

Trong thế giới của trí tuệ nhân tạo, các mô hình ngôn ngữ lớn (LLM) như GPT-4 hay Claude giống như những vị học giả uyên bác đã đọc hết hàng tỷ cuốn sách. Tuy nhiên, ngay cả vị học giả thông thái nhất cũng có một điểm yếu chí mạng: Họ chỉ nhớ những gì đã đọc trong quá trình huấn luyện và hoàn toàn “mù tịt” về những gì đang xảy ra hôm nay, hoặc những bí mật riêng tư trong doanh nghiệp của bạn.
Để khắc phục kẽ hở này, một kỹ thuật mang tên RAG (Retrieval-Augmented Generation) đã ra đời. RAG không chỉ là một thuật ngữ kỹ thuật; nó chính là “cây cầu” nối liền trí thông minh thiên bẩm của AI với kho tàng tri thức khổng lồ, cập nhật liên tục của nhân loại.
Mục lục
1. RAG là gì? Sự kết hợp giữa “Truy xuất” và “Sáng tạo”
Retrieval-Augmented Generation (RAG), được giới thiệu lần đầu bởi các nhà nghiên cứu tại Facebook AI Research (nay là Meta AI) vào năm 2020, là một kiến trúc giúp tối ưu hóa đầu ra của LLM bằng cách tham chiếu đến một cơ sở tri thức đáng tin cậy nằm ngoài dữ liệu huấn luyện của nó.
Hãy tưởng tượng bạn đang đi thi:
- Nếu không có RAG: Bạn phải dùng trí nhớ thuần túy. Nếu câu hỏi rơi vào kiến thức bạn chưa học, bạn sẽ bắt đầu “đoán mò” (hiện tượng này trong AI gọi là Hallucination – Ảo giác).
- Nếu có RAG: Bạn được phép mang theo một cuốn sách tham khảo vào phòng thi. Khi gặp câu hỏi, bạn mở sách ra, tìm đoạn văn liên quan nhất và dùng khả năng ngôn ngữ của mình để tổng hợp câu trả lời.
Theo định nghĩa từ IBM, RAG kết hợp hai mô hình: mô hình truy xuất (để tìm dữ liệu) và mô hình tạo (để viết câu trả lời).
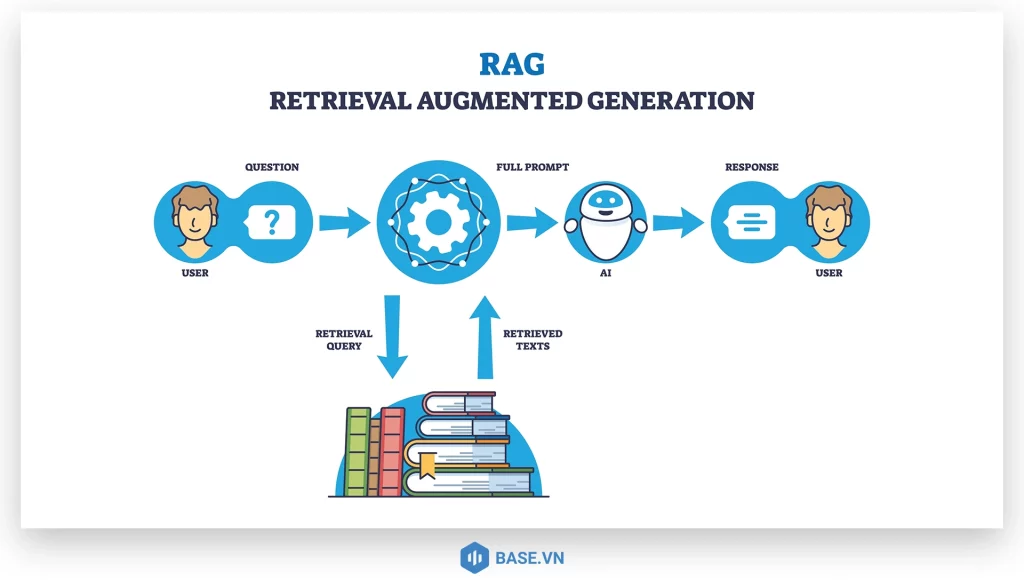
2. Vì sao hệ thống AI hiện đại bắt buộc phải có RAG?
Nhiều người lầm tưởng rằng chỉ cần một model AI mạnh là đủ. Nhưng thực tế, ngay cả những model hàng đầu cũng đối mặt với ba rào cản lớn mà chỉ RAG mới có thể giải quyết triệt để:
Vượt qua giới hạn thời gian (Knowledge Cutoff)
Mọi LLM đều có một điểm dừng kiến thức. Nếu một model kết thúc huấn luyện vào năm 2023, nó sẽ không biết gì về các sự kiện năm 2024. Thay vì tiêu tốn hàng triệu USD để huấn luyện lại (retrain) mô hình, RAG cho phép bạn chỉ cần cập nhật kho dữ liệu bên ngoài. Như NVIDIA đã nhận định, RAG giúp AI luôn được cập nhật thông tin mới nhất mà không cần tốn kém chi phí tính toán cho việc huấn luyện lại.
Kiểm soát tính chính xác và minh bạch
AI có xu hướng trả lời rất tự tin ngay cả khi nó sai. RAG buộc AI phải “nói có sách, mách có chứng”. Một hệ thống RAG tốt có thể trích dẫn chính xác nguồn tài liệu (URL, tên file, số trang) mà nó đã dùng để tạo câu trả lời, giúp người dùng dễ dàng kiểm chứng lại thông tin.
Bảo mật dữ liệu doanh nghiệp
Doanh nghiệp không thể đưa toàn bộ bí mật kinh doanh lên mạng để huấn luyện mô hình công cộng. Với RAG, dữ liệu của bạn nằm an toàn trong kho lưu trữ riêng (thường là Vector Database). AI chỉ truy cập tạm thời vào các mảnh thông tin cần thiết để giải quyết câu hỏi hiện tại, đảm bảo tính riêng tư theo chuẩn AWS.
3. RAG hoạt động ra sao? Quy trình 6 bước chi tiết
Để một hệ thống RAG vận hành trơn tru, dữ liệu phải trải qua một hành trình từ “thô” sang “số” cực kỳ tinh vi.
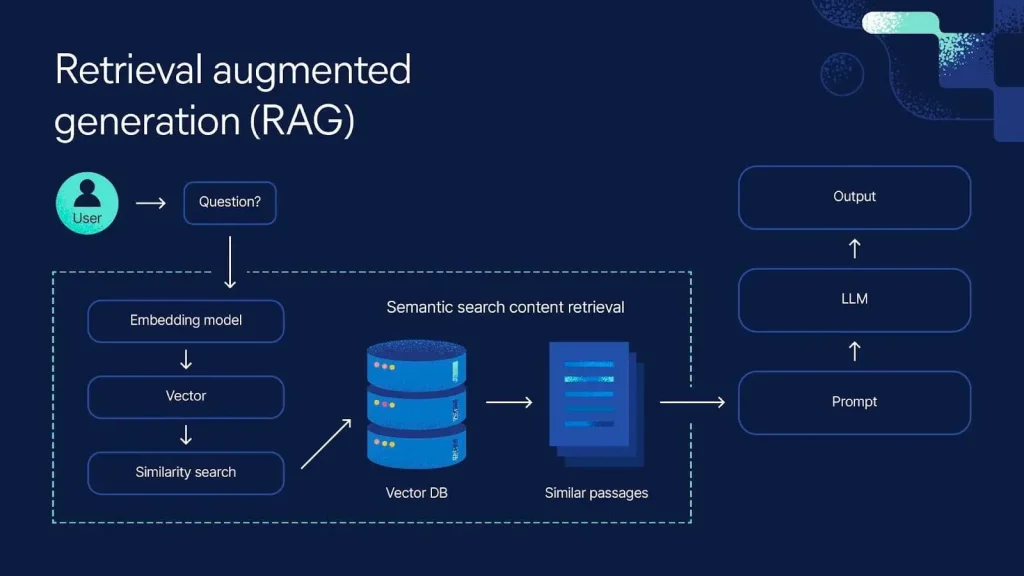
Bước 1: Thu thập và Chia nhỏ dữ liệu (Chunking)
AI không thể đọc một lúc 1.000 trang tài liệu trong vài giây. Vì thế, bước đầu tiên là chia nhỏ tài liệu thành các đoạn văn ngắn (gọi là Chunks). Việc chia nhỏ này phải đảm bảo tính toàn vẹn của ngữ cảnh — không được cắt đôi một câu nói quan trọng.
Bước 2: Chuyển hóa thành Embedding (Vector hóa)
Mỗi đoạn văn sẽ được đưa qua một mô hình Embedding (như các mô hình của OpenAI hoặc Hugging Face) để chuyển thành các chuỗi số gọi là Vector. Đây là bước then chốt giúp máy tính hiểu được “ý nghĩa” thay vì chỉ là “mặt chữ”.
Bước 3: Lưu trữ vào Vector Database
Các vector này được lưu trữ vào các cơ sở dữ liệu chuyên dụng như Pinecone, Milvus hay Weaviate. Tại đây, các thông tin có ý nghĩa giống nhau sẽ nằm gần nhau trong không gian toán học đa chiều.
Bước 4: Truy xuất (Retrieval)
Khi người dùng đặt câu hỏi, ví dụ: “Chính sách bảo hành sản phẩm X là gì?”, câu hỏi này cũng được chuyển thành Vector. Hệ thống sẽ thực hiện phép toán tìm kiếm các đoạn văn bản có tọa độ gần nhất với câu hỏi đó trong kho lưu trữ.
Bước 5: Tăng cường Prompt (Augmentation)
Đây là trái tim của RAG. Hệ thống tạo ra một câu lệnh (Prompt) mới cho AI bao gồm:
- Câu hỏi gốc của người dùng.
- Các đoạn văn bản liên quan nhất vừa tìm thấy (Context).
- Chỉ thị: “Chỉ được dùng thông tin được cung cấp để trả lời”.
Bước 6: Tạo câu trả lời (Generation)
LLM đọc “đề bài” mới này và viết ra câu trả lời cuối cùng. Kết quả là người dùng nhận được một thông tin cực kỳ chính xác và sát với thực tế dữ liệu của mình.
4. RAG và Fine-tuning: Khi nào dùng cái nào?
Trong giới AI, Fine-tuning (huấn luyện bổ sung) thường bị nhầm lẫn với RAG. Tuy nhiên, chúng phục vụ các mục đích khác nhau:
- Fine-tuning: Giống như việc bạn cho AI đi học một khóa đào tạo chuyên sâu để thay đổi phong cách nói chuyện hoặc học thuật ngữ chuyên ngành. Nó thay đổi bản thân “con người” AI.
- RAG: Giống như việc đưa cho AI một thư viện để tra cứu. Nó thay đổi “nguồn thông tin” mà AI có thể tiếp cận.
Đa số các chuyên gia từ Microsoft đều khuyên rằng: Hãy dùng RAG để cập nhật kiến thức và dùng Fine-tuning để điều chỉnh hành vi/phong cách của mô hình.
5. Những thách thức khi triển khai RAG thực tế
Dù mạnh mẽ, RAG vẫn có những “điểm mù” mà các kỹ sư cần lưu ý:
- Chất lượng truy xuất (Retrieval Quality): Nếu hệ thống tìm sai tài liệu, AI chắc chắn sẽ trả lời sai.
- Giới hạn ngữ cảnh (Context Window): Mỗi mô hình AI chỉ có thể đọc một lượng từ nhất định trong một lần. Nếu bạn nhồi nhét quá nhiều tài liệu tìm được vào Prompt, AI sẽ bị quá tải.
- Độ trễ hệ thống: Quy trình tìm kiếm rồi mới trả lời sẽ mất thêm một khoảng thời gian (latencies) so với việc AI trả lời trực tiếp.
6. Kết luận
RAG không chỉ là một giải pháp kỹ thuật, nó là tư duy mới về cách chúng ta sử dụng AI: Không tin tưởng tuyệt đối vào trí nhớ của máy tính, mà hãy cung cấp cho nó những nguồn sự thật đáng tin cậy.
Với RAG, doanh nghiệp có thể biến những khối dữ liệu “chết” trong máy chủ thành những kiến thức sống động, giúp hỗ trợ khách hàng và tối ưu hóa vận hành một cách chưa từng có.
INDA Academy tự hào là đơn vị tiên phong trong việc đào tạo phân tích dữ liệu và AI chuyên sâu, đặc biệt cho khối ngành Ngân hàng – Tài chính – Bảo hiểm tại Việt Nam. Sau hơn 12 năm “thực chiến” cùng những dòng chảy dữ liệu khổng lồ, chúng tôi đã xây dựng nên một hệ sinh thái đào tạo toàn diện, giúp hàng nghìn học viên chuyển mình từ người mới bắt đầu trở thành những chuyên gia lành nghề, sẵn sàng đáp ứng tiêu chuẩn khắt khe của các doanh nghiệp lớn.
Điểm khác biệt lớn nhất tại INDA chính là triết lý đào tạo dựa trên các dự án thực tế (Project-based) và lộ trình cá nhân hóa nhờ ứng dụng AI. Chúng tôi không chỉ dạy bạn cách sử dụng công cụ, mà còn truyền tải tư duy khai phá giá trị từ dữ liệu để đưa ra quyết định kinh doanh chính xác.
Tìm hiểu thêm về các khóa học TẠI ĐÂY:
Lộ trình đào tạo Data Engineer
Lộ trình đào tạo Data Analyst
Lộ trình đào tạo Tester
Khóa học Data Engineer nâng cao – Thực chiến 5 dự án doanh nghiệp
Khóa học Data Analyst nâng cao – Thực chiến 5 dự án doanh nghiệp

