
Các lệnh SQL có thể dùng để truy xuất dữ liệu từ bất cứ cơ sở dữ liệu nào. Nếu bạn đã từng truy xuất thông tin từ cơ sở dữ liệu, rất có thể bạn đã gặp những lệnh truy vấn chậm. Để có hiệu năng tốt hơn, chúng ta cần những câu lệnh tối ưu, nhanh hơn, và hiệu quả hơn.
Chủ đề tối ưu hóa truy vấn là rất rộng nhưng chúng tôi sẽ cố gắng đề cập đến những điểm quan trọng nhất. Trong bài viết này, chúng tôi sẽ không đi sâu vào phân tích cơ sở dữ liệu, mà là những thủ thuật đơn giản khi bạn tự học SQL có thể điều chỉnh truy vấn, có thể được áp dụng nhằm cải thiện hiệu suất ngay lập tức.
Mục lục
Giới thiệu về tối ưu hóa
Tối ưu hóa truy vấn là một kĩ năng quan trọng đối với các Data Analyst, nguời khai thác dữ liệu từ CSDL với tần suất cao. Để cải thiện hiệu quả của các truy vấn, các lập trình viên và Data Analyst cần hiểu được công cụ tối ưu hóa truy vấn và và cách công cụ này chọn một lối truy cập và chuẩn bị kế hoạch tiến hành truy vấn.
Việc điều chỉnh truy vấn có liên quan tới những kiến thức về các kĩ thuật như công cụ tối ưu theo chi phí và theo kinh nghiệm, cộng với những công cụ giúp phân tích kế hoạch thực thi truy vấn (execution plan) do CSDL cung cấp. Cách tốt nhất để điều chỉnh hiệu suất là tìm cách viết các truy vấn theo nhiều cách khác nhau, từ đó so sánh kế hoạch thực thi của mỗi truy vấn.
Các bí quyết chung để tối ưu hóa truy vấn khi tự học SQL
Mỗi tip dưới đây đã được kiểm tra bằng cách chạy cả hai truy vấn gốc và truy vấn đã chỉnh sửa khi truy vấn dữ liệu từ cơ sở dữ liệu 11g Oracle mẫu, đặc biệt trên lược đồ Sales (Sales Schema). Tôi đã ghi lại thời gian trung bình của mỗi truy vấn để thể hiện sự tối ưu khi xây dựng các truy vấn hiệu quả hơn.
Lưu ý:
Khi tự học SQL, các kỹ thuật tối ưu truy vấn có sự khác biệt nhau giữa các hệ quản trị CSDL khác nhau, phụ thuộc vào Database Engine của từng hệ quản trị CSDL. Độc giả nên lưu tâm điều này.
Tip #1: Sử dụng Tên Cột thay vì * trong lệnh SELECT – Tips cần chú ý khi tự học SQL
Nếu bạn chỉ đang chọn một số ít cột từ bảng, không cần sử dụng lệnh SELECT *. Dù cách viết này dễ, nhưng lại gây tốn nhiều thời gian hơn để cơ sở dữ liệu có thể hoàn thành truy vấn. Bằng cách chỉ chọn những cột cần thiết, bạn đang giảm bớt kích cỡ của bảng kết quả, giảm lưu lượng mạng, và làm tăng hiệu năng của truy vấn.
Ví dụ:
Truy vấn gốc:
| 1 | SELECT* FROMSH.Sales; |
Truy vấn đã được cải thiện:
| 1 | SELECTs.prod_id FROMSH.sales s; |
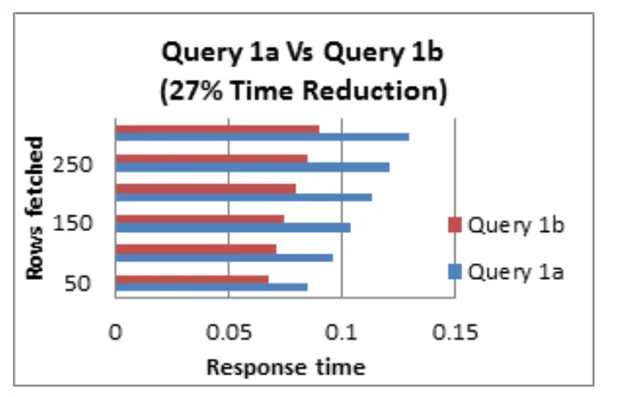
Tip #2: Tránh đưa mệnh đề HAVING trong lệnh SELECT
Tip thứ hai trong khi tự học SQL về tối ưu hóa lệnh truy vấn là mệnh đề HAVING có tác dụng lọc sau khi các hàng đã được chọn và được sử dụng như một filter. Mệnh đề này không có nhiều tác dụng với lệnh SELECT. Cách hoạt động của nó là quét qua bảng kết quả cuối cùng để phân tích và bỏ những hàng không đáp ứng điều kiện của mệnh đề HAVING.
Ví dụ:
Truy vấn gốc:
| 1234567 | SELECTs.cust_id,count(s.cust_id)FROMSH.sales sGROUPBYs.cust_idHAVINGs.cust_id != '1660'ANDs.cust_id != '2'; |
Truy vấn đã được cải thiện:
| 123456789 | SELECTs.cust_id,count(cust_id)FROMSH.sales sWHEREs.cust_id != '1660'ANDs.cust_id !='2'GROUPBYs.cust_id; |

Tip #3: Loại bỏ các mệnh đề DISTINCT không cần thiết – Tự học SQL
Khi xem xét ví dụ dưới đây, từ khóa DISTINCT trong truy vấn gốc là không cần thiết vì tên bảng đã chứa p.ID là khóa chính của bảng – đây là một phần của kết quả. Việc đưa mệnh dề DISTINCT sẽ khiến CSDL thực hiện thêm một phép so sánh để loại bỏ các dòng trùng nhau trong tập kết quả.
Ví dụ:
Truy vấn gốc:
| 1234567 | SELECTDISTINCT* FROMSH.sales sJOINSH.customers cONs.cust_id= c.cust_idWHEREc.cust_marital_status = 'single'; |
Truy vấn đã được cải thiện:
| 1234567 | SELECT* FROMSH.sales s JOINSH.customers cONs.cust_id = c.cust_idWHEREc.cust_marital_status='single'; |

- Xem thêm: Phân tích RFM trong SQL
Tip #4: Un-nest các truy vấn nội bộ (Sub-query)
Viết lại các sub-query sẽ giúp truy vấn chạy hiệu quả và tối ưu hơn. Nhìn chung, việc unnest các sub-query luôn được tiến hành với sub-query tương tác với tối đa một bảng từ mệnh đề FROM, được sử dụng trong các mệnh đề ANY, ALL, và EXISTS. Một sub-query không tương quan, hay một sub-query với nhiều hơn một bảng từ mệnh đề FROM, sẽ được làm phẳng nếu dựa theo ngữ cảnh của truy vấn đó.
Ví dụ:
Truy vấn gốc:
| 12345678910111213 | SELECT*FROMSH.products pWHEREp.prod_id =(SELECTs.prod_idFROMSH.sales sWHEREs.cust_id = 100996ANDs.quantity_sold = 1 ); |
Truy vấn đã được cải thiện:
| 123456789 | SELECTp.*FROMSH.products p, sales sWHEREp.prod_id = s.prod_idANDs.cust_id = 100996ANDs.quantity_sold = 1; |

Tip #5:Cân nhắc sử dụng mệnh đề IN khi truy vấn một cột đã được đánh index
Mệnh đề IN có thể được khai thác cho các lệnh truy vấn sử dụng bảng đã được đánh index, và đồng thời, công cụ tối ưu hóa có thể sắp xếp danh sách IN để khớp với thứ tự phân loại của chỉ số, dẫn tới lệnh truy vấn hiệu quả hơn. Do đó khi trong quá trình thực hành và tự học SQL, cần chú ý rằng danh sách IN chỉ được chứa các hàm, hoặc các giá trị là hằng số trong việc thực hiện khối truy vấn, ví dụ như các tham chiếu ngoài.
Ví dụ:
Truy vấn gốc:
| 1234567 | SELECTs.*FROMSH.sales sWHEREs.prod_id = 14ORs.prod_id = 17; |
Truy vấn đã cải thiện:
| 12345 | SELECTs.*FROMSH.sales sWHEREs.prod_id IN(14, 17) |
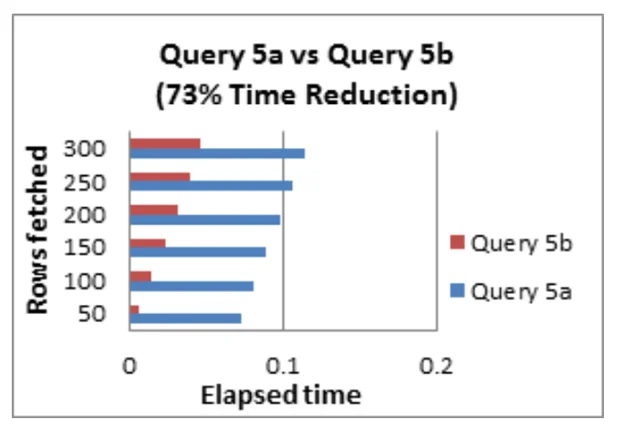
Tip #6:Sử dụng EXISTS thay cho DISTINCT khi kết nối các bảng có một hoặc nhiều liên kết.
Từ khóa DISTINCT có tác dụng chọn tất cả cột trong bảng, phân tích và lọc ra các cột bị trùng lặp. Thay vào đó, nếu bạn sử dụng sub-query với từ khóa EXISTS, bạn có thể tránh việc phải trả lại toàn bộ một bảng.
Ví dụ:
Truy vấn gốc:
| 12345 | SELECTDISTINCTc.country_id, c.country_nameFROMSH.countries c,SH.customers eWHEREe.country_id = c.country_id; |
Truy vấn đã được cải thiện:
| 1234567 | SELECTc.country_id, c.country_nameFROMSH.countries cWHEREEXISTS (SELECT'X'FROMSH.customers eWHEREe.country_id = c.country_id); |

Tip #7: Sử dụng UNION ALL thay cho UNION
Mệnh đề UNION ALL nhanh hơn UNION bỏi vì mệnh đề UNION ALL không tính tới các điểm trùng lập và mệnh đề UNION lại tìm các điểm trùng lặp trong bảng khi chọn hàng, dù có điểm trùng lặp hay không hãy ưu tiên sử dụng UNION ALL khi chúng ta biết chắc chắn mỗi dòng trong kết quả sẽ là duy nhất hoặc có thể chấp nhận việc trùng lặp.
Ví dụ:
Truy vấn gốc:
| 123456789 | SELECTcust_idFROMSH.salesUNIONSELECTcust_idFROMcustomers; |
Truy vấn đã cải thiện:
| 123456789 | SELECTcust_idFROMSH.salesUNIONALLSELECTcust_idFROMcustomers; |
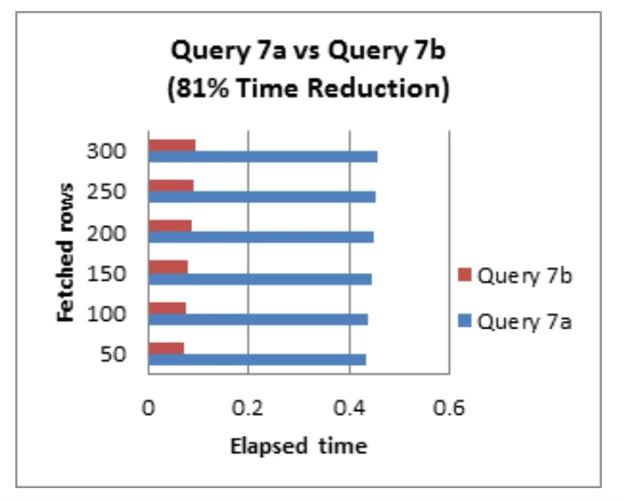
Tip #8:Tránh sử dụng OR trong các mệnh đề thỏa mãn nhiều điều kiện
Trong trường hợp khi bạn tự học SQL, mỗi khi bạn đặt ‘OR’ trong condition kết nối, truy vấn sẽ chậm đi ít nhất một hoặc hai thừa số
Ví dụ:
Truy vấn gốc
| 1234567 | SELECT*FROMSH.costs cINNERJOINSH.products p ONc.unit_price =p.prod_min_price ORc.unit_price = p.prod_list_price; |
Truy vấn đã cải thiên
| 1234567891011121314151617 | SELECT*FROMSH.costs cINNERJOINSH.products p ONc.unit_price =p.prod_min_priceUNIONALLSELECT*FROMSH.costs cINNERJOINSH.products p ONc.unit_price =p.prod_list_price; |
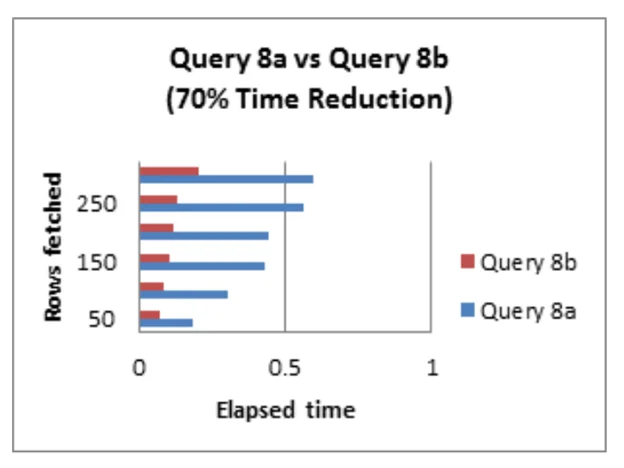
Tip #9:Tránh đặt hàm số bên phải của toán tử so sánh
Các hàm số hay phương pháp rất thường được sử dụng với truy vấn SQL tương ứng. Viết lại truy vấn bằng cách bỏ các hàm tổng hợp sẽ tăng hiệu suất đáng kế, đặc biệt với các cột đã được đánh index (chỉ mục).
Ví dụ:
Truy vấn gốc
| 1234567 | SELECT*FROMSH.salesWHEREEXTRACT (YEARFROMTO_DATE (time_id, ‘DDMON-RR’)) = 2001 ANDEXTRACT (MONTHFROMTO_DATE (time_id, ‘DD-MON-RR’)) =12; |
Truy vấn đã cải thiện:
| 123 | SELECT* FROMSH.salesWHERETRUNC (time_id) BETWEENTRUNC(TO_DATE(‘12/01/2001’, ’mm/dd/yyyy’)) ANDTRUNC (TO_DATE (‘12/30/2001’,’mm/dd/yyyy’)); |
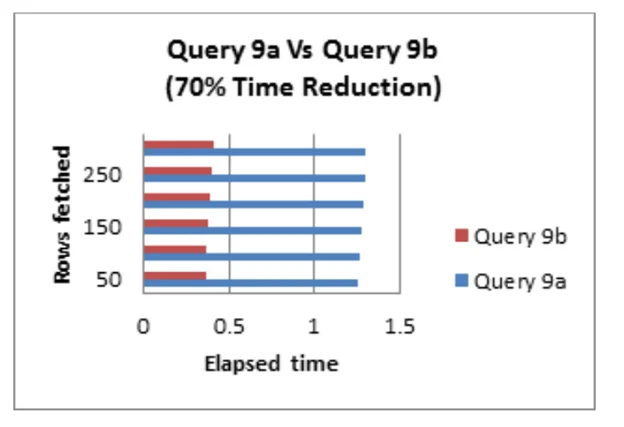
Tip #10:Loại bỏ các phép toán thừa
Khi làm hoặc tự học SQL, sẽ có lúc bạn thực hiện các phép toán trong một statement của SQL. Các phép toán có thể làm giảm hiệu suất đáng kể nếu cách viết không phù hợp. Mỗi lần truy vấn tìm thấy một hàng, nó sẽ thực hiện lại phép toán. Vì vậy, việc loại bỏ phép toán không cần thiết sẽ giúp truy vấn chạy nhanh hơn rất nhiều.
Ví dụ:
Truy vấn gốc:
| 12345 | SELECT*FROMSH.sales sWHEREs.cust_id + 10000 < 35000; |
Truy vấn đã cải thiện:
| 12345 | SELECT*FROMSH.sales sWHEREs.cust_id < 25000; |
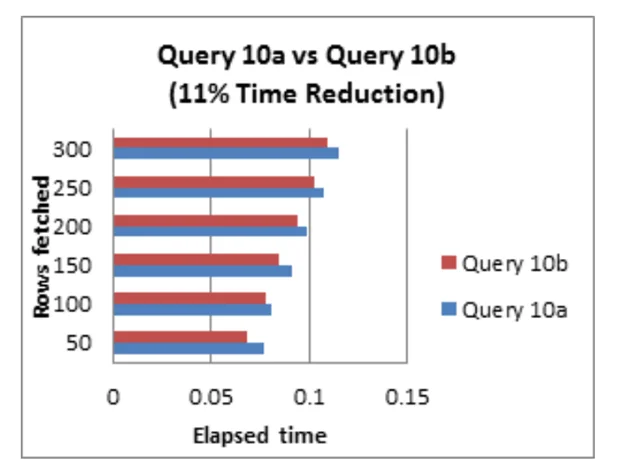
Tối ưu hóa truy vấn là một công việc phổ biến dành cho các quản trị viên cơ sở dữ liệu và người thiết kế ứng dụng để điều chỉnh hiệu quả chung của hệ thống cơ sở dữ liệu.
Mục đích của bài viết này là đưa ra các trường hợp trong SQL để cung cấp một tư liệu tham khảo nhanh chóng, dễ hiểu khi bạn tự học SQL. Ngay cả khi bạn có hạ tầng tốt, hiệu suất có thể suy giảm đáng kể do có các truy vấn thiếu hiệu quả.
Tối ưu hóa truy vấn SQL sẽ có ảnh hưởng rất lớn tới hiệu quả của DBMS, và hoạt động này sẽ tiếp tục phát triển với những chiến lược mới, phức tạp hơn dựa trên sự phát triển của các Database Engine mới, tối ưu hơn.
Vì vậy, chúng ta nên cố gắng làm theo các tip nói trên để truy vấn trở nên hiệu quả hơn. Chúng ta có thể tối ưu hóa mà không tốn quá nhiều công sức nếu thường xuyên thực hiện và tuân theo các nguyên tắc. Trọng tâm chính là tối ưu hóa truy vấn để đạt được hiệu suất cao nhất.
Do vậy, nếu bạn đang tự học SQL hãy lưu nhanh bài viết này để cải thiện kỹ năng và áp dụng nó vào giải quyết vấn đề của bạn một cách nhanh chóng nhé!
Nguồn: Internet
Chúng tôi chuyên cung cấp những khóa học về Phân tích dữ liệu, đăng ký ngay để nhận được tư vấn chi tiết lộ trình dành riêng cho bạn nhé!


