

Last updated on January 7th, 2026 at 09:53 am
Mục lục
1. Vì sao tối ưu hiệu suất truy vấn SQL vẫn là kỹ năng cốt lõi năm 2026?
Trong hơn 10 năm làm việc với các hệ thống dữ liệu từ OLTP đến Data Warehouse, tôi nhận thấy một điểm không thay đổi: phần lớn vấn đề hiệu suất hệ thống đều bắt nguồn từ truy vấn SQL kém tối ưu. Năm 2026, khi dữ liệu tăng nhanh, yêu cầu real-time cao hơn và SQL được dùng sâu trong AI/Analytics pipeline, tối ưu SQL không còn là kỹ năng “nice-to-have” mà là năng lực nền tảng.
SQL hiện diện trong:
- Ứng dụng backend và sản phẩm số (OLTP)
- Hệ thống BI, báo cáo, phân tích
- Feature Store và tầng serving cho AI/ML
Điều thay đổi không phải là SQL, mà là: dựa trên execution plan, dữ liệu thực tế và ngày càng có sự hỗ trợ của AI.
2. Phân tích Execution Plan – luôn là điểm bắt đầu đúng
2.1. Execution Plan nói lên điều gì?
Trong thực tế triển khai, hơn 80% các truy vấn “chậm không rõ lý do” mà tôi từng xử lý đều có thể giải thích rõ ràng khi nhìn vào execution plan. Execution plan cho biết database engine:
- Truy cập dữ liệu như thế nào (scan hay seek)
- Join các bảng theo thứ tự nào
- Tốn chi phí CPU, I/O ở đâu
Không có execution plan, mọi tối ưu chỉ là phỏng đoán.

2.2. Đọc execution plan theo tư duy hiện đại
Khi phân tích execution plan, cần tập trung vào:
- Full Table Scan xuất hiện ở đâu và vì sao
- Nested Loop Join trên tập dữ liệu lớn
- Cardinality Estimation bị sai lệch
- Sự khác biệt giữa Estimated Plan và Actual Plan
Trong nhiều hệ thống doanh nghiệp, chỉ cần sửa một cardinality estimation sai đã giúp query nhanh hơn từ vài giây xuống vài trăm mili-giây.
3. Indexing hiện đại: đúng quan trọng hơn nhiều
3.1. Nguyên tắc tạo index hiệu quả
Một lỗi tôi thường thấy ở học viên và cả đội kỹ thuật là tạo index theo cảm giác. Index chỉ thực sự hiệu quả khi:
- Phục vụ trực tiếp cho WHERE, JOIN, ORDER BY, GROUP BY
- Được thiết kế đúng thứ tự cột trong composite index
- Không bị lạm dụng quá mức
Trong các hệ thống OLTP lớn, việc tạo sai index không chỉ làm query chậm mà còn ảnh hưởng nghiêm trọng đến hiệu suất ghi dữ liệu.
3.2. Xu hướng index năm 2026
So với giai đoạn 2020–2022, indexing đã tiến xa hơn:
- Covering Index giúp tránh truy cập bảng gốc
- Filtered / Partial Index giảm kích thước index
- BRIN Index đặc biệt hiệu quả với bảng hàng trăm triệu dòng có tính tuần tự
- AI-driven index recommendation ngày càng phổ biến trong các database hiện đại
Trong một hệ thống log >1 tỷ bản ghi tôi từng tham gia tối ưu, việc chuyển từ B-tree sang BRIN index đã giảm thời gian truy vấn hơn 70%.
4. Tối ưu cấu trúc câu truy vấn SQL
4.1. Tránh SELECT * – nguyên tắc cơ bản nhưng thường bị bỏ qua
SELECT * làm tăng I/O, memory và network overhead. Trong các pipeline analytics, điều này còn gây lãng phí tài nguyên downstream. Nguyên tắc đơn giản nhưng hiệu quả: chỉ lấy những cột thực sự cần dùng.
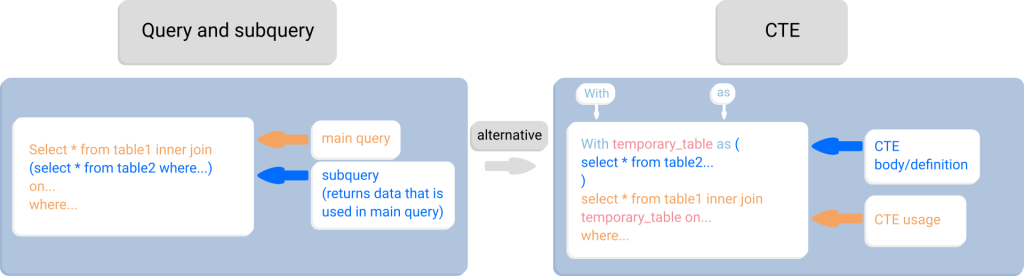
4.2. JOIN, Subquery và CTE – hiểu đúng để dùng đúng
Không phải lúc nào CTE cũng chậm, nhưng cũng không phải lúc nào cũng nhanh. Tôi từng gặp nhiều trường hợp CTE được dùng để “làm code đẹp”, nhưng execution plan lại materialize toàn bộ CTE khiến query chậm gấp nhiều lần.
Nguyên tắc:
- Tránh correlated subquery trên bảng lớn
- Kiểm tra execution plan thay vì tin vào cú pháp
- Ưu tiên INNER JOIN khi logic cho phép
4.3. Tránh hàm trong WHERE
Ví dụ sai phổ biến:
WHERE YEAR(order_date) = 2024
Cách viết tối ưu hơn:
WHERE order_date >= ‘2024-01-01’
AND order_date < ‘2025-01-01’
Việc áp hàm lên cột thường khiến database không thể sử dụng index hiệu quả.
5. Statistics & Data Distribution – yếu tố quyết định nhưng hay bị quên
Query optimizer đưa ra quyết định dựa trên statistics. Trong các hệ thống có dữ liệu skew (lệch phân phối), statistics lỗi thời gần như chắc chắn dẫn đến execution plan sai.
Best practices:
- Bật auto-update statistics
- Refresh statistics sau khi dữ liệu thay đổi lớn
- Theo dõi hiệu suất truy vấn sau mỗi lần load dữ liệu
6. Partitioning & Schema Design cho dữ liệu lớn
6.1. Partitioning đúng giúp SQL nhanh vượt trội
Partitioning cho phép database chỉ scan phần dữ liệu cần thiết. Tôi từng thấy query báo cáo giảm từ vài phút xuống vài giây chỉ nhờ partition pruning đúng cách.
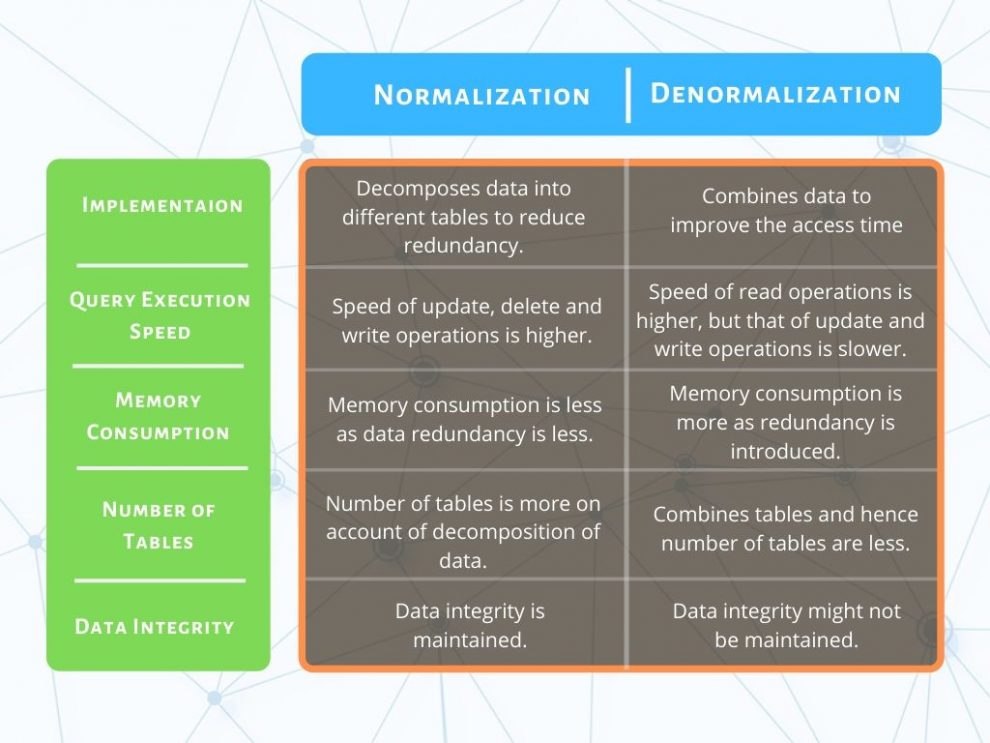
6.2. Normalization vs Denormalization
Năm 2026, nhiều hệ thống áp dụng thiết kế lai:
- Normalize cho transactional workload
- Denormalize cho reporting và analytics
Không có thiết kế đúng cho mọi hệ thống – chỉ có thiết kế phù hợp với workload thực tế.
7. Caching & Materialized Views
Query plan cache và result cache giúp giảm đáng kể chi phí CPU. Với các dashboard và báo cáo chạy lặp lại, materialized view là giải pháp cực kỳ hiệu quả nếu được refresh hợp lý.
8. Transaction, Locking và Concurrency
Hiệu suất SQL không chỉ nằm ở một câu query mà còn ở cách các query chạy đồng thời. Chọn isolation level phù hợp và giữ transaction ngắn là hai yếu tố then chốt để giảm lock contention và deadlock.
9. Monitoring & Observability – tối ưu là quá trình liên tục
Những hệ thống vận hành tốt đều theo dõi:
- Query latency (avg, p95, p99)
- CPU và I/O waits
- Blocking và deadlock
Monitoring giúp phát hiện performance regression sớm, trước khi người dùng nhận ra.
10. AI & Automated SQL Optimization – xu hướng không thể bỏ qua
AI ngày càng được dùng để:
- Đề xuất index
- Viết lại truy vấn
- Phát hiện query bất thường
Tuy AI chưa thay thế hoàn toàn DBA hay Data Engineer, nhưng nó giúp giảm đáng kể công việc thủ công và rút ngắn thời gian tối ưu.
11. Checklist nhanh khi gặp truy vấn SQL chậm
- Xem execution plan (actual)
- Kiểm tra index liên quan
- Kiểm tra statistics
- Kiểm tra volume dữ liệu và partition
- Kiểm tra concurrency và locking
Checklist này phản ánh đúng thứ tự xử lý trong các dự án tối ưu SQL thực tế.
12. Kết luận
Cải thiện hiệu suất truy vấn SQL năm 2026 không còn là vài mẹo cú pháp, mà là một tư duy hệ thống: hiểu dữ liệu, hiểu engine và hiểu cách workload vận hành. Những ai nắm vững tư duy này sẽ luôn có lợi thế bền vững trong các vai trò Data Analyst, Data Engineer và Backend Engineer.
INDA Academy tự hào là đơn vị tiên phong trong việc đào tạo phân tích dữ liệu và AI chuyên sâu, đặc biệt cho khối ngành Ngân hàng – Tài chính – Bảo hiểm tại Việt Nam. Sau hơn 12 năm “thực chiến” cùng những dòng chảy dữ liệu khổng lồ, chúng tôi đã xây dựng nên một hệ sinh thái đào tạo toàn diện, giúp hàng nghìn học viên chuyển mình từ người mới bắt đầu trở thành những chuyên gia lành nghề, sẵn sàng đáp ứng tiêu chuẩn khắt khe của các doanh nghiệp lớn.
Điểm khác biệt lớn nhất tại INDA chính là triết lý đào tạo dựa trên các dự án thực tế (Project-based) và lộ trình cá nhân hóa nhờ ứng dụng AI. Chúng tôi không chỉ dạy bạn cách sử dụng công cụ, mà còn truyền tải tư duy khai phá giá trị từ dữ liệu để đưa ra quyết định kinh doanh chính xác.
Tìm hiểu thêm về các khóa học TẠI ĐÂY
SQL Level 2: Advanced SQL (for Data Engineer) – Lập trình dữ liệu nâng cao
Bài viết liên quan:
 Hướng dẫn tối ưu hóa cấu trúc object, tablespace CSDL Oracle
Khi nào một index nên được xây dựng lại (rebuild) trong Oracle Database?
Tìm hiểu Index, Khi nào cần tạo index trong cơ sở dữ liệu ?
Hướng dẫn tối ưu hóa cấu trúc object, tablespace CSDL Oracle
Khi nào một index nên được xây dựng lại (rebuild) trong Oracle Database?
Tìm hiểu Index, Khi nào cần tạo index trong cơ sở dữ liệu ?
 TOP 6 CÁC TRANG WEB HỌC SQL TRỰC TUYẾN MIỄN PHÍ
TOP 6 CÁC TRANG WEB HỌC SQL TRỰC TUYẾN MIỄN PHÍ
 Các kiến thức cơ bản về SQL (Phần 1)
Các kiến thức cơ bản về SQL (Phần 1)