Last updated on January 21st, 2026 at 03:01 pm
Thế giới phân tích dữ liệu (data analytics) dựa vào các đường ống (pipeline) ETL và ELT để thu thập những thông tin chi tiết có ý nghĩa từ dữ liệu. Các kỹ sư dữ liệu và nhà phát triển ETL thường được yêu cầu xây dựng hàng chục đường ống phụ thuộc lẫn nhau như một phần của nền tảng dữ liệu của họ, tuy nhiên việc điều phối, quản lý và giám sát tất cả các đường ống này có thể là một thách thức lớn. Nhưng giờ đây, công việc này có thể trở nên dễ dàng hơn trong Cloud Composer bằng cách sử dụng một tập hợp các toán tử của Cloud Data Fusion.
Các toán tử mới của Cloud Data Fusion cho phép bạn dễ dàng quản lý các đường ống trong Cloud Composer mà không cần phải viết nhiều dòng lệnh. Giờ đây, bạn có thể triển khai, bắt đầu hoặc dừng các đường ống của mình bằng cách sử dụng các toán tử cùng một vài tham số. Điều này giúp bạn tiết kiệm thời gian nhưng vẫn đảm bảo độ chính xác và tính hiệu quả trong quy trình làm việc.

Mục lục
Quản lý đường ống dữ liệu của bạn
Data Fusion là dịch vụ tích hợp dữ liệu đám mây được quản lý hoàn toàn bởi Google Cloud và được xây dựng trên nền tảng mã nguồn mở CDAP, giúp người dùng xây dựng và quản lý các đường ống dữ liệu ETL và ELT thông quan một giao diện đồ họa trực quan. Bằng cách loại bỏ các rào cản mã hóa, các nhà phân tích dữ liệu và người dùng doanh nghiệp đều có thể tham gia cùng các nhà phát triển để quản lý dữ liệu của họ.
Quản lý tất cả các đường ống Data Fusion của bạn có thể là một thách thức. Lấy ví dụ, việc xác định cách thức và thời điểm kích hoạt các đường ống của bạn có thể không đơn giản như tưởng tượng. Trong một số trường hợp, bạn có thể muốn lập lịch chạy đường ống theo định kỳ, nhưng bạn sẽ nhanh chóng nhận ra rằng công việc này có sự phụ thuộc và các hệ thống, quy trình và đường ống khác.
Bạn có thể nhận thấy rằng bạn thường cần phải chờ đợi để chạy đường ống của mình cho đến khi một số điều kiện khác được thỏa mãn, chẳng hạn như nhận được thông điệp Pub/Sub, dữ liệu đến trong một bucket, hoặc trong một nhóm các đường ống mà đường ống này phụ thuộc vào dữ liệu đầu ra của các đường ống khác. Đó chính là khi Cloud Composer trở nên hữu ích.

Cloud Composer được xây dựng trên mã nguồn mở Apache Airflow, là dịch vụ điều phối được quản lý hoàn toàn bởi Google, cho phép người dùng quản lý các đường ống trong toàn bộ nền tảng dữ liệu của mình. Quy trình công việc của Cloud Composer được định cấu hình bằng cách xây dựng các đồ thị vòng có hướng (directed acyclic graph – DAG) bằng Python.
Trong khi DAG mô tả tập hợp các nhiệm vụ trong một quy trình công việc nhất định, thì chính các toán tử sẽ xác định những gì được hoàn thiện sau một tác vụ. Bạn có thể xem các toán tử như một mẫu và các toán tử Data Fusion mới này cho phép bạn dễ dàng triển khai, bắt đầu và dừng các đường ống ETL/ELT Data Fusion của mình đơn giản bằng cách cung cấp một vài tham số.
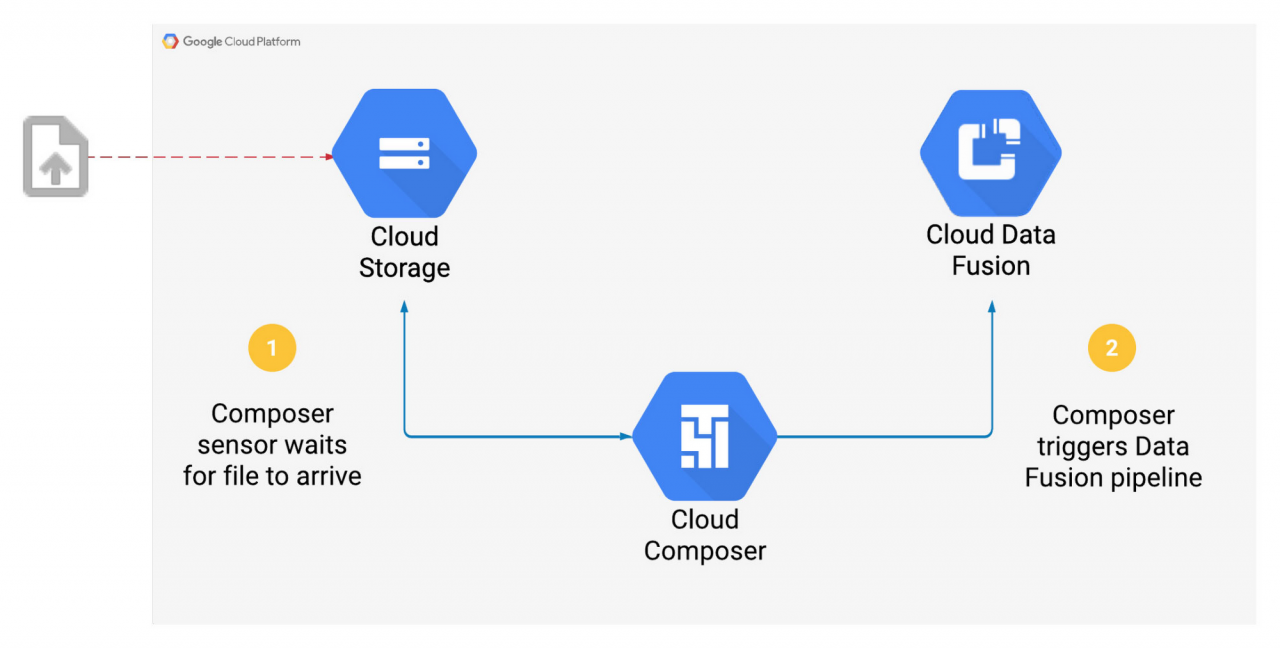
Xem xét một trường hợp cụ thể khi Composer kích hoạt đường dẫn Data Fusion đúng một lần khi có tập tin gửi đến trong Cloud Storage bucket:

Các bước làm trên được thực hiện như một chuỗi tác vụ trong Composer. Khi một toán tử được khởi tạo, nó sẽ trở thành tác vụ đơn (single task) trong quy trình làm việc, sau đó toán tử CloudDataFusionStartPipeline được sử dụng để bắt đầu Data Fusion pipeline.
Các toán tử này giúp đơn giản hóa DAG. Thay vì yêu cầu mã nguồn bằng ngôn ngữ Python để gọi API Data Fusion hoặc CDAP, Google Cloud cung cấp toán tử với những chi tiết về pipeline, làm giảm độ phức tạp và cải thiện độ tin cậy trong quy trình làm việc của Cloud Composer.
Điều phối các đường ống
Việc điều phối các đường ống với những toán tử này sẽ hoạt động như thế nào trong thực tế? Dưới đây là một ví dụ về cách bắt đầu một đường ống. các nguyên tắc ở đây có thể dễ dàng được mở rộng để bắt đầu, dừng và triển khai tất cả các đường ốn Data Fusion từ Cloud Composer.
Giả sử có một đối tượng Data Fusion với một đường dẫn đã được triển khai và sẵn sàng hoạt động và bạn cần tạo ra một quy trình Composer để kiểm tra sự tồn tại của một tập tin trong Cloud Storage bucket. Trong tương lai, Google Cloud sẽ thêm một trong các toán tử Data Fusion mới vào Cloud Composer DAG để có thể kích hoạt đường dẫn khi tập tin tới, chuyển vào một tên tập tin mới dưới dạng đối số (runtime argument).
Bây giờ, bạn có thể bắt đầu quy trình Cloud Composer và xem cách thức nó hoạt động.
1. Kiểm tra sự tồn tại của đối tượng trong Cloud Storage bucket
Thêm cảm biến GCSObjectExistenceSensor vào DAG. Sau khi bắt đầu tác vụ này, nó sẽ chờ đợi một đối tượng được tải lên Cloud Storage.
gcs_sensor_task = GCSObjectExistenceSensor(
task_id="gcs_object_sensor",
bucket='my_data_bucket',
object='my_data_01082020.csv',
dag=dag
)
2. Khởi động Data Fusion pipeline
Sử dụng toán tử CloudDataFusionStartPipelineOperator để bắt đầu một đường dẫn đã được triển khai trong Data Fusion. Tác vụ này được coi là hoàn thành sau khi đường dẫn được khởi động thành công trong Data Fusion.
start_pipeline_task = CloudDataFusionStartPipelineOperator(
task_id="start_cdf_pipeline",
location='us-west1',
pipeline_name =’demo_pipeline',
instance_name="demo_instance",
runtime_args={'input_dir':'my_data_01082020.csv'},
dag=dag
)
Bạn có thể xem thêm airflow documentation để hiểu thêm chi tiết về các tham số cần thiết trong toán tử này.
3. Sắp xếp thứ tự của luồng tác vụ bằng toán tử dịch chuyển bit
Khi DAG này được khởi động, tác vụ gcs_sensor sẽ thực thi đầu tiên. Chỉ khi tác vụ này hoàn tất thì tác vụ start_pipeline mới thực thi.
gcs_sensor_task >> start_pipeline_task
4. Tải DAG của bạn lên Cloud Composer DAG bucket và bắt đầu quy trình làm việc
Bây giờ khi DAG của bạn đã hoàn thiện, hãy nhấp vào liên kết tới thư mục DAGs từ trang đích của Cloud Composer và tải DAG của bạn lên.

Nhấp vào liên kết máy chủ Airflow web để khởi động giao diện người dùng Airflow và sau đó kích hoạt DAG bằng cách ấn nút Run.

5. Các tác vụ đã được thực thi
Khi tập tin được tải lên bucket nguồn của Google Cloud, Data Fusion sẽ được kích hoạt.

Vận hành và điều phối
Giờ đây, khi bạn không còn phải viết các dòng lệnh Python và duy trì các test gọi API Data Fusion, bạn sẽ có nhiều thời gian hơn để tập trung vào những phần khác trong quy trình làm việc của mình. Các toán tử Data Fusion này là một bổ sung tuyệt vời cho bộ các toán tử đã có sẵn trên Google Cloud. Cloud Composer và Airflow cũng hỗ trợ các toán tử cho BigQuery, Cloud Dataflow, Cloud Dataproc, Cloud Datastore và Cloud Pub/Sub, mang đến những tích hợp tuyệt vời hơn trên toàn bộ nền tảng dữ liệu của bạn.
Sử dụng các toán tử Data Fusion mới là một cách thức minh bạch để mang lại DAG đơn giản và dễ đọc trong Cloud Composer. Bằng cách giảm độ phức tạp và loại bỏ các rào cản mã hóa, việc quản lý đường ống ETL và ELT trở nên dễ tiếp cận hơn với các thành viên trong tổ chức của bạn. Bạn có thể xem thêm Airflow documentation để tìm hiểu kỹ hơn về các toán tử mới này.
Xu hướng và cập nhật mới về ETL với Cloud Data Fusion trên Google Cloud
Cloud Data Fusion trong bối cảnh ETL/ELT hiện đại
Trong những năm gần đây, Cloud Data Fusion không chỉ được nhìn nhận như một công cụ ETL truyền thống, mà dần trở thành nền tảng ETL/ELT cloud-native phục vụ cho các kiến trúc phân tích hiện đại trên Google Cloud. Việc chuyển dịch từ ETL sang ELT, nơi dữ liệu được load thẳng vào BigQuery trước khi transform, khiến Data Fusion ngày càng được sử dụng như một lớp orchestration và chuẩn hóa dữ liệu thay vì xử lý nặng ở tầng trung gian.
No-code / Low-code trở thành xu hướng chủ đạo
Một trong những thay đổi rõ rệt nhất là việc Cloud Data Fusion ngày càng được định vị là giải pháp no-code/low-code ETL. Giao diện kéo-thả cho phép xây dựng pipeline trực quan, giúp:
- Giảm phụ thuộc vào đội ngũ Data Engineer thuần code
- Mở rộng khả năng tham gia của Data Analyst, Analytics Engineer
- Rút ngắn thời gian triển khai pipeline từ PoC đến production
Điều này phản ánh xu hướng chung của thị trường: tăng tốc phát triển dữ liệu thay vì tối ưu code phức tạp.
Điều phối pipeline và tự động hóa theo chuẩn DataOps
Cloud Data Fusion ngày càng được sử dụng song song với Cloud Composer (Managed Airflow) để quản lý pipeline phức tạp. Thay vì chạy pipeline rời rạc, các doanh nghiệp bắt đầu xây dựng:
- Workflow ETL/ELT có phụ thuộc dữ liệu rõ ràng
- Pipeline kích hoạt theo lịch, theo sự kiện hoặc theo trạng thái hệ thống
- Quy trình CI/CD cho dữ liệu theo hướng DataOps
Xu hướng này cho thấy ETL không còn là tác vụ đơn lẻ mà trở thành một phần của hệ sinh thái vận hành dữ liệu tổng thể.
Bảo mật và kiến trúc hybrid được ưu tiên hơn
Khi dữ liệu ngày càng nhạy cảm, Cloud Data Fusion được mở rộng mạnh về mặt bảo mật và kết nối hạ tầng:
- Hỗ trợ Private IP để pipeline không cần truy cập Internet
- Tích hợp CMEK (Customer-Managed Encryption Keys) cho các tổ chức yêu cầu kiểm soát khóa mã hóa
- Kết hợp với VPC Service Controls nhằm hạn chế rò rỉ dữ liệu
Xu hướng này đặc biệt quan trọng với doanh nghiệp lớn, ngân hàng, fintech hoặc các tổ chức vận hành hybrid / multi-cloud architecture.
Mở rộng ETL sang near-real-time và streaming
Cloud Data Fusion không còn giới hạn trong batch ETL truyền thống. Việc kết hợp với các dịch vụ như Datastream, Pub/Sub hoặc BigQuery streaming ingestion giúp pipeline:
- Tiếp cận dữ liệu gần real-time
- Phục vụ dashboard, monitoring và phân tích hành vi nhanh hơn
- Giảm độ trễ giữa hệ thống vận hành và hệ thống phân tích
Đây là bước chuyển quan trọng khi nhu cầu phân tích không còn chỉ dừng ở báo cáo cuối ngày hay cuối tháng.
Data lineage và governance ngày càng được chú trọng
Một xu hướng nổi bật khác là quản trị dữ liệu (Data Governance). Cloud Data Fusion hỗ trợ theo dõi lineage dữ liệu từ nguồn đến đích, giúp:
- Hiểu rõ dữ liệu đến từ đâu, được transform như thế nào
- Phân tích tác động khi thay đổi schema hoặc logic xử lý
- Phục vụ audit, compliance và kiểm soát chất lượng dữ liệu
Trong bối cảnh dữ liệu ngày càng phức tạp, lineage không còn là “nice to have” mà trở thành yêu cầu bắt buộc.
Tự động hóa hạ tầng và quản lý bằng Infrastructure as Code
Ngoài giao diện trực quan, Cloud Data Fusion ngày càng được triển khai song song với các công cụ Infrastructure as Code (IaC) như Terraform. Điều này giúp:
- Chuẩn hóa môi trường dev / staging / production
- Giảm lỗi thủ công khi triển khai pipeline
- Phù hợp với mô hình DevOps – DataOps hiện đại
Xu hướng này cho thấy Data Fusion không chỉ dành cho người không biết code, mà vẫn đủ linh hoạt cho đội ngũ kỹ thuật chuyên sâu.
Vai trò của Cloud Data Fusion trong kiến trúc dữ liệu 2025–2026
Tổng thể lại, Cloud Data Fusion đang dịch chuyển từ một công cụ ETL thuần túy sang vai trò:
- Lớp kết nối và chuẩn hóa dữ liệu
- Công cụ orchestration pipeline trong hệ sinh thái Google Cloud
- Thành phần quan trọng trong chiến lược DataOps và governance
Với sự phát triển của BigQuery, Data Fusion không cạnh tranh trực tiếp với xử lý SQL hay transform in-warehouse, mà bổ sung và hoàn thiện kiến trúc dữ liệu end-to-end.
INDA Academy tự hào là đơn vị tiên phong trong việc đào tạo phân tích dữ liệu và AI chuyên sâu, đặc biệt cho khối ngành Ngân hàng – Tài chính – Bảo hiểm tại Việt Nam. Sau hơn 12 năm “thực chiến” cùng những dòng chảy dữ liệu khổng lồ, chúng tôi đã xây dựng nên một hệ sinh thái đào tạo toàn diện, giúp hàng nghìn học viên chuyển mình từ người mới bắt đầu trở thành những chuyên gia lành nghề, sẵn sàng đáp ứng tiêu chuẩn khắt khe của các doanh nghiệp lớn.
Điểm khác biệt lớn nhất tại INDA chính là triết lý đào tạo dựa trên các dự án thực tế (Project-based) và lộ trình cá nhân hóa nhờ ứng dụng AI. Chúng tôi không chỉ dạy bạn cách sử dụng công cụ, mà còn truyền tải tư duy khai phá giá trị từ dữ liệu để đưa ra quyết định kinh doanh chính xác.
Tìm hiểu thêm về các khóa học TẠI ĐÂY:
Môn học DWH/ETL
Lộ trình đào tạo Data Engineer
Lộ trình đào tạo Data Analyst
Lộ trình đào tạo Tester
Khóa học Data Engineer nâng cao – Thực chiến 5 dự án doanh nghiệp
Khóa học Data Analyst nâng cao – Thực chiến 5 dự án doanh nghiệp
Nguồn: Google Cloud Blog

Với hơn 15 năm kinh nghiệm trong lĩnh vực Data Engineering, Business Intelligence (BI) và Data Analytics, Ha Vu Phuong không chỉ là một chuyên gia trong ngành mà còn là người tiên phong trong việc triển khai hệ thống dữ liệu lớn cho các ngân hàng và doanh nghiệp tại Việt Nam.