

Trong suốt một thập kỷ qua, ngành công nghệ dữ liệu đã nỗ lực thực hiện một cuộc “hôn nhân” đầy tham vọng giữa Data Lake và Data Warehouse để tạo ra khái niệm Lakehouse. Mục tiêu tối thượng là hợp nhất sự linh hoạt của hồ dữ liệu với cấu trúc chặt chẽ của kho dữ liệu. Tuy nhiên, khi cơn bão Trí tuệ nhân tạo tạo sinh (Generative AI) đổ bộ, giới chuyên gia nhận ra rằng mô hình Lakehouse truyền thống vẫn tồn tại một lỗ hổng chí tử: AI vẫn bị coi là một thực thể tách biệt, nằm bên ngoài “bức tường thành” của nền tảng dữ liệu.
Sự ra đời của Autonomous AI Lakehouse không chỉ đơn thuần là việc thêm hậu tố “AI” vào một thuật ngữ cũ. Đây là nỗ lực mang tính cách mạng nhằm định nghĩa lại nền tảng dữ liệu hiện đại, chuyển dịch từ một nơi chỉ để “hợp nhất lưu trữ” sang một “môi trường thực thi trí tuệ” tự vận hành.
Mục lục
1. Từ Lakehouse 1.0 đến Autonomous AI Lakehouse: Sự tiến hóa tất yếu
Để hiểu rõ giá trị của kiến trúc mới, chúng ta cần nhìn lại những hạn chế của mô hình Lakehouse 1.0. Trong cấu trúc cũ, mặc dù dữ liệu đã được gom về một nơi, nhưng AI vẫn là một “vị khách” ngoại lai. Mỗi khi cần huấn luyện mô hình hay triển khai ứng dụng RAG (Retrieval-Augmented Generation), các kỹ sư vẫn phải thực hiện quy trình trích xuất và vận chuyển dữ liệu phức tạp.
Việc di chuyển dữ liệu (Data Movement) tạo ra những rào cản lớn:
- Độ trễ (Latency): Dữ liệu không thể phục vụ AI ngay lập tức do tốn thời gian vận chuyển.
- Chi phí ẩn: Phí băng thông và tài nguyên tính toán để duy trì các đường ống ETL cồng kềnh.
- Rủi ro bảo mật: Khi dữ liệu rời khỏi hệ thống quản trị gốc, lớp bảo mật thường bị suy yếu.
Autonomous AI Lakehouse giải quyết bài toán này bằng triết lý “Bring AI to Data”. Thay vì bắt dữ liệu phải chu du đến với AI, Oracle đã mang trí tuệ nhân tạo đặt ngay tại nơi dữ liệu sinh sống, biến nền tảng lưu trữ thành một thực thể có khả năng tự suy luận và hành động.

2. Giải phẫu kiến trúc đa tầng của Autonomous AI Lakehouse
Một hệ thống Autonomous AI Lakehouse chuẩn mực không được xây dựng như một khối hộc mà là sự giao thoa giữa AI, Analytics và Data Platform. Kiến trúc này được thiết kế dựa trên các lớp logic chặt chẽ:
Tầng lưu trữ mở và sức mạnh của Apache Iceberg
Nền móng của hệ thống là tầng lưu trữ dựa trên định dạng mở Apache Iceberg. Đây là “ngôn ngữ chung” giúp dữ liệu duy trì tính linh hoạt:
- Tính mở: Không bị bó buộc vào một nhà cung cấp cụ thể (No vendor lock-in).
- Hiệu năng: Quản lý metadata thông minh giúp truy vấn trên tệp tin giá rẻ với tốc độ của kho dữ liệu cao cấp.
- Tính nhất quán: Hỗ trợ giao dịch ACID, đảm bảo dữ liệu không bị lỗi khi nhiều engine cùng truy cập.
Tầng truy cập hợp nhất (Unified Access)
Phía trên tầng lưu trữ là Unified Data Catalog — được ví như một “bản đồ tri thức” toàn diện. Tầng này xóa bỏ ranh giới giữa kho và hồ dữ liệu:
- Cung cấp một cái nhìn duy nhất cho toàn bộ tài sản dữ liệu từ SQL đến CSV thô.
- Người dùng chỉ cần dùng SQL tiêu chuẩn để truy vấn xuyên suốt các đám mây (Multicloud).
- Phá bỏ các “ốc đảo dữ liệu” (Data Silos) trong doanh nghiệp.
Tầng thực thi AI bản địa (Built-in AI)
Đây là “trái tim” tạo nên sự khác biệt. Thay vì cài đặt thêm các giải pháp rời rạc, Oracle tích hợp sẵn các năng lực AI vào tầng lõi:
- Vector Search: Tìm kiếm ngữ nghĩa trực tiếp bằng ngôn ngữ tự nhiên.
- ML in-database: Chạy các mô hình dự báo trực tiếp bằng SQL hoặc Python ngay trên dữ liệu gốc.
- Agentic AI: Các AI Agent tự động đọc hiểu dữ liệu và thực hiện hành động nghiệp vụ mà không cần can thiệp thủ công.
3. Những năng lực cốt lõi định nghĩa tương lai dữ liệu
Autonomous AI Lakehouse mang lại những năng lực đặc thù giúp doanh nghiệp tối ưu hóa nguồn tài nguyên quý giá nhất của mình:
- Autonomous Operations (Tự vận hành): Hệ thống tự động vá lỗi, tự động mở rộng và tự tối ưu hóa các chỉ mục (indexes). Điều này giúp giảm 80% công việc quản trị thủ công.
- Multicloud by Design: Khả năng truy vấn dữ liệu đồng thời trên OCI, AWS, Azure. Dữ liệu của bạn ở đâu, AI Lakehouse có mặt ở đó để xử lý tại chỗ.
- Unified Analytics: Một nền tảng duy nhất xử lý mọi loại dữ liệu (Structured, Unstructured) cho mọi nhu cầu từ báo cáo đến học máy.
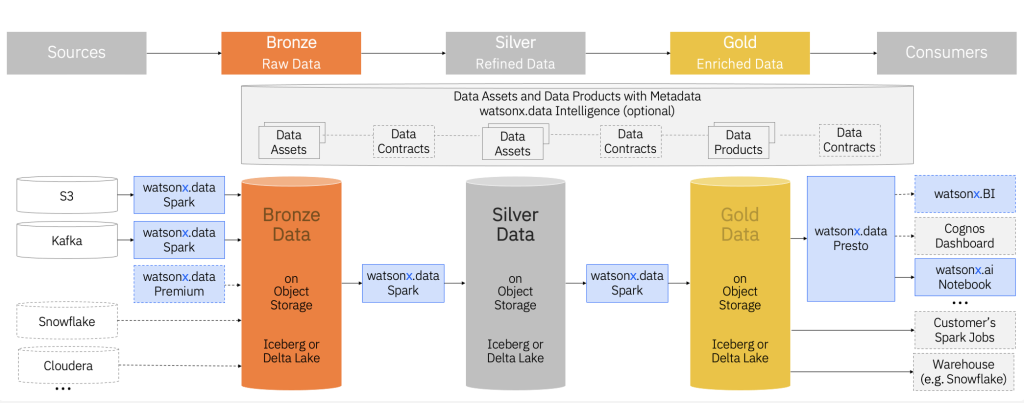
4. Mô hình Medallion trong kỷ nguyên AI Lakehouse
Để quản trị chất lượng dữ liệu, mô hình Medallion (Huy chương) được áp dụng để phân tách các giai đoạn tinh lọc dữ liệu:
- Lớp Bronze (Raw Data): Lưu trữ dữ liệu nguyên bản, bất biến. Đây là nguồn sự thật để tái xử lý dữ liệu khi cần.
- Lớp Silver (Validated Data): AI bản địa bắt đầu làm sạch, chuẩn hóa schema và loại bỏ dữ liệu rác. Đây là nơi các Data Scientist huấn luyện mô hình.
- Lớp Gold (Enriched Data): Dữ liệu đã được làm giàu bằng thuật toán AI, sẵn sàng cho báo cáo BI hoặc làm ngữ cảnh cho ứng dụng GenAI qua kỹ thuật RAG.
Quá trình dịch chuyển giữa các lớp này diễn ra tự động, giúp rút ngắn thời gian từ dữ liệu thô đến giá trị kinh doanh từ hàng tháng xuống còn hàng giờ.
5. Kịch bản thực chiến: Từ lý thuyết đến giá trị thực tế
Hãy xem xét kịch bản trong ngành ngân hàng: Khi một giao dịch đáng ngờ diễn ra, hệ thống AI Lakehouse không chỉ kiểm tra số dư. Nó thực hiện truy vấn vector so sánh hành vi này với hàng tỷ bản ghi lịch sử trên hồ dữ liệu để tìm ra mẫu gian lận chỉ trong vài mili giây mà không cần di chuyển dữ liệu.
Trong dịch vụ khách hàng, doanh nghiệp có thể dùng tính năng Select AI. Nhân viên chỉ cần hỏi: “Tại sao khách hàng khu vực miền Bắc có xu hướng rời bỏ dịch vụ?”. Hệ thống sẽ quét qua hàng triệu tài liệu PDF thô trên hồ dữ liệu và trả về câu trả lời chính xác kèm dẫn chứng, giúp ban lãnh đạo ra quyết định kịp thời.
6. Lựa chọn chiến lược: Sự đánh đổi giữa tối ưu và linh hoạt
Mặc dù vượt trội, nhưng triển khai Autonomous AI Lakehouse cần sự cân nhắc kỹ lưỡng về các yếu tố đánh đổi (Trade-offs):
- Ưu điểm: Giảm tối đa độ phức tạp hạ tầng, bảo mật tuyệt đối và hiệu năng cực cao do không di chuyển dữ liệu.
- Hạn chế: Sự phụ thuộc hệ sinh thái (Vendor Lock-in) vào Oracle để tận hưởng tính năng tự vận hành. Ngoài ra, chi phí có thể là rào cản với các startup có nhu cầu dữ liệu đơn giản.
7. Kết luận: Tương lai thuộc về Data-centric AI
Kỷ nguyên xây dựng AI tách biệt với dữ liệu đang dần khép lại. Oracle đã gửi thông điệp mạnh mẽ: AI không phải là đích đến, nó là khả năng nền tảng phải hiện diện ngay tại nơi dữ liệu sinh ra. Autonomous AI Lakehouse không chỉ tiết kiệm chi phí mà còn tạo ra môi trường tốc độ để dữ liệu thực sự biết “suy luận”. Tương lai thuộc về những doanh nghiệp biết biến hồ dữ liệu thành thực thể sống động, nơi tri thức và dữ liệu hòa làm một.
FAQ: Những câu hỏi thường gặp
1. Autonomous AI Lakehouse có thay thế hoàn toàn Data Warehouse không?
Nó bao hàm và nâng cấp năng lực của Warehouse, cho phép xử lý cả báo cáo truyền thống lẫn AI hiện đại trên một nền tảng duy nhất.
2. Tôi có cần dùng ETL để sử dụng AI không?
Không bắt buộc. Bạn có thể thực thi các mô hình AI trực tiếp trên dữ liệu thô ở hồ dữ liệu (Object Storage) mà không cần nạp vào Database.
3. Làm sao để tránh bị khóa vào nhà cung cấp?
Nhờ hỗ trợ Apache Iceberg, dữ liệu của bạn luôn ở định dạng mở tiêu chuẩn. Bạn có thể dùng các công cụ khác để đọc dữ liệu này, đảm bảo tính linh hoạt lâu dài.
INDA Academy tự hào là đơn vị tiên phong trong việc đào tạo phân tích dữ liệu và AI chuyên sâu, đặc biệt cho khối ngành Ngân hàng – Tài chính – Bảo hiểm tại Việt Nam. Sau hơn 12 năm “thực chiến” cùng những dòng chảy dữ liệu khổng lồ, chúng tôi đã xây dựng nên một hệ sinh thái đào tạo toàn diện, giúp hàng nghìn học viên chuyển mình từ người mới bắt đầu trở thành những chuyên gia lành nghề, sẵn sàng đáp ứng tiêu chuẩn khắt khe của các doanh nghiệp lớn.
Điểm khác biệt lớn nhất tại INDA chính là triết lý đào tạo dựa trên các dự án thực tế (Project-based) và lộ trình cá nhân hóa nhờ ứng dụng AI. Chúng tôi không chỉ dạy bạn cách sử dụng công cụ, mà còn truyền tải tư duy khai phá giá trị từ dữ liệu để đưa ra quyết định kinh doanh chính xác.
Tìm hiểu thêm về các khóa học TẠI ĐÂY:
Lộ trình đào tạo Data Engineer
Lộ trình đào tạo Data Analyst
Lộ trình đào tạo Tester
Khóa học Data Engineer nâng cao – Thực chiến 5 dự án doanh nghiệp
Khóa học Data Analyst nâng cao – Thực chiến 5 dự án doanh nghiệp
Bài viết liên quan:
 Lakehouse Query Engine: “Bộ não” quyết định hiệu năng hệ thống dữ liệu 2026
Lakehouse Query Engine: “Bộ não” quyết định hiệu năng hệ thống dữ liệu 2026
 Delta Lake vs Iceberg vs Hudi: So sánh chi tiết Table Format cho Data Lakehouse 2026
Delta Lake vs Iceberg vs Hudi: So sánh chi tiết Table Format cho Data Lakehouse 2026
 Data Lake vs Data Warehouse vs Lakehouse: Phân tích chiến lược kiến trúc dữ liệu toàn diện 2026
Data Lake vs Data Warehouse vs Lakehouse: Phân tích chiến lược kiến trúc dữ liệu toàn diện 2026
 Data Lakehouse vs Data Warehouse: Kiến trúc nào là “xương sống” cho doanh nghiệp 2026?
Data Lakehouse vs Data Warehouse: Kiến trúc nào là “xương sống” cho doanh nghiệp 2026?
 Phân biệt Database, Data Warehouse, Data Mart, Data Lake và kiến trúc dữ liệu hiện đại (Cập nhật 2026)
Data Lakehouse là gì? Kiến trúc, lợi ích và khi nào doanh nghiệp nên áp dụng (Cập nhật 2026)
Phân biệt Database, Data Warehouse, Data Mart, Data Lake và kiến trúc dữ liệu hiện đại (Cập nhật 2026)
Data Lakehouse là gì? Kiến trúc, lợi ích và khi nào doanh nghiệp nên áp dụng (Cập nhật 2026)