

Trong cuộc đua chuyển đổi số, dữ liệu không chỉ là tài sản mà đã trở thành năng lực cốt lõi. Tuy nhiên, ranh giới giữa việc sở hữu dữ liệu và việc khai thác dữ liệu hiệu quả thường bị ngăn cách bởi những rào cản về kiến trúc hạ tầng. Data Lakehouse ra đời không phải như một xu hướng nhất thời, mà là một sự tiến hóa tất yếu để giải quyết mâu thuẫn giữa tính linh hoạt của Data Lake và sự chính xác của Data Warehouse.
Để triển khai thành công, doanh nghiệp cần nhìn nhận Lakehouse như một kiến trúc hệ thống hoàn chỉnh thay vì chỉ là một tập hợp các công cụ rời rạc. Bài viết này sẽ mổ xẻ mọi ngóc ngách của kiến trúc Data Lakehouse, từ tầng vật lý đến các quyết định thiết kế chiến lược.
Mục lục
1. Bản chất của Kiến trúc Data Lakehouse: Sự hội tụ của hai thế giới
Trước khi đi sâu vào các thành phần, chúng ta cần hiểu rõ lý do tại sao kiến trúc này lại thay đổi cuộc chơi. Trong quá khứ, doanh nghiệp thường phải duy trì hai hệ thống song song: một Data Lake để lưu trữ dữ liệu thô phục vụ AI/ML và một Data Warehouse để phục vụ báo cáo BI. Điều này dẫn đến sự phân mảnh dữ liệu (Data Silos), tăng gấp đôi chi phí lưu trữ và gây ra sự mâu thuẫn trong các báo cáo kinh doanh.
Kiến trúc Data Lakehouse xóa bỏ ranh giới này bằng cách xây dựng một lớp quản lý thông minh trực tiếp trên nền tảng lưu trữ giá rẻ. Điểm cốt lõi giúp Lakehouse khác biệt chính là tính Decoupled (Tách biệt). Việc tách biệt hoàn toàn giữa Storage (Lưu trữ) và Compute (Tính toán) cho phép hệ thống mở rộng không giới hạn mà không bị ràng buộc về mặt phần cứng hay chi phí.
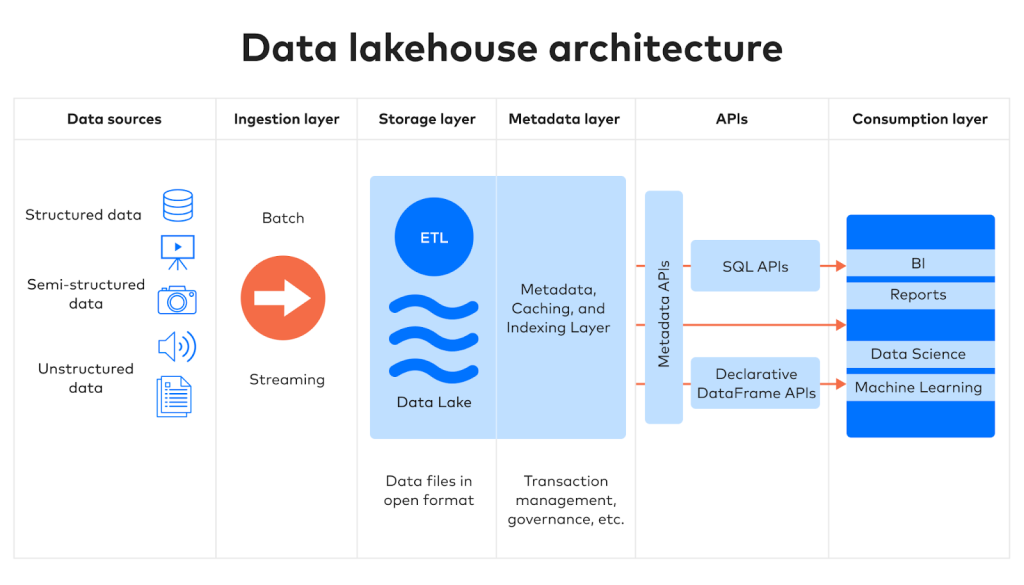
2. Phân tích 5 tầng chức năng của một hệ thống Lakehouse chuẩn mực
Một hệ thống Data Lakehouse “vững chãi” thường được cấu thành từ 5 lớp logic, phối hợp nhịp nhàng để đảm bảo dữ liệu luôn trôi chảy và sạch sẽ.
2.1. Ingestion Layer (Tầng thu thập dữ liệu)
Đây là điểm chạm đầu tiên của dữ liệu vào hệ thống. Trong kiến trúc hiện đại, tầng này phải xử lý đa dạng các luồng dữ liệu:
- Batch Processing: Nạp dữ liệu theo định kỳ (ví dụ hàng giờ, hàng ngày) từ các nguồn như SQL Server, Oracle.
- Streaming & Real-time: Thu thập dữ liệu ngay lập tức từ các thiết bị IoT, log website hoặc ứng dụng di động thông qua Kafka.
- Change Data Capture (CDC): Một kỹ thuật tối quan trọng giúp đồng bộ các thay đổi nhỏ nhất từ cơ sở dữ liệu gốc vào Lakehouse mà không làm quá tải hệ thống nguồn.
2.2. Storage Layer (Tầng lưu trữ vật lý)
Lớp này thường sử dụng Cloud Object Storage (Amazon S3, Azure Blob Storage). Tại đây, dữ liệu được lưu trữ dưới dạng các tệp tin cột (Columnar files) như Parquet hoặc ORC. Việc lưu trữ theo cột giúp tối ưu hóa dung lượng nén và cho phép các công cụ tính toán chỉ đọc đúng những cột cần thiết, giúp tiết kiệm đáng kể tài nguyên I/O.
2.3. Metadata & Table Format Layer (Linh hồn của Lakehouse)
Nếu thiếu lớp này, kiến trúc Lakehouse sẽ sụp đổ trở lại thành một “Data Swamp” (đầm lầy dữ liệu). Các công nghệ như Delta Lake, Apache Iceberg hoặc Hudi đóng vai trò là lớp Metadata trung gian. Lớp này cung cấp các tính năng mà trước đây chỉ có trong Database truyền thống:
- Tính nhất quán ACID: Đảm bảo dữ liệu không bị lỗi khi có nhiều người cùng đọc/ghi.
- Time Travel: Khả năng “du hành thời gian” để truy vấn lại các phiên bản dữ liệu cũ, phục vụ mục đích kiểm toán hoặc sửa lỗi.
- Schema Evolution: Cho phép thay đổi cấu trúc bảng linh hoạt theo sự biến đổi của hoạt động kinh doanh.
2.4. Compute & Query Engine Layer (Tầng xử lý dữ liệu)
Lakehouse không phụ thuộc vào một công cụ duy nhất. Nó cho phép đa dạng hóa các Engine:
- Spark/Flink: Dành cho các pipeline biến đổi dữ liệu phức tạp.
- Trino/Presto: Dành cho các truy vấn phân tích tức thời với tốc độ cao.
- ML Engines: Các thư viện như TensorFlow truy cập trực tiếp vào dữ liệu để huấn luyện mô hình.
2.5. Data Governance & Security Layer (Tầng quản trị và bảo mật)
Đây là lớp bao phủ toàn bộ hệ thống, đảm bảo dữ liệu được phân quyền đúng người (Access Control), có nguồn gốc rõ ràng (Data Lineage) và đạt chuẩn chất lượng (Data Quality).
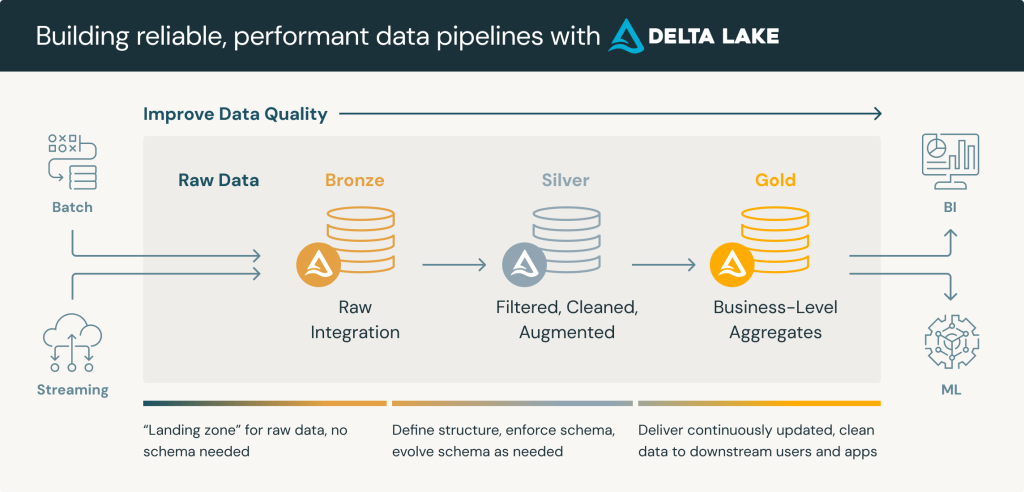
3. Luồng di chuyển của dữ liệu: Mô hình Medallion (Huy chương)
Để quản lý chất lượng dữ liệu hiệu quả, kiến trúc Lakehouse thường áp dụng mô hình Medallion, chia dữ liệu thành ba giai đoạn tinh lọc khác nhau.
Lớp Bronze (Raw Data – Dữ liệu thô)
Dữ liệu được nạp vào đây ở trạng thái nguyên bản nhất. Không có bất kỳ sự thay đổi nào được thực hiện. Lớp này đóng vai trò như một kho lưu trữ lịch sử vĩnh viễn, cho phép chúng ta tái xử lý dữ liệu từ đầu nếu quy trình kinh doanh thay đổi hoặc phát hiện lỗi logic ở các lớp sau.
Lớp Silver (Validated Data – Dữ liệu chuẩn hóa)
Tại đây, dữ liệu từ lớp Bronze được làm sạch, loại bỏ các bản ghi trùng lặp, xử lý các giá trị bị thiếu và áp dụng các cấu trúc bảng (Schema). Lớp Silver là “mỏ vàng” cho các nhà khoa học dữ liệu (Data Scientists) để thực hiện các phân tích chuyên sâu và huấn luyện mô hình AI.
Lớp Gold (Enriched Data – Dữ liệu kinh doanh)
Đây là sản phẩm cuối cùng của pipeline. Dữ liệu được tổng hợp, tính toán sẵn các chỉ số (Aggregated) và tối ưu hóa để phục vụ các báo cáo BI, Dashboard của cấp quản lý. Dữ liệu lớp Gold mang tính chính xác cao và là “nguồn sự thật duy nhất” (Single Source of Truth) cho toàn doanh nghiệp.
4. Những thách thức và quyết định thiết kế chiến lược
Thiết kế một kiến trúc Lakehouse không chỉ là việc chọn công cụ “xịn” nhất, mà là việc đưa ra những lựa chọn đánh đổi (Trade-offs) phù hợp.
4.1. Giải quyết bài toán “Small Files Problem”
Khi nạp dữ liệu liên tục (streaming), hệ thống dễ phát sinh hàng triệu file nhỏ. Điều này làm metadata layer bị quá tải và query engine chạy chậm lại.
Chiến lược thiết kế: Bạn cần thiết lập cơ chế Auto-compaction (tự động gộp file) để duy trì kích thước file ở mức lý tưởng (thường là 128MB – 512MB).
4.2. Chiến lược phân vùng (Partitioning) và Indexing
Việc phân vùng dữ liệu quá sâu (Over-partitioning) có thể gây tác dụng ngược. Ví dụ, nếu bạn phân vùng theo từng phút, hệ thống sẽ mất quá nhiều thời gian để duyệt qua các thư mục.
Chiến lược thiết kế: Chỉ phân vùng theo các chiều dữ liệu phổ biến nhất (thường là thời gian). Với các bảng có khối lượng cực lớn, hãy cân nhắc sử dụng Z-Order Indexing (một kỹ thuật đa chiều) để tăng tốc độ truy xuất mà không làm phức tạp hóa cấu trúc thư mục.
4.3. Quản lý chi phí (TCO Optimization)
Lợi thế của Lakehouse là rẻ, nhưng nếu không kiểm soát, chi phí tính toán (Compute) sẽ tăng vọt.
Chiến lược thiết kế: Áp dụng cơ chế Auto-scaling cho các cụm máy chủ và tận dụng Spot Instances (máy chủ giá rẻ của Cloud) cho các job xử lý không quá khẩn cấp.
5. Ví dụ thực tế: Triển khai Lakehouse trong hệ thống E-commerce
Hãy xem xét cách dữ liệu di chuyển trong một sàn thương mại điện tử lớn:
- Giai đoạn Ingestion: Dữ liệu đơn hàng từ Database và hành vi clickstream từ Website được đẩy vào Kafka và nạp liên tục vào lớp Bronze.
- Giai đoạn Processing: Một job Spark sẽ quét lớp Bronze mỗi 15 phút để làm sạch dữ liệu, kiểm tra tính hợp lệ của mã giảm giá và ghi vào lớp Silver.
- Giai đoạn Serving:
- Các nhà phân tích sử dụng Trino truy vấn trực tiếp vào lớp Gold để xem doanh thu thực tế theo thời gian thực.
- Hệ thống gợi ý sản phẩm (Recommendation System) truy cập vào lớp Silver để học hành vi người dùng và đưa ra gợi ý sản phẩm phù hợp ngay trong phiên làm việc.
- Giai đoạn Governance: Hệ thống tự động kiểm tra xem có bản ghi nào bị lỗi format không và gửi cảnh báo về Telegram cho đội ngũ Data Engineer.
6. Lộ trình 4 bước thiết kế hệ thống Lakehouse thành công
Để bài học lý thuyết đi vào thực tiễn, doanh nghiệp cần tuân thủ lộ trình sau:
- Xác định Use-case ưu tiên: Đừng cố xây dựng một hệ thống khổng lồ ngay từ đầu. Hãy bắt đầu bằng một bài toán cụ thể (ví dụ: Tối ưu hóa tồn kho).
- Lựa chọn Table Format chủ đạo: Delta Lake cho sự ổn định, Iceberg cho tính mở, hoặc Hudi cho bài toán Streaming nặng.
- Xây dựng Metadata Catalog: Thiết lập một từ điển dữ liệu để mọi người đều biết dữ liệu nào nằm ở đâu và ý nghĩa là gì.
- Triển khai DataOps: Áp dụng các quy trình kiểm thử tự động (Unit test cho dữ liệu) để đảm bảo pipeline luôn vận hành trơn tru.
Kết luận
Kiến trúc Data Lakehouse không phải là một đích đến cố định, mà là một hành trình tối ưu hóa liên tục. Sức mạnh thực sự của Lakehouse không nằm ở công nghệ bạn chọn, mà nằm ở cách bạn thiết kế các thành phần phối hợp với nhau để giải quyết bài toán kinh doanh.
Trong tương lai, khi AI ngày càng trở nên quan trọng, kiến trúc Lakehouse sẽ là nền tảng vững chắc nhất để doanh nghiệp xây dựng các hệ thống trí tuệ nhân tạo có khả năng tự học và tự tối ưu. Hãy bắt đầu với một tư duy hệ thống đúng đắn để biến hồ dữ liệu của bạn thành một tài sản sinh lời bền vững.
FAQ (Câu hỏi thường gặp)
1. Chi phí lớn nhất khi xây dựng Lakehouse là gì?
Không phải là tiền lưu trữ (Storage), mà là chi phí nhân sự Data Engineer và chi phí tính toán (Compute) nếu pipeline không được tối ưu hóa.
2. Data Lakehouse có cần dùng Hadoop không?
Không nhất thiết. Hầu hết các kiến trúc Lakehouse hiện đại đều chạy trực tiếp trên Cloud Object Storage và các Compute Engine tách biệt, loại bỏ sự phức tạp của hệ sinh thái Hadoop cũ.
3. Làm sao để bảo mật dữ liệu trong Lakehouse?
Bạn cần sử dụng các lớp quản trị tập trung (như Unity Catalog hoặc AWS Lake Formation) để áp dụng các chính sách phân quyền ở mức độ bảng, hàng và cột.
INDA Academy tự hào là đơn vị tiên phong trong việc đào tạo phân tích dữ liệu và AI chuyên sâu, đặc biệt cho khối ngành Ngân hàng – Tài chính – Bảo hiểm tại Việt Nam. Sau hơn 12 năm “thực chiến” cùng những dòng chảy dữ liệu khổng lồ, chúng tôi đã xây dựng nên một hệ sinh thái đào tạo toàn diện, giúp hàng nghìn học viên chuyển mình từ người mới bắt đầu trở thành những chuyên gia lành nghề, sẵn sàng đáp ứng tiêu chuẩn khắt khe của các doanh nghiệp lớn.
Điểm khác biệt lớn nhất tại INDA chính là triết lý đào tạo dựa trên các dự án thực tế (Project-based) và lộ trình cá nhân hóa nhờ ứng dụng AI. Chúng tôi không chỉ dạy bạn cách sử dụng công cụ, mà còn truyền tải tư duy khai phá giá trị từ dữ liệu để đưa ra quyết định kinh doanh chính xác.
Tìm hiểu thêm về các khóa học TẠI ĐÂY:
Lộ trình đào tạo Data Engineer
Lộ trình đào tạo Data Analyst
Lộ trình đào tạo Tester
Khóa học Data Engineer nâng cao – Thực chiến 5 dự án doanh nghiệp
Khóa học Data Analyst nâng cao – Thực chiến 5 dự án doanh nghiệp
Bài viết liên quan:
 Lakehouse Query Engine: “Bộ não” quyết định hiệu năng hệ thống dữ liệu 2026
Lakehouse Query Engine: “Bộ não” quyết định hiệu năng hệ thống dữ liệu 2026
 Delta Lake vs Iceberg vs Hudi: So sánh chi tiết Table Format cho Data Lakehouse 2026
Delta Lake vs Iceberg vs Hudi: So sánh chi tiết Table Format cho Data Lakehouse 2026
 Data Lake vs Data Warehouse vs Lakehouse: Phân tích chiến lược kiến trúc dữ liệu toàn diện 2026
Data Lake vs Data Warehouse vs Lakehouse: Phân tích chiến lược kiến trúc dữ liệu toàn diện 2026
 Data Lakehouse vs Data Warehouse: Kiến trúc nào là “xương sống” cho doanh nghiệp 2026?
Data Lakehouse vs Data Warehouse: Kiến trúc nào là “xương sống” cho doanh nghiệp 2026?
 Data Lakehouse là gì? Kiến trúc, lợi ích và khi nào doanh nghiệp nên áp dụng (Cập nhật 2026)
Data Lakehouse là gì? Kiến trúc, lợi ích và khi nào doanh nghiệp nên áp dụng (Cập nhật 2026)
 Data Warehouse – Thiết kế logic và vật lý của kho dữ liệu
Data Warehouse – Thiết kế logic và vật lý của kho dữ liệu