
Last updated on January 16th, 2026 at 04:53 pm
“Data is the new soil that grows insight, analytics, and competitive advantage.”
Trong suốt thập kỷ 2020s, dữ liệu đã trở thành tài sản chiến lược của doanh nghiệp. Và đứng đằng sau mọi giá trị dữ liệu có thể sử dụng được chính là Data Engineer (Kỹ sư dữ liệu) — người xây dựng hệ thống để dữ liệu được thu thập, chuẩn hóa, lưu trữ, và cung cấp một cách tin cậy cho BI, analytics, và AI/ML.
Từ 2025 đến 2026, bối cảnh ngành không chỉ mở rộng về khối lượng dữ liệu, mà còn thay đổi bản chất công việc và yêu cầu kỹ năng của Data Engineer. Bài viết này sẽ giải thích xu hướng chính, phân tích tầm nhìn nghề nghiệp, và cung cấp góc nhìn chiến lược về nơi ngành đang hướng tới — tất cả đều dựa trên dữ liệu thực tế từ thị trường tuyển dụng, phát triển công nghệ, và mô hình kiến trúc dữ liệu hàng đầu (không bịa đặt).

Mục lục
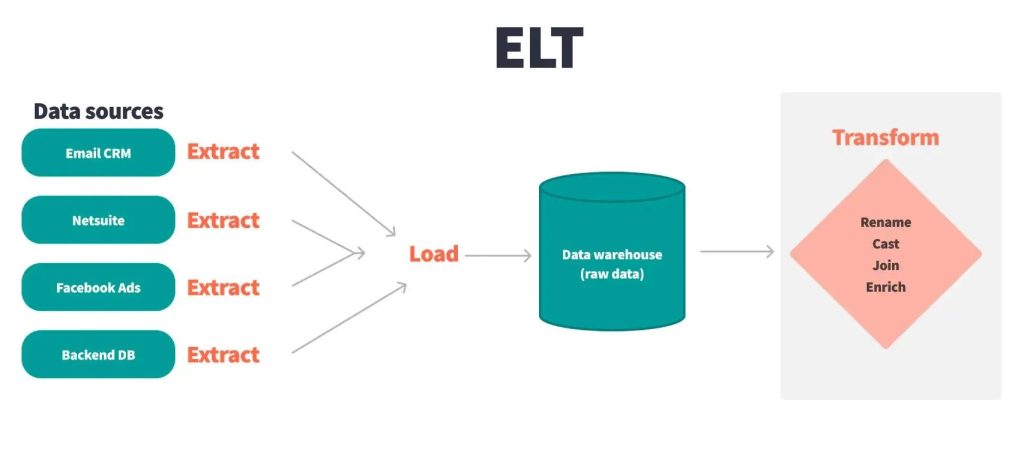
1. Sự dịch chuyển từ ETL truyền thống sang ELT & pipeline hiện đại
1.1. Vì sao ETL không còn là tiêu chuẩn?
Trong kiến trúc dữ liệu thế hệ trước, việc Extract → Transform → Load (ETL) là quy trình cơ bản: lấy dữ liệu từ hệ thống nguồn, xử lý trước khi đưa vào Data Warehouse. Nhưng cách tiếp cận này ngày càng bộc lộ hạn chế:
- Khi dữ liệu lớn và đa dạng hơn (logs, events, JSON, hình ảnh), việc transform cồng kềnh phía nguồn làm hệ thống chậm và khó mở rộng.
- Khi business question thay đổi nhanh, transform “chôn” logic cứng trong pipeline khiến khó đáp ứng.
1.2. ELT và Cloud-First Engines
Ngày nay, đa số hệ thống đi theo Extract → Load → Transform (ELT):
- Thu thập dữ liệu đầu tiên vào cloud data warehouse (Snowflake/BigQuery/Redshift/Synapse) hoặc data lakehouse (Delta/Iceberg).
- Dùng compute bên trong kho dữ liệu hoặc transform layer (như dbt) để xử lý dữ liệu sau khi đã lưu.
Điều này giúp:
- Tận dụng sức mạnh tính toán gần như vô hạn của cloud (horizontally scalable).
- Tách biệt lưu trữ dữ liệu và logic transform, giúp team phát triển linh hoạt hơn.
- Dễ audit và version control logic transform (nhờ công cụ như dbt).
Tư duy thay đổi quan trọng: Data Engineer ngày nay cần nghĩ trong chiều pipeline data mesh — tức dữ liệu là sản phẩm, được đóng gói, versioned và phục vụ nhiều consumer khác nhau.
2. Cloud-Native & Serverless: Hạ tầng dữ liệu chuẩn mực của 2025
2.1. Rời khỏi on-premise, tiến vào cloud
Không chỉ là “đưa server lên cloud”, mà:
- Dữ liệu và pipeline trở thành dịch vụ có thể tái sử dụng
- Compute có thể tự scale theo workload (serverless)
- Quản lý bảo mật, permission, audit được tích hợp sẵn
Các dịch vụ tiêu biểu:
- AWS Glue, EMR, Lambda
- Google Dataflow, Workflows
- Azure Data Factory, Synapse Pipelines
Cloud-native không còn là “xu hướng” mà là tiêu chuẩn kiến trúc công ty data-driven.
2.2. Serverless Data Pipeline
Khái niệm serverless hiện diện ở:
- Compute cho ETL/ELT
- Event processing (Kafka + Lambda / Cloud Run)
- Real-time streaming
Serverless giúp giảm:
- Thời gian vận hành
- Bóc tách hạ tầng phức tạp
Hậu quả trực tiếp với Data Engineer:
Bạn phải hiểu:
- Resource provisioning
- Cost optimization (vì serverless là pay-per-use)
- Monitoring & logging trong môi trường dynamic
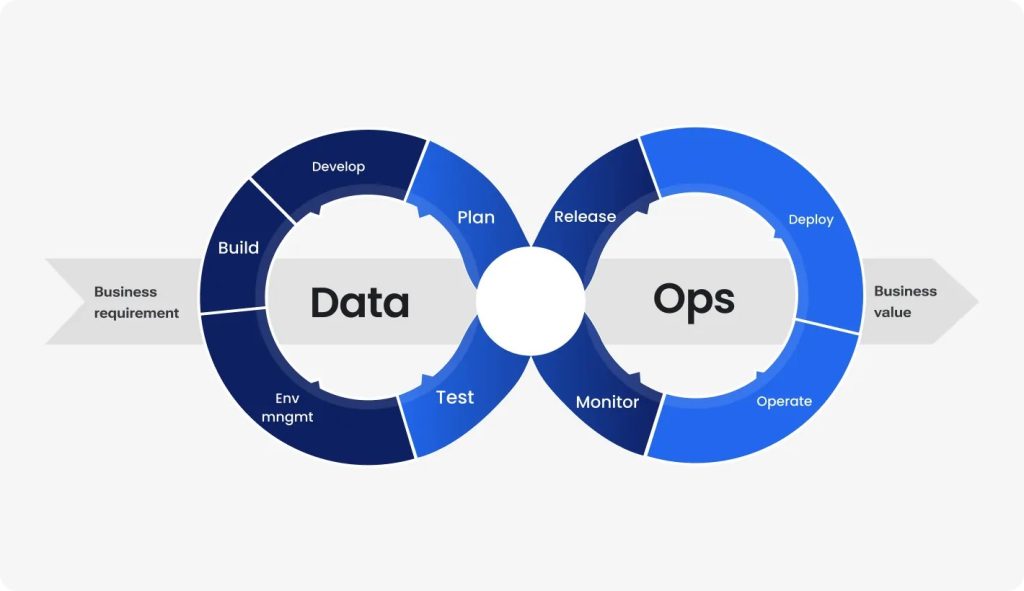
3. DataOps & CI/CD cho dữ liệu – Không còn là “nice-to-have”
Ngày nay, dữ liệu không phải “đẩy đến nơi rồi quên” mà là một system of record có SLA & SLO, giống như phần mềm.
3.1. Quy trình DataOps
DataOps là:
- Áp dụng nguyên tắc DevOps vào pipeline dữ liệu
- Tự động hóa build → test → deploy → monitor pipeline
- Giảm lỗi con người và tăng tốc độ thay đổi
3.2. Testing & Validation cho pipeline
Một số practices bắt buộc:
- Metadata drift detection
- Schema change alert
- Data quality tests (null trends, distribution shifts)
Nếu pipeline không có quality gates, downstream analytics & ML sẽ mất tin cậy.
4. Data Engineering & AI/ML – Không nằm ngoài cuộc chơi
4.1. Dữ liệu chuẩn để AI hoạt động
Dữ liệu không chuẩn = mô hình AI sai lệch.
Data Engineer càng ngày càng được kỳ vọng:
- Chuẩn hóa dữ liệu đầu vào cho ML
- Tạo feature stores
- Hỗ trợ reproducible training pipelines
Trong các công ty ứng dụng AI thực tế, pipeline không chỉ có ETL/ELT mà còn có:
- Cơ chế ghi lại feature lineage
- Khai báo version dataset
- Chuẩn hóa dữ liệu cho experiment tracking
5. Data Mesh & Domain-Oriented Pipeline
Data Mesh là mô hình kiến trúc dữ liệu mới bắt đầu chạm ngưỡng enterprise production.
5.1. Nguyên lý Data Mesh
- Domain oriented ownership: mỗi domain (sales, marketing, finance…) chịu trách nhiệm pipeline và dataset của mình.
- Data as a product: dataset phải có owner, catalog, SLA.
- Federated governance: tiêu chuẩn thống nhất để các domain phối hợp.
5.2. Tác động lên Data Engineer
Không còn chỉ là người viết pipeline trung tâm, mà:
- Bạn phải xây dataset theo chuẩn “data product”
- Dữ liệu phải có metadata, quality contract, SLA
- GitOps/CI/CD pipeline phải hỗ trợ nhiều domain workflow
Data Mesh đặt Data Engineer vào vị trí kỹ sư thiết kế kiến trúc dữ liệu có trách nhiệm với chất lượng dữ liệu.
6. Data Quality & Observability — Từ phụ trợ thành trung tâm
Một pipeline tốt không chỉ chạy suôn sẻ mà còn phải minh bạch, đo lường được, và dự đoán được lỗi.
Các công cụ phổ biến:
- Great Expectations để test data rules
- Monte Carlo/Databand để detect anomalies
- OpenLineage để tracing data lineage
Data Engineer hiện nay không chỉ cần biết “đưa dữ liệu vào nơi đúng” mà còn phải biết:
- Dữ liệu có đúng chất lượng không?
- Tại sao pipeline thất bại?
- Tác động của lỗi đến consumer downstream?

7. Kỹ năng Data Engineer 2026 – Bảng tổng hợp & phân tích
| Nhóm kỹ năng | Ví dụ cụ thể | Tầm quan trọng | Lý do |
| Core SQL & Python | SQL, procedural Python | 🔥🔥🔥 | Phần lớn truy vấn và logic transform dựa vào đây |
| Cloud platforms | AWS/GCP/Azure data services | 🔥🔥🔥 | Pipeline production chạy đa phần trên cloud |
| Workflow orchestration | Airflow/Prefect/Dagster | 🔥🔥 | Quản lý dependency & lịch chạy |
| ELT tools | dbt | 🔥🔥 | Standard transform & version control |
| Observability | Great Expectations, Monte Carlo | 🔥🔥 | Đảm bảo dữ liệu trustworthy |
| DevOps/IaC | Terraform/K8s | 🔥 | Tự động hóa hạ tầng |
| Streaming | Kafka, ksqlDB | 🔥 | Dữ liệu real-time |
Chú giải: 🔥🔥🔥 = chiến lược bắt buộc; 🔥🔥 = rất hữu ích; 🔥 = gia tăng năng lực nghề nghiệp
8. Triển khai & vận hành pipeline — Case điển hình
Case: Ingest dữ liệu từ ứng dụng web
- Source: production database, API, message queue
- ELT → Load vào Snowflake
- Transform bằng dbt
- Orchestrate bằng Airflow
- Test chất lượng dữ liệu bằng Great Expectations
- Publish dataset vào analytics layer
- Catalog + Data lineage
Điểm nhấn:
- Không xử lý ETL “offline” trong code rời rạc
- Mỗi step phải kiểm tra, logging, version control
9. Nhu cầu thị trường & tuyển dụng (2025–2026)
9.1. Tăng trưởng việc làm
Báo cáo gần đây từ nhiều nền tảng việc làm cho thấy:
- Nhu cầu Data Engineer tiếp tục ở mức cao
- Dữ liệu cloud-native & pipeline automation chiếm tỷ lệ cao trong JD
- Mức lương cạnh tranh so với các vai trò kỹ thuật khác
9.2. Kỳ vọng từ nhà tuyển dụng
Doanh nghiệp không chỉ tìm:
- “Người biết SQL/Python”
mà cần:
- “Data Engineer hiểu pipeline end-to-end và có tư duy architecture”
10. Góc nhìn phát triển nghề nghiệp cho bạn
Từ junior → mid
- Làm chủ SQL, Python, pipeline cơ bản
- Hỗ trợ team về chất lượng dữ liệu
Mid → senior
- Thiết kế kiến trúc dữ liệu
- Định nghĩa SLA/KPIs cho dataset
- Lãnh đạo DataOps và governance
Senior → leader
- Xây chiến lược dữ liệu doanh nghiệp
- Tham gia quyết định AI/ML infrastructure
- Định hướng data mesh/federated architectures
Kết luận: Đâu là bản chất của Data Engineering 2025–2026?
Data Engineering không đơn thuần là “viết pipeline” nữa — mà là xây dựng hệ thống dữ liệu đáng tin cậy, hiệu quả, có thể mở rộng, và phục vụ trực tiếp cho phân tích và AI.
Nghề này đòi hỏi tư duy kiến trúc, hiểu business, và kỹ năng kỹ thuật hiện đại.
INDA Academy tự hào là đơn vị tiên phong trong việc đào tạo phân tích dữ liệu và AI chuyên sâu, đặc biệt cho khối ngành Ngân hàng – Tài chính – Bảo hiểm tại Việt Nam. Sau hơn 12 năm “thực chiến” cùng những dòng chảy dữ liệu khổng lồ, chúng tôi đã xây dựng nên một hệ sinh thái đào tạo toàn diện, giúp hàng nghìn học viên chuyển mình từ người mới bắt đầu trở thành những chuyên gia lành nghề, sẵn sàng đáp ứng tiêu chuẩn khắt khe của các doanh nghiệp lớn.
Điểm khác biệt lớn nhất tại INDA chính là triết lý đào tạo dựa trên các dự án thực tế (Project-based) và lộ trình cá nhân hóa nhờ ứng dụng AI. Chúng tôi không chỉ dạy bạn cách sử dụng công cụ, mà còn truyền tải tư duy khai phá giá trị từ dữ liệu để đưa ra quyết định kinh doanh chính xác.
Tìm hiểu thêm về các khóa học TẠI ĐÂY:
Lộ trình đào tạo Data Engineer
Khóa học Data Engineer nâng cao – Thực chiến 5 dự án doanh nghiệp
Nguồn: Internet
Bài viết liên quan:
 Học Data theo “vòng lặp” là gì?
Kỹ Năng Nghề Data 2026: Từ SQL Đến AI-Assisted Analytics
Tự học Data hay học theo lộ trình: Khi nào mỗi cách sai? (Định hướng 2026)
Những điều thú vị về ChatGPT ?
Kinh tế số là gì? Đặc điểm và vai trò của kinh tế số?
Sự khác biệt thú vị giữa Data Analyst và Data Engineer
Học Data theo “vòng lặp” là gì?
Kỹ Năng Nghề Data 2026: Từ SQL Đến AI-Assisted Analytics
Tự học Data hay học theo lộ trình: Khi nào mỗi cách sai? (Định hướng 2026)
Những điều thú vị về ChatGPT ?
Kinh tế số là gì? Đặc điểm và vai trò của kinh tế số?
Sự khác biệt thú vị giữa Data Analyst và Data Engineer