
Last updated on January 28th, 2026 at 09:59 am
Giới thiệu GridFS
GridFS là MongoDB Specification để lưu giữ và thu thập các file lớn như các image, audio, video file,… Nó là một loại của hệ thống file để lưu giữ các file nhưng dữ liệu của nó được lưu giữ bên trong các Collection của MongoDB. GridFS có khả năng lưu giữ các file ngay cả khi kích cỡ của nó lớn hơn giới hạn kích cỡ là 16 MB của Document.
GridFS phân chia một file thành các Chunk và lưu giữ mỗi mảng dữ liệu trong một Document riêng, kích cỡ tối đa của nó là 255k.
Theo mặc định, GridFS sử dụng hai Collection là fs.files và fs.chunks để lưu giữ metadata của file và các chunk. Mỗi Chunk được nhận diện bởi trường _id ObjectId duy nhất. fs.files hoạt động như là một Document cha. Trường files_id trong fs.chunks liên kết Chunk tới Document cha của nó.
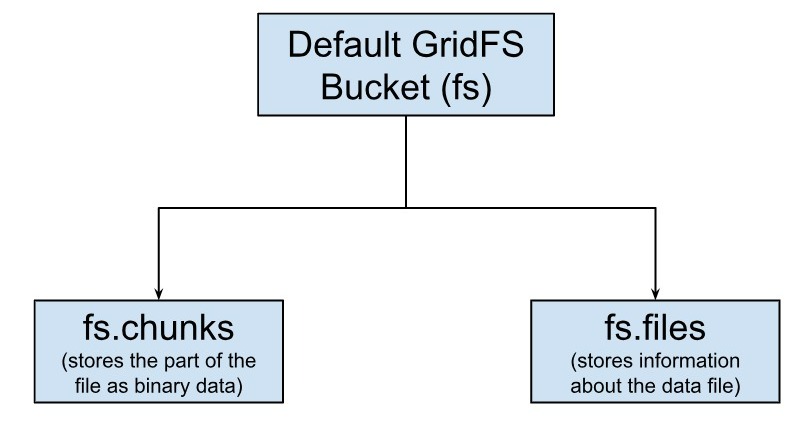
Dưới đây là Document mẫu của fs.files collection:
{
"filename": "test.txt",
"chunkSize": NumberInt(261120),
"uploadDate": ISODate("2014-04-13T11:32:33.557Z"),
"md5": "7b762939321e146569b07f72c62cca4f",
"length": NumberInt(646)
}Document xác định tên file, kích cỡ chunk, ngày cập nhật, và độ dài.
Dưới đây là Document mẫu của fs.chunks document:
{
"files_id": ObjectId("534a75d19f54bfec8a2fe44b"),
"n": NumberInt(0),
"data": "Mongo Binary Data"
}Thêm File tới GridFS
Bây giờ, chúng ta sẽ lưu giữ một mp3 file bởi sử dụng GridFS với lệnh put. Chúng ta sẽ sử dụng tiện ích mongofiles.exe có trong thư mục bin của thư mục cài đặt MongoDB.
Mở dòng nhắc lệnh, điều hướng tới mongofiles.exe trong thư mục bin của thư mục cài đặt MongoDB và soạn code sau:
>mongofiles.exe -d gridfs put song.mp3Ở đây, gridfs là tên của Database trong đó file sẽ được lưu giữ. Nếu Database này không tồn tại thì MongoDB sẽ tự động tạo một Document mới. song.mp3 là tên của file tải lên. Để quan sát Document của file trong Database, bạn sử dụng truy vấn find.
>db.fs.files.find()Lệnh trên sẽ cho kết quả:
{
_id: ObjectId('534a811bf8b4aa4d33fdf94d'),
filename: "song.mp3",
chunkSize: 261120,
uploadDate: new Date(1397391643474), md5: "e4f53379c909f7bed2e9d631e15c1c41",
length: 10401959
}Chúng ta cũng có thể quan sát tất cả các Chunk có mặt trong fs.chunks collection liên quan tới file được lưu giữ với phần code sau, sử dụng document id được trả về từ truy vấn trước.
>db.fs.chunks.find({files_id:ObjectId('534a811bf8b4aa4d33fdf94d')})Với tôi, truy vấn trả về 40 Document, nghĩa là toàn bộ mp3 document được phân chia thành 40 chunk.
Nguồn: Internet
INDA Academy tự hào là đơn vị tiên phong trong việc đào tạo phân tích dữ liệu và AI chuyên sâu, đặc biệt cho khối ngành Ngân hàng – Tài chính – Bảo hiểm tại Việt Nam. Sau hơn 12 năm “thực chiến” cùng những dòng chảy dữ liệu khổng lồ, chúng tôi đã xây dựng nên một hệ sinh thái đào tạo toàn diện, giúp hàng nghìn học viên chuyển mình từ người mới bắt đầu trở thành những chuyên gia lành nghề, sẵn sàng đáp ứng tiêu chuẩn khắt khe của các doanh nghiệp lớn.
Điểm khác biệt lớn nhất tại INDA chính là triết lý đào tạo dựa trên các dự án thực tế (Project-based) và lộ trình cá nhân hóa nhờ ứng dụng AI. Chúng tôi không chỉ dạy bạn cách sử dụng công cụ, mà còn truyền tải tư duy khai phá giá trị từ dữ liệu để đưa ra quyết định kinh doanh chính xác.
Tìm hiểu thêm về các khóa học TẠI ĐÂY:
Lộ trình đào tạo Data Engineer
Lộ trình đào tạo Data Analyst
Lộ trình đào tạo Tester
Khóa học Data Engineer nâng cao – Thực chiến 5 dự án doanh nghiệp
Khóa học Data Analyst nâng cao – Thực chiến 5 dự án doanh nghiệp


