỳ dễ bị phá vỡ chỉ bởi một con số sai. Đừng để pipeline của bạn chạy mà thiếu đi những bài test chất lượng.
FAQ (Câu hỏi thường gặp về Data Pipeline Testing)
Nên test bao nhiêu phần trăm dữ liệu là đủ?
Không có con số cố định. Với dữ liệu quan trọng, hãy test 100%. Với dữ liệu lớn và ít quan trọng hơn, việc lấy mẫu (Sampling) 5-10% có thể giúp cân bằng giữa chi phí và độ phủ.
Ai là người chịu trách nhiệm viết Test Cases?
Data Engineer là người hiện thực hóa kỹ thuật, nhưng Data Analyst và Business User mới là những người hiểu rõ quy tắc nghiệp vụ nhất. Một sự phối hợp chặt chẽ giữa các bên là chìa khóa để có những bộ test case chất lượng.
Có nên dừng pipeline ngay khi phát hiện lỗi không?
Phụ thuộc vào mức độ nghiêm trọng. Với lỗi Schema Change, nên dừng ngay để tránh hỏng hệ thống hạ tầng. Với lỗi nhỏ về tính chính xác, bạn có thể cho pipeline chạy tiếp nhưng phải bắn cảnh báo và đánh dấu (Flag) các bản ghi bị lỗi để người dùng biết.
INDA Academy tự hào là đơn vị tiên phong trong việc đào tạo phân tích dữ liệu và AI chuyên sâu, đặc biệt cho khối ngành Ngân hàng – Tài chính – Bảo hiểm tại Việt Nam. Sau hơn 12 năm “thực chiến” cùng những dòng chảy dữ liệu khổng lồ, chúng tôi đã xây dựng nên một hệ sinh thái đào tạo toàn diện, giúp hàng nghìn học viên chuyển mình từ người mới bắt đầu trở thành những chuyên gia lành nghề, sẵn sàng đáp ứng tiêu chuẩn khắt khe của các doanh nghiệp lớn.
Điểm khác biệt lớn nhất tại INDA chính là triết lý đào tạo dựa trên các dự án thực tế (Project-based) và lộ trình cá nhân hóa nhờ ứng dụng AI. Chúng tôi không chỉ dạy bạn cách sử dụng công cụ, mà còn truyền tải tư duy khai phá giá trị từ dữ liệu để đưa ra quyết định kinh doanh chính xác.
Tìm hiểu thêm về các khóa học TẠI ĐÂY:
Lộ trình đào tạo Data Engineer
Lộ trình đào tạo Data Analyst
Lộ trình đào tạo Tester
Khóa học Data Engineer nâng cao – Thực chiến 5 dự án doanh nghiệp
Khóa học Data Analyst nâng cao – Thực chiến 5 dự án doanh nghiệp
Bài viết liên quan:
 Docker for Data Pipelines: Chuẩn hóa môi trường và tối ưu hóa triển khai trong Data Engineering
Docker for Data Pipelines: Chuẩn hóa môi trường và tối ưu hóa triển khai trong Data Engineering
 CI/CD for Data Pipelines: Cách tự động hóa triển khai và tối ưu vận hành hệ thống dữ liệu
CI/CD for Data Pipelines: Cách tự động hóa triển khai và tối ưu vận hành hệ thống dữ liệu
 Data Pipeline Debugging: Nghệ Thuật Tìm Root Cause Khi Hệ Thống Dữ Liệu “Gãy Đổ”
Data Pipeline Debugging: Nghệ Thuật Tìm Root Cause Khi Hệ Thống Dữ Liệu “Gãy Đổ”
 Data Incident Management: Khi Dashboard không còn nói lời thật lòng
Data Incident Management: Khi Dashboard không còn nói lời thật lòng
 Data Pipeline Thực Tế: Cách Doanh Nghiệp Xử Lý Dữ Liệu Từ A-Z
Data Pipeline Thực Tế: Cách Doanh Nghiệp Xử Lý Dữ Liệu Từ A-Z
 Late-arriving Data: Khi dữ liệu “đi lạc” và bài toán về tính chính xác trong Data Warehouse
Late-arriving Data: Khi dữ liệu “đi lạc” và bài toán về tính chính xác trong Data Warehouse