

Trong thế giới công nghệ, người ta thường ca ngợi sức mạnh của các mô hình ngôn ngữ lớn hay khả năng nhận diện hình ảnh siêu việt. Tuy nhiên, nếu ví mô hình AI là một thực thể thông minh, thì dữ liệu chính là nguồn thức ăn, và AI Pipeline chính là hệ tiêu hóa giúp chuyển hóa nguồn thức ăn thô thành năng lượng và trí tuệ.
Nhiều dự án AI thất bại không phải vì thuật toán yếu, mà vì họ thiếu một “đường ống” dẫn dữ liệu đủ tốt. Thực tế, mô hình (model) chỉ chiếm một phần nhỏ trong cấu trúc hệ thống. Phần lớn nguồn lực của các kỹ sư hiện nay tập trung vào việc xây dựng AI Pipeline – quy trình tự động hóa dòng chảy dữ liệu từ lúc thu thập cho đến khi trả về kết quả dự đoán cho người dùng.
Mục lục
AI Pipeline là gì?
Hiểu một cách đơn giản nhất, AI Pipeline là chuỗi các bước xử lý dữ liệu khép kín và tự động. Thay vì các kỹ sư phải nạp dữ liệu, làm sạch và chạy mô hình một cách thủ công, Pipeline kết nối tất cả các giai đoạn này thành một dòng chảy liền mạch.
Mục tiêu cốt lõi của Pipeline là biến dữ liệu thô (raw data) – vốn thường lộn xộn và không có cấu trúc – thành các tập dữ liệu “sạch” mà máy tính có thể học được. Từ đó, hệ thống không chỉ đưa ra dự đoán một lần mà có thể liên tục cập nhật, tự học hỏi và cải thiện độ chính xác theo thời gian nhờ vào tính chất lặp lại của quy trình.
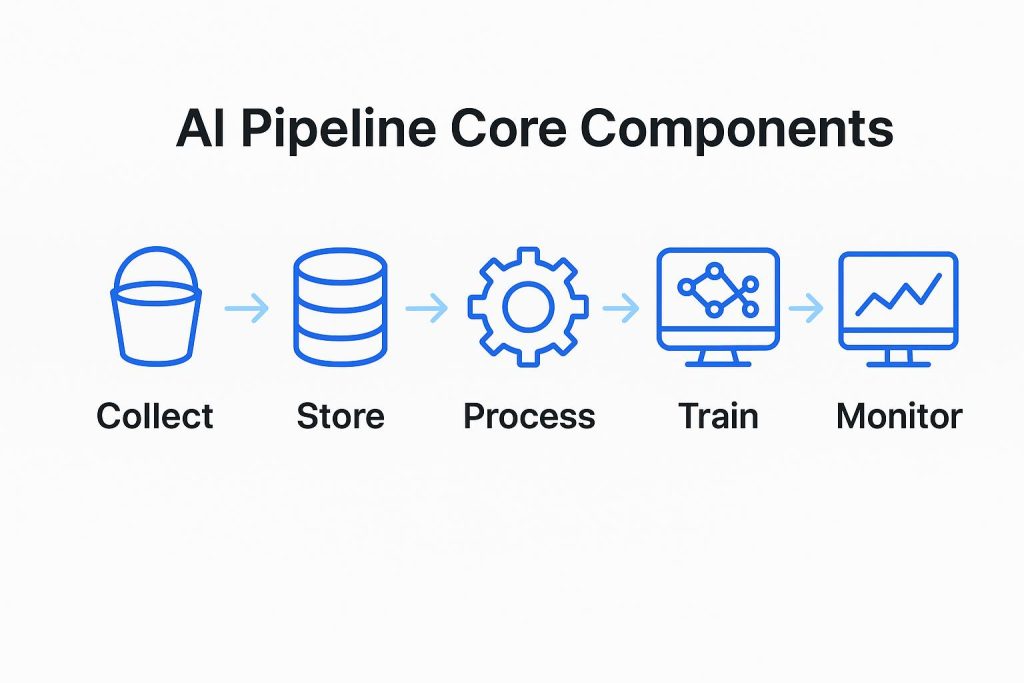
Tại sao AI Pipeline là “xương sống” của mọi hệ thống hiện đại?
Trong một hệ thống AI nhỏ lẻ, bạn có thể xử lý dữ liệu bằng tay. Nhưng khi hệ thống phục vụ hàng triệu người dùng, AI Pipeline trở thành yếu tố sống còn vì ba lý do lớn sau đây:
Đảm bảo chất lượng dữ liệu đồng nhất: Nguyên tắc vàng trong AI là “Garbage In, Garbage Out” (Dữ liệu rác thì kết quả cũng là rác). Pipeline đóng vai trò như một bộ lọc kiểm soát chất lượng, giúp loại bỏ các sai số, dữ liệu trùng lặp hoặc định dạng lỗi trước khi chúng kịp tiếp cận mô hình. Điều này giúp mô hình luôn hoạt động dựa trên những thông tin chuẩn xác nhất.
Tối ưu hóa khả năng mở rộng (Scalability): Một Pipeline được thiết kế tốt cho phép doanh nghiệp xử lý lượng dữ liệu khổng lồ trên các nền tảng đám mây mà không cần tăng nhân sự. Khả năng tự động hóa giúp hệ thống vận hành 24/7, từ việc tiếp nhận dữ liệu mới đến việc cập nhật mô hình mà không có độ trễ lớn.
Tính bền vững và khả năng tái sử dụng: Thay vì xây dựng quy trình riêng cho từng dự án, các thành phần trong một AI Pipeline có thể được tái cấu trúc để sử dụng cho nhiều mục đích khác nhau. Ví dụ, bước làm sạch văn bản cho một chatbot chăm sóc khách hàng có thể được dùng lại cho một hệ thống phân tích cảm xúc người dùng trên mạng xã hội.
Hành trình “biến hình” của dữ liệu qua các bước chính
Để hiểu cách một AI Pipeline hoạt động, hãy cùng theo chân một đơn vị dữ liệu từ khi nó còn là những con số thô cho đến khi trở thành một dự đoán thông minh.
1. Thu thập và nạp dữ liệu (Data Ingestion)
Mọi hành trình đều bắt đầu từ nguồn. Dữ liệu có thể đến từ các cơ sở dữ liệu nội bộ, các cảm biến IoT, tệp tin log từ website hoặc thông qua các API bên thứ ba. Ở giai đoạn này, Pipeline phải đối mặt với thách thức về tốc độ và định dạng. Tùy vào yêu cầu, hệ thống sẽ chọn xử lý theo lô (Batch) – tức là gom dữ liệu lại xử lý một lần vào cuối ngày, hoặc xử lý dòng (Streaming) – tức là dữ liệu được đẩy đi ngay khi nó vừa xuất hiện.
2. Tiền xử lý và làm sạch (Data Processing)
Dữ liệu thô thường rất “ồn”. Nó có thể chứa các giá trị trống, định dạng ngày tháng không đồng nhất hoặc các ký tự lỗi. Bước này giống như việc sàng lọc quặng; Pipeline sẽ thực hiện các thao tác chuẩn hóa định dạng, xử lý các giá trị thiếu bằng thuật toán và loại bỏ những dữ liệu không liên quan để tạo ra một bộ dữ liệu tinh khiết hơn.
3. Kỹ thuật đặc trưng (Feature Engineering)
Đây là giai đoạn quan trọng nhất nhưng cũng khó nhất. Dữ liệu sau khi làm sạch vẫn chưa chắc đã giúp ích cho mô hình. Các kỹ sư cần trích xuất các “đặc trưng” (features) quan trọng nhất. Ví dụ, thay vì nạp vào máy tính cả một đoạn lịch sử mua sắm dài dằng dặc, Pipeline sẽ tính toán và trích xuất ra một con số duy nhất là “Tổng chi tiêu trong 30 ngày gần nhất”. Con số này giúp mô hình học nhanh và chính xác hơn nhiều so với dữ liệu thô.
4. Huấn luyện và Đánh giá mô hình
Khi dữ liệu đã sẵn sàng, nó được đưa vào “lò luyện” thuật toán. Tại đây, máy tính sẽ tìm kiếm các quy luật ẩn sâu trong dữ liệu. Sau khi huấn luyện, Pipeline không lập tức đưa mô hình vào sử dụng mà phải trải qua bước kiểm định gắt gao. Hệ thống sẽ so sánh kết quả dự đoán của mô hình với thực tế để tính toán các chỉ số như độ chính xác (Accuracy) hay sai số (RMSE). Nếu kết quả không đạt yêu cầu, Pipeline có thể tự động điều chỉnh tham số và huấn luyện lại.
5. Triển khai và Giám sát (Deployment & Monitoring)
Khi mô hình đã vượt qua bài kiểm tra, nó sẽ được đưa lên môi trường thực tế để phục vụ người dùng. Tuy nhiên, công việc của Pipeline chưa dừng lại ở đó. Môi trường thực tế luôn biến động; sở thích của người dùng thay đổi, xu hướng thị trường dịch chuyển dẫn đến hiện tượng “trôi dữ liệu” (Data Drift). Pipeline phải liên tục giám sát hiệu suất và kích hoạt quy trình huấn luyện lại (Retraining) ngay khi phát hiện mô hình bắt đầu kém hiệu quả.
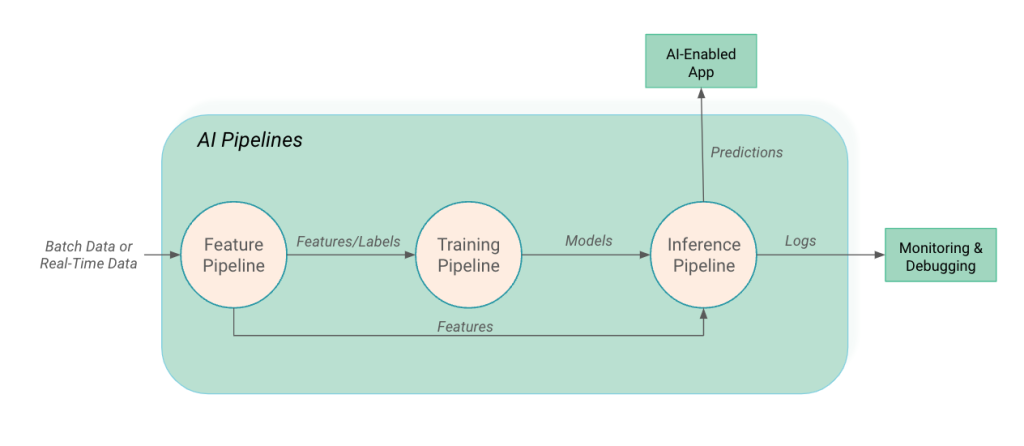
Sự khác biệt giữa AI Pipeline và ML Pipeline
Dù thường được dùng thay thế cho nhau, nhưng thực chất AI Pipeline có phạm vi rộng lớn hơn. Nếu như ML Pipeline tập trung chủ yếu vào vòng đời của mô hình (huấn luyện, đánh giá, tối ưu thuật toán), thì AI Pipeline bao quát toàn bộ hệ thống bao gồm cả hạ tầng dữ liệu, tích hợp ứng dụng và phản hồi người dùng. AI Pipeline mang tính chất của một giải pháp phần mềm hoàn chỉnh, đảm bảo rằng trí tuệ nhân tạo thực sự tạo ra giá trị trong thực tế chứ không chỉ nằm trong phòng thí nghiệm.
Những công cụ hỗ trợ xây dựng Pipeline hiệu quả
Hiện nay, các doanh nghiệp không cần phải xây dựng Pipeline từ con số 0. Có rất nhiều công cụ mạnh mẽ hỗ trợ từng công đoạn:
- Apache Airflow: Công cụ điều phối dòng việc (orchestration) phổ biến nhất, giúp quản lý lịch trình và sự phụ thuộc giữa các bước.
- MLflow: Tập trung vào việc quản lý các phiên bản mô hình và lưu trữ kết quả thực nghiệm.
- Kubeflow: Giải pháp tối ưu cho những hệ thống chạy trên nền tảng đám mây, giúp mở rộng quy mô một cách linh hoạt.
Lời kết
Xây dựng một AI Pipeline không chỉ là công việc của các lập trình viên, mà là sự kết hợp giữa tư duy về dữ liệu, thuật toán và vận hành hệ thống. Một đường ống dẫn dữ liệu vững chắc sẽ giúp doanh nghiệp chuyển mình từ việc thử nghiệm AI sang việc triển khai AI ở quy mô công nghiệp, đảm bảo tính ổn định và chính xác trong dài hạn.
Khi kiến trúc dữ liệu ngày càng phức tạp với sự xuất hiện của các công nghệ như RAG hay LLM, vai trò của AI Pipeline sẽ ngày càng quan trọng hơn, trở thành yếu tố then chốt quyết định sự thành bại của mọi chiến lược trí tuệ nhân tạo.
INDA Academy tự hào là đơn vị tiên phong trong việc đào tạo phân tích dữ liệu và AI chuyên sâu, đặc biệt cho khối ngành Ngân hàng – Tài chính – Bảo hiểm tại Việt Nam. Sau hơn 12 năm “thực chiến” cùng những dòng chảy dữ liệu khổng lồ, chúng tôi đã xây dựng nên một hệ sinh thái đào tạo toàn diện, giúp hàng nghìn học viên chuyển mình từ người mới bắt đầu trở thành những chuyên gia lành nghề, sẵn sàng đáp ứng tiêu chuẩn khắt khe của các doanh nghiệp lớn.
Điểm khác biệt lớn nhất tại INDA chính là triết lý đào tạo dựa trên các dự án thực tế (Project-based) và lộ trình cá nhân hóa nhờ ứng dụng AI. Chúng tôi không chỉ dạy bạn cách sử dụng công cụ, mà còn truyền tải tư duy khai phá giá trị từ dữ liệu để đưa ra quyết định kinh doanh chính xác.
Tìm hiểu thêm về các khóa học TẠI ĐÂY:
Lộ trình đào tạo Data Engineer
Lộ trình đào tạo Data Analyst
Lộ trình đào tạo Tester
Khóa học Data Engineer nâng cao – Thực chiến 5 dự án doanh nghiệp
Khóa học Data Analyst nâng cao – Thực chiến 5 dự án doanh nghiệp

