
Trong bối cảnh chuyển đổi số, nhiều doanh nghiệp đã đầu tư mạnh vào các hệ thống lõi như CRM, ERP, Data Warehouse hay Marketing Automation. Tuy nhiên, một nghịch lý phổ biến là dữ liệu vẫn bị phân tán và “kẹt” trong các hệ thống riêng lẻ, thiếu khả năng kết nối tổng thể. Điều này khiến doanh nghiệp dù có lượng dữ liệu lớn nhưng vẫn không thể xây dựng một cái nhìn Customer 360 thống nhất và sâu sắc về khách hàng.
Nguyên nhân chính không nằm ở công nghệ, mà ở sự thiếu đồng bộ trong chiến lược hội tụ dữ liệu, dữ liệu bị chia cắt giữa các phòng ban, cùng với nền tảng Data Governance chưa chặt chẽ. Vì vậy, doanh nghiệp cần xây dựng kiến trúc Customer 360 như một nền tảng trung tâm để kết nối, đồng bộ và khai thác dữ liệu xuyên suốt giữa các hệ thống, qua đó chuyển hóa dữ liệu phân tán thành giá trị kinh doanh thực tế.

Mục lục
I. Bản Chất Học Thuật Của Kiến Trúc Customer 360 Trong Khoa Học Dữ Liệu
Để thiết kế một hệ thống hội tụ vận hành chuẩn xác, trước hết chúng ta cần chuẩn hóa tư duy về khái niệm kiến trúc Customer 360 dưới góc nhìn học thuật.
Trong khoa học dữ liệu, đây không phải là một công cụ hay một phần mềm thương mại cụ thể, mà là một khung xương kiến trúc (Framework) mô tả cách thức tổ chức dữ liệu, công nghệ và quy trình vận hành nhằm thu thập, làm sạch và hợp nhất toàn bộ các điểm chạm tương tác của khách hàng về một hồ sơ duy nhất (Unified Customer Profile).
Kiến trúc này đóng vai trò định hướng cách thức dòng dữ liệu di chuyển, tương tác, chuyển hóa và được kiểm soát nghiêm ngặt bên trong tổ chức. Nó đóng vai trò như một tầng nền tảng (Abstraction Layer) nằm trên các hệ thống tác nghiệp, chịu trách nhiệm đồng bộ hóa ngữ nghĩa dữ liệu mà không làm xáo trộn cấu trúc vận hành cốt lõi của các phần mềm thành phần.
Xét dưới góc độ chiến lược, một kiến trúc Customer 360 được thiết kế chuẩn mực bắt buộc phải giúp tổ chức đạt được ba mục tiêu cốt lõi nhằm tối ưu hóa giá trị tài sản số.
Trước hết, hệ thống phải kiến tạo được nguồn sự thật duy nhất (Single Source of Truth) nhằm xóa bỏ hoàn toàn tình trạng không nhất quán dữ liệu, nơi mà mỗi phòng ban lại giữ một phiên bản thông tin khác nhau về cùng một thực thể khách hàng.
Song song với đó, cấu trúc này phải thúc đẩy cơ chế lưu thông thông tin liên phòng ban, phá vỡ triệt để các ốc đảo thông tin thâm căn cố đế để thiết lập một giao thức chia sẻ dữ liệu mượt mà, minh bạch giữa khối kỹ thuật (Data Team) và khối nghiệp vụ (Sales, Marketing, CSKH).
Cuối cùng, mục tiêu tối thượng của khung kiến trúc là kích hoạt năng lực thực chiến của dữ liệu, đảm bảo toàn bộ tài nguyên sau khi trải qua các bộ lọc xử lý tinh vi sẽ không rơi vào trạng thái lưu trữ thụ động, mà phải được chuyển hóa thành các hành động kinh doanh cụ thể, trực tiếp phục vụ các chiến dịch tiếp thị và tối ưu hóa vận hành thực tế.
II. Tổng Quan Sơ Đồ Khung Vận Hành Và Dòng Chảy Dữ Liệu Trung Tâm
Về mặt cấu trúc, dòng chảy dữ liệu bên trong kiến trúc Customer 360 vận hành theo một nguyên lý tuyến tính nghiêm ngặt từ dưới lên trên, chuyển hóa từ các tập dữ liệu thô sơ ban đầu thành các quyết định kinh doanh có giá trị chiến lược.
Ở tầng đáy, hệ thống thiết lập các cổng kết nối để liên tục hút dữ liệu từ mọi điểm chạm tương tác của doanh nghiệp. Ngay sau khi được thu gom, dòng dữ liệu này được đẩy qua tầng trung tâm – nơi diễn ra các hoạt động kỹ thuật phức tạp bao gồm làm sạch, chuẩn hóa cú pháp, mã hóa bảo mật và thực hiện thuật toán ghép định danh phức hợp nhằm định hình nên một mã khách hàng duy nhất.
Khi hồ sơ khách hàng đã được làm sạch và hợp nhất, dữ liệu tiếp tục được chuyển dịch lên tầng phân tích nâng cao. Tại đây, các mô hình trí tuệ nhân tạo và học máy sẽ can thiệp để tính toán các chỉ số dự báo tương lai, gắn thẻ phân khúc vi mô và làm giàu thuộc tính hồ sơ.
Thành phẩm thông tin chuyên sâu này cuối cùng sẽ được tầng kích hoạt phân phối ngược trở lại các phần mềm tác nghiệp tuyến đầu hoặc các hệ thống báo cáo quản trị thông minh. Toàn bộ chu trình này tạo nên một vòng lặp khép kín, đảm bảo dữ liệu liên tục được cập nhật, tối ưu hóa và sinh lời cho doanh nghiệp theo thời gian thực.
III. Mổ Xẻ Chi Tiết 7 Thành Phần Cốt Lõi Trong Kiến Trúc Customer 360
Để xây dựng thành công một hệ thống dữ liệu hội tụ mạnh mẽ, các kiến trúc sư giải pháp phải bóc tách và thiết kế nghiêm ngặt 7 thành phần cấu thành cốt lõi dưới đây.
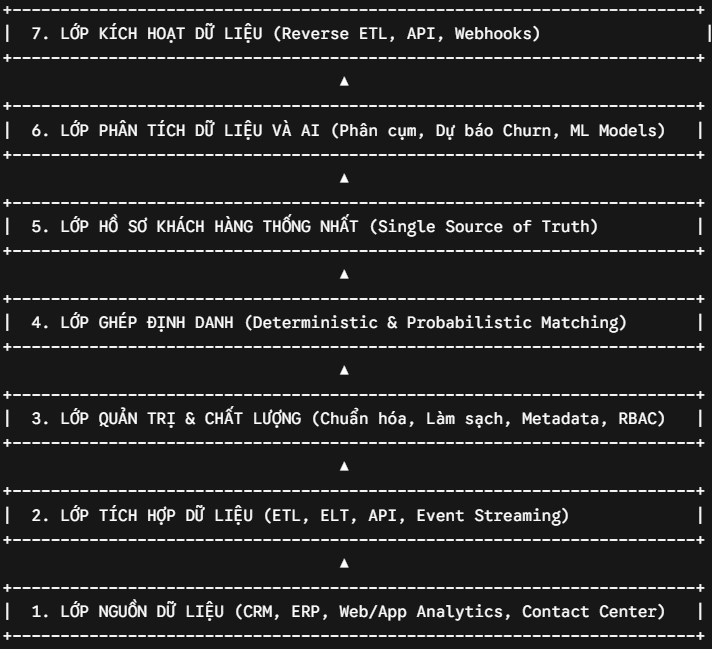
1. Lớp Nguồn Dữ Liệu (Data Sources)
Thành phần đầu tiên nằm ở tầng đáy của kiến trúc Customer 360 là lớp nguồn dữ liệu. Thành phần này hoàn toàn không tự sinh ra dữ liệu, mà đóng vai trò là đầu mối tiếp nhận mọi dấu vết tương tác của khách hàng từ trực tuyến cho đến ngoại tuyến.
Để quản trị hiệu quả, lớp dữ liệu này thường được chia thành bốn nhóm chính: dữ liệu hồ sơ (Profile Data) từ CRM, bao gồm thông tin liên hệ và lịch sử chăm sóc khách hàng; dữ liệu giao dịch (Transactional Data) từ ERP hoặc POS, ghi nhận hoạt động mua sắm và hóa đơn; dữ liệu hành vi số (Behavioral Data) thu thập từ website và ứng dụng di động dưới dạng sự kiện thời gian thực; và dữ liệu phản hồi (Feedback Data) từ contact center, gồm ticket hỗ trợ, khiếu nại và mức độ hài lòng của khách hàng.
2. Lớp Tích Hợp Dữ Liệu (Data Integration Layer)
Khi các nguồn dữ liệu đã được xác định, lớp tích hợp dữ liệu đóng vai trò như “đường ống” trung gian, chịu trách nhiệm thu thập, đồng bộ và chuyển dữ liệu từ các hệ thống tác nghiệp về kho lưu trữ trung tâm.
Tùy vào khối lượng và yêu cầu độ trễ, lớp này vận hành qua bốn cơ chế chính: ETL, trong đó dữ liệu được trích xuất, xử lý rồi mới nạp vào kho, phù hợp với dữ liệu giao dịch lớn theo lô định kỳ; ELT, nạp dữ liệu thô lên cloud trước rồi xử lý sau để tối ưu tốc độ; API cho việc trao đổi dữ liệu nhỏ và nhanh; và Event Streaming như Apache Kafka để truyền dữ liệu hành vi theo thời gian thực với độ trễ rất thấp.
3. Lớp Quản Trị Và Chất Lược Dữ Liệu (Data Quality & Data Governance)
Dữ liệu thô từ nhiều nguồn đổ về chắc chắn sẽ đối mặt với tình trạng xung đột cú pháp, sai lệch định dạng và chứa nhiều tạp chất. Lớp quản trị và chất lượng dữ liệu đóng vai trò như một bộ lọc nghiêm ngặt, chịu trách nhiệm làm sạch và định hình tài nguyên thông qua các rào cản kỹ thuật chuyên sâu.
Quy trình này bắt đầu bằng việc chuẩn hóa dữ liệu (Data Normalization) nhằm đồng bộ hóa các biến thể về một quy chuẩn chung như định dạng ngày tháng hay cấu trúc số điện thoại thống nhất. Kế tiếp, hoạt động làm sạch (Data Cleansing) tự động phát hiện và loại bỏ các bản ghi trùng lặp, xóa ký tự rác hệ thống và điền giá trị mặc định cho các trường thông tin bị bỏ trống.
Đồng thời, màng lọc kiểm soát quyền truy cập sẽ thiết lập chính sách bảo mật, tự động mã hóa các trường dữ liệu nhạy cảm và phân quyền dựa trên vai trò (RBAC) dưới sự quản lý nghiêm ngặt của hệ thống siêu dữ liệu (Metadata Management).
4. Lớp Ghép Định Danh Khách Hàng (Identity Resolution)
Đây là lớp cốt lõi và phức tạp nhất trong kiến trúc Customer 360, quyết định trực tiếp đến hiệu quả toàn hệ thống. Trong môi trường đa kênh, một khách hàng thường tồn tại dưới nhiều định danh khác nhau như CRM ID, email, Device ID hay cookie trình duyệt.
Lớp Identity Resolution giải quyết vấn đề này bằng hai phương pháp chính: đối sánh chính xác (Deterministic Matching), khi các bản ghi được hợp nhất dựa trên ít nhất một thông tin định danh trùng khớp tuyệt đối; và đối sánh xác suất (Probabilistic Matching), sử dụng thuật toán để phân tích hành vi và tính toán mức độ liên quan dựa trên các tín hiệu như IP, thời gian tương tác và vị trí địa lý.
Sau khi xử lý, toàn bộ các định danh rời rạc sẽ được hợp nhất thành một mã định danh duy nhất gọi là Master Customer ID.
5. Lớp Hồ Sơ Khách Hàng Thống Nhất (Unified Customer Profile)
Thành phẩm sau khi đi qua bộ lọc định danh tinh vi chính là Hồ sơ khách hàng thống nhất. Đây là nơi lưu trữ nguồn sự thật duy nhất, cung cấp một bức chân dung đa chiều, sạch sẽ và được làm giàu liên tục về từng cá nhân khách hàng. Cấu trúc của một hồ sơ hội tụ đạt chuẩn bắt buộc phải bao gồm bốn khối thông tin được sắp xếp khoa học, bắt đầu từ thông tin nhân khẩu học cơ bản hoặc thuộc tính tổ chức đối với mô hình B2B.
Tiếp theo là dòng thời gian hành vi tích hợp (Behavioral Timeline) hiển thị trực quan mọi hành động của khách hàng theo chuỗi niên đại trên mọi kênh tương tác. Đi kèm với đó là lớp chỉ số tổng hợp chuyên sâu (Aggregated Metrics) bao gồm tổng chi tiêu, tần suất mua sắm và giá trị vòng đời khách hàng (CLV) được tính toán tự động, kết hợp với hệ thống thẻ phân loại và sở thích (Tags & Preferences) giúp định vị chính xác phân khúc hiện tại của khách hàng.
6. Lớp Phân Tích Dữ Liệu Và AI (Analytics & AI Layer)
Khi dữ liệu đã nằm gọn trong một kho lưu trữ sạch sẽ, lớp Trí tuệ nhân tạo (AI) và Học máy (Machine Learning) sẽ can thiệp để chuyển hóa các dữ liệu lịch sử trong hồ sơ thành các dự báo có tính định hướng tương lai, giúp doanh nghiệp chủ động đón đầu xu hướng thị trường.
Cơ chế này vận hành dựa trên ba mô hình thuật toán chuyên sâu bao gồm mô hình phân khúc nâng cao (Advanced Customer Segmentation) sử dụng thuật toán phân cụm tự động để nhóm khách hàng thành các phân khúc vi mô theo thời gian thực.
Song song đó, mô hình dự báo nguy cơ rời bỏ (Churn Prediction Model) liên tục phân tích các dấu hiệu suy giảm tương tác để kịp thời gắn cờ cảnh báo trước khi khách hàng thực sự từ bỏ thương hiệu. Cuối cùng, mô hình gợi ý hành động tối ưu (Next Best Action) sẽ phân tích sâu lịch sử giao dịch của các nhóm tương đồng để đưa ra dự báo chính xác về sản phẩm tiếp theo khách có khả năng mua cao nhất.
7. Lớp Kích Hoạt Dữ Liệu (Data Activation)
Thành phần cuối cùng này chịu trách nhiệm hiện thực hóa giá trị kinh doanh của toàn bộ hạ tầng kỹ thuật thông qua cơ chế Reverse ETL, Webhooks hoặc API mở để đẩy các thông tin chuyên sâu đã xử lý ngược trở lại các phần mềm tác nghiệp hàng ngày của từng phòng ban nghiệp vụ:
| Bộ phận tiếp nhận | Cơ chế kích hoạt và Ứng dụng thực tế |
| Marketing | Hệ thống tự động đồng bộ tệp khách hàng có nguy cơ rời bỏ sang các công cụ quảng cáo như Facebook Ads, Google Ads hoặc HubSpot để chạy các chiến dịch quảng cáo bám đuổi (Retargeting) hoặc gửi email tặng mã ưu đãi cứu vãn thời gian thực. |
| Sales (Kinh doanh) | Khi nhân viên Sales mở phần mềm CRM, màn hình sẽ lập tức hiển thị thẻ sản phẩm gợi ý bán kèm dựa trên điểm số xác suất mua hàng được tính toán sẵn, giúp thiết kế kịch bản tư vấn trúng đích và nâng cao tỷ lệ bán chéo (Cross-selling). |
| Chăm sóc khách hàng | Hệ thống tổng đài tự động nhận diện Master Customer ID khi khách gọi đến, lập tức hiển thị toàn bộ lịch sử tương tác và các khiếu nại kỹ thuật cũ trên màn hình của điện thoại viên để họ chủ động xử lý sự cố ngay lập tức. |
| Ban lãnh đạo | Dữ liệu sạch từ kho trung tâm được truyền trực tiếp về các Dashboard quản trị thông minh (Power BI, Tableau), cung cấp các biểu đồ trực quan, chính xác về sức khỏe doanh nghiệp theo thời gian thực để phục vụ công tác ra quyết định chiến lược. |
IV. Phân Tích So Sánh Các Mô Hình Kiến Trúc Triển Khai Phổ Biến
Để hiện thực hóa sơ đồ 7 thành phần nêu trên, doanh nghiệp cần phải lựa chọn một mô hình kiến trúc hạ tầng phù hợp với quy mô dữ liệu và năng lực công nghệ của tổ chức. Mỗi mô hình đều sở hữu những đặc tính kỹ thuật và ranh giới ứng dụng riêng biệt đòi hỏi sự cân nhắc kỹ lưỡng từ các chuyên gia kiến trúc giải pháp.
Mô hình kiến trúc đầu tiên và cũng là truyền thống nhất chính là Mô hình tập trung (Centralized Model). Theo cơ chế này, toàn bộ dữ liệu từ các hệ thống nguồn sẽ được hút hoàn toàn và lưu trữ vật lý tại một kho dữ liệu duy nhất như Data Warehouse hoặc một nền tảng CDP đóng gói. Điểm mạnh vượt trội của mô hình này nằm ở năng lực đồng bộ hóa dữ liệu tuyệt đối, giúp việc thiết lập khung quản trị dữ liệu và bảo mật thông tin trở nên nhất quán và dễ dàng hơn.
Tuy nhiên, nhược điểm lớn nhất của nó là chi phí đầu tư hạ tầng phần cứng và bản quyền phần mềm ban đầu rất cao, thời gian triển khai thường kéo dài và đòi hỏi đội ngũ kỹ sư phải có năng lực xử lý dữ liệu lớn chuyên sâu để vận hành bộ máy cồng kềnh này. Mô hình này là lựa chọn bắt buộc cho ngành Ngân hàng, Bảo hiểm hoặc các Tập đoàn tài chính lớn nơi an toàn bảo mật và tính chính xác tuyệt đối được đặt lên hàng đầu.
Để khắc phục nhược điểm về thời gian triển khai và chi phí của mô hình tập trung, Mô hình kết hợp (Hybrid Model) đã ra đời như một giải pháp dung hòa linh hoạt.
Trong kiến trúc Hybrid, các dữ liệu định danh cốt lõi và lịch sử giao dịch quan trọng sẽ được gộp về kho lưu trữ trung tâm để xử lý ghép định danh, trong khi các dữ liệu hành vi chi tiết hoặc log kỹ thuật số dung lượng lớn vẫn được giữ lại tại các hệ thống nguồn và chỉ được truy vấn thông qua kết nối API khi có yêu cầu tác nghiệp cụ thể.
Kiến trúc này giúp giảm tải áp lực lưu trữ cho kho trung tâm và tăng tốc độ triển khai, thế nhưng nó lại đặt ra một thách thức rất lớn về mặt quản trị khi cơ chế đồng bộ hóa giữa các tầng dữ liệu trở nên phức tạp hơn rất nhiều. Đây là mô hình lý tưởng cho các doanh nghiệp quy mô vừa đang trong giai đoạn tăng trưởng nhanh và cần tối ưu hóa chi phí.
Trong những năm gần đây, với sự phát triển mạnh mẽ của hạ tầng điện toán đám mây, Mô hình Composable (Composable Architecture) đã trỗi dậy và trở thành một xu hướng kiến trúc tiên tiến được các chuyên gia dữ liệu đánh giá rất cao.
Mô hình này cho phép doanh nghiệp không cần phải mua một nền tảng đóng gói sẵn cồng kềnh, mà tự thiết lập hệ thống bằng cách lắp ghép các mô-đun công nghệ chuyên biệt đứng trực tiếp trên nền tảng một kho dữ liệu đám mây có sẵn của tổ chức. Kiến trúc này mang lại khả năng mở rộng cực kỳ linh hoạt, chi phí tối ưu theo mức độ sử dụng thực tế và không bị phụ thuộc vào một nhà cung cấp giải pháp duy nhất.
Dù vậy, nhược điểm cốt lõi của nó là đòi hỏi đội ngũ kỹ sư dữ liệu nội bộ phải có trình độ chuyên môn rất cao để tự làm chủ việc tích hợp và vận hành các cấu phần rời rạc thành một thể thống nhất. Mô hình này cực kỳ phù hợp cho các tập đoàn công nghệ hoặc các doanh nghiệp đã có nền tảng dữ liệu trưởng thành.
V. Ma Trận Hệ Sinh Thái Công Nghệ Hỗ Trợ Kiến Trúc Dữ Liệu
Việc hiện thực hóa sơ đồ kiến trúc Customer 360 đòi hỏi sự phối hợp nhịp nhàng của một hệ sinh thái công nghệ đa tầng từ hạ tầng lên ứng dụng, được cụ thể hóa qua bảng phân bổ giải pháp chuyên nghiệp dưới đây:
| Thành phần kiến trúc | Giải pháp / Nền tảng tiêu biểu | Vai trò kỹ thuật thực tế trong hệ thống |
| Hệ thống nguồn (Data Sources) | Salesforce CRM, Oracle ERP, SAP, POS Systems | Ghi nhận và lưu trữ các tập dữ liệu tác nghiệp thô ban đầu của từng bộ phận chức năng. |
| Quản trị dữ liệu khách hàng | Segment, Twilio CDP, Tealium, Insider | Hỗ trợ thu thập luồng dữ liệu, xử lý định danh (Identity Resolution) và kích hoạt dữ liệu thời gian thực. |
| Hạ tầng lưu trữ quy mô lớn | Snowflake, Google BigQuery, AWS Redshift | Kho dữ liệu trung tâm (Data Warehouse) cho dữ liệu có cấu trúc, phục vụ truy vấn nặng. |
| Hồ dữ liệu linh hoạt | Databricks (Data Lakehouse) | Lưu trữ và xử lý các tập dữ liệu lớn, dữ liệu phi cấu trúc, phục vụ huấn luyện mô hình AI. |
| Trực quan hóa dữ liệu | Microsoft Power BI, Tableau, Looker | Xây dựng các hệ thống Dashboard báo cáo thông minh, trực quan hóa chỉ số cho ban điều hành. |
| Lớp phân tích nâng cao | Machine Learning Platforms (Python, Vertex AI) | Chạy các mô hình thuật toán dự báo rời bỏ, phân cụm khách hàng và tối ưu gợi ý hành vi. |
VI. 5 Sai Lầm Chiến Lược Khiến Dự Án Dữ Liệu Thất Bại
Hành trình hiện thực hóa giải pháp chứa đựng rất nhiều rủi ro mang tính hệ thống mà nếu không nhận diện sớm, doanh nghiệp sẽ phải trả giá bằng những khoản lãng phí ngân sách khổng lồ.
Mối nguy hiểm đầu tiên xuất phát từ việc đồng nhất khung kiến trúc với một phần mềm thương mại cụ thể, dẫn đến việc ban điều hành coi dự án này là một thương vụ mua sắm phần mềm thuần túy rồi khoán trắng cho phòng IT mà thiếu đi một chiến lược gắn liền với bài toán kinh doanh. Điều này hệ quả dẫn đến sai lầm thứ hai là sự thiếu đồng hành của khối nghiệp vụ tuyến đầu ngay từ khâu thiết kế, khiến sản phẩm đầu ra hoàn toàn không khớp với quy trình tác nghiệp thực tế của phòng Sales hay Marketing.
Bên cạnh đó, việc bỏ quên khung Quản trị Dữ liệu (Data Governance) cũng là một bẫy ngầm đáng sợ, bởi nếu không có quy định rõ ràng về quyền sở hữu dữ liệu và quy chuẩn nhập liệu, kho dữ liệu trung tâm sẽ nhanh chóng bị tái ô nhiễm thành một đầm lầy dữ liệu rác chỉ sau vài tháng vận hành.
Tình trạng này càng trở nên nghiêm trọng nếu doanh nghiệp dung nạp dữ liệu bẩn và thiết lập thuật toán định danh của lớp Identity Resolution lỏng lẻo, gây ra hiện tượng gộp nhầm hồ sơ của các cá thể khác nhau và phá vỡ hoàn toàn tính chính xác của các mô hình dự báo.
Cuối cùng, việc triển khai dàn trải thiếu trọng tâm và không xác định hệ chỉ số KPI rõ ràng ngay từ đầu sẽ khiến dự án mất đi thước đo định hướng, làm đội ngũ kỹ thuật gặp khó khăn trong việc chứng minh hiệu quả đầu tư thực tế để thuyết phục ban lãnh đạo tiếp tục duy trì ngân sách dài hạn.
VII. Khảo Sát Các Câu Hỏi Thường Gặp Dưới Góc Nhìn Chuyên Gia (FAQ)
1. Xây dựng một kiến trúc Customer 360 có bắt buộc phải mua nền tảng CDP không?
Việc cấu thành hệ thống có cần đến nền tảng CDP (Customer Data Platform) hay không phụ thuộc hoàn toàn vào yêu cầu về độ trễ của bài toán kinh doanh thực tế. Nếu doanh nghiệp đòi hỏi phải cá nhân hóa trải nghiệm theo thời gian thực (Real-time) ngay khi khách hàng đang tương tác trên Web/App, CDP sẽ là một mảnh ghép hỗ trợ đắc lực nhờ các cổng kết nối và bộ lọc dữ liệu dòng chảy có sẵn.
Ngược lại, nếu mục tiêu cốt lõi của tổ chức chỉ dừng lại ở việc phục vụ các báo cáo quản trị chiến lược, phân tích chuyên sâu định kỳ hoặc tối ưu vận hành dạng Batch, hệ thống hoàn toàn có thể được xây dựng vững chắc dựa trên nền tảng Cloud Data Warehouse và các công cụ ETL/ELT truyền thống nhằm tối ưu hóa chi phí đầu tư và bảo trì hạ tầng.
2. Sự khác biệt cốt lõi giữa hệ thống CRM và kiến trúc Customer 360 là gì?
Đây là hai thành phần có mối quan hệ tương hỗ chặt chẽ nhưng đóng vai trò hoàn toàn khác nhau trong bức tranh tổng thể của Enterprise IT. CRM bản chất là một hệ thống tác nghiệp nguồn (Operational System), được thiết kế để ghi nhận, lưu trữ và quản lý các tương tác trực tiếp của đội ngũ Sales và bộ phận chăm sóc khách hàng tuyến đầu.
Trong khi đó, kiến trúc Customer 360 đứng ở tầng trên, đóng vai trò là một tầng hội tụ dữ liệu trung tâm của toàn tổ chức. Nó tiến hành thu hút dữ liệu từ CRM kết hợp đồng thời với dữ liệu giao dịch từ ERP, dữ liệu hành vi từ Web/App và nhật ký cuộc gọi từ Call Center để tạo ra một hồ sơ tổng thể duy nhất, sau đó làm giàu thông tin bằng AI và trả ngược các insight giá trị về lại để giúp chính hệ thống CRM hoạt động thông minh và hiệu quả hơn.
3. Phương pháp tiếp cận nào là an toàn nhất cho doanh nghiệp bắt đầu từ con số 0?
Với các doanh nghiệp có hạ tầng dữ liệu còn sơ khai, việc triển khai ngay một kiến trúc Customer 360 toàn diện có thể gây rủi ro thất bại. Cách tiếp cận hiệu quả hơn là triển khai theo từng giai đoạn (phased approach) trong khoảng 3–12 tháng tùy năng lực nội tại.
Giai đoạn đầu nên xây dựng MVP bằng cách kết nối 2 nguồn dữ liệu quan trọng và tương đối sạch như CRM và Website Analytics trên một mô hình hybrid đơn giản để làm quen quy trình. Khi hệ thống vận hành ổn định, doanh nghiệp có thể mở rộng dần sang các nguồn phức tạp hơn như ERP, dữ liệu POS offline, và cuối cùng là tích hợp AI/Machine Learning để phục vụ các mô hình phân tích và dự báo nâng cao.
Kết Luận
Bản chất của việc xây dựng và vận hành Customer 360 không nằm ở việc đầu tư nhiều công nghệ đắt tiền, mà ở chiến lược quản trị dữ liệu chặt chẽ và sự phối hợp đồng bộ giữa các phòng ban. Khi doanh nghiệp thiết kế được một kiến trúc chuẩn với 7 thành phần cốt lõi, từ lớp dữ liệu nguồn đến lớp kích hoạt, họ sẽ tạo ra một nền tảng dữ liệu thống nhất, sạch và đã được hội tụ.
Trên nền tảng đó, doanh nghiệp có thể tối ưu chi phí vận hành, nâng cao trải nghiệm khách hàng và thúc đẩy tăng trưởng bền vững trong kỷ nguyên số.
INDA Academy tự hào là đơn vị tiên phong trong việc đào tạo phân tích dữ liệu và AI chuyên sâu, đặc biệt cho khối ngành Ngân hàng – Tài chính – Bảo hiểm tại Việt Nam. Sau hơn 12 năm “thực chiến” cùng những dòng chảy dữ liệu khổng lồ, chúng tôi đã xây dựng nên một hệ sinh thái đào tạo toàn diện, giúp hàng nghìn học viên chuyển mình từ người mới bắt đầu trở thành những chuyên gia lành nghề, sẵn sàng đáp ứng tiêu chuẩn khắt khe của các doanh nghiệp lớn.
Điểm khác biệt lớn nhất tại INDA chính là triết lý đào tạo dựa trên các dự án thực tế (Project-based) và lộ trình cá nhân hóa nhờ ứng dụng AI. Chúng tôi không chỉ dạy bạn cách sử dụng công cụ, mà còn truyền tải tư duy khai phá giá trị từ dữ liệu để đưa ra quyết định kinh doanh chính xác.
Tìm hiểu thêm về các khóa học TẠI ĐÂY:
Lộ trình đào tạo Data Engineer
Lộ trình đào tạo Data Analyst
Lộ trình đào tạo Tester
Khóa học Data Engineer nâng cao – Thực chiến 5 dự án doanh nghiệp
Khóa học Data Analyst nâng cao – Thực chiến 5 dự án doanh nghiệp
