
Mục lục
Sharding là gì?
Shard trong MongoDB là một tiến trình lưu giữ các bản ghi dữ liệu qua nhiều thiết bị và nó là một phương pháp của MongoDB để đáp ứng yêu cầu về sự gia tăng dữ liệu. Khi kích cỡ của dữ liệu tăng lên, một thiết bị đơn không thể đủ để lưu giữ dữ liệu. Sharding giải quyết vấn đề này với việc mở rộng phạm vi theo bề ngang (horizontal scaling). Với Sharding, bạn bổ sung thêm nhiều thiết bị để hỗ trợ cho việc gia tăng dữ liệu và các yêu cầu của các hoạt động đọc và ghi.
Tại sao sử dụng Sharding?
Trong Replication, tất cả hoạt động ghi thực hiện ở node sơ cấp.
Các truy vấn tiềm tàng vẫn đến node sơ cấp.
Một Replica Set đơn có giới hạn là 12 node.
Bộ nhớ không thể đủ lớn khi tập dữ liệu hoạt động là lớn.
Local Disk là không đủ lớn.
Việc mở rộng phạm vi theo chiều dọc (vertical scaling) là quá tốn kém.
Sharding trong MongoDB
Dưới đây là sơ đồ minh họa Sharding trong MongoDB sử dụng Sharded Cluster.
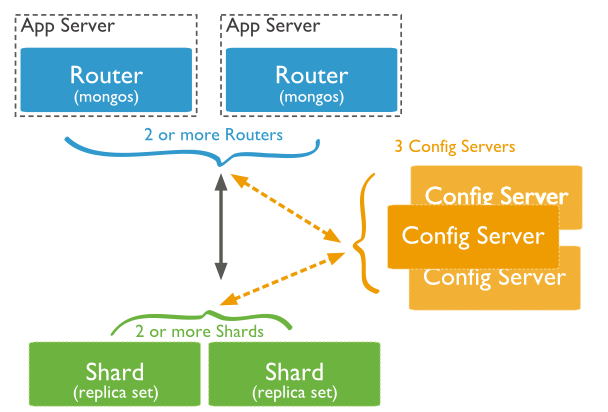
Trong sơ đồ trên, có ba thành phần chính:
Shards: được sử dụng để lưu giữ dữ liệu. Chúng cung cấp tính khả dụng cao và dữ liệu có tính đồng nhất. Trong môi trường tạo lập, mỗi Shard là một Replica Set riêng biệt.
Config Servers: lưu giữ metadata của Cluster. Dữ liệu này chứa một ánh xạ của tập dữ liệu của Cluster tới Shards. Query Router sử dụng metadata này để hướng các hoạt động tới Shards cụ thể. Trong môi trường tạo lập, sharded clusters có chính xác 3 Config Servers.
Query Routers: về cơ bản nó là mongo instance, giao diện với Ứng dụng Client và hướng các hoạt động tới Shard phù hợp. Query Router xử lý và hướng các hoạt động tới Shard và sau đó trả kết quả về Clients. Một Sharded Cluster có thể chứa nhiều hơn một Query Router để phân chia việc tải yêu cầu từ Client. Một Client gửi các yêu cầu tới một Query Router. Nói chung, một Sharded Cluster có nhiều Query Routers.
Nguồn: Internet
Chúng tôi chuyên cung cấp những khóa học về Phân tích dữ liệu, đăng ký ngay để nhận được tư vấn chi tiết lộ trình dành riêng cho bạn nhé!

