
Trong bối cảnh quản trị doanh nghiệp hiện đại, việc đầu tư ngân sách khổng lồ vào các hệ thống cốt lõi như CRM, ERP, Data Warehouse hay các giải pháp Marketing Automation tiên tiến không còn là điều hiếm gặp. Thế nhưng, đa số ban lãnh đạo và các kỹ sư dữ liệu (Data Engineers) vẫn phải đối mặt với một nghịch lý hệ thống: Dữ liệu sinh ra liên tục nhưng bị giam cầm trong các cấu trúc cô lập, hoàn toàn thiếu cơ chế liên thông toàn diện. Hệ quả là doanh nghiệp sở hữu tài nguyên số nhưng bất lực trong việc phác họa một chân dung khách hàng thống nhất.
Để giải quyết triệt để bài toán này, các tổ chức không thể chỉ dựa vào việc mua sắm công cụ công nghệ độc lập mà phải thấu hiểu sâu sắc bản chất kiến trúc dữ liệu trung tâm. Việc nghiên cứu cơ chế Customer 360 hoạt động như thế nào chính là chìa khóa giúp các nhà quản trị phá vỡ các “ốc đảo dữ liệu” (Data Silos), chuyển hóa các tập dữ liệu phân mảnh thành nguồn tài sản chiến lược thúc đẩy tăng trưởng.

Mục lục
I. Nguyên Lý Cốt Lõi: Bản Chất Kiến Trúc Customer 360 Hoạt Động Như Thế Nào?
Để hình dung một cách bản chất customer 360 hoạt động như thế nào, chúng ta cần hiểu rằng đây không phải là một kho chứa dữ liệu tĩnh (Static Repository) mà là một chu trình động liên tục (Dynamic Data Cycle). Mọi thành phần trong kiến trúc này đều vận hành dựa trên một nguyên lý tối thượng: One Customer = One Unified Profile (Một khách hàng tương ứng với một hồ sơ hội tụ duy nhất).

Về mặt cơ chế, mô hình customer 360 hoạt động như thế nào trong thực tế vận hành? Chu trình này đòi hỏi hệ thống phải liên tục thực hiện việc hút dữ liệu từ nguồn, xử lý làm sạch, áp dụng thuật toán đối sánh để giải quyết bài toán định danh, và kích hoạt dòng dữ liệu ngược trở lại các phần mềm tác nghiệp hàng ngày (CRM, Helpdesk, Automation Tools). Chính cơ chế tuần hoàn này đảm bảo dữ liệu luôn tươi mới (Freshness) và có giá trị sử dụng theo thời gian thực (Real-time Value).
II. Phương Pháp Luận 6 Bước: Quy Trình Customer 360 Hoạt Động Như Thế Nào Trong Doanh Nghiệp?
Để hiện thực hóa mô hình này, đội ngũ kỹ sư dữ liệu và chuyên viên kiến trúc giải pháp (Solution Architects) cần tuân thủ nghiêm ngặt quy trình 6 bước chuẩn hóa, minh họa rõ nét cho cách thức customer 360 hoạt động như thế nào từ hạ tầng lên ứng dụng:
Bước 1: Thu thập và Tích hợp dữ liệu đa nguồn (Data Ingestion)
Hệ thống Customer 360 không tự sinh ra dữ liệu mới; vai trò của nó là một Hub trung tâm kết nối dòng chảy thông tin hiện có của tổ chức. Tại bước này, các kỹ sư sẽ thiết lập các đường ống dẫn dữ liệu (Data Pipelines) thông qua các phương thức kết nối linh hoạt như API, Webhook, hoặc các cơ chế truyền file tự động (SFTP Batch Processing) để gom dữ liệu về vùng đệm (Staging Area).
Dòng chảy dữ liệu đầu vào mô tả cách customer 360 hoạt động như thế nào ở tầng biên được phân loại thành hai nhóm chính:
- Dữ liệu tĩnh (Structural/Transactional Data): Thông tin định danh cơ bản từ CRM, lịch sử hóa đơn, công nợ từ hệ thống ERP, hoặc lịch sử quét mã vạch giao dịch tại các máy POS ngoại tuyến.
- Dữ liệu động (Behavioral/Streaming Data): Luồng dữ liệu phún xuất liên tục từ các điểm chạm số (Digital Touchpoints) như hành vi nhấp chuột (Clicks), thời gian lưu trang (On-site time) từ Web tracking, các sự kiện trong ứng dụng (In-app events), log tương tác Email, và nhật ký xử lý ticket từ hệ thống Call Center.
Bước 2: Chuẩn hóa và Làm sạch dữ liệu (Data Cleansing & Standardization)
Dữ liệu thô (Raw Data) thu thập từ nhiều nguồn chắc chắn sẽ đối mặt với tình trạng “nhiễu” do xung đột cú pháp, lỗi nhập liệu thủ công của con người hoặc sự khác biệt trong cấu trúc thiết kế của từng phần mềm gốc. Nếu đưa thẳng dữ liệu lỗi này vào kho lưu trữ, hệ thống sẽ rơi vào cái bẫy “Dữ liệu rác” (Garbage In, Garbage Out).
Bài toán thực tế: Một khách hàng tên là Nguyễn Văn A đăng ký thẻ thành viên. Hệ thống CRM ghi nhận là Nguyễn Văn A, log Website lưu trữ dạng không dấu là Nguyen Van A, trong khi hóa đơn ERP lại xuất dữ liệu chữ in hoa là NGUYEN VAN A.
Nhiệm vụ của lớp xử lý dữ liệu ở bước này là áp dụng các quy tắc cấu trúc (Parsing & Transformation Rules): xóa bỏ các ký tự đặc biệt, đồng bộ bảng mã font chữ, chuẩn hóa định dạng ngày tháng và quy đổi toàn bộ các trường thông tin liên hệ (như số điện thoại về định dạng quốc tế +84) về một tiêu chuẩn duy nhất.
Bước 3: Ghép định danh khách hàng chuyên sâu (Identity Resolution)
Đây được coi là “trái tim” và là cấu phần kỹ thuật phản ánh rõ nhất việc customer 360 hoạt động như thế nào để xử lý các thuật toán phức tạp. Trọng tâm của bước này là liên kết các chuỗi nhận diện rời rạc (như Account ID trên CRM, Cookie ID trên trình duyệt Web, Device ID trên điện thoại, và Email cá nhân) để xác định xem chúng có thuộc về cùng một thực thể duy nhất hay không.
Hệ thống sẽ áp dụng hai cơ chế đối sánh chuyên sâu:
- Đối sánh chính xác (Deterministic Matching): Dựa trên các trường dữ liệu định danh tuyệt đối và có độ chính xác cao như số Căn cước công dân (CCCD), Số điện thoại chính, Mã số thuế, hoặc Địa chỉ Email duy nhất.
- Đối sánh xác suất (Probabilistic Matching): Khi thiếu các trường định danh tuyệt đối, AI và Học máy (Machine Learning) sẽ tính toán trọng số xác suất dựa trên các thông tin mờ như: họ tên gần giống nhau, truy cập từ cùng một địa chỉ IP, hoặc dùng chung một mã nhận diện quảng cáo thiết bị (IDFA/GAID). Nếu tổng điểm số tin cậy vượt qua ngưỡng cấu hình (Confidence Threshold), hệ thống sẽ ra quyết định hợp nhất tài khoản.
| Loại khóa định danh | Thuộc tính thành phần | Hệ thống nguồn cung cấp chính |
| Dữ liệu ngoại tuyến (Offline ID) | Email, Phone Number, CCCD, Customer_ID | CRM, ERP, Core-Banking, POS, Call Center |
| Dữ liệu trực tuyến (Online ID) | Device ID (IDFA/GAID), Cookie ID, IP Address | Web/App Analytics, CDP Tracking SDK |
Bước 4: Xây dựng Hồ sơ khách hàng thống nhất (Unified Customer Profile)
Sau khi hoàn tất quá trình ghép định danh, hệ thống tiến hành tổng hợp tất cả các thuộc tính dữ liệu (Attributes Mapping) để thiết lập một Hồ sơ khách hàng thống nhất. Đây chính là thực thể thông tin hoàn chỉnh nhất – nơi cung cấp một Nguồn sự thật duy nhất (Single Source of Truth – SSOT) cho toàn bộ tổ chức.
Hồ sơ thống nhất này không phải là một bảng dữ liệu phẳng thông thường. Nó là một cấu trúc đa chiều bao gồm trục dòng thời gian hành vi (Behavioral Timeline) ghi nhận mọi tương tác lịch sử theo thứ tự thời gian thực, danh mục sản phẩm/dịch vụ hiện hữu và mức độ phân hạng thành viên (Tiering). Toàn bộ kho dữ liệu này sẽ được lưu trữ tối ưu tại các hạ tầng chuyên dụng như Customer Data Platform (CDP) hoặc Data Warehouse/Data Lake để sẵn sàng cung cấp cho các bộ phận khai thác.
Bước 5: Phân tích nâng cao và Kiến tạo Insight (Intelligence Layer)
Sở hữu dữ liệu sạch mới chỉ là điều kiện cần; giá trị kinh tế thực sự chỉ xuất hiện khi doanh nghiệp tích hợp thêm Lớp xử lý thông minh (Intelligence Layer) bằng các mô hình phân tích nâng cao và Trí tuệ nhân tạo (AI) nhằm khai thác sâu hơn cách thức customer 360 hoạt động như thế nào khi chuyển hóa dữ liệu thành hành động.
Tại bước này, các thuật toán Machine Learning sẽ chạy liên tục trên các hồ sơ hội tụ để phát hiện các mẫu hành vi đặc trưng. Chẳng hạn, mô hình dự báo rời bỏ (Churn Prediction Model) sẽ tự động chấm điểm rủi ro của từng khách hàng dựa trên các biến số đầu vào như: tần suất tương tác giảm đột ngột, có lịch sử khiếu nại chưa xử lý triệt để. Đồng thời, hệ thống cũng tự động tính toán Giá trị vòng đời tương lai (Customer Lifetime Value – CLV) và đề xuất giải pháp tiếp cận tối ưu kế tiếp (Next Best Action – NBA).
Bước 6: Kích hoạt dữ liệu toàn diện (Data Activation)
Dữ liệu sẽ trở thành một tài nguyên chết nếu nó chỉ được lưu trữ trong các hạ tầng của phòng IT. Bước cuối cùng để chứng minh hiệu quả thực tế của việc customer 360 hoạt động như thế nào chính là Kịch hoạt dữ liệu (Data Activation) – hay còn gọi là quá trình đồng bộ ngược (Reverse ETL).
Hệ thống sẽ đẩy các Insight, phân khúc khách hàng (Segments) và điểm số dự báo đã được xử lý về lại chính các công cụ tác nghiệp hàng ngày của các bộ phận:
- Marketing: Nhận tệp khách hàng được phân loại tự động để kích hoạt các kịch bản nuôi dưỡng, cá nhân hóa thông điệp hiển thị trên Web/App theo thời gian thực.
- Sales: Hệ thống CRM của nhân viên kinh doanh lập tức hiển thị thông tin về các sản phẩm mà khách hàng vừa tìm kiếm nhiều nhất trên môi trường số, cung cấp bối cảnh đắt giá để thực hiện các cuộc gọi bán chéo (Cross-selling).
- Customer Service: Điện thoại viên tổng đài tiếp nhận thông tin hóa đơn và lịch sử lỗi hệ thống của khách hàng ngay khi hồi chuông điện thoại reo lên, rút ngắn tối đa thời gian xử lý khiếu nại (AHT).
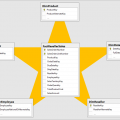
III. Kiến Trúc Hạ Tầng: Sơ Đồ Hệ Thống Customer 360 Hoạt Động Như Thế Nào?
Để triển khai giải pháp này một cách bài bản, doanh nghiệp cần xây dựng và làm chủ một mô hình kiến trúc công nghệ đa tầng. Sơ đồ dưới đây khái quát tổng quan mô hình dòng chảy dữ liệu của customer 360 hoạt động như thế nào từ nguồn vào đến đầu ra tác nghiệp:
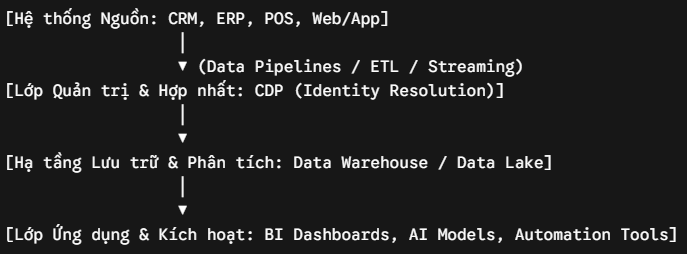
Sự kết hợp đồng bộ giữa các thành phần kiến trúc công nghệ này được cụ thể hóa qua bảng phân bổ giải pháp dưới đây:
| Thành phần kiến trúc | Giải pháp ứng dụng tiêu biểu | Vai trò thực tế trong hệ thống |
| Hệ thống nguồn (Data Sources) | Salesforce, SAP ERP, Oracle POS, Firebase, GA4 | Ghi nhận và lưu trữ gốc các tập dữ liệu thô ban đầu phát sinh từ hoạt động vận hành của từng phòng ban. |
| Lớp quản trị dữ liệu (Data Management Layer) | Segment, Tealium, Insider (CDP) | Thu thập luồng dữ liệu, thực hiện Identity Resolution và quản lý các kịch bản kích hoạt thời gian thực (Real-time Engagement). |
| Hạ tầng lưu trữ (Storage Infrastructure) | Snowflake, Google BigQuery, AWS Redshift | Lưu trữ tập trung dữ liệu lịch sử quy mô lớn, hỗ trợ thực hiện các câu lệnh truy vấn cấu trúc phức tạp (Heavy Queries). |
| Lớp hiển thị (Visualization Layer) | Tableau, Power BI, Looker Studio | Trực quan hóa dữ liệu thô thành hệ thống Dashboard quản trị động phục vụ công tác điều hành của ban lãnh đạo. |
| Lớp xử lý thông minh (Intelligence Layer) | AWS SageMaker, Databricks, Google Vertex AI | Huấn luyện và vận hành các mô hình thuật toán phân tích dự báo, phân cụm khách hàng nâng cao. |
IV. Những “Bẫy Ngầm” Chiến Lược Khiến Dự Án Customer 360 Thất Bại
Hành trình hiện thực hóa giải pháp chứa đựng rất nhiều rủi ro mang tính hệ thống. Hiểu rõ bản chất công nghệ và cách thức customer 360 hoạt động như thế nào thôi là chưa đủ, các nhà quản trị cần nhận diện sớm các sai lầm kinh điển sau:
- Đồng nhất dự án dữ liệu với dự án công nghệ thuần túy: Đây là sai lầm phổ biến nhất khi ban điều hành khoán trắng toàn bộ dự án cho đội ngũ IT. Nếu cấu trúc dữ liệu xây dựng xong không xuất phát từ bài toán kinh doanh thực tế của phòng Marketing, Sales hay CSKH, hệ thống sẽ nhanh chóng rơi vào trạng thái “bỏ hoang”.
- Thiếu Khung quản trị dữ liệu (Data Governance Framework): Xây dựng hệ thống mà không ban hành các quy định nghiêm ngặt về quyền sở hữu dữ liệu, quy chuẩn nhập liệu đầu vào và phân quyền bảo mật thông tin sẽ khiến kho dữ liệu nhanh chóng bị tái ô nhiễm (Data Swamp) chỉ sau một thời gian ngắn vận hành.
- Hệ thống phân giải định danh (Identity Resolution) thiết lập lỏng lẻo: Việc cấu hình sai lệch các quy tắc so khớp (Matching Rules) sẽ dẫn đến hệ quả hệ thống không thể gộp các tài khoản ảo về hồ sơ gốc khiến chân dung khách hàng vẫn bị chia cắt, hoặc nghiêm trọng hơn là gộp nhầm dữ liệu của hai khách hàng khác nhau vào cùng một mã định danh.
V. Khảo Sát Các Câu Hỏi Thường Gặp (Technical & Strategic FAQs)
1. Về mặt kỹ thuật, hệ thống Customer 360 hoạt động như thế nào để đảm bảo tính thời gian thực (Real-Time)?
Tùy thuộc vào kiến trúc hạ tầng và bài toán kinh doanh, cơ chế xử lý của hệ thống sẽ được phân bổ theo 3 tầng: Xử lý theo mẻ (Batch Processing) chạy định kỳ cuối ngày phù hợp cho dữ liệu tài chính ERP; Xử lý cận thời gian thực (Near Real-Time) mất vài phút để đồng bộ dữ liệu giao dịch; và Xử lý luồng (Streaming Processing) áp dụng cho dữ liệu hành vi trên Web/App nhằm kích hoạt ngay lập tức các chiến dịch cá nhân hóa khi khách hàng đang tương tác.
2. Nền tảng Customer 360 có thay thế được hệ thống CRM hiện tại của doanh nghiệp không?
Hoàn toàn không. Đây là hai thành phần có mối quan hệ tương hỗ và đóng vai trò khác nhau trong kiến trúc Enterprise IT. CRM là hệ thống tác nghiệp nguồn (System of Record) phục vụ riêng cho quy trình bán hàng của đội ngũ Sales. Customer 360 đứng ở lớp trên, thu hút dữ liệu từ CRM kết hợp cùng ERP, POS, Website để tạo ra bức tranh tổng thể, sau đó làm giàu thông tin và trả ngược các Insight giá trị về lại để giúp nhân viên Sales sử dụng CRM hoạt động hiệu quả hơn.
3. Giai đoạn đầu xây dựng Customer 360 có bắt buộc phải ứng dụng AI/Machine Learning không?
Không bắt buộc. Trong giai đoạn khởi đầu (MVP), doanh nghiệp hoàn toàn có thể vận hành hệ thống Customer 360 cực kỳ hiệu quả dựa trên các quy tắc logic cứng định sẵn (Rule-based) để làm sạch và ghép định danh chính xác. Việc tích hợp thêm lớp AI/Machine Learning là bước phát triển nâng cao ở giai đoạn sau, khi nền tảng dữ liệu đã thực sự sạch và doanh nghiệp có nhu cầu triển khai các bài toán dự báo rủi ro hoặc tối ưu hóa gợi ý tự động.
Kết Luận
Bản chất của Customer 360 không phải là một công cụ phần mềm độc lập có thể mua đứt bán đoạn trên thị trường. Đây là một chiến lược quản trị dữ liệu dài hạn, đòi hỏi sự kết hợp chặt chẽ giữa ba yếu tố cốt lõi: Quy trình vận hành, Chất lượng dữ liệu và Hạ tầng công nghệ.
Thấu hiểu bản chất kiến trúc customer 360 hoạt động như thế nào và vận hành chuẩn chỉ nó qua quy trình 6 bước kỹ thuật sẽ giúp doanh nghiệp đập tan được các ốc đảo thông tin cô lập, thiết lập một nguồn sự thật duy nhất. Đây chính là nền tảng vững chắc để tối ưu hóa bộ máy vận hành, nâng cao trải nghiệm người dùng và thúc đẩy sự tăng trưởng doanh thu vượt trội trong nền kinh tế số.
INDA Academy tự hào là đơn vị tiên phong trong việc đào tạo phân tích dữ liệu và AI chuyên sâu, đặc biệt cho khối ngành Ngân hàng – Tài chính – Bảo hiểm tại Việt Nam. Sau hơn 12 năm “thực chiến” cùng những dòng chảy dữ liệu khổng lồ, chúng tôi đã xây dựng nên một hệ sinh thái đào tạo toàn diện, giúp hàng nghìn học viên chuyển mình từ người mới bắt đầu trở thành những chuyên gia lành nghề, sẵn sàng đáp ứng tiêu chuẩn khắt khe của các doanh nghiệp lớn.
Điểm khác biệt lớn nhất tại INDA chính là triết lý đào tạo dựa trên các dự án thực tế (Project-based) và lộ trình cá nhân hóa nhờ ứng dụng AI. Chúng tôi không chỉ dạy bạn cách sử dụng công cụ, mà còn truyền tải tư duy khai phá giá trị từ dữ liệu để đưa ra quyết định kinh doanh chính xác.
Tìm hiểu thêm về các khóa học TẠI ĐÂY:
Lộ trình đào tạo Data Engineer
Lộ trình đào tạo Data Analyst
Lộ trình đào tạo Tester
Khóa học Data Engineer nâng cao – Thực chiến 5 dự án doanh nghiệp
Khóa học Data Analyst nâng cao – Thực chiến 5 dự án doanh nghiệp
Bài viết liên quan:
 Chiến Lược Customer 360: 7 Lợi Ích Sống Còn Để Quản Trị Dựa Trên Dữ Liệu
Chiến Lược Customer 360: 7 Lợi Ích Sống Còn Để Quản Trị Dựa Trên Dữ Liệu
 Xây dựng Business Dashboard theo chủ đề, ngành nghề, phòng ban
Xây dựng Business Dashboard theo chủ đề, ngành nghề, phòng ban
 Xây dựng báo cáo chăm sóc khách hàng(Customer Service Dashboard)
Xây dựng báo cáo chăm sóc khách hàng(Customer Service Dashboard)
 Mẫu báo cáo quản trị (Management Dashboard)
Mẫu báo cáo quản trị (Management Dashboard)
 [Power BI Basic] Nhóm các hàng (Group rows) với Power Query Editor
[Power BI Basic] Nhóm các hàng (Group rows) với Power Query Editor
 Cần tìm hiểu những gì để sử dụng Power BI như một Data Analyst?
Cần tìm hiểu những gì để sử dụng Power BI như một Data Analyst?