

Việc huấn luyện thành công một mô hình Machine Learning với độ chính xác cao thường được coi là đỉnh cao của một dự án dữ liệu. Tuy nhiên, sự thật là rất nhiều dự án AI tiềm năng đã “chết yểu” ngay sau bước này vì không thể bước ra khỏi môi trường thí nghiệm. Một mô hình nằm trên laptop của nhà khoa học dữ liệu là một mô hình vô dụng. Giá trị thực sự của AI chỉ bắt đầu khi nó được triển khai vào hệ thống sản xuất (Production), sẵn sàng nhận dữ liệu từ người dùng và trả về những dự đoán chính xác trong tích tắc.
Quá trình đưa mô hình từ file lưu trữ (như .pkl, .h5, hay .onnx) thành một dịch vụ hoạt động ổn định được gọi là Model Serving. Đây chính là “cây cầu” kết nối trí tuệ nhân tạo với thực tế kinh doanh, biến những dòng code phức tạp thành các tính năng hữu ích mà khách hàng có thể chạm vào. Bài viết này sẽ giúp bạn giải mã toàn bộ quy trình Model Serving, từ các phương pháp triển khai phổ biến đến những chiến thuật tối ưu hiệu suất cho hệ thống AI quy mô lớn.
Mục lục
1. Model Serving là gì?
Model Serving là quá trình triển khai một mô hình Machine Learning đã được huấn luyện vào môi trường Production để cung cấp các dự đoán dựa trên dữ liệu đầu vào. Trong hệ thống phần mềm hiện đại, Model Serving thường hoạt động như một dịch vụ độc lập, giao tiếp với các ứng dụng khác thông qua giao thức API hoặc tin nhắn.
Theo định nghĩa từ Google Cloud, mục tiêu của Model Serving không chỉ là chạy mô hình, mà còn là quản lý tài nguyên tính toán (CPU/GPU) sao cho việc dự báo diễn ra nhanh nhất với chi phí thấp nhất. Khi một người dùng mở ứng dụng Grab và nhận được thời gian dự kiến tài xế đến, đó chính là kết quả của một hệ thống Model Serving đang hoạt động ở phía sau.
2. Model Serving nằm ở đâu trong ML Pipeline?
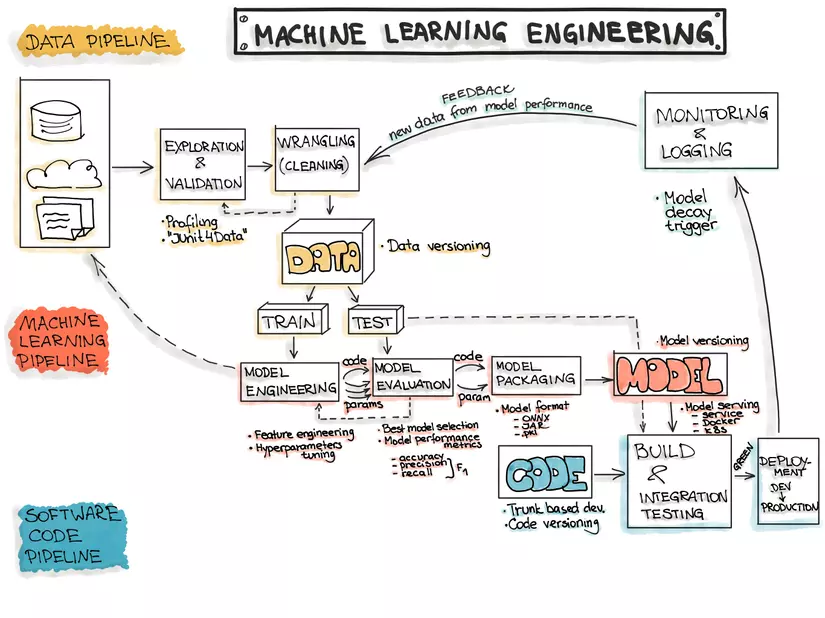
Để hiểu tầm quan trọng của Serving, chúng ta cần nhìn vào bức tranh tổng thể của một đường ống dữ liệu (ML Pipeline).
Sau khi dữ liệu được thu nạp, xử lý và mô hình đã được huấn luyện cũng như đánh giá (Evaluation), chúng ta sẽ có một “Model Artifact” – bản thiết kế của trí tuệ. Model Serving là bước kế tiếp, nơi chúng ta biến bản thiết kế này thành một thực thể có khả năng phản hồi. Nếu Ingestion cung cấp nguyên liệu, Training tạo ra bộ não, thì Serving chính là “miệng và tai” giúp mô hình giao tiếp với thế giới.
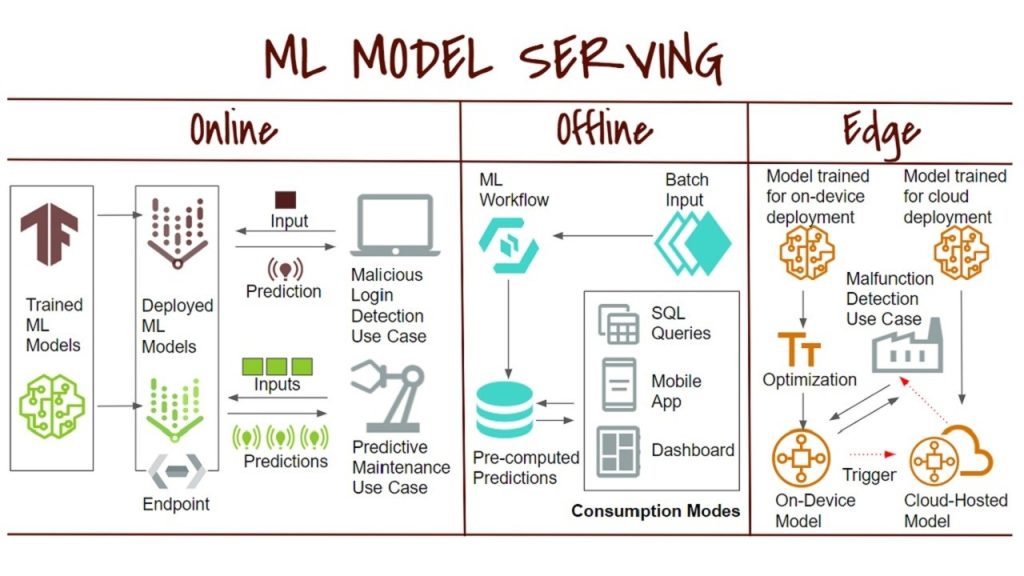
3. Các phương pháp Model Serving phổ biến hiện nay
Tùy thuộc vào bài toán kinh doanh, các kỹ sư sẽ lựa chọn cách thức phục vụ mô hình khác nhau. Không có phương pháp tốt nhất, chỉ có phương pháp phù hợp nhất với yêu cầu về thời gian và tài nguyên.
Batch Model Serving (Phục vụ theo lô)
Batch Serving là phương pháp thực hiện dự đoán trên một tập hợp dữ liệu lớn định kỳ (ví dụ: mỗi giờ, mỗi ngày).
- Cơ chế: Dữ liệu được gom lại thành các khối lớn, mô hình chạy một lần để dự đoán cho toàn bộ và lưu kết quả vào cơ sở dữ liệu.
- Ví dụ: Hệ thống ngân hàng dự đoán danh sách khách hàng có nguy cơ rời bỏ dịch vụ vào cuối mỗi ngày, hoặc dự báo nhu cầu kho bãi cho tuần kế tiếp.
- Ưu điểm: Đơn giản, không yêu cầu phản hồi tức thời, tối ưu hóa được hiệu suất tính toán khi xử lý số lượng lớn bản ghi cùng lúc.
Online Model Serving (Phục vụ thời gian thực)
Ngược lại với Batch, Online Serving đòi hỏi mô hình phải trả về kết quả ngay lập tức khi nhận được yêu cầu.
- Cơ chế: Mô hình được triển khai như một dịch vụ luôn luôn lắng nghe (thường qua REST hoặc gRPC). Khi người dùng thực hiện một hành động, ứng dụng gửi dữ liệu đến mô hình và nhận lại dự đoán trong mili giây.
- Ví dụ: Hệ thống phát hiện gian lận thẻ tín dụng (phải quyết định trong chưa đầy 1 giây), chatbot AI, hoặc hệ thống gợi ý sản phẩm của Shopee khi bạn vừa tìm kiếm một từ khóa.
- Ưu điểm: Mang lại trải nghiệm người dùng mượt mà, đáp ứng các yêu cầu thay đổi liên tục.
Bảng so sánh Batch Serving và Online Serving
| Tiêu chí | Batch Serving | Online Serving |
| Độ trễ (Latency) | Cao (Vài phút đến vài giờ) | Rất thấp (Vài mili giây) |
| Băng thông (Throughput) | Rất cao | Phụ thuộc vào hạ tầng |
| Độ phức tạp | Thấp | Cao |
| Tính sẵn sàng | Theo lịch trình | Luôn luôn sẵn sàng (24/7) |
4. Kiến trúc Model Serving tiêu chuẩn
Một hệ thống Model Serving chuyên nghiệp không chỉ bao gồm tệp mô hình mà còn là một hạ tầng phân tầng chặt chẽ để đảm bảo tính ổn định và khả năng mở rộng.
Các thành phần chính:
- API Layer: Thường là REST API hoặc gRPC, đóng vai trò tiếp nhận yêu cầu từ phía Client.
- Inference Engine: Trái tim của hệ thống, nơi thực hiện các phép toán đại số tuyến tính để đưa ra kết quả dự báo.
- Model Registry/Storage: Nơi quản lý các phiên bản mô hình khác nhau (v1.0, v2.0), cho phép kiểm soát và chuyển đổi giữa các phiên bản một cách an toàn.
5. Quy trình 4 bước triển khai Model Serving chuyên nghiệp
Để đưa một mô hình vào “thực chiến”, các kỹ sư MLOps thường tuân thủ quy trình nghiêm ngặt sau:
Bước 1: Packaging (Đóng gói mô hình)
Mô hình cần được đóng gói cùng với tất cả các thư viện phụ thuộc (dependencies). Xu hướng hiện đại là sử dụng Docker để tạo ra một “Container Image”. Điều này đảm bảo mô hình chạy ổn định trên bất kỳ máy chủ nào mà không gặp lỗi “thiếu thư viện”.
Bước 2: Deployment (Triển khai)
Sau khi có Image, chúng ta triển khai nó lên hạ tầng cloud hoặc server vật lý. Kubernetes thường được dùng ở bước này để tự động hóa việc mở rộng (scaling) số lượng server khi lượng truy cập tăng đột biến.
Bước 3: Cung cấp API dự đoán
Việc sử dụng gRPC thay vì REST truyền thống đang trở nên phổ biến trong Model Serving nhờ tốc độ truyền tải dữ liệu nhị phân cực nhanh, giúp giảm thiểu độ trễ tối đa cho các ứng dụng realtime.
Bước 4: Monitoring (Giám sát)
Sau khi “lên sóng”, mô hình cần được theo dõi chặt chẽ qua các chỉ số:
- Hạ tầng: CPU, RAM, Latency.
- Chất lượng: Độ chính xác có bị giảm theo thời gian không (Model Drift)? Dữ liệu người dùng gửi lên có khác biệt nhiều so với lúc huấn luyện không (Data Drift)?
6. Model Serving và mối liên kết với Feature Store
Trong thực tế, dữ liệu người dùng gửi lên thường rất sơ sài (ví dụ: chỉ có User_ID). Tuy nhiên, mô hình lại cần hàng trăm thông tin khác (như lịch sử mua hàng, điểm uy tín).
Đây là lúc Online Feature Store xuất hiện. Quy trình sẽ là:
- Ứng dụng gửi User_ID đến hệ thống Serving.
- Hệ thống Serving truy vấn Feature Store để lấy đầy đủ các đặc trưng (features) của người dùng đó.
- Mô hình thực hiện dự báo dựa trên tập dữ liệu đầy đủ.
Sự kết hợp này giúp đảm bảo tính nhất quán (Consistency) và tốc độ, vì các feature đã được tính toán sẵn và lưu trữ trong bộ nhớ tốc độ cao.
7. Những thách thức lớn trong Model Serving
Triển khai Model Serving không bao giờ là dễ dàng khi phải đối mặt với:
- Độ trễ (Latency): Với các mô hình Deep Learning lớn, việc xử lý có thể mất nhiều thời gian. Các kỹ sư phải sử dụng các kỹ thuật như Quantization (nén mô hình) để tăng tốc.
- Scalability (Khả năng mở rộng): Làm thế nào để hệ thống vẫn chạy tốt khi số lượng người dùng tăng từ 1.000 lên 1.000.000 trong đêm giao thừa?
- Versioning (Quản lý phiên bản): Khi có mô hình mới tốt hơn, làm sao để cập nhật mà không gây gián đoạn dịch vụ (Zero-downtime deployment)?
8. Các công cụ “quyền lực” hỗ trợ Model Serving
Hiện nay, bạn không cần phải tự xây dựng mọi thứ từ đầu. Có rất nhiều công cụ mạnh mẽ hỗ trợ:
- TensorFlow Serving: Tối ưu hóa tuyệt vời cho các mô hình của TensorFlow, hỗ trợ tốt gRPC.
- TorchServe: Giải pháp “chính chủ” từ AWS và PyTorch để phục vụ các mô hình Deep Learning.
- KServe (trước đây là KFServing): Một tiêu chuẩn phục vụ mô hình trên nền tảng Kubernetes, hỗ trợ đa dạng các framework (Scikit-learn, XGBoost, PyTorch…).
- BentoML: Một framework linh hoạt giúp đóng gói và tạo API cho mô hình một cách cực kỳ nhanh chóng.
9. Best Practices để tối ưu Model Serving
Để hệ thống AI của bạn đạt hiệu suất “đỉnh”, hãy áp dụng các nguyên tắc sau:
- Tách biệt môi trường: Không bao giờ chạy Serving trên cùng server với Training để tránh tranh chấp tài nguyên.
- Sử dụng Containerization: Luôn dùng Docker để đảm bảo tính nhất quán.
- Batching Requests: Nếu có thể, hãy gom các request lẻ tẻ lại thành một nhóm nhỏ để xử lý cùng lúc trên GPU nhằm tăng băng thông (Throughput).
- Cơ chế dự phòng (Fallback): Luôn có một logic đơn giản (ví dụ: trả về sản phẩm phổ biến nhất) nếu hệ thống Model Serving gặp sự cố.
Kết luận
Model Serving chính là chặng đua cuối cùng nhưng lại mang tính quyết định đến sự thành bại của một dự án Machine Learning. Một hệ thống serving được thiết kế tốt không chỉ mang lại dự đoán chính xác mà còn phải đảm bảo tốc độ, sự ổn định và khả năng phục hồi.
Trong kiến trúc AI hiện đại, Model Serving là một mắt xích không thể tách rời khỏi ML Pipeline, Feature Store và các nền tảng dữ liệu (Data Platforms). Đầu tư vào Model Serving chính là đầu tư vào giá trị thực tiễn mà AI mang lại cho con người.
INDA Academy tự hào là đơn vị tiên phong trong việc đào tạo phân tích dữ liệu và AI chuyên sâu, đặc biệt cho khối ngành Ngân hàng – Tài chính – Bảo hiểm tại Việt Nam. Sau hơn 12 năm “thực chiến” cùng những dòng chảy dữ liệu khổng lồ, chúng tôi đã xây dựng nên một hệ sinh thái đào tạo toàn diện, giúp hàng nghìn học viên chuyển mình từ người mới bắt đầu trở thành những chuyên gia lành nghề, sẵn sàng đáp ứng tiêu chuẩn khắt khe của các doanh nghiệp lớn.
Điểm khác biệt lớn nhất tại INDA chính là triết lý đào tạo dựa trên các dự án thực tế (Project-based) và lộ trình cá nhân hóa nhờ ứng dụng AI. Chúng tôi không chỉ dạy bạn cách sử dụng công cụ, mà còn truyền tải tư duy khai phá giá trị từ dữ liệu để đưa ra quyết định kinh doanh chính xác.
Tìm hiểu thêm về các khóa học TẠI ĐÂY:
Lộ trình đào tạo Data Engineer
Lộ trình đào tạo Data Analyst
Lộ trình đào tạo Tester
Khóa học Data Engineer nâng cao – Thực chiến 5 dự án doanh nghiệp
Khóa học Data Analyst nâng cao – Thực chiến 5 dự án doanh nghiệp

