
Last updated on January 16th, 2026 at 01:46 pm
Ngày nay có rất nhiều hệ thống đang sử dụng Hadoop để phân tích và xử lý dữ liệu lớn. Ưu điểm lớn nhất của Hadoop là được dựa trên một mô hình lập trình song song với xử lý dữ liệu lớn là MapReduce, mô hình này cho phép khả năng tính toán có thể mở rộng, linh hoạt, khả năng chịu lỗi, chi phí rẻ. Điều này cho phép tăng tốc thời gian xử lý các dữ liệu lớn nhằm duy trì tốc độ, giảm thời gian chờ đợi khi dữ liệu ngày càng lớn.
Dù có rất nhiều điểm mạnh về khả năng tính toán song song và khả năng chịu lỗi cao nhưng Apache Haddop có một nhược điểm là tất cả các thao tác đều phải thực hiện trên ổ đĩa cứng điều này đã làm giảm tốc độ tính toán đi gấp nhiều lần.
Để khắc phục được nhược điểm này thì Apache Spark được ra đời. Apache Spark có thể chạy nhanh hơn 10 lần so với Haddop ở trên đĩa cứng và 100 lần khi chạy trên bộ nhớ RAM.
Mục lục
Giới thiệu về Apache Spark
Apache Spark là một framework mã nguồn mở tính toán cụm, được phát triển sơ khởi vào năm 2009 bởi AMPLab. Sau này, Spark đã được trao cho Apache Software Foundation vào năm 2013 và được phát triển cho đến nay.
Tốc độ xử lý của Spark có được do việc tính toán được thực hiện cùng lúc trên nhiều máy khác nhau. Đồng thời việc tính toán được thực hiện ở bộ nhớ trong (in-memories) hay thực hiện hoàn toàn trên RAM.
Spark cho phép xử lý dữ liệu theo thời gian thực, vừa nhận dữ liệu từ các nguồn khác nhau đồng thời thực hiện ngay việc xử lý trên dữ liệu vừa nhận được ( Spark Streaming).
Spark không có hệ thống file của riêng mình, nó sử dụng hệ thống file khác như: HDFS, Cassandra, S3,…. Spark hỗ trợ nhiều kiểu định dạng file khác nhau (text, csv, json…) đồng thời nó hoàn toàn không phụ thuộc vào bất cứ một hệ thống file nào.
Thành phần của Spark
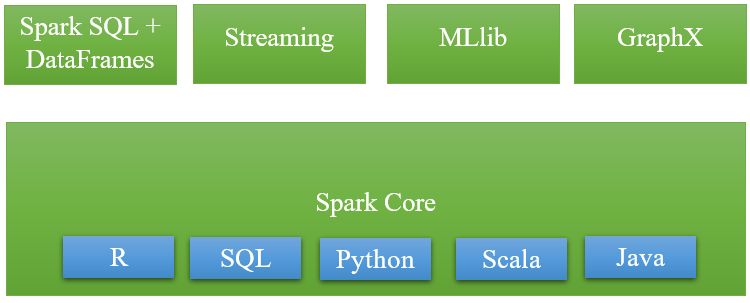
Apache Spark gồm có 5 thành phần chính : Spark Core, Spark Streaming, Spark SQL, MLlib và GraphX, trong đó:
- Spark Core là nền tảng cho các thành phần còn lại và các thành phần này muốn khởi chạy được thì đều phải thông qua Spark Core do Spark Core đảm nhận vai trò thực hiện công việc tính toán và xử lý trong bộ nhớ (In-memory computing) đồng thời nó cũng tham chiếu các dữ liệu được lưu trữ tại các hệ thống lưu trữ bên ngoài.
- Spark SQL cung cấp một kiểu data abstraction mới (SchemaRDD) nhằm hỗ trợ cho cả kiểu dữ liệu có cấu trúc (structured data) và dữ liệu nửa cấu trúc (semi-structured data – thường là dữ liệu dữ liệu có cấu trúc nhưng không đồng nhất và cấu trúc của dữ liệu phụ thuộc vào chính nội dung của dữ liệu ấy). Spark SQL hỗ trợ DSL (Domain-specific language) để thực hiện các thao tác trên DataFrames bằng ngôn ngữ Scala, Java hoặc Python và nó cũng hỗ trợ cả ngôn ngữ SQL với giao diện command-line và ODBC/JDBC server.
- Spark Streaming được sử dụng để thực hiện việc phân tích stream bằng việc coi stream là các mini-batches và thực hiệc kỹ thuật RDD transformation đối với các dữ liệu mini-batches này. Qua đó cho phép các đoạn code được viết cho xử lý batch có thể được tận dụng lại vào trong việc xử lý stream, làm cho việc phát triển lambda architecture được dễ dàng hơn. Tuy nhiên điều này lại tạo ra độ trễ trong xử lý dữ liệu (độ trễ chính bằng mini-batch duration) và do đó nhiều chuyên gia cho rằng Spark Streaming không thực sự là công cụ xử lý streaming giống như Storm hoặc Flink.
- MLlib (Machine Learning Library): MLlib là một nền tảng học máy phân tán bên trên Spark do kiến trúc phân tán dựa trên bộ nhớ. Theo các so sánh benchmark Spark MLlib nhanh hơn 9 lần so với phiên bản chạy trên Hadoop (Apache Mahout).
- GrapX: Grapx là nền tảng xử lý đồ thị dựa trên Spark. Nó cung cấp các Api để diễn tảcác tính toán trong đồ thị bằng cách sử dụng Pregel Api.
Những điểm nổi bật của Spark
- Xử lý dữ liệu: Spark xử lý dữ liệu theo lô và thời gian thực
- Tính tương thích: Có thể tích hợp với tất cả các nguồn dữ liệu và định dạng tệp được hỗ trợ bởi cụm Hadoop.
- Hỗ trợ ngôn ngữ: hỗ trợ Java, Scala, Python và R.
- Phân tích thời gian thực:
- Apache Spark có thể xử lý dữ liệu thời gian thực tức là dữ liệu đến từ các luồng sự kiện thời gian thực với tốc độ hàng triệu sự kiện mỗi giây. Ví dụ: Data Twitter chẳng hạn hoặc luợt chia sẻ, đăng bài trên Facebook. Sức mạnh Spark là khả năng xử lý luồng trực tiếp hiệu quả.
- Apache Spark có thể được sử dụng để xử lý phát hiện gian lận trong khi thực hiện các giao dịch ngân hàng. Đó là bởi vì, tất cả các khoản thanh toán trực tuyến được thực hiện trong thời gian thực và chúng ta cần ngừng giao dịch gian lận trong khi quá trình thanh toán đang diễn ra.
- Mục tiêu sử dụng:
- Xử lý dữ liệu nhanh và tương tác
- Xử lý đồ thị
- Công việc lặp đi lặp lại
- Xử lý thời gian thực
- joining Dataset
- Machine Learning
- Apache Spark là Framework thực thi dữ liệu dựa trên Hadoop HDFS. Apache Spark không thay thế cho Hadoop nhưng nó là một framework ứng dụng. Apache Spark tuy ra đời sau nhưng được nhiều người biết đến hơn Apache Hadoop vì khả năng xử lý hàng loạt và thời gian thực.
Những doanh nghiệp sử dụng Apache Spark
Hiện nay, có rất nhiều hãng lớn đã dùng Spark cho các sản phẩm của mình như Yahoo, ebay, IBM, Cisco…

Cập nhật xu hướng mới về Apache Spark (2025–2026)
1. Phiên bản Apache Spark 3.5.x là bản nâng cấp quan trọng
Apache Spark 3.5.0 và các bản 3.5.x liên tiếp (bao gồm 3.5.5) là những phát hành đáng chú ý trong dòng 3.x, với hơn 1.300 issue được xử lý và nhiều cải tiến về hiệu năng, API và khả năng tương thích cho workloads lớn.
Các điểm nổi bật trong dòng 3.5 bao gồm:
- Spark Connect mở rộng hỗ trợ client Scala, Go và cải thiện tương thích với Structured Streaming.
- Tăng cường Spark SQL, với nhiều hàm SQL mới, cú pháp SQL nâng cao (IDENTIFIER clause, named parameters).
- Hỗ trợ HyperLogLog approximate aggregations, hữu ích cho analytics quy mô lớn.
Phiên bản này tiếp tục củng cố Spark như một nền tảng thống nhất cho ETL, SQL, streaming và analytics.
2. Các cải tiến PySpark giúp phát triển nhanh hơn
Spark 3.5 giới thiệu nhiều tính năng mới quan trọng cho PySpark:
- Arrow-Optimized Python UDFs giúp tăng tốc các UDF bằng cách sử dụng dữ liệu cột hiệu quả hơn, giảm overhead serialization giữa Python và JVM.
- Python User-Defined Table Functions (UDTFs) cho phép tạo các hàm trả về toàn bộ bảng, mở rộng khả năng xử lý phức tạp.
- API kiểm thử cải tiến và thông báo lỗi chi tiết hơn, giúp developers nhanh chóng chẩn lỗi trong workflow.
Những cải tiến này làm cho PySpark ngày càng gần gũi hơn với workflow phát triển Python hiện đại, đồng thời giảm bớt các giới hạn truyền thống của Python trong môi trường phân tán.
3. Structured Streaming & Watermark nâng cao
Structured Streaming tiếp tục được nâng cấp mạnh:
- dropDuplicatesWithinWatermark() giúp xử lý loại bỏ trùng lặp dựa trên watermark, dễ áp dụng cho các pipeline thời gian thực phức tạp.
- Quản lý trạng thái tốt hơn với RocksDB state store và checkpoint linh hoạt, giảm độ trễ xử lý toàn pipeline.
Những cải tiến này cho phép Spark xử lý streaming với độ chính xác và ổn định cao hơn ở quy mô lớn.
4. Hỗ trợ Spark trong các môi trường đám mây hiện đại
Các dịch vụ đám mây lớn đã tích hợp và nâng cấp Spark:
- AWS Glue 5.0 sử dụng Spark 3.5, mang đến UDF tối ưu Arrow và khả năng quản lý bộ nhớ tốt hơn trong streaming.
- Azure Synapse Runtime for Spark 3.5 đã có bản preview, tạo tiền đề cho khả năng chạy Spark trong môi trường lakehouse tích hợp.
- Amazon EMR phi máy chủ hiện hỗ trợ Spark 4.0.1 ở bản preview, mở rộng khả năng xử lý ANSI SQL, định dạng VARIANT và quản trị dữ liệu theo Iceberg.
Điều này phản ánh xu hướng: Spark không chỉ chạy trên cluster truyền thống mà còn là trụ cột xử lý dữ liệu trong kiến trúc cloud-native, serverless analytics và lakehouse.
5. Dòng Spark 4.0 tiếp tục tiến lên
Spark 4.0.x đã ra mắt vào giữa năm 2025 và đang được hỗ trợ trong nhiều dịch vụ provider. Bản 4.0.1 cho phép:
- Xử lý ANSI SQL tiêu chuẩn
- Hỗ trợ VARIANT và JSON/Giải pháp dữ liệu bán cấu trúc
- Tăng khả năng streaming, phù hợp với pipeline thời gian thực phức tạp hơn.
Dòng 4.x thể hiện tầm nhìn của Spark là trên cả một engine ETL dữ liệu lớn, hướng tới trở thành nền tảng xử lý dữ liệu thống nhất cho batch, streaming, SQL, và quy trình analytics phức tạp.
Tổng kết
Với sự phát triển mạnh mẽ trong vài năm trở lại đây của Apache Spark thì lập trình viên, các nhà khoa học máy tính có thêm công cụ hữu hiệu để phục vụ công việc của mình và người ta sẽ dần quên “Hadoop Stack” mà thay thế vào đó sẽ là “Big data Stack”, với nhiều sự lựa chọn hơn không chỉ là Hadoop.
INDA Academy tự hào là đơn vị tiên phong trong việc đào tạo phân tích dữ liệu và AI chuyên sâu, đặc biệt cho khối ngành Ngân hàng – Tài chính – Bảo hiểm tại Việt Nam. Sau hơn 12 năm “thực chiến” cùng những dòng chảy dữ liệu khổng lồ, chúng tôi đã xây dựng nên một hệ sinh thái đào tạo toàn diện, giúp hàng nghìn học viên chuyển mình từ người mới bắt đầu trở thành những chuyên gia lành nghề, sẵn sàng đáp ứng tiêu chuẩn khắt khe của các doanh nghiệp lớn.
Điểm khác biệt lớn nhất tại INDA chính là triết lý đào tạo dựa trên các dự án thực tế (Project-based) và lộ trình cá nhân hóa nhờ ứng dụng AI. Chúng tôi không chỉ dạy bạn cách sử dụng công cụ, mà còn truyền tải tư duy khai phá giá trị từ dữ liệu để đưa ra quyết định kinh doanh chính xác.
Tìm hiểu thêm về các khóa học TẠI ĐÂY:
Lộ trình đào tạo Data Engineer
Lộ trình đào tạo Data Analyst
Lộ trình đào tạo Tester
Khóa học Data Engineer nâng cao – Thực chiến 5 dự án doanh nghiệp
Khóa học Data Analyst nâng cao – Thực chiến 5 dự án doanh nghiệp
Nguồn: Internet
