
Trong hệ thống chứng chỉ Trí tuệ nhân tạo (AI) toàn cầu hiện nay, Oracle AI Vector Search Professional (Mã đề 1Z0-184-25) là một trường hợp cực kỳ đặc biệt. Đại đa số các kỳ thi AI ngoài kia thường kiểm tra thí sinh về toán học thuật toán, cách viết code huấn luyện mô hình (Model Training) hay tinh chỉnh tham số chuyên sâu. Nhưng Oracle lại rẽ sang một hướng đi hoàn toàn khác: Họ kiểm tra năng lực Tư duy hệ thống và Vận hành hạ tầng dữ liệu.
Chính sự khác biệt này đã tạo nên một thực tế phũ phàng tại các trung tâm khảo thí: Rất nhiều kỹ sư dữ liệu, lập trình viên học thuộc làu làu các định nghĩa trên hệ thống bài giảng MyLearn của Oracle nhưng khi bước vào phòng thi vẫn nhận kết quả “Failed” như thường. Lý do không phải họ lười học, mà vì họ đã tiếp cận sai phương pháp ngay từ bước khởi đầu.
Bài viết chuyên sâu này của Học viện sẽ đóng vai trò là một người Mentor, đồng hành cùng bạn bóc tách lộ trình học tập (Learning Path), phân tích ma trận trọng số đề thi và chia sẻ chiến lược làm bài (Exam Mindset) giúp bạn cầm chắc tấm bằng Professional trong tay.

Mục lục
1. Giải Mã Nghịch Lý: Vì Sao Học Kỹ Nhưng Vẫn Trượt 1Z0-184-25?
Để không đi vào vết xe đổ của những người đi trước, bạn cần hiểu rõ cấu trúc bẫy của đề thi Oracle. Đề thi Professional của Oracle nói không với các câu hỏi lý thuyết suông kiểu: “HNSW là viết tắt của từ gì?” hay “Có bao nhiêu Distance Metrics?”.
Thay vào đó, Oracle sẽ quăng bạn vào một Bối cảnh dự án (Scenario-based) của một doanh nghiệp thực tế. Nhiều người tiếp cận theo kiểu xem video cho xong hoặc cố ghi nhớ khái niệm mà bỏ qua phần thực hành (Hands-on labs). Đề thi không hỏi lý thuyết phẳng, mà đặt bạn vào tình huống cụ thể và yêu cầu chọn giải pháp phù hợp. Nếu không hiểu trade-off (sự đánh đổi) giữa các lựa chọn, bạn rất dễ chọn sai dù đã học qua nội dung đó.
Một sai lầm khác là bỏ qua hands-on lab. Đây là phần giúp bạn hiểu cách hệ thống vận hành thực tế, đặc biệt là cách query và index ảnh hưởng trực tiếp đến kết quả. Khi không có trải nghiệm này, các câu hỏi dạng bối cảnh trở nên rất khó xử lý. Tóm lại, vấn đề không nằm ở lượng kiến thức, mà ở việc: bạn có hiểu cách hệ thống hoạt động và ra quyết định tối ưu hay không.
2. Bản Đồ Lộ Trình: Cấu Trúc Learning Path Chuẩn Từ Oracle University
Hệ thống bài giảng trên nền tảng MyLearn của Oracle không sắp xếp các chương một cách ngẫu nhiên. Họ thiết kế nội dung theo một dòng chảy kiến trúc (Pipeline Flow) mô phỏng chính xác hành trình của dữ liệu Vector ngoài đời thực. Lộ trình học tập này được phân rã thành 3 tầng cốt lõi sau:
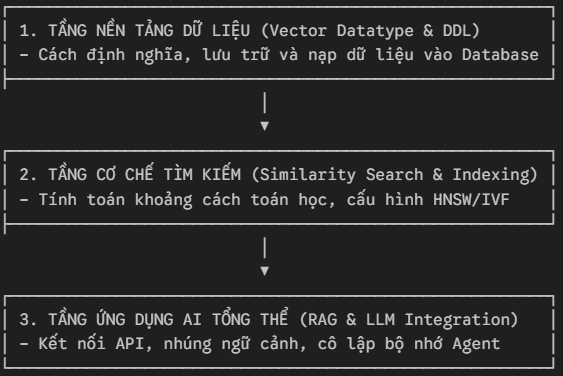
Chính vì vậy, nếu bạn chỉ học từng module riêng lẻ mà không nhìn được bức tranh tổng thể, bạn sẽ gặp khó khi làm bài. Đề thi thường đặt câu hỏi theo một pipeline hoàn chỉnh, ví dụ từ truy vấn -> thiết lập index -> trả về kết quả, chứ ít khi hỏi từng phần độc lập.
3. Ma Trận Trọng Số: Phần Nào Đáng Để Bạn “Đổ Mồ Hôi”?
Không phải phần nào trong learning path cũng có trọng số điểm như nhau. Nếu mục tiêu của bạn là vượt qua kỳ thi một cách hiệu quả nhất, việc ưu tiên đúng nội dung sẽ tạo ra sự khác biệt rõ rệt. Bạn cần thực hiện chiến lược “bắn có mục tiêu” – tập trung 80% công lực vào 20% vùng kiến thức chiếm điểm số cao nhất và có tính phân loại thí sinh mạnh nhất.
Dưới đây là bảng ma trận phân tích mức độ quan trọng của các Topic được tổng hợp từ kinh nghiệm của đội ngũ chuyên gia tại Học viện:
Bảng ma trận trọng số nội dung đề thi Oracle AI Vector Search Professional
| Chủ đề khảo sát (Topic) | Mức độ quan trọng | Ý nghĩa thực tế trong đề thi |
| Vector Indexing (HNSW vs. IVF) | 🔥 Cực kỳ Cao | Quyết định phần lớn các câu hỏi tình huống (Scenario). |
| Distance Metrics (Cosine, L2…) | 🔴 Cao | Gắn trực tiếp với cách thiết lập câu lệnh truy vấn. |
| Similarity Search Logic | 🔴 Cao | Nền tảng logic điều hướng của toàn bộ hệ thống. |
| RAG & AI Integration | 🟡 Trung bình | Xu hướng câu hỏi đang tăng mạnh trong các đợt cập nhật đề. |
| Embedding Generation | 🟡 Trung bình | Chủ yếu kiểm tra ở mức độ khái niệm và pipeline dữ liệu. |
| Vector Datatype / Syntax DDL | 🟢 Thấp | Ít câu hỏi đào sâu, chủ yếu là cú pháp khởi tạo cơ bản. |
4. Breakdown Chi Tiết Chiến Thuật Học Theo Góc Nhìn “Đi Thi”
4.1. Vector Fundamentals – Hiểu đủ để không sai phần nền
Phần này giúp bạn hiểu vector là gì và cách Oracle lưu trữ embedding trong database dưới dạng một kiểu dữ liệu bản địa. Tuy nhiên, đây không phải khu vực để bạn “ăn điểm” phân loại, mà là phần nền bắt buộc để hiểu các chương sau. Thí sinh không cần đi quá sâu vào toán học ma trận phức tạp hay cách các mô hình AI tạo ra embedding như thế nào, điều quan trọng là nắm vững cách dữ liệu được biểu diễn và sử dụng trong câu lệnh truy vấn SQL mở rộng.
4.2. Similarity Search – Nơi nhiều người học sai cách
Similarity search là cơ chế cốt lõi của vector search, nhưng cũng là phần dễ bị học sai nhất. Nhiều người cố ghi nhớ công thức, trong khi đề thi lại kiểm tra khả năng lựa chọn metric phù hợp với từng tình huống cụ thể của dữ liệu và bài toán kinh doanh.
Ba phương pháp phổ biến gồm Cosine similarity, L2 distance (Euclidean) và Inner product. Không có phương pháp nào tốt nhất trong mọi trường hợp. Nếu bạn không gắn công thức với context cụ thể (Ví dụ: Cosine dùng cho văn bản có độ dài không đồng đều, L2 dùng cho nhận diện hình ảnh/khuôn mặt), bạn sẽ rất dễ bị đánh lừa bởi các đáp án nhiễu có cấu trúc gần giống nhau.
4.3. Vector Indexing (HNSW vs. IVF) – Phần quyết định Pass hay Fail
Đây là phần quan trọng nhất trong toàn bộ kỳ thi. Hầu hết các câu hỏi phân loại có độ khó cao đều xoay quanh việc chọn loại index phù hợp dựa trên tư duy Trade-off (Sự đánh đổi):
- HNSW (Hierarchical Navigable Small World): Mang lại độ chính xác cực cao và tốc độ truy vấn tối ưu, nhưng đổi lại là chi phí bộ nhớ (RAM) rất lớn để duy trì cấu trúc đồ thị đa tầng. Hãy chọn HNSW khi bối cảnh đề bài yêu cầu Low Latency và High Accuracy.
- IVF (Inverted File Index): Cơ chế phân cụm không gian giúp IVF nhẹ hơn, phù hợp với dataset khổng lồ ở quy mô Enterprise nhưng hệ thống phải chấp nhận một mức sai số nhất định. Hãy chọn IVF khi đề bài nhấn mạnh vào yếu tố tiết kiệm tài nguyên phần cứng hoặc dữ liệu cực lớn.
Điểm mấu chốt là đề thi không hỏi định nghĩa của HNSW hay IVF, mà bắt bạn đóng vai một kiến trúc sư để lựa chọn giải pháp tối ưu cho một hạ tầng đang bị giới hạn phần cứng hoặc hiệu năng.
4.4. Embedding & RAG Integration – Xu hướng công nghệ mới
RAG (Retrieval-Augmented Generation) là ứng dụng quan trọng nhất của vector search ở thời điểm hiện tại. Phần này kiểm tra cách vector search đóng vai trò truy xuất dữ liệu liên quan để làm giàu ngữ cảnh cho LLM.
Trọng tâm không nằm ở bản thân model, mà nằm ở pipeline kết nối: Dữ liệu được bóc tách thế nào, chuyển thành vector ra sao, và làm thế nào để đồng bộ bộ nhớ ngắn hạn/dài hạn cho các AI Agents. Xu hướng các câu hỏi RAG đang tăng rất nhanh trong kho đề thi của Oracle.
5. Yếu Tố Bị Đánh Giá Thấp Nhất: Hands-on Labs
Phần lab thực hành trong learning path của Oracle University không phải là phần đọc thêm cho vui, mà là phần cốt lõi giúp bạn sống sót qua phòng thi. Thông qua việc trực tiếp tương tác với môi trường Cloud, bạn sẽ thấy rõ:
- Cú pháp thực tế khi tạo bảng có chứa trường dữ liệu VECTOR.
- Cách hệ thống xây dựng index chạy ngầm phía sau và sự thay đổi về mặt thời gian phản hồi trước và sau khi có index.
- Cách nhúng các hàm gọi API của các mô hình ngôn ngữ lớn (Cohere, Llama) trực tiếp trong câu lệnh SQL.
Nếu bạn bỏ qua phần này, bạn có thể vẫn nhớ khái niệm trên lý thuyết, nhưng sẽ gặp khó khăn rất lớn khi đề thi đưa ra một đoạn code SQL bị khuyết và yêu cầu điền từ khóa đúng để hoàn thiện luồng cấu hình.
6. Chiến Lược Phòng Thi (Exam Mindset): Đọc Vị Câu Hỏi Bối Cảnh
Khi đối mặt với đề thi 1Z0-184-25, bạn cần trang bị một tâm thế làm bài bài bản để tránh bị rối trước các câu hỏi tình huống dài:
- Xác định từ khóa ưu tiên tối cao: Mỗi câu hỏi bối cảnh luôn chứa một “từ khóa neo”. Hãy tìm xem đề bài đang ưu tiên Tốc độ, Độ chính xác, hay Chi phí hạ tầng. Đáp án đúng luôn bám sát vào mục tiêu ưu tiên này.
- Loại trừ các phương án phi thực tế: Có những đáp án đưa ra cú pháp SQL hoàn toàn sai hoặc cấu hình các tham số index vượt quá giới hạn logic của hệ thống. Việc nắm chắc kiến thức nền và cú pháp qua các bài Lab sẽ giúp bạn loại bỏ ngay 2 đáp án nhiễu đầu tiên trong vòng 5 giây.
- Không chọn theo cảm tính lý thuyết thuần túy: Hãy luôn đối chiếu giải pháp với bối cảnh dữ liệu mà đề bài cung cấp. Một giải pháp được coi là “hoàn hảo trên giấy” vẫn có thể là đáp án sai nếu nó vi phạm vào các ràng buộc tài nguyên của doanh nghiệp được mô tả trong câu hỏi.
Lời Kết
Chinh phục chứng chỉ Oracle AI Vector Search Professional 1Z0-184-25 không phải là một nhiệm vụ bất khả thi nếu bạn có một chiến lược ôn tập đúng đansa. Hãy chuyển dịch tư duy từ việc học thuộc lòng sang tư duy thấu hiểu kiến trúc hệ thống và những sự đánh đổi trong thế giới thực. Đó là con đường ngắn nhất để bạn không chỉ pass kỳ thi một cách thuyết phục mà còn thực sự làm chủ công nghệ để ứng dụng vào các dự án Enterprise thế hệ mới.
Góc Hỏi – Đáp Nhanh (FAQ dành cho Học viên chuẩn bị thi)
1. Tôi nên phân bổ thời gian ôn thi như thế nào nếu chỉ có khoảng 4 tuần chuẩn bị?
Trả lời: Lộ trình lý tưởng cho 4 tuần là: Tuần 1 tập trung nắm vững khái niệm Vector và các hàm tính khoảng cách (Distance Metrics). Tuần 2 dành toàn bộ thời gian cho Vector Indexing (HNSW, IVF) và làm sạch cú pháp DDL.
Tuần 3 tập trung vào pipeline RAG và thực hành 100% các bài Hands-on Labs. Tuần 4 dành để luyện các đề thi thử (Practice Exams) để rèn luyện tư duy đọc đề bối cảnh và quản lý thời gian làm bài trong phòng thi.
2. Đề thi có hỏi sâu về phần lập trình Python khi tích hợp RAG không?
Trả lời: Vì đây là chứng chỉ Professional thiên về hệ thống dữ liệu của Oracle, các câu hỏi sẽ tập trung nhiều hơn vào cú pháp SQL mở rộng và các gói thủ tục PL/SQL tích hợp sẵn trong database.
Đối với Python, đề thi có thể kiểm tra ở mức độ hiểu cách sử dụng driver kết nối chính thức (python-oracledb) để truyền các câu lệnh truy vấn vector từ ứng dụng bên ngoài vào database, chứ không bắt bạn phải viết các thuật toán xử lý dữ liệu phức tạp bằng Python.
3. Tôi có thể tìm các câu hỏi mẫu (Sample Questions) chuẩn ở đâu?
Trả lời: Nguồn câu hỏi mẫu uy tín và sát với đề thi thật nhất chính là bài thi thử có sẵn ở cuối Learning Path trên hệ thống Oracle MyLearn. Sau khi hoàn thành toàn bộ khóa học, Oracle sẽ mở khóa kho câu hỏi ôn tập này cho bạn. Hãy làm đi làm lại bộ câu hỏi này, đọc kỹ phần giải thích (Explanation) cho cả các đáp án sai để hiểu sâu sắc logic chấm điểm của giám khảo Oracle.
INDA Academy tự hào là đơn vị tiên phong trong việc đào tạo phân tích dữ liệu và AI chuyên sâu, đặc biệt cho khối ngành Ngân hàng – Tài chính – Bảo hiểm tại Việt Nam. Sau hơn 12 năm “thực chiến” cùng những dòng chảy dữ liệu khổng lồ, chúng tôi đã xây dựng nên một hệ sinh thái đào tạo toàn diện, giúp hàng nghìn học viên chuyển mình từ người mới bắt đầu trở thành những chuyên gia lành nghề, sẵn sàng đáp ứng tiêu chuẩn khắt khe của các doanh nghiệp lớn.
Điểm khác biệt lớn nhất tại INDA chính là triết lý đào tạo dựa trên các dự án thực tế (Project-based) và lộ trình cá nhân hóa nhờ ứng dụng AI. Chúng tôi không chỉ dạy bạn cách sử dụng công cụ, mà còn truyền tải tư duy khai phá giá trị từ dữ liệu để đưa ra quyết định kinh doanh chính xác.
Tìm hiểu thêm về các khóa học TẠI ĐÂY:
Lộ trình đào tạo Data Engineer
Lộ trình đào tạo Data Analyst
Lộ trình đào tạo Tester
Khóa học Data Engineer nâng cao – Thực chiến 5 dự án doanh nghiệp
Khóa học Data Analyst nâng cao – Thực chiến 5 dự án doanh nghiệp
Bài viết liên quan:
 Cẩm Nang Oracle Multicloud: Giải Mã Kiến Trúc Tích Hợp Sâu Và Tư Duy Thiết Kế Hạ Tầng Đa Đám Mây Thế Hệ Mới
In-Database Machine Learning Là Gì? Phân Tích Kiến Trúc Kỹ Thuật Và Cách Oracle Tái Định Nghĩa Quy Trình Triển Khai ML
Cẩm Nang Tích Hợp Oracle AI Services: Kiến Trúc Ứng Dụng Và Lộ Trình Triển Khai Cho Kỹ Sư Hệ Thống
Kiến Trúc AI Agents Trong Doanh Nghiệp: Hướng Dẫn Toàn Tập Triển Khai Vào Môi Trường Production Với OCI Enterprise AI 2026
Cẩm Nang Oracle Multicloud: Giải Mã Kiến Trúc Tích Hợp Sâu Và Tư Duy Thiết Kế Hạ Tầng Đa Đám Mây Thế Hệ Mới
In-Database Machine Learning Là Gì? Phân Tích Kiến Trúc Kỹ Thuật Và Cách Oracle Tái Định Nghĩa Quy Trình Triển Khai ML
Cẩm Nang Tích Hợp Oracle AI Services: Kiến Trúc Ứng Dụng Và Lộ Trình Triển Khai Cho Kỹ Sư Hệ Thống
Kiến Trúc AI Agents Trong Doanh Nghiệp: Hướng Dẫn Toàn Tập Triển Khai Vào Môi Trường Production Với OCI Enterprise AI 2026
 AI thất bại trong doanh nghiệp vì không có người sở hữu bài toán?
Lộ trình ứng dụng AI cho doanh nghiệp SME từ con số 0
AI thất bại trong doanh nghiệp vì không có người sở hữu bài toán?
Lộ trình ứng dụng AI cho doanh nghiệp SME từ con số 0