Dữ liệu trong một kho lưu trữ hiện đại thường kể hai câu chuyện khác nhau. Câu chuyện thứ nhất là về thực tại – những gì đang diễn ra ngay lúc này. Câu chuyện thứ hai, khó nắm bắt hơn nhưng mang giá trị sống còn, là về việc mọi thứ đã từng như thế nào trong quá khứ.
Trong khi các bảng sự kiện (Fact Table) ghi lại dòng chảy không ngừng của các giao dịch, thì các bảng mô tả (Dimension Table) lại đại diện cho bối cảnh của những giao dịch đó. Tuy nhiên, bối cảnh không bao giờ đứng yên. Một khách hàng thay đổi địa chỉ, một sản phẩm được tái định vị phân khúc, hay một nhân viên chuyển sang chi nhánh mới… Nếu hệ thống dữ liệu chỉ cập nhật trạng thái mới nhất, chúng ta sẽ vô tình xóa sạch dấu vết của quá khứ, biến mọi báo cáo lịch sử trở thành những “con số giả” vì thiếu đi bối cảnh chính xác tại thời điểm chúng phát sinh.
Slowly Changing Dimension (SCD) chính là giải pháp cho bài toán này. Đây không chỉ là một kỹ thuật lưu trữ, mà là tư duy quản lý sự tiến hóa của dữ liệu, giúp Data Warehouse giữ được tính trung thực tuyệt đối trước dòng chảy của thời gian.
Mục lục
I. Bản chất của SCD: Khi bối cảnh là chìa khóa của sự chính xác
Trong kiến trúc kho dữ liệu, nếu không có SCD, hệ thống của bạn giống như một bức ảnh chụp nhanh (snapshot) chỉ hiển thị được thực tại. Khi một khách hàng ở Hà Nội chuyển vào TP. Hồ Chí Minh, việc ghi đè địa chỉ mới lên dữ liệu cũ sẽ khiến toàn bộ doanh thu phát sinh trước đó của họ bị gán nhầm cho khu vực phía Nam.
SCD giải quyết vấn đề này bằng cách quản lý các thay đổi chậm của dữ liệu mô tả, đảm bảo mỗi sự kiện luôn được kết nối với đúng “phiên bản” của thực thể tại thời điểm đó. Điều này tạo ra một nền tảng vững chắc cho phân tích bối cảnh, thực hiện audit dữ liệu minh bạch và cung cấp dữ liệu huấn luyện chính xác cho các mô hình Machine Learning – nơi trạng thái của dữ liệu tại thời điểm quá khứ (Point-in-time) là yếu tố quyết định độ chính xác của mô hình.
Việc bỏ qua quản lý lịch sử chiều (dimension) sẽ dẫn đến hiệu ứng “nhảy số” trên Dashboard. Hãy tưởng tượng sếp của bạn xem báo cáo doanh thu theo vùng của năm ngoái vào tháng 1, sau đó xem lại vào tháng 6 và thấy con số đã thay đổi chỉ vì một nhóm khách hàng lớn vừa chuyển vùng sinh sống. Sự thiếu nhất quán này làm xói mòn niềm tin vào dữ liệu (Data Trust), thứ vốn dĩ là tài sản quý giá nhất của đội ngũ làm dữ liệu.
II. Phân loại các chiến lược SCD: Từ cơ bản đến chuyên sâu
Tùy vào nhu cầu phân tích và tài nguyên hệ thống, các kỹ sư dữ liệu sẽ lựa chọn một trong các loại SCD phổ biến sau đây. Mỗi loại đại diện cho một mức độ ưu tiên giữa chi phí vận hành và nhu cầu lưu giữ lịch sử.
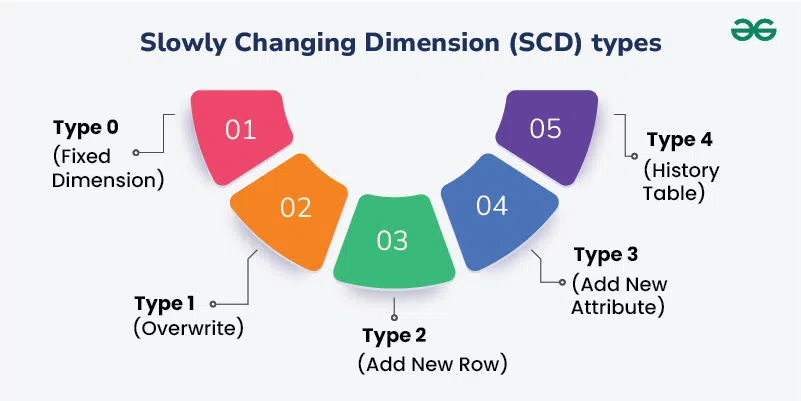
1. SCD Type 0: Sự bất biến tuyệt đối
SCD Type 0 được dành riêng cho những dữ liệu mang tính định danh gốc và không bao giờ thay đổi sau khi đã được nạp lần đầu. Ví dụ điển hình là ngày sinh của khách hàng hoặc mã định danh ban đầu của một thiết bị IoT. Mặc dù đơn giản, Type 0 đóng vai trò như một chốt chặn bảo mật, ngăn chặn các lỗi logic từ hệ thống nguồn làm sai lệch những thông tin mang tính nền tảng.
2. SCD Type 1: Ghi đè – Sự ưu tiên cho thực tại
SCD Type 1 chọn cách tiếp cận thực dụng nhất: khi dữ liệu thay đổi, giá trị mới sẽ ghi đè trực tiếp lên giá trị cũ. Đây là lựa chọn lý tưởng cho những thông tin không có giá trị phân tích quá khứ, chẳng hạn như sửa lỗi chính tả tên khách hàng, cập nhật số điện thoại hoặc email. Ưu điểm của nó là giữ cho bảng dữ liệu cực kỳ gọn nhẹ và query đơn giản vì không có bản ghi trùng lặp. Tuy nhiên, cái giá phải trả là bạn mất sạch dấu vết quá khứ.
3. SCD Type 2: “Tiêu chuẩn vàng” và là trái tim của Data Warehouse
Đây là kỹ thuật cốt lõi trong mọi hệ thống chuyên nghiệp. Thay vì thay đổi dòng cũ, hệ thống tạo ra một dòng mới với một Surrogate Key (Khóa thay thế) riêng biệt. Các cột kỹ thuật như start_date, end_date, và is_current trở thành những “tọa độ thời gian” giúp định vị chính xác mỗi phiên bản.
Khi một khách hàng thay đổi địa chỉ, bản ghi cũ sẽ được “đóng” lại bằng cách cập nhật end_date là ngày hôm nay, và một bản ghi mới được “mở” ra. Nhờ đó, Fact Table có thể tìm đúng phiên bản dữ liệu mô tả dựa trên thời điểm giao dịch xảy ra thông qua phép Join trên Surrogate Key. Đây là cách duy nhất để đảm bảo tính nhất quán của dữ liệu qua các thời kỳ.
4. SCD Type 3: Lưu trữ lịch sử hạn chế
SCD Type 3 lưu giá trị hiện tại và một giá trị ngay trước đó trong cùng một dòng bằng cách thêm cột previous_value. Phương pháp này cung cấp khả năng so sánh nhanh giữa “trước” và “sau” mà không làm tăng số lượng bản ghi. Tuy nhiên, nó chỉ lưu được một phiên bản lịch sử duy nhất. Nếu dữ liệu thay đổi lần thứ ba, thông tin của lần thứ nhất sẽ bị xóa bỏ. Nó thường được dùng cho các thay đổi có tính chất chu kỳ hoặc ngắn hạn.
5. SCD Type 4: Mô hình bảng lịch sử tách biệt
Trong kiến trúc hiện đại, SCD Type 4 ngày càng phổ biến. Hệ thống duy trì hai bảng: một bảng chỉ chứa dữ liệu mới nhất (giúp báo cáo BI chạy cực nhanh) và một bảng phụ lưu toàn bộ lịch sử (History table). Cách tiếp cận lai này giải quyết được mâu thuẫn giữa nhu cầu tốc độ của người dùng cuối và nhu cầu truy vết của các nhà khoa học dữ liệu.
III. Quy trình vận hành SCD trong Pipeline ETL: Phân tích kỹ thuật
Để thực hiện SCD Type 2, một pipeline không chỉ đơn thuần là đẩy dữ liệu đi mà phải thực hiện một quy trình so sánh logic cực kỳ nghiêm ngặt. Đây là nơi các kỹ sư dữ liệu thể hiện kỹ năng tối ưu hóa hệ thống.
1. Cơ chế Change Detection (Phát hiện thay đổi)
Quy trình bắt đầu bằng việc đọc dữ liệu từ nguồn và so sánh với dữ liệu hiện tại trong kho. Tuy nhiên, việc so sánh từng cột (column-by-column comparison) cho những bảng có hàng trăm thuộc tính là một thảm họa về hiệu suất. Giải pháp tối ưu là sử dụng kỹ thuật Hash Diff. Toàn bộ các trường thông tin cần theo dõi sẽ được băm (hash) thành một chuỗi mã hóa duy nhất (ví dụ dùng MD5 hoặc SHA-256). Nếu mã băm của bản ghi nguồn khác mã băm của bản ghi trong kho, hệ thống hiểu rằng có sự thay đổi.
2. Quản lý Surrogate Key
Theo tài liệu về Dimensional Modeling của Ralph Kimball, việc sử dụng Surrogate Key thay vì Business Key (như ID gốc từ ứng dụng) là yếu tố bắt buộc. Business Key có thể bị tái sử dụng hoặc thay đổi do lỗi hệ thống nguồn, nhưng Surrogate Key là nội bộ của Data Warehouse, đảm bảo mỗi dòng lịch sử là duy nhất và không bao giờ thay đổi.
3. Quy trình MERGE logic
Pipeline sẽ thực hiện một lệnh MERGE (hoặc UPSERT tùy nền tảng):
- Nếu không khớp Business Key: Chèn bản ghi mới (New Member).
- Nếu khớp Business Key nhưng khác mã băm: Cập nhật bản ghi cũ (Expire old record) và chèn bản ghi mới (Insert new version).
- Nếu khớp cả hai: Bỏ qua (No change).
IV. Những thách thức “xương xẩu” trong môi trường Production
Lý thuyết về SCD rất rõ ràng, nhưng thực tế triển khai luôn ẩn chứa những rủi ro có thể đánh sập hệ thống.
1. Bài toán Late-arriving Dimension
Đây là tình huống “ác mộng” nhất: Bạn nhận được thông tin thay đổi địa chỉ của khách hàng diễn ra từ 3 tháng trước, nhưng dữ liệu giao dịch của 3 tháng đó đã được nạp xong và gắn với địa chỉ cũ. Khi đó, bạn buộc phải thực hiện quy trình Backfill. Bạn phải chèn phiên bản lịch sử đó vào “giữa” các phiên bản đang có, điều chỉnh lại ngày bắt đầu/kết thúc của các bản ghi liên quan và có thể phải chạy lại (reprocess) các bảng Fact để đảm bảo tính chính xác.
Đọc thêm: Data Backfill: Khi Pipeline cần “ngược dòng thời gian” xử lý dữ liệu lịch sử
2. Bùng nổ kích thước dữ liệu (Data Volatility)
Nếu một thuộc tính thay đổi quá thường xuyên (ví dụ: số dư tài khoản hay điểm tín dụng thay đổi hàng giờ), việc áp dụng SCD Type 2 sẽ khiến bảng Dimension phình to khủng khiếp, làm giảm hiệu suất Join. Trong trường hợp này, các kỹ sư thường tách các thuộc tính “thay đổi nhanh” sang một bảng riêng (gọi là Junk Dimension hoặc Rapidly Changing Attribute) để bảo vệ sự ổn định cho bảng Dimension chính.
3. Đảm bảo tính Idempotent
Pipeline SCD phải đảm bảo tính Idempotent – nghĩa là dù bạn chạy lại pipeline bao nhiêu lần với cùng một tập dữ liệu đầu vào, kết quả trong kho dữ liệu phải không đổi. Nếu không kiểm soát kỹ, việc chạy lại pipeline có thể vô tình đóng/mở thêm các phiên bản trùng lặp, gây sai lệch nghiêm trọng cho báo cáo.
V. Best Practices để xây dựng hệ thống SCD bền bỉ
Để một hệ thống SCD vận hành trơn tru qua nhiều năm, đội ngũ kỹ thuật cần tuân thủ các nguyên tắc thiết kế sau:
- Tối ưu hóa tài nguyên Cloud: Với các bảng SCD lên đến hàng chục triệu dòng, hãy sử dụng kỹ thuật phân vùng (Partitioning) theo effective_start_date hoặc thời gian nạp dữ liệu. Điều này giúp Query Engine chỉ quét những phân vùng cần thiết thay vì toàn bộ bảng.
- Sử dụng Semantic Layer: Đừng để analyst phải tự viết các câu lệnh lọc WHERE is_current = True. Hãy tạo các View hoặc lớp Semantic để ẩn đi sự phức tạp của SCD, giúp người dùng cuối tiếp cận dữ liệu một cách dễ dàng nhất.
- Tự động hóa với công cụ hiện đại: Thay vì viết hàng trăm dòng SQL MERGE thủ công, hãy tận dụng tính năng snapshots của các công cụ như dbt (data build tool). Nó tự động hóa toàn bộ việc quản lý lịch sử, tạo Surrogate Key và xử lý ngày hiệu lực, giúp giảm 80% công sức vận hành.
- Giám sát chất lượng (Data Quality Monitoring): Thiết lập các bài kiểm tra tự động để đảm bảo không có hai bản ghi nào của cùng một khách hàng có khoảng thời gian hiệu lực bị chồng lấn (overlapping) hoặc bị hở (gaps).
VI. SCD trong kiến trúc dữ liệu hiện đại
Ngày nay, SCD không còn chỉ nằm trong các kho dữ liệu SQL truyền thống. Với sự trỗi dậy của Lakehouse (như Databricks Delta Lake hay Apache Iceberg), khả năng quản lý phiên bản dữ liệu (Time Travel) đã đưa SCD lên một tầm cao mới. Bạn có thể dễ dàng truy vấn dữ liệu của một bảng tại một mốc thời gian bất kỳ trong quá khứ chỉ với một dòng lệnh SQL đơn giản.
Tuy nhiên, dù công nghệ có thay đổi, tư duy về SCD vẫn giữ nguyên giá trị cốt lõi: Sự thật lịch sử là nền tảng của mọi phân tích đúng đắn.
VII. Kết luận
Slowly Changing Dimension không chỉ là một thủ thuật lưu trữ dữ liệu; nó là cam kết của đội ngũ kỹ thuật về tính trung thực của thông tin. Nó cho phép chúng ta nhìn về quá khứ với một lăng kính chính xác, đảm bảo rằng mọi báo cáo kinh doanh hôm nay đều dựa trên một sự thật nhất quán.
Việc thấu hiểu và triển khai đúng chiến lược SCD sẽ giúp hệ thống Analytics của bạn không chỉ nhanh mà còn sâu sắc, biến dữ liệu từ những con số vô hồn thành những câu chuyện lịch sử có giá trị, giúp doanh nghiệp đưa ra những quyết định dựa trên dữ liệu (Data-driven) một cách tự tin nhất.
INDA Academy tự hào là đơn vị tiên phong trong việc đào tạo phân tích dữ liệu và AI chuyên sâu, đặc biệt cho khối ngành Ngân hàng – Tài chính – Bảo hiểm tại Việt Nam. Sau hơn 12 năm “thực chiến” cùng những dòng chảy dữ liệu khổng lồ, chúng tôi đã xây dựng nên một hệ sinh thái đào tạo toàn diện, giúp hàng nghìn học viên chuyển mình từ người mới bắt đầu trở thành những chuyên gia lành nghề, sẵn sàng đáp ứng tiêu chuẩn khắt khe của các doanh nghiệp lớn.
Điểm khác biệt lớn nhất tại INDA chính là triết lý đào tạo dựa trên các dự án thực tế (Project-based) và lộ trình cá nhân hóa nhờ ứng dụng AI. Chúng tôi không chỉ dạy bạn cách sử dụng công cụ, mà còn truyền tải tư duy khai phá giá trị từ dữ liệu để đưa ra quyết định kinh doanh chính xác.
Tìm hiểu thêm về các khóa học TẠI ĐÂY:
Lộ trình đào tạo Data Engineer
Lộ trình đào tạo Data Analyst
Lộ trình đào tạo Tester
Khóa học Data Engineer nâng cao – Thực chiến 5 dự án doanh nghiệp
Khóa học Data Analyst nâng cao – Thực chiến 5 dự án doanh nghiệp