

Để một hệ thống trí tuệ nhân tạo (AI) có thể đưa ra những dự báo chính xác hay nhận diện khuôn mặt trong tích tắc, nó cần một lượng dữ liệu khổng lồ. Tuy nhiên, dữ liệu này không tự dưng xuất hiện một cách ngăn nắp trong bộ não của máy tính. Chúng nằm rải rác ở khắp nơi: từ hành vi nhấp chuột của người dùng trên website, các giao dịch mua sắm trong cửa hàng, cho đến những tín hiệu từ thiết bị cảm biến IoT trong nhà máy.
Thách thức đầu tiên của mọi kiến trúc sư dữ liệu là làm sao gom tất cả “đống lộn xộn” đó về một nơi một cách an toàn và nhanh chóng.
Quá trình này được gọi là Data Ingestion (Thu nhận dữ liệu). Đây là cánh cửa đầu tiên mà mọi mẩu thông tin phải đi qua để bước vào thế giới của phân tích và học máy. Nếu ví dữ liệu là “máu” nuôi sống cơ thể AI, thì Data Ingestion chính là hệ thống mạch máu, đảm bảo dòng chảy thông tin luôn thông suốt và không bị tắc nghẽn. Bài viết này sẽ đi sâu vào cách thức Data Ingestion vận hành, các phương pháp thu nhận hiện đại và vai trò sống còn của nó trong một AI Data Platform chuyên nghiệp.
Mục lục
1. Data Ingestion là gì? Định nghĩa và bản chất
Về mặt kỹ thuật, Data Ingestion là quá trình thu thập và chuyển dữ liệu từ nhiều nguồn khác nhau vào một hệ thống lưu trữ trung tâm như Data Lake, Data Warehouse hoặc kiến trúc Lakehouse hiện đại.
Mục tiêu của quá trình này không chỉ đơn thuần là sao chép dữ liệu. Data Ingestion đóng vai trò như một bộ lọc và cầu nối, giúp:
- Tập hợp dữ liệu từ các nguồn không đồng nhất (Database, File, API).
- Đảm bảo dữ liệu được đưa vào hạ tầng lưu trữ theo một cấu trúc có thể kiểm soát được.
- Cung cấp “nguyên liệu thô” ổn định cho các giai đoạn xử lý dữ liệu và huấn luyện mô hình Machine Learning tiếp theo.
Trong một Data Pipeline hoàn chỉnh, Ingestion luôn là bước xuất phát điểm. Nếu bước này gặp lỗi hoặc dữ liệu bị thiếu hụt, toàn bộ các mô hình dự báo hạ nguồn sẽ trở nên vô dụng, giống như việc bạn cố gắng vận hành một chiếc xe đua với loại nhiên liệu lẫn nhiều tạp chất.
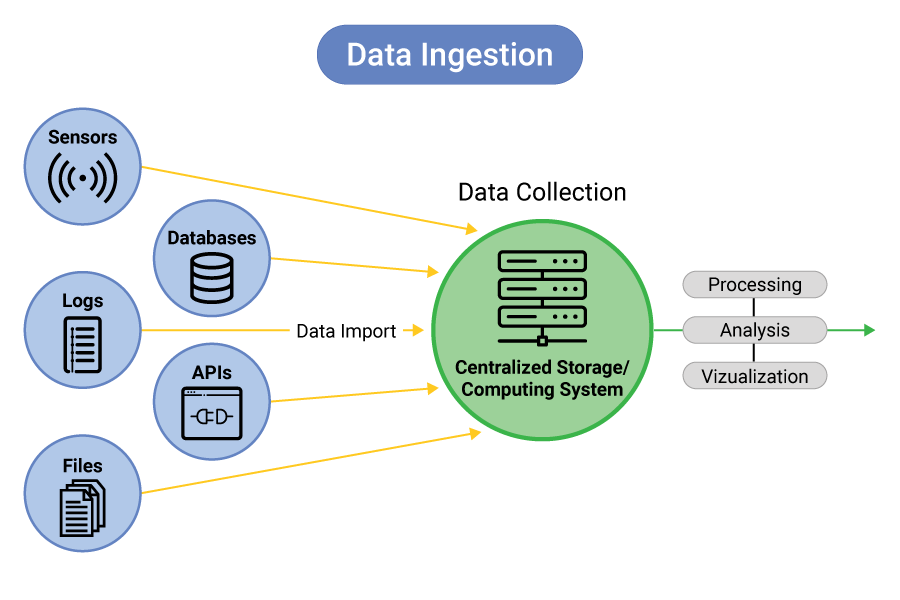
2. Vai trò của Data Ingestion trong hệ sinh thái AI
Trong một AI Data Platform, dữ liệu không đi thẳng từ nguồn vào mô hình AI mà phải trải qua một hành trình nghiêm ngặt:
Như sơ đồ trên minh họa, Ingestion Layer là “tiền tuyến”. Nó chịu trách nhiệm giao tiếp với thế giới bên ngoài. Một hệ thống thu nhận dữ liệu tốt sẽ giúp doanh nghiệp:
- Tránh mất mát dữ liệu: Đảm bảo không có bản ghi nào bị bỏ sót trong quá trình chuyển giao.
- Giảm tải cho nguồn: Thu thập dữ liệu sao cho không làm ảnh hưởng đến hiệu suất vận hành của các ứng dụng gốc (như website hay hệ thống thanh toán).
- Đáp ứng yêu cầu về thời gian: Một số mô hình AI cần dữ liệu ngay lập tức (như phát hiện gian lận thẻ tín dụng), yêu cầu Ingestion phải diễn ra trong mili giây.
3. Các nguồn dữ liệu “nuôi dưỡng” AI
Dữ liệu trong các hệ thống AI hiện nay không còn gói gọn trong các bảng tính Excel. Data Ingestion phải có khả năng xử lý đa dạng các loại nguồn:
| Nguồn dữ liệu | Ví dụ thực tế | Đặc điểm |
| Relational Database | SQL Server, MySQL, Oracle | Dữ liệu giao dịch, thông tin khách hàng. |
| Application Logs | Web logs, App event logs | Hành vi nhấp chuột, thời gian chờ của người dùng. |
| Dịch vụ API | Google Analytics, Facebook Ads | Dữ liệu marketing, xu hướng từ bên thứ ba. |
| Thiết bị IoT | Cảm biến nhiệt độ, GPS, Camera | Dữ liệu liên tục, tần suất cực cao. |
| File Storage | CSV, JSON, Parquet, Hình ảnh | Dữ liệu phi cấu trúc hoặc bán cấu trúc. |
Trong các hệ thống lớn, việc phải quản lý việc thu nhận từ hàng trăm nguồn dữ liệu khác nhau cùng lúc là một bài toán hóc búa về quản trị và băng thông.
4. Hai phương pháp Data Ingestion phổ biến nhất
Tùy vào nhu cầu về độ tươi (freshness) của dữ liệu, chúng ta có hai cách tiếp cận chính:
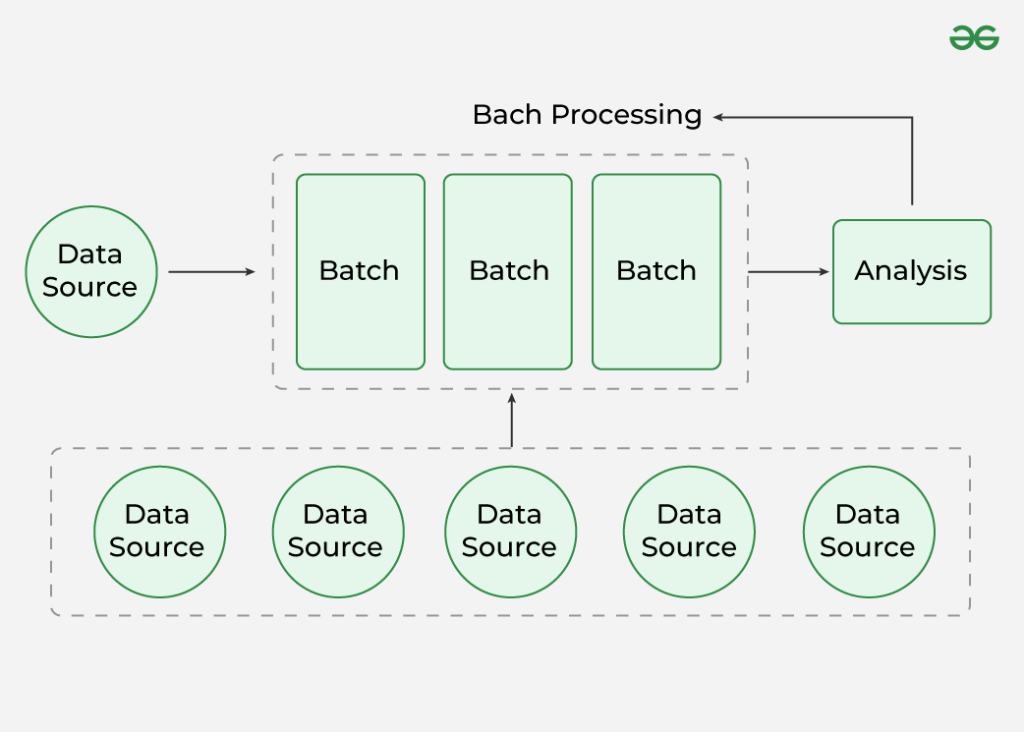
Batch Data Ingestion (Thu nhận theo lô)
Đây là phương pháp thu thập dữ liệu theo từng nhóm lớn tại những thời điểm nhất định trong ngày (ví dụ: cứ mỗi 4 tiếng hoặc vào lúc 2 giờ sáng).
- Ưu điểm: Đơn giản, dễ kiểm soát lỗi và tiết kiệm tài nguyên hạ tầng vì không cần hệ thống chạy 24/7.
- Hạn chế: Độ trễ cao. Nếu dữ liệu phát sinh lúc 8 giờ sáng nhưng đến 2 giờ sáng hôm sau mới được thu nhận, mô hình AI sẽ luôn “chậm chân” so với thực tế.
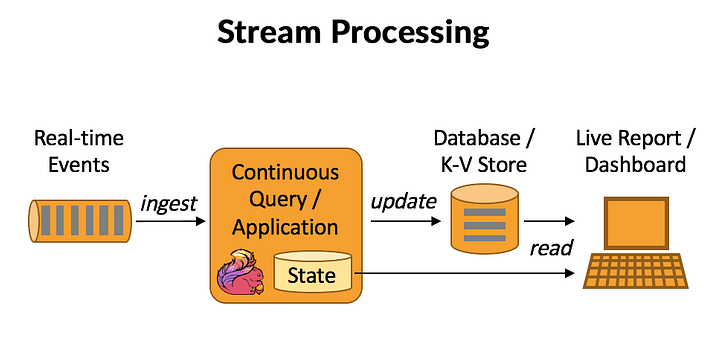
Streaming Data Ingestion (Thu nhận thời gian thực)
Đây là phương pháp thu nhận dữ liệu liên tục ngay khi chúng vừa mới phát sinh.
- Ưu điểm: Dữ liệu gần như là tức thời (Real-time). Đây là lựa chọn bắt buộc cho các hệ thống như đề xuất sản phẩm (Recommendation) hoặc cảnh báo an ninh.
- Hạn chế: Hệ thống cực kỳ phức tạp, yêu cầu hạ tầng chịu tải lớn và chi phí vận hành cao hơn hẳn so với Batch.
So sánh nhanh:
Batch Ingestion giống như việc bạn đợi đến cuối tuần mới đi siêu thị để mua đồ ăn cho cả tuần. Trong khi đó, Streaming Ingestion giống như việc bạn có một đường ống dẫn sữa trực tiếp từ nông trại vào tủ lạnh nhà mình – sữa luôn mới nhưng việc duy trì đường ống đó tốn kém hơn nhiều.
5. Kiến trúc Data Ingestion trong AI Data Platform
Trong một nền tảng dữ liệu hiện đại, lớp Ingestion không chỉ là một sợi dây nối. Nó là một hệ thống gồm nhiều tầng để đảm bảo tính ổn định.
Thông thường, kiến trúc này bao gồm:
- Ingestion Agents/Connectors: Các bộ kết nối chuyên dụng để “nói chuyện” với nguồn dữ liệu.
- Message Queue (Hàng đợi tin nhắn): Các công cụ như Apache Kafka đóng vai trò là “vùng đệm”. Nếu hệ thống lưu trữ phía sau bị chậm, dữ liệu sẽ được giữ tạm thời tại đây để không bị mất.
- Storage Layer: Nơi dữ liệu được đổ xuống, thường là lớp Bronze trong kiến trúc Medallion của Lakehouse. Tại đây, dữ liệu vẫn giữ nguyên trạng thái thô để phục vụ mục đích kiểm toán sau này.
6. Data Ingestion trong thế giới Lakehouse
Nếu bạn đang xây dựng một hệ thống dữ liệu theo mô hình Lakehouse, Data Ingestion sẽ đóng vai trò là người gác cổng cho lớp Bronze. Quy trình này diễn ra như sau:
- Ingestion: Thu thập dữ liệu từ CRM, IoT, Logs.
- Bronze Layer: Lưu trữ dữ liệu thô dưới định dạng Parquet hoặc Delta Lake. Dữ liệu ở đây chưa được làm sạch, đôi khi còn sai định dạng hoặc trùng lặp.
- Chuyển đổi hạ nguồn: Từ Bronze, các pipeline xử lý sẽ lọc dữ liệu để đưa lên tầng Silver (đã làm sạch) và Gold (sẵn sàng cho báo cáo/AI).
Việc tách biệt Ingestion thành một lớp riêng cho tầng Bronze giúp các kỹ sư dữ liệu có thể “quay ngược thời gian” để xử lý lại dữ liệu nếu phát hiện ra lỗi ở các tầng phía trên mà không cần phải kết nối lại với nguồn gốc.
7. Các công cụ “quyền lực” trong làng Data Ingestion
Để xây dựng một pipeline thu nhận mạnh mẽ, các kỹ sư thường tin dùng các công cụ sau:
- Apache Kafka: Ông vua trong mảng Streaming Ingestion, có khả năng xử lý hàng triệu tin nhắn mỗi giây.
- Airbyte / Fivetran: Các công cụ hiện đại giúp tự động hóa việc thu nhận dữ liệu từ các ứng dụng SaaS và Database chỉ với vài cú nhấp chuột.
- Apache NiFi: Một công cụ mạnh mẽ để quản lý dòng chảy dữ liệu (data flow) với giao diện trực quan.
- Apache Flink: Không chỉ thu nhận, Flink còn cho phép xử lý dữ liệu ngay trên đường đi (Stream Processing) trước khi đổ vào kho lưu trữ.
8. Những thách thức “đau đầu” khi triển khai
Dù nghe có vẻ đơn giản là “chuyển dữ liệu từ A sang B”, nhưng thực tế lại phức tạp hơn nhiều:
- Bùng nổ khối lượng dữ liệu (Data Volume): Làm sao để thu nhận hàng Terabyte dữ liệu mỗi ngày mà không làm sập mạng lưới nội bộ?
- Chất lượng dữ liệu (Data Quality): Dữ liệu từ nguồn có thể bị hỏng hoặc thiếu trường thông tin. Hệ thống Ingestion cần có cơ chế cảnh báo sớm.
- Thay đổi cấu trúc (Schema Evolution): Một ngày đẹp trời, team phát triển ứng dụng thêm một cột mới vào Database. Nếu hệ thống Ingestion không linh hoạt, toàn bộ pipeline sẽ bị gãy.
- Bảo mật: Dữ liệu trong quá trình di chuyển phải được mã hóa để tránh rò rỉ thông tin nhạy cảm của khách hàng.
9. Best Practices để xây dựng Ingestion Pipeline “bất bại”
Để hệ thống AI của bạn luôn có “máu sạch”, hãy tuân thủ các nguyên tắc vàng sau:
- Thiết kế để mở rộng: Hãy chọn các công cụ có khả năng mở rộng ngang (Scale-out) để khi dữ liệu tăng gấp 10 lần, bạn chỉ cần thêm máy chủ thay vì viết lại code.
- Giám sát 24/7: Phải có Dashboard theo dõi lưu lượng dữ liệu. Nếu dòng chảy bị ngắt, bạn cần biết ngay lập tức.
- Quản lý Schema chặt chẽ: Sử dụng các công cụ như Schema Registry để đảm bảo dữ liệu đầu vào luôn đúng định dạng.
- Tách biệt Batch và Streaming: Đừng cố dùng một công cụ cho mọi mục đích. Hãy dùng Kafka cho streaming và Airbyte cho batch để đạt hiệu suất tối ưu nhất.
Kết luận
Data Ingestion không chỉ là một bước kỹ thuật, nó là nền tảng của niềm tin trong hệ thống AI. Một nền tảng thu nhận dữ liệu vững chắc sẽ giúp doanh nghiệp tự tin triển khai các mô hình Machine Learning phức tạp mà không lo ngại về vấn đề thiếu hụt hay sai lệch thông tin.
Trong các hệ thống AI hiện đại, Data Ingestion thường được kết hợp chặt chẽ với Lakehouse Architecture và Medallion Architecture để tạo nên một quy trình xử lý dữ liệu khép kín, minh bạch và hiệu quả.
INDA Academy tự hào là đơn vị tiên phong trong việc đào tạo phân tích dữ liệu và AI chuyên sâu, đặc biệt cho khối ngành Ngân hàng – Tài chính – Bảo hiểm tại Việt Nam. Sau hơn 12 năm “thực chiến” cùng những dòng chảy dữ liệu khổng lồ, chúng tôi đã xây dựng nên một hệ sinh thái đào tạo toàn diện, giúp hàng nghìn học viên chuyển mình từ người mới bắt đầu trở thành những chuyên gia lành nghề, sẵn sàng đáp ứng tiêu chuẩn khắt khe của các doanh nghiệp lớn.
Điểm khác biệt lớn nhất tại INDA chính là triết lý đào tạo dựa trên các dự án thực tế (Project-based) và lộ trình cá nhân hóa nhờ ứng dụng AI. Chúng tôi không chỉ dạy bạn cách sử dụng công cụ, mà còn truyền tải tư duy khai phá giá trị từ dữ liệu để đưa ra quyết định kinh doanh chính xác.
Tìm hiểu thêm về các khóa học TẠI ĐÂY:
Lộ trình đào tạo Data Engineer
Lộ trình đào tạo Data Analyst
Lộ trình đào tạo Tester
Khóa học Data Engineer nâng cao – Thực chiến 5 dự án doanh nghiệp
Khóa học Data Analyst nâng cao – Thực chiến 5 dự án doanh nghiệp
