
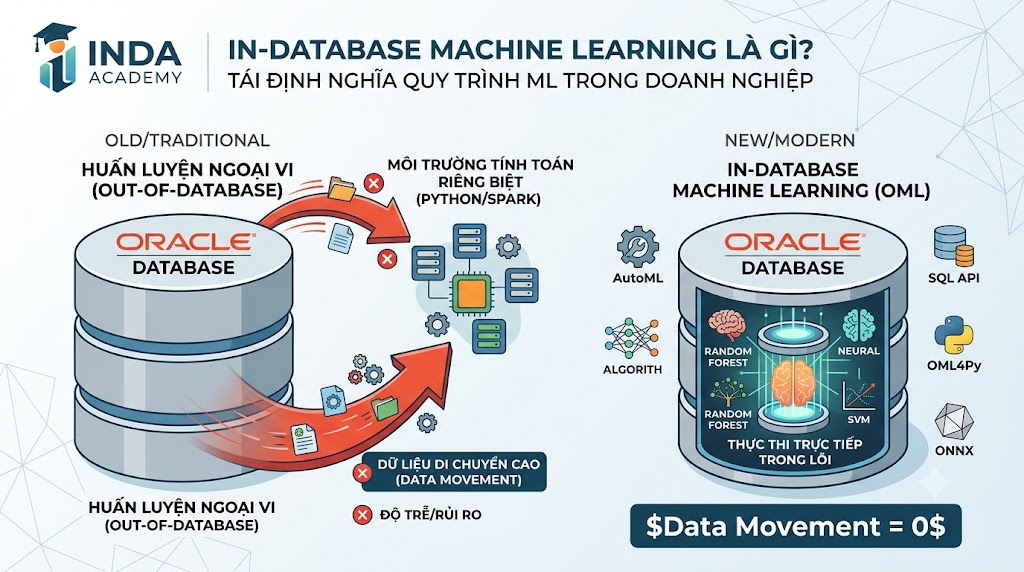
Trong nhiều năm qua, quy trình triển khai Machine Learning (ML Pipeline) trong doanh nghiệp hầu như đều tuân theo một kịch bản kinh điển: Dữ liệu được lưu trữ tập trung trong các cơ sở dữ liệu (Database), sau đó được trích xuất (Extract) và vận chuyển sang các môi trường tính toán riêng biệt như Python, Apache Spark, hoặc các nền tảng ML chuyên dụng để huấn luyện mô hình.
Mô hình kiến trúc “Out-of-Database” này mang lại sự linh hoạt ban đầu cho các Data Scientist, nhưng khi quy mô dữ liệu tiến đến cấp độ Terabyte hoặc Petabyte, nó lập tức bộc lộ những lỗ hổng chí mạng: độ trễ hệ thống (Latency) tăng vọt, chi phí hạ tầng nhân đôi, và đặc biệt là rủi ro rò rỉ bảo mật khi dữ liệu phải liên tục di chuyển qua lại giữa các phân vùng mạng.
Để giải quyết triệt để nghịch lý này, Oracle Machine Learning (OML) đã xuất hiện và đại diện cho một triết lý thiết kế hoàn toàn trái ngược: Thay vì dịch chuyển dữ liệu đến nơi huấn luyện mô hình, hãy đưa toàn bộ năng lực Machine Learning trực tiếp vào lõi Database. Bài viết chuyên sâu này của Học viện sẽ cùng bạn bóc tách kiến trúc In-Database Machine Learning và cách Oracle đang tái định nghĩa lại vòng đời vận hành ML trong doanh nghiệp.
Mục lục
1. Bản Chất Của Oracle Machine Learning: Loại Bỏ “Cơn Ác Mộng” Data Movement
Để hiểu tại sao Oracle Machine Learning (OML) trở thành một kỹ năng quan trọng đối với các kỹ sư dữ liệu hiện đại, chúng ta cần nhìn thẳng vào “nỗi đau” lớn nhất của các kiến trúc cũ: Data Movement (Sự dịch chuyển dữ liệu).
Trong các hệ thống truyền thống, để huấn luyện một mô hình dự báo hành vi khách hàng, quy trình thường diễn ra như sau:
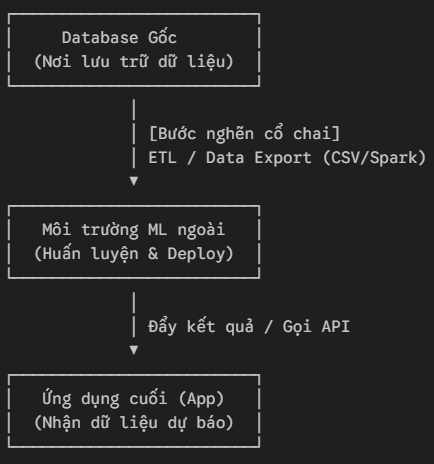
Chính mũi tên dịch chuyển dữ liệu (ETL/Export) kia là nơi phát sinh mọi rắc rối. Quy mô dữ liệu càng lớn, thời gian trích xuất càng lâu, gây nghẽn băng thông mạng nội bộ. Chưa kể, khi dữ liệu rời khỏi lớp bảo mật nghiêm ngặt của Database để nằm dưới dạng các tệp tin CSV hoặc DataFrame trên các cụm tính toán rời rạc, các chính sách quản trị dữ liệu (Data Governance) gần như bị vô hiệu hóa.
Oracle Machine Learning (OML) giải quyết tận gốc bài toán này bằng cách biến chính Oracle Autonomous Database hoặc Oracle AI Database thành môi trường thực thi ML. Toàn bộ vòng đời của mô hình – từ tiền xử lý dữ liệu, trích xuất đặc trưng (Feature Engineering), huấn luyện mô hình (Model Training) cho đến triển khai (Deployment) và chấm điểm thời gian thực (Real-time Scoring) – đều diễn ra ngay tại nơi dữ liệu sinh ra và lưu trữ. Dữ liệu di chuyển bằng 0 ($Data Movement = 0$).
2. Bóc Tách Kiến Trúc In-Database Machine Learning: Sự Khác Biệt Mang Tính Nền Tảng
Kiến trúc In-Database ML của Oracle không thuần túy là việc cài đặt thêm các thư viện Python vào máy chủ cơ sở dữ liệu. Đây là một sự cải tiến sâu sắc từ bên trong lõi của Database Kernel engine.
Sơ đồ kiến trúc tối ưu: Hệ thống In-Database ML
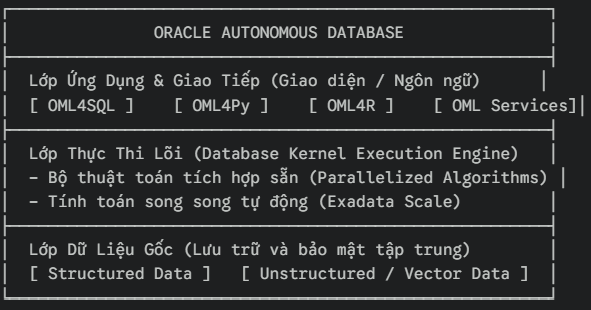
Nhìn vào sơ đồ kiến trúc trên, chúng ta có thể thấy hệ thống được tổ chức thành các tầng tích hợp chặt chẽ:
- Tầng dữ liệu gốc (Data Layer): Nơi lưu trữ toàn bộ dữ liệu doanh nghiệp một cách an toàn. Các thuật toán ML có thể truy cập trực tiếp vào các bảng dữ liệu mà không cần thông qua bất kỳ giao thức mạng ngoại vi nào.
- Tầng thực thi lõi (Execution Engine): Các thuật toán Machine Learning (như Random Forest, Support Vector Machines, K-Means…) được lập trình bằng ngôn ngữ C/C++ và tích hợp thẳng vào mã nguồn của Database Engine. Nhờ đó, chúng tận dụng được toàn bộ sức mạnh phần cứng cao cấp như khả năng xử lý song song (Parallel Execution) của Exadata, tối ưu hóa bộ nhớ RAM và kiến trúc lưu trữ dạng cột (In-Memory Columnar).
- Tầng giao tiếp đa ngôn ngữ (Interface Layer): Oracle cung cấp các “vỏ bọc” đa dạng để phù hợp với mọi vai trò trong doanh nghiệp. Bạn là Data Analyst thành thạo SQL? Bạn có thể dùng OML4SQL. Bạn là Data Scientist đam mê Code? Bạn có thể sử dụng OML4Py (Python) hoặc OML4R (ngôn ngữ R) để gọi các thuật toán In-Database với cú pháp quen thuộc.
3. Quy Trình Vận Hành Thực Tế: ML Hòa Vào Dòng Chảy Của SQL
Một trong những điểm đột phá lớn nhất của OML là biến các thao tác Machine Learning trở nên tự nhiên như việc viết một câu lệnh truy vấn dữ liệu hằng ngày. Quy trình xây dựng và sử dụng mô hình trong OML vận hành thông qua các bước:
- Chuẩn bị dữ liệu (Data Preparation): Thay vì viết code Python để xử lý các giá trị khuyết thiếu (Missing values) hoặc chuẩn hóa dữ liệu trên RAM máy tính, bạn sử dụng sức mạnh xử lý của SQL để xử lý trực tiếp trên đĩa cứng của Database ở quy mô lớn.
- Huấn luyện mô hình (Model Training): Kỹ sư gọi các hàm thủ tục (Stored Procedures) có sẵn để huấn luyện. Ví dụ, để chạy một thuật toán phân loại khách hàng, hệ thống sẽ thực thi một câu lệnh PL/SQL hoặc một đoạn mã Python kết nối trực tiếp vào bộ core thuật toán trong database. Mô hình sau khi train xong sẽ được lưu trữ dưới dạng một Database Object (được quản lý giống như một bảng hoặc một View).
- Triển khai và Chấm điểm thời gian thực (Real-time Scoring): Đây là nơi OML tỏa sáng. Việc dự báo (Inference) không cần phải thông qua một web service hay API trung gian phức tạp nào khác. Bạn có thể nhúng trực tiếp mô hình vào câu lệnh SQL SELECT.
Ví dụ thực tế: Để dự báo khả năng một khách hàng rời bỏ dịch vụ (Prediction) ngay khi đang truy vấn danh sách, câu lệnh SQL sẽ có dạng cực kỳ tối giản:
SELECT customer_id, PREDICTION(churn_model USING *) AS will_churn FROM customers;
Kết quả dự báo được trả về ngay lập tức trong luồng dữ liệu của truy vấn. Điều này cho phép các ứng dụng báo cáo, dashboard (như Oracle Analytics Cloud hoặc PowerBI) lấy kết quả dự báo thời gian thực mà không cần thêm bất kỳ tầng tích hợp nào.
4. Các Tính Năng Cốt Lõi Tái Định Nghĩa Khái Niệm Machine Learning
Để đáp ứng nhu cầu của các dự án Enterprise lớn, Oracle Machine Learning trang bị một bộ công cụ toàn diện, phá vỡ khoảng cách giữa Analytics truyền thống và Data Science hiện đại:
- Bộ thuật toán In-Database tối ưu hóa cao: Tích hợp sẵn hơn 30 thuật toán thương mại hàng đầu bao gồm Phân loại (Classification), Hồi quy (Regression), Phân cụm (Clustering), Phát hiện bất thường (Anomaly Detection), và Phân tích liên kết (Association Rules). Tất cả đều được cấu hình để tự động chạy song song ở quy mô lớn.
- AutoML (Machine Learning Tự Động): Tính năng cứu cánh cho các tổ chức thiếu hụt chuyên gia ML cấp cao. AutoML của Oracle tự động thực hiện các bước: Lựa chọn thuật toán tối ưu nhất cho tập dữ liệu, tự động chọn lọc các đặc trưng quan trọng (Feature Selection), và tự động dò tìm siêu tham số (Hyperparameter Tuning) để cho ra mô hình có độ chính xác cao nhất với thời gian ngắn nhất.
- Bring Your Own Model (BYOM): Oracle hiểu rằng hệ sinh thái open-source vô cùng phong phú. Vì vậy, OML cho phép các Data Scientist huấn luyện các mô hình Deep Learning phức tạp bên ngoài (bằng PyTorch, TensorFlow…) rồi xuất ra định dạng chuẩn ONNX. Sau đó, bạn có thể nhập khẩu (Import) mô hình ONNX này trực tiếp vào Oracle Database để thực hiện chấm điểm (Scoring) với hiệu năng In-Database cực cao.
5. MLOps Trong Oracle: Tính Hợp Nhất Triệt Tiêu Sự Phân Mảnh
Trong các hệ sinh thái ML mã nguồn mở, việc xây dựng quy trình MLOps (Quản lý vòng đời mô hình từ thiết kế đến vận hành) là một bài toán đau đầu. Doanh nghiệp phải kết nối hàng loạt công cụ như Git để quản lý mã nguồn, MLflow để quản lý phiên bản model, Docker/Kubernetes để đóng gói deploy, và Prometheus để giám sát hệ thống.
Oracle Machine Learning định nghĩa lại MLOps bằng một từ duy nhất: Hợp nhất (Integration). Vì dữ liệu và mô hình nằm chung một nhà (Database), doanh nghiệp nghiễm nhiên thừa hưởng các cơ chế quản trị cao cấp có sẵn của Oracle:
- Bảo mật và Quyền truy cập: Việc ai được phép chạy model, ai được xem kết quả dự báo được quản lý đồng nhất bằng cơ chế phân quyền User/Role của Database.
- Sao lưu và Phục hồi (Backup & Recovery): Khi Database được backup, toàn bộ các mô hình ML bên trong cũng được bảo vệ tương tự. Tránh rủi ro mất mát mô hình khi máy chủ ML bên ngoài gặp sự cố.
- Giám sát độ lệch dữ liệu (Data & Model Drift): OML cung cấp các công cụ tích hợp giúp tự động theo dõi xem phân phối dữ liệu thực tế đầu vào có bị thay đổi so với thời điểm train mô hình hay không, từ đó kích hoạt luồng tự động huấn luyện lại (Retrain) mô hình ngay tại chỗ.
6. Đặt Lên Bàn Cân: So Sánh OML Với Các Nền Tảng ML Hiện Đại
Để giúp các Solution Architect có cái nhìn khách quan trước khi đưa ra quyết định lựa chọn kiến trúc, hãy cùng phân tích bảng so sánh ưu – nhược điểm dưới đây giữa Oracle Machine Learning và các nền tảng phổ biến như Databricks (Lakehouse thuần túy) hay các công cụ In-Data Warehouse khác (Snowflake/BigQuery ML):
Bảng so sánh đặc tính kiến trúc các nền tảng ML
| Tiêu chí | Oracle Machine Learning (OML) | Databricks (Lakehouse) | Snowflake / BigQuery ML |
| Vị trí xử lý | Tuyệt đối In-Database (Trong lõi Engine). | Ngoài nguồn dữ liệu (Đọc dữ liệu từ Data Lake). | Cận dữ liệu (Gần dữ liệu, vẫn cần một lớp ảo hóa tính toán). |
| Data Movement | Bằng 0 (Data Movement = 0). | Khá cao (Phụ thuộc vào tốc độ kéo dữ liệu từ Object Storage). | Thấp đến Trung bình tùy cấu hình kết nối ứng dụng. |
| Thế mạnh lõi | Xử lý dữ liệu doanh nghiệp lớn, Real-time Scoring độ trễ cực thấp. | Xử lý Deep Learning, Unstructured Data (Audio/Video) quy mô lớn. | Phân tích dữ liệu kinh doanh, ML cơ bản bằng lệnh SQL mở rộng. |
| Độ linh hoạt hệ sinh thái | Giới hạn trong môi trường Oracle và chuẩn ONNX. | Rất cao (Hỗ trợ toàn bộ thư viện Open-source Python/Scala). | Trung bình (Phụ thuộc vào các hàm UDF mở rộng). |
7. Khi Nào Nên Và Không Nên Sử Dụng Oracle Machine Learning?
Mặc dù sở hữu những thông số kỹ thuật ấn tượng, OML không phải là một “viên đạn bạc” giải quyết được mọi bài toán công nghệ. Học viện đưa ra khuyến nghị thực tế cho doanh nghiệp dựa trên các kịch bản cụ thể sau:
Doanh nghiệp NÊN lựa chọn Oracle Machine Learning khi:
- Hệ thống dữ liệu kinh doanh cốt lõi (ERP, CRM, Giao dịch ngân hàng) đã và đang vận hành ổn định trên nền tảng Oracle Database.
- Bài toán yêu cầu tính toán kết quả dự báo theo thời gian thực với độ trễ cực thấp (Sub-millisecond), ví dụ như hệ thống Chấm điểm tín dụng khi khách hàng quẹt thẻ, hoặc Phát hiện gian lận giao dịch tài chính (Fraud Detection).
- Doanh nghiệp thuộc các ngành có tiêu chuẩn bảo mật dữ liệu khắt khe (Ngân hàng, Bảo hiểm, Y tế, Chính phủ) – nơi việc chuyển dữ liệu ra khỏi database là một điều cấm kỵ về mặt pháp lý.
Doanh nghiệp KHÔNG NÊN sử dụng OML mà nên chọn nền tảng khác khi:
- Bài toán nghiên cứu thuần túy về Deep Learning nâng cao, cần huấn luyện các mô hình thị giác máy tính hoặc xử lý ngôn ngữ tự nhiên (NLP) khổng lồ dựa trên hàng trăm cụm GPU chuyên dụng độc lập.
- Nguồn dữ liệu đầu vào của doanh nghiệp hoàn toàn là dữ liệu thô dạng phi cấu trúc nằm phân tán trên các hệ thống Cloud Storage khác nhau và không có ý định đưa vào quản lý trong Database.
Lời Kết
Oracle Machine Learning phản ánh một xu thế tất yếu của kiến trúc dữ liệu hiện đại: Sự hội tụ giữa Data Platform (Nền tảng dữ liệu) và AI Platform (Nền tảng Trí tuệ nhân tạo). Bằng cách triệt tiêu hoàn toàn bước dịch chuyển dữ liệu và đưa các thuật toán ML vào hoạt động như các thành phần bản địa của cơ sở dữ liệu, Oracle đã mở ra một con đường ngắn nhất, an toàn nhất để doanh nghiệp giải phóng giá trị ẩn giấu trong khối dữ liệu khổng lồ của mình. Đó không chỉ là câu chuyện về công nghệ, đó là tư duy tối ưu hóa vận hành trong kỷ nguyên số.
Góc Hỏi – Đáp Nhanh
1. Tôi là một Data Scientist quen viết code Python, tôi có bị gò bó khi chuyển sang dùng OML không?
Trả lời: Hoàn toàn không. Với công cụ OML4Py, bạn vẫn viết code Python bằng các thư viện quen thuộc (như Pandas, Scikit-Learn) thông qua giao diện OML Notebooks. Điểm khác biệt là phía dưới hạ tầng, OML sẽ tự động chuyển đổi các thao tác của bạn thành các câu lệnh thực thi trực tiếp trong Database, giúp bạn xử lý các tập dữ liệu lớn vượt quá dung lượng RAM của máy tính cá nhân một cách dễ dàng.
2. Hiệu năng của việc chạy thuật toán ML ngay trong Database có làm ảnh hưởng đến các tác vụ truy xuất dữ liệu thông thường (OLTP) của doanh nghiệp không?
Trả lời: Đây là một lo ngại hoàn toàn chính đáng. Tuy nhiên, trên các môi trường hiện đại như Oracle Autonomous Database, hệ thống sử dụng cơ chế quản lý tài nguyên thông minh (Resource Manager). Bạn có thể cấu hình phân bổ tài nguyên CPU/RAM riêng biệt cho các tác vụ Huấn luyện ML (thường chạy vào giờ thấp điểm) và ưu tiên tài nguyên cho các giao dịch trực tuyến hằng ngày, đảm bảo hệ thống luôn vận hành ổn định.
3. Làm thế nào để tôi bắt đầu học và thực hành Oracle Machine Learning?
Trả lời: Con đường ngắn nhất là bạn đăng ký một tài khoản Oracle Cloud Free Tier. Oracle cung cấp dịch vụ Always Free cho Autonomous Database, bên trong đã tích hợp sẵn môi trường OML Notebooks đi kèm các tập dữ liệu mẫu và tài liệu hướng dẫn chi tiết từ cơ bản đến nâng cao để bạn có thể bắt đầu thực hành ngay lập tức.
INDA Academy tự hào là đơn vị tiên phong trong việc đào tạo phân tích dữ liệu và AI chuyên sâu, đặc biệt cho khối ngành Ngân hàng – Tài chính – Bảo hiểm tại Việt Nam. Sau hơn 12 năm “thực chiến” cùng những dòng chảy dữ liệu khổng lồ, chúng tôi đã xây dựng nên một hệ sinh thái đào tạo toàn diện, giúp hàng nghìn học viên chuyển mình từ người mới bắt đầu trở thành những chuyên gia lành nghề, sẵn sàng đáp ứng tiêu chuẩn khắt khe của các doanh nghiệp lớn.
Điểm khác biệt lớn nhất tại INDA chính là triết lý đào tạo dựa trên các dự án thực tế (Project-based) và lộ trình cá nhân hóa nhờ ứng dụng AI. Chúng tôi không chỉ dạy bạn cách sử dụng công cụ, mà còn truyền tải tư duy khai phá giá trị từ dữ liệu để đưa ra quyết định kinh doanh chính xác.
Tìm hiểu thêm về các khóa học TẠI ĐÂY:
Lộ trình đào tạo Data Engineer
Lộ trình đào tạo Data Analyst
Lộ trình đào tạo Tester
Khóa học Data Engineer nâng cao – Thực chiến 5 dự án doanh nghiệp
Khóa học Data Analyst nâng cao – Thực chiến 5 dự án doanh nghiệp
Bài viết liên quan:
 Cẩm Nang Tích Hợp Oracle AI Services: Kiến Trúc Ứng Dụng Và Lộ Trình Triển Khai Cho Kỹ Sư Hệ Thống
Kiến Trúc AI Agents Trong Doanh Nghiệp: Hướng Dẫn Toàn Tập Triển Khai Vào Môi Trường Production Với OCI Enterprise AI 2026
Cẩm Nang Tích Hợp Oracle AI Services: Kiến Trúc Ứng Dụng Và Lộ Trình Triển Khai Cho Kỹ Sư Hệ Thống
Kiến Trúc AI Agents Trong Doanh Nghiệp: Hướng Dẫn Toàn Tập Triển Khai Vào Môi Trường Production Với OCI Enterprise AI 2026
 Học Machine Learning cơ bản miễn phí như thế nào? Lộ trình cho người mới (2026)
Xây dựng năng lực AI nội bộ cho doanh nghiệp: SkillAI tiếp cận bài toán “không phụ thuộc chuyên gia” như thế nào?
Đào tạo AI in-house cho doanh nghiệp: Khi nào nên triển khai?
Học Machine Learning cơ bản miễn phí như thế nào? Lộ trình cho người mới (2026)
Xây dựng năng lực AI nội bộ cho doanh nghiệp: SkillAI tiếp cận bài toán “không phụ thuộc chuyên gia” như thế nào?
Đào tạo AI in-house cho doanh nghiệp: Khi nào nên triển khai?
 Lợi ích của AI: Khám phá ưu điểm và giá trị mà trí tuệ nhân tạo mang lại
Lợi ích của AI: Khám phá ưu điểm và giá trị mà trí tuệ nhân tạo mang lại