
Last updated on February 9th, 2022 at 01:55 pm
Mục lục
Xem thêm phần 1 về Cách tiếp cận Lakehouse.
Theo cách tiếp cận này, các dịch vụ AWS đảm nhận công việc nặng nhọc sau đây:
-
Cung cấp và quản lý các thành phần cơ sở hạ tầng có thể mở rộng, linh hoạt, an toàn và hiệu quả về chi phí
-
Đảm bảo các thành phần cơ sở hạ tầng tích hợp tự nhiên với nhau
Cách tiếp cận này cho phép bạn tập trung nhiều thời gian hơn vào các công việc sau:
-
Nhanh chóng xây dựng các pipeline phân tích và dữ liệu
-
Tăng tốc đáng kể việc tích hợp dữ liệu mới và thúc đẩy thông tin chi tiết từ dữ liệu của bạn
-
Hỗ trợ nhiều tính cách người dùng
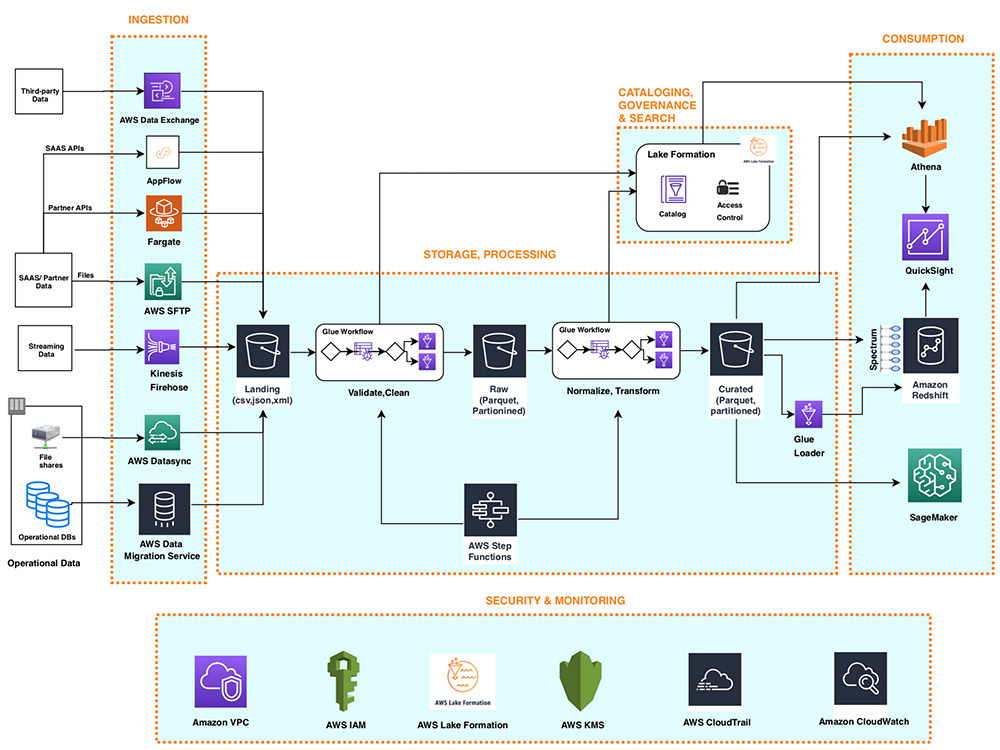
Kiến trúc Tham chiếu Lakehouse trên AWS
Sơ đồ sau minh họa kiến trúc tham chiếu Lakehouse trên AWS:

1. Data Ingestion Layer
Data ingestion layer trong kiến trúc tham chiếu Lakehouse của chúng tôi bao gồm một tập hợp các dịch vụ AWS được xây dựng theo mục đích để cho phép nhập dữ liệu từ nhiều nguồn khác nhau vào storage layer Lakehouse. Hầu hết các dịch vụ nhập có thể cung cấp dữ liệu trực tiếp đến cả data lake và lưu trữ data warehouse. Các dịch vụ AWS được xây dựng theo mục đích riêng phù hợp với yêu cầu kết nối, định dạng dữ liệu, cấu trúc dữ liệu và tốc độ dữ liệu duy nhất của các nguồn sau:
-
Cơ sở dữ liệu vận hành
-
Ứng dụng SaaS
-
Chia sẻ file
-
Dữ liệu streaming
1.1. Cơ sở dữ liệu vận hành (OLTP, ERP, CRM)
Thành phần AWS Data Migration Service (AWS DMS) trong ingestion layer có thể kết nối với một số cơ sở dữ liệu RDBMS và NoSQL đang hoạt động và nhập dữ liệu của chúng vào nhóm Amazon Simple Storage Service (Amazon S3) trong data lake hoặc trực tiếp vào các bảng dàn trong Amazon Redshift data warehouse. Với AWS DMS, bạn có thể thực hiện nhập dữ liệu nguồn một lần và sau đó sao chép các thay đổi đang diễn ra trong cơ sở dữ liệu nguồn.
1.2. Ứng dụng SaaS
Ingestion layer sử dụng Amazon AppFlow để dễ dàng nhập dữ liệu ứng dụng SaaS vào data lake của bạn. Với một vài cú nhấp chuột, bạn có thể thiết lập luồng nhập dữ liệu không cần máy chủ trong Amazon AppFlow.
Luồng của bạn có thể kết nối với các ứng dụng SaaS như Salesforce, Marketo và Google Analytics, nhập dữ liệu và phân phối dữ liệu đó đến storage layer Lakehouse, tới S3 bucket trong data lake hoặc trực tiếp tới các bảng dàn trong data warehouse Amazon Redshift. Bạn có thể lên lịch các luồng nhập dữ liệu Amazon AppFlow hoặc kích hoạt chúng bằng các events trong ứng dụng SaaS. Dữ liệu được nhập có thể được validated, filtered, mapped, và masked trước khi phân phối đến bộ nhớ Lakehouse.
1.3. File shares
Nhiều ứng dụng lưu trữ dữ liệu có cấu trúc và không có cấu trúc trong các tệp được lưu trữ trên ổ cứng mạng (NAS). AWS DataSync có thể nhập hàng trăm terabyte và hàng triệu tệp từ các thiết bị NAS hỗ trợ NFS và SMB vào vùng đích của data lake.
DataSync tự động xử lý tập lệnh của các công việc sao chép, lên lịch và giám sát chuyển giao, xác thực tính toàn vẹn của dữ liệu và tối ưu hóa việc sử dụng mạng. DataSync có thể thực hiện chuyển tệp một lần và sau đó theo dõi và đồng bộ hóa các tệp đã thay đổi vào Lakehouse. DataSync được quản lý đầy đủ và có thể được thiết lập trong vài phút.
1.4. Dữ liệu streaming
Ingestion layer sử dụng Amazon Kinesis Data Firehose để nhận dữ liệu truyền trực tuyến từ các nguồn bên trong hoặc bên ngoài và phân phối đến storage layer Lakehouse. Với một vài cú nhấp chuột, bạn có thể định cấu hình điểm cuối API Kinesis Data Firehose nơi các nguồn có thể gửi dữ liệu truyền trực tuyến như clickstreams, nhật ký ứng dụng, cơ sở hạ tầng và số liệu giám sát cũng như dữ liệu IoT như thiết bị đo từ xa và đọc cảm biến. Kinesis Data Firehose thực hiện các hành động sau:
-
Đệm các incoming stream
-
Đồng bộ, nén, chuyển đổi, phân vùng và mã hóa dữ liệu
-
Cung cấp dữ liệu dưới dạng các đối tượng S3 vào data lake hoặc dưới dạng các hàng thành các staging tables trong data warehouse Amazon Redshift
Kinesis Data Firehose không có máy chủ, không yêu cầu quản trị và bạn chỉ phải trả tiền cho khối lượng dữ liệu bạn truyền và xử lý thông qua dịch vụ. Kinesis Data Firehose tự động thay đổi tỷ lệ để điều chỉnh theo khối lượng và thông lượng của dữ liệu đến. Để xây dựng pipeline phân tích phát trực tuyến theo thời gian thực, ingestion layer cung cấp Amazon Kinesis Data Streams.

2. Lakehouse Storage Layer
Amazon Redshift và Amazon S3 cung cấp storage layer thống nhất, được tích hợp nguyên bản của kiến trúc tham chiếu Lakehouse. Thông thường, Amazon Redshift lưu trữ dữ liệu đáng tin cậy, phù hợp và được quản lý cao, được cấu trúc thành các schema chiều tiêu chuẩn, trong khi Amazon S3 cung cấp bộ lưu trữ data lake quy mô exabyte cho dữ liệu có cấu trúc, bán cấu trúc và phi cấu trúc.
Với hỗ trợ dữ liệu bán cấu trúc trong Amazon Redshift, bạn cũng có thể nhập và lưu trữ dữ liệu bán cấu trúc trong data warehouse Amazon Redshift của mình. Amazon S3 cung cấp khả năng mở rộng, khả năng cung cấp dữ liệu, bảo mật và hiệu suất hàng đầu trong ngành. Các tổ chức thường lưu trữ dữ liệu trong Amazon S3 bằng các định dạng tệp mở. Các định dạng tệp mở cho phép phân tích cùng một dữ liệu Amazon S3 bằng cách sử dụng nhiều thành phần lớp xử lý và tiêu thụ.
Lớp danh mục chung lưu trữ các schema của tập dữ liệu có cấu trúc hoặc bán cấu trúc trong Amazon S3. Các thành phần sử dụng tập dữ liệu S3 thường áp dụng schema này cho tập dữ liệu khi chúng đọc nó (hay còn gọi là schema-on-read).
Amazon Redshift Spectrum là một trong những trung tâm của storage layer Lakehouse được tích hợp nguyên bản. Redshift Spectrum cho phép Amazon Redshift trình bày một giao diện SQL thống nhất có thể chấp nhận và xử lý các câu lệnh SQL trong đó cùng một truy vấn có thể tham chiếu và kết hợp các tập dữ liệu được lưu trữ trong data lake cũng như lưu trữ trong data warehouse.
Amazon Redshift có thể truy vấn hàng petabyte dữ liệu được lưu trữ trong Amazon S3 bằng cách sử dụng một lớp lên đến hàng nghìn node Redshift Spectrum tạm thời và áp dụng các tối ưu hóa truy vấn phức tạp của Amazon Redshift. Redshift Spectrum có thể truy vấn dữ liệu được phân vùng trong data lake S3. Nó có thể đọc dữ liệu được nén bằng codec mã nguồn mở và được lưu trữ ở định dạng hàng hoặc cột mã nguồn mở bao gồm JSON, CSV, Avro, Parquet, ORC và Apache Hudi.
Khi Redshift Spectrum đọc các tập dữ liệu được lưu trữ trong Amazon S3, nó sẽ áp dụng schema tương ứng từ danh mục AWS Lake Formation chung cho dữ liệu (schema-on-read). Với Redshift Spectrum, bạn có thể xây dựng các pipeline gốc Amazon Redshift thực hiện các hành động sau:
-
Lưu giữ khối lượng lớn historical data trong data lake và nhập hot data trong vài tháng vào data warehouse bằng cách sử dụng Redshift Spectrum
-
Tạo tập dữ liệu được bổ sung chi tiết bằng cách xử lý cả hot data trong bộ lưu trữ đính kèm và historical data trong data lake, tất cả đều không di chuyển dữ liệu theo một trong hai hướng
-
Chèn các hàng tập dữ liệu đã được bổ sung chi tiết vào một bảng được lưu trữ trên bộ lưu trữ đính kèm hoặc trực tiếp vào bảng bên ngoài được lưu trữ trong data lake
-
Dễ dàng giảm tải khối lượng lớn historical data từ data warehouse vào bộ lưu trữ data lake rẻ hơn và vẫn dễ dàng truy vấn nó như một phần của các truy vấn Amazon Redshift
Dữ liệu có cấu trúc cao trong Amazon Redshift thường hỗ trợ các truy vấn tương tác và bảng điều khiển BI nhanh, đáng tin cậy, trong khi dữ liệu có cấu trúc, không cấu trúc và bán cấu trúc trong Amazon S3 thường thúc đẩy các trường hợp sử dụng ML, khoa học dữ liệu và xử lý dữ liệu lớn.
AWS DMS và Amazon AppFlow trong ingestion layer có thể phân phối dữ liệu từ các nguồn có cấu trúc trực tiếp đến data lake S3 hoặc data warehouse Amazon Redshift để đáp ứng các yêu cầu của ca sử dụng. Trong trường hợp nhập file dữ liệu, DataSync đưa dữ liệu vào Amazon S3. Các thành phần của processing layer có thể truy cập dữ liệu trong storage layer Lakehouse hợp nhất thông qua một giao diện thống nhất duy nhất như Amazon Redshift SQL, có thể kết hợp dữ liệu được lưu trữ trong cụm Amazon Redshift với dữ liệu trong Amazon S3 bằng cách sử dụng Redshift Spectrum.
Trong S3 Data Lake, cả dữ liệu có cấu trúc và không có cấu trúc đều được lưu trữ dưới dạng các đối tượng S3. Các đối tượng S3 trong data lake được tổ chức thành các nhóm hoặc tiền tố đại diện cho các vùng landing, raw, trusted, và curated. Đối với các pipeline lưu trữ dữ liệu trong data lake S3, dữ liệu được nhập từ nguồn vào vùng đích như hiện tại.
Sau đó, processing layer xác thực dữ liệu vùng landing và lưu trữ dữ liệu đó trong nhóm vùng raw hoặc prefix để lưu trữ vĩnh viễn. Processing layer áp dụng schema, phân vùng và các phép biến đổi khác cho dữ liệu vùng raw để đưa nó về trạng thái phù hợp và lưu trữ nó trong vùng trusted. Bước cuối cùng, processing layer sắp xếp một tập dữ liệu vùng trusted bằng cách mô hình hóa nó, kết hợp nó với các tập dữ liệu khác và lưu trữ nó trong curated layer. Thông thường, các tập dữ liệu từ curated layer được nhập một phần hoặc toàn bộ vào kho lưu trữ dữ liệu Amazon Redshift để phục vụ các trường hợp sử dụng cần truy cập độ trễ rất thấp hoặc cần chạy các truy vấn SQL phức tạp.
Tập dữ liệu trong mỗi vùng thường được phân vùng dọc theo một key phù hợp với mẫu tiêu thụ cụ thể cho vùng tương ứng (thô, đáng tin cậy hoặc được sắp xếp). Các đối tượng S3 tương ứng với tập dữ liệu được nén, sử dụng codec mã nguồn mở như GZIP, BZIP và Snappy, để giảm chi phí lưu trữ và thời gian đọc cho các thành phần trong lớp xử lý và tiêu thụ. Các tập dữ liệu thường được lưu trữ trong các định dạng cột mã nguồn mở như Parquet và ORC để giảm thêm lượng dữ liệu đọc khi các thành phần của lớp xử lý và tiêu thụ chỉ truy vấn một tập hợp con của các cột. Amazon S3 cung cấp một loạt các storage layer được thiết kế cho các trường hợp sử dụng khác nhau. Lớp lưu trữ phân cấp thông minh của Amazon S3 được thiết kế để tối ưu hóa chi phí bằng cách tự động di chuyển dữ liệu sang cấp truy cập hiệu quả về chi phí nhất mà không ảnh hưởng đến hiệu suất hoặc chi phí hoạt động.
Amazon Redshift cung cấp data warehouse quy mô petabyte lưu trữ cho dữ liệu có cấu trúc cao thường được mô hình hóa thành các dimensional hoặc denormalized schemas. Trên Amazon Redshift, dữ liệu được lưu trữ ở định dạng cột, được nén cao và được lưu trữ theo kiểu phân tán trên một cụm các nút hiệu suất cao. Mỗi nút cung cấp lên đến 64 TB dung lượng lưu trữ được quản lý hiệu quả cao. Amazon Redshift cho phép chất lượng dữ liệu cao và tính nhất quán bằng cách thực thi các giao dịch trên schema, ACID và cách ly khối lượng công việc. Các tổ chức thường lưu trữ dữ liệu có cấu trúc là dataset được tuân thủ cao, hài hòa, đáng tin cậy và được quản lý trên Amazon Redshift để phục vụ các trường hợp sử dụng yêu cầu thông lượng rất cao, độ trễ rất thấp và đồng thời cao. Bạn cũng có thể sử dụng các chế độ xem cụ thể hóa từng bước được làm mới trong Amazon Redshift để tăng đáng kể hiệu suất và thông lượng của các truy vấn phức tạp được tạo bởi bảng điều khiển BI.
Khi bạn xây dựng Lakehouse bằng cách nhập dữ liệu từ nhiều nguồn khác nhau, bạn thường có thể bắt đầu lưu trữ hàng trăm đến hàng nghìn dataset trên data lake và data warehouse của mình. Một danh mục dữ liệu trung tâm để cung cấp metadata cho tất cả các dataset trong bộ lưu trữ Lakehouse (data warehouse cũng như data lake) ở một nơi duy nhất và dễ dàng tìm kiếm là rất quan trọng để tự phục vụ việc khám phá dữ liệu trong Lakehouse. Ngoài ra, việc tách metadata khỏi dữ liệu được lưu trữ trong data lake thành một schema trung tâm kích hoạt schema-on-read cho các thành phần processing và consumption layer cũng như Redshift Spectrum.
Trong kiến trúc tham chiếu Lakehouse, Lake Formation cung cấp danh mục trung tâm để lưu trữ metadata cho tất cả các tập dữ liệu được lưu trữ trong Lakehouse (cho dù được lưu trữ trong Amazon S3 hay Amazon Redshift). Các tổ chức lưu trữ cả metadata kỹ thuật (chẳng hạn như versioned table schemas, thông tin phân vùng, vị trí dữ liệu thực và dấu thời gian cập nhật) và các thuộc tính kinh doanh (chẳng hạn như chủ sở hữu dữ liệu, người quản lý dữ liệu, định nghĩa kinh doanh cột và độ nhạy thông tin cột) của tất cả các dataset của họ trong Lake Formation.
Nhiều dataset được lưu trữ trong data lake thường có schema liên tục phát triển và tăng phân vùng dữ liệu, trong khi các schema của dataset được lưu trữ trong data warehouse phát triển một cách có quản lý. Trình thu thập dữ liệu AWS Glue theo dõi các schema đang phát triển và các phân vùng dữ liệu mới được thêm vào được lưu trữ trong dataset được lưu trữ trong data lake cũng như dataset được lưu trữ trong data warehouse và thêm các phiên bản mới của các schema tương ứng trong danh mục Lake Formation. Ngoài ra, Lake Formation cung cấp các API để cho phép đăng ký và quản lý metadata bằng cách sử dụng các tập lệnh tùy chỉnh và các sản phẩm của bên thứ ba.
Lake Formation cung cấp cho người quản trị data lake một trung tâm để thiết lập quyền cấp bảng và cột chi tiết cho cơ sở dữ liệu và bảng được lưu trữ trong data lake. Sau khi bạn thiết lập quyền của Lake Formation, người dùng và nhóm chỉ có thể truy cập các bảng và cột được ủy quyền bằng cách sử dụng nhiều dịch vụ processing và consumption layer như AWS Glue, Amazon EMR, Amazon Athena và Redshift Spectrum.
Còn tiếp…

Với hơn 15 năm kinh nghiệm trong lĩnh vực Data Engineering, Business Intelligence (BI) và Data Analytics, Ha Vu Phuong không chỉ là một chuyên gia trong ngành mà còn là người tiên phong trong việc triển khai hệ thống dữ liệu lớn cho các ngân hàng và doanh nghiệp tại Việt Nam.
Bài viết liên quan:
 ERD là gì – Cách thiết kế ERD (Entity-Relationship Diagram)
ERD là gì – Cách thiết kế ERD (Entity-Relationship Diagram)
 11 bước để Triển khai kho dữ liệu
11 bước để Triển khai kho dữ liệu
 Data Engineer là gì? Những thông tin bạn cần nắm rõ về Data Engineer
Data Engineer là gì? Những thông tin bạn cần nắm rõ về Data Engineer
 Quản trị dữ liệu trong các ngân hàng Việt Nam
Quản trị dữ liệu trong các ngân hàng Việt Nam
 Data Lake là gì? Lợi ích của Data Lake là gì?
Data Lake là gì? Lợi ích của Data Lake là gì?
 TẦM QUAN TRỌNG CỦA QUẢN LÝ DỮ LIỆU (DATA MANAGEMENT) (P2)
TẦM QUAN TRỌNG CỦA QUẢN LÝ DỮ LIỆU (DATA MANAGEMENT) (P2)