

Trong quản trị dữ liệu, có một nghịch lý luôn tồn tại: Hệ thống càng hiện đại, dữ liệu càng khó tin. Một buổi sáng, Dashboard báo cáo doanh thu bỗng dưng sụt giảm 30% mà không rõ lý do. Đội ngũ kỹ thuật nháo nhào kiểm tra hàng trăm script ETL và hàng nghìn bảng dữ liệu đan xen nhưng không tìm thấy điểm gãy. Đó không phải là một sự cố kỹ thuật thông thường; đó là một cuộc khủng hoảng vận hành khi hệ thống dữ liệu của bạn đã trở thành một “hộp đen” (black box) hoàn toàn mất kiểm soát.
Nếu bạn không thể trả lời ngay lập tức câu hỏi: “Con số này thực chất đến từ đâu và đã bị nhào nặn bởi những logic nào?”, thì nền tảng Analytics của doanh nghiệp đang đứng trên một nền cát lún. Data Lineage (Truy vết dữ liệu) sinh ra để chấm dứt sự mơ hồ đó. Nó không đơn thuần là một sơ đồ kỹ thuật; nó là “bản đồ gene” ghi lại mọi biến đổi, mọi điểm dừng và mọi mối quan hệ của dữ liệu từ khi còn là những bản ghi thô cho đến khi trở thành thông tin chiến lược trên bàn làm việc của Ban lãnh đạo.
Mục lục
1. Data Lineage là gì? Định nghĩa sự minh bạch tuyệt đối trong Data Engineering
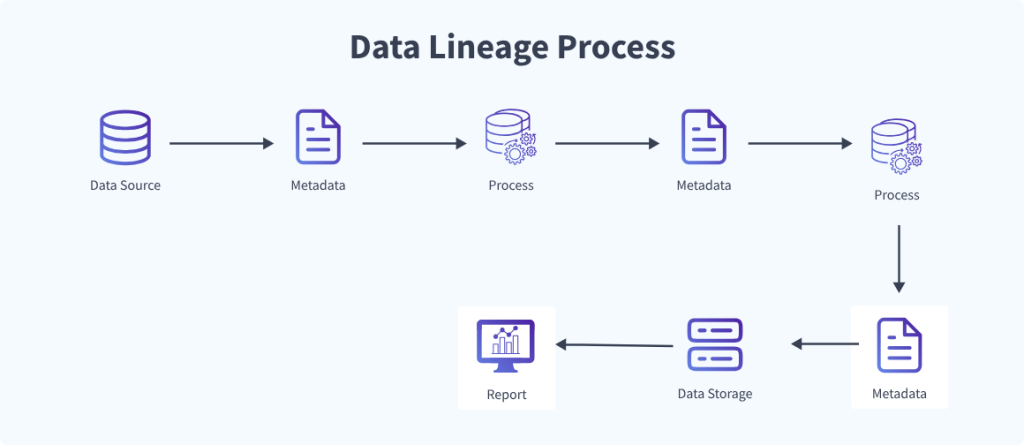
Nói một cách thực dụng, Data Lineage là khả năng quan sát và ghi lại toàn bộ vòng đời của dữ liệu. Nó cho phép chúng ta nhìn thấu hành trình di chuyển qua các giai đoạn: Ingestion (Nạp), Transformation (Biến đổi), và Consumption (Tiêu thụ).
Nếu coi Data Pipeline là một dây chuyền sản xuất khổng lồ, thì Data Lineage chính là hệ thống camera giám sát thông minh đặt tại từng công đoạn. Nó cho chúng ta biết:
- Nguồn gốc (Source): Dữ liệu được trích xuất từ đâu? (Cơ sở dữ liệu giao dịch OLTP, cổng API bên thứ ba, các tệp log phẳng hay các sự kiện streaming thời gian thực).
- Quá trình nhào nặn (Transformation): Những phép toán SQL nào đã được áp dụng? Có bước kết hợp (Join), lọc (Filter) hay tổng hợp (Aggregation) nào làm thay đổi bản chất dữ liệu không?
- Điểm đến cuối cùng (Destination): Những Dashboard, báo cáo Power BI, Tableau hay các mô hình Machine Learning nào đang trực tiếp “nuôi sống” bởi dataset này?
Sự khác biệt lớn nhất giữa Data Lineage và các loại tài liệu dữ liệu khác chính là tính liên kết động. Trong khi Data Catalog giúp bạn biết bạn đang có gì, thì Data Lineage cho bạn biết mọi thứ liên quan đến nhau như thế nào.

2. Vì sao Data Lineage là “xương sống” của một Data Platform hiện đại?
Khi hệ thống dữ liệu phát triển từ vài chục lên hàng nghìn pipeline, việc quản lý thủ công là điều bất khả thi. Data Lineage mang lại những giá trị mang tính sống còn cho doanh nghiệp:
2.1. Tăng tốc độ xử lý sự cố (Root Cause Analysis)
Đây là giá trị dễ thấy nhất. Khi một chỉ số trên báo cáo bị sai lệch, thay vì phải rà soát thủ công hàng vạn dòng code trong mù quáng, Data Engineer chỉ cần nhìn vào sơ đồ Lineage. Hệ thống sẽ hiển thị ngay mắt xích nào bị lỗi, bảng nào chưa được cập nhật dữ liệu mới nhất (Stale data) hoặc một logic tính toán vừa bị thay đổi vào đêm qua gây ra lỗi dây chuyền.
2.2. Phân tích tác động (Impact Analysis) – “Bùa hộ mệnh” cho kỹ sư
Hãy tưởng tượng bạn chuẩn bị xóa một cột “cũ” trong database vì nghĩ không ai dùng. Nếu không có Lineage, bạn đang chơi trò “cò quay Nga” với hệ thống. Với Lineage, bạn sẽ biết ngay rằng việc xóa cột đó sẽ làm sập 3 báo cáo tài chính và 1 mô hình dự báo kho vận. Khả năng dự báo này giúp giảm thiểu tối đa rủi ro vận hành khi thực hiện các thay đổi (Change Management).
2.3. Đảm bảo tính tuân thủ và Kiểm toán (Compliance & Audit)
Trong các ngành nhạy cảm như Tài chính, Ngân hàng hay Y tế, việc chứng minh nguồn gốc dữ liệu là yêu cầu bắt buộc của pháp luật (như GDPR, HIPAA). Data Lineage cung cấp một hồ sơ kiểm soát minh bạch, cho biết dữ liệu khách hàng nhạy cảm đã được xử lý ở đâu, qua những môi trường nào và ai có quyền tiếp cận.
2.4. Xây dựng văn hóa dựa trên dữ liệu (Data Trust)
Người dùng kinh doanh thường có tâm lý nghi ngờ số liệu khi thấy sự mâu thuẫn giữa các phòng ban. Một sơ đồ Lineage trực quan là bằng chứng thép để giải thích một cách thuyết phục: “Con số này được lấy từ nguồn A, đã qua bước kiểm duyệt chuẩn hóa ở B”, giúp xóa bỏ mọi sự mơ hồ và củng cố niềm tin vào hệ thống Analytics chung.
3. Các cấp độ của Data Lineage: Từ vĩ mô đến vi mô
Để triển khai Data Lineage thành công, doanh nghiệp cần hiểu rõ các tầng không gian mà nó bao phủ:
3.1. Table-Level Lineage (Cấp độ bảng)
Đây là mức độ cơ bản và phổ biến nhất, hiển thị mối quan hệ giữa các dataset lớn. Bạn sẽ thấy dữ liệu chảy từ lớp Raw (Bronze) sang lớp Staging (Silver) và kết thúc ở các bảng Analytics (Gold). Cấp độ này giúp các quản lý dữ liệu có cái nhìn tổng thể về kiến trúc hạ tầng.
3.2. Column-Level Lineage (Cấp độ cột)
Đây là cấp độ “nội soi” sâu nhất và cũng khó triển khai nhất. Nó cho biết chính xác cột Net_Profit ở bảng đích thực chất là kết quả của phép toán (Price * Quantity) – Discount lấy từ ba bảng nguồn khác nhau. Cấp độ này là vũ khí tối thượng để các kỹ sư debug các lỗi logic cực kỳ phức tạp.
3.3. End-to-End Lineage (Toàn diện)
Sự kết nối xuyên suốt từ “điểm đầu” (hệ thống nguồn CRM/ERP) qua các công cụ ETL, qua Data Warehouse, đến tận lớp hiển thị (BI Tools). Chỉ khi đạt được cấp độ này, doanh nghiệp mới thực sự sở hữu một bản đồ dữ liệu hoàn chỉnh.
4. Kiến trúc Data Lineage trong một Modern Data Platform chuyên nghiệp
Hệ thống truy vết không hoạt động độc lập mà phải được tích hợp vào từng ngóc ngách của hạ tầng dữ liệu:
- Lớp nguồn (Data Sources): Các cơ sở dữ liệu giao dịch, API, hoặc các luồng Kafka. Metadata về cấu trúc nguồn cần được ghi lại ngay từ bước đầu tiên.
- Lớp xử lý (Processing Layer): Nơi thực thi các logic bằng Spark, Python hoặc SQL. Đây là nơi “phép thuật” diễn ra và cũng là nơi phát sinh nhiều Metadata nhất. Các công cụ hiện đại sẽ tự động trích xuất Lineage từ mã nguồn (Parsing SQL).
- Lớp lưu trữ (Storage Layer): Các Data Warehouse như BigQuery, Snowflake hay Redshift. Tại đây, Lineage giúp theo dõi các phiên bản dữ liệu (Data Versioning) và lịch sử thay đổi của schema.
- Lớp phân tích (Analytics Layer): Điểm cuối cùng là các Dashboard (Power BI, Tableau, Looker). Sự kết nối tại đây giúp người dùng cuối có thể click vào một biểu đồ và xem ngược lại nguồn gốc của con số đó.
5. Những “trợ thủ” đắc lực nhất để theo dõi luồng dữ liệu
Việc vẽ sơ đồ Lineage bằng tay hay dùng Excel là một nhiệm vụ bất khả thi và sẽ nhanh chóng lỗi thời. Các Data Engineer chuyên nghiệp thường dựa vào các nhóm công cụ sau:
- dbt (data build tool): “Ông vua” trong việc tự động hóa sơ đồ Lineage từ các câu lệnh SQL. dbt tự động sinh ra file manifest.json chứa mọi mối quan hệ giữa các model, giúp việc visualization trở nên cực kỳ đơn giản.
- DataHub / Amundsen: Các nền tảng Data Catalog và Metadata mã nguồn mở mạnh mẽ nhất hiện nay. Chúng cho phép tập hợp Lineage từ nhiều công cụ khác nhau (ví dụ: nối liền Lineage từ Spark sang Airflow rồi sang Snowflake) thành một giao diện duy nhất.
- Monte Carlo / Bigeye: Các nền tảng Data Observability. Chúng không chỉ vẽ sơ đồ mà còn sử dụng AI để giám sát “sức khỏe” dữ liệu trên chính sơ đồ Lineage đó. Nếu một mắt xích bị lỗi, hệ thống sẽ cảnh báo ngay lập tức mức độ ảnh hưởng đến các báo cáo hạ nguồn.
6. Hướng dẫn 5 bước triển khai Data Lineage cho doanh nghiệp
Để không bị ngợp giữa hàng nghìn pipeline, hãy bắt đầu một cách có chiến lược:
Bước 1: Xác định các Dataset “Sống còn” (Critical Data Elements)
Đừng cố làm Lineage cho tất cả mọi thứ ngay từ đầu. Hãy chọn ra 10-20 báo cáo quan trọng nhất ảnh hưởng trực tiếp đến doanh thu hoặc các báo cáo thuế/tài chính để triển khai trước.
Bước 2: Tự động hóa việc thu thập Metadata
Hãy ưu tiên các công cụ có khả năng tự động đọc Log hệ thống hoặc mã nguồn (SQL parsing). Ví dụ, nếu bạn dùng Google BigQuery, bạn có thể tận dụng thông tin từ INFORMATION_SCHEMA.JOBS để biết bảng nào được tạo ra từ bảng nào.
Bước 3: Xây dựng Metadata Repository trung tâm
Mọi thông tin về nguồn, đích và logic biến đổi cần được lưu trữ vào một cơ sở dữ liệu chuyên dụng. Thông tin này phải bao gồm cả “dấu mốc thời gian” (Timestamp) để theo dõi tính tươi mới của dữ liệu.
Bước 4: Trực quan hóa (Visualization)
Sử dụng các sơ đồ dạng Node-and-Edge (nút và đường nối). Một hình ảnh có giá trị bằng ngàn lời nói; sơ đồ trực quan sẽ giúp cả kỹ sư lẫn lãnh đạo doanh nghiệp hiểu được hệ thống chỉ trong vài giây.
Bước 5: Tích hợp vào quy trình vận hành (DataOps)
Biến việc kiểm tra Lineage thành một phần của quy trình review code. Trước khi một pipeline mới được deploy, kỹ sư phải kiểm tra xem nó có phá vỡ sơ đồ Lineage hiện tại hay không.
7. Những thách thức “xương xẩu” và cách vượt qua
Triển khai Data Lineage không phải là con đường trải đầy hoa hồng:
- Hệ thống phân mảnh: Mỗi công cụ trong Data Stack lại có một định dạng Metadata khác nhau. Giải pháp là sử dụng các chuẩn chung như OpenLineage để các công cụ có thể giao tiếp với nhau.
- Dữ liệu không cấu trúc: Việc truy vết Lineage cho các file hình ảnh hay video khó hơn nhiều so với dữ liệu dạng bảng. Ở đây, chúng ta cần gắn tag và metadata thủ công nhiều hơn.
- Khối lượng Metadata khổng lồ: Việc lưu trữ Lineage cho hàng tỷ giao dịch mỗi ngày có thể làm chậm hệ thống. Hãy tập trung vào việc lưu trữ Metadata của các Job/Task thay vì lưu từng bản ghi đơn lẻ.
8. Kết luận: Tương lai của Data Engineering là sự minh bạch
Data Lineage không còn là một tính năng “thêm thắt” hay một sở thích kỹ thuật của các Data Engineer. Trong một thế giới mà dữ liệu được coi là tài sản chiến lược, thì Lineage chính là hệ thống bảo an và giám định cho tài sản đó.
Một doanh nghiệp sở hữu khả năng truy vết dữ liệu tốt sẽ có tốc độ phản ứng nhanh hơn với sự cố, tiết kiệm hàng nghìn giờ làm việc cho đội ngũ kỹ thuật và quan trọng nhất là xây dựng được một nền tảng niềm tin vững chắc cho mọi quyết định kinh doanh. Đừng để hệ thống dữ liệu của bạn là một “hộp đen” đầy rủi ro, hãy thắp sáng nó bằng Data Lineage ngay hôm nay.
FAQ (Giải đáp thắc mắc chuyên sâu)
Data Lineage có làm chậm hiệu năng của Data Warehouse không?
Hầu hết các công cụ Lineage hiện đại hoạt động bằng cách đọc Metadata từ các tệp Log hoặc mã nguồn (Passive collection), do đó chúng gần như không gây ra bất kỳ gánh nặng nào cho quá trình tính toán và truy vấn dữ liệu thực tế.
Nên chọn công cụ Lineage mã nguồn mở hay trả phí?
Nếu bạn có đội ngũ kỹ thuật mạnh và muốn tùy biến sâu, DataHub hoặc Amundsen là lựa chọn tuyệt vời. Nếu bạn cần sự ổn định, hỗ trợ nhanh và tích hợp sẵn các tính năng cảnh báo tự động, các giải pháp trả phí như Monte Carlo hay Collibra sẽ đáng giá từng xu đầu tư.
INDA Academy tự hào là đơn vị tiên phong trong việc đào tạo phân tích dữ liệu và AI chuyên sâu, đặc biệt cho khối ngành Ngân hàng – Tài chính – Bảo hiểm tại Việt Nam. Sau hơn 12 năm “thực chiến” cùng những dòng chảy dữ liệu khổng lồ, chúng tôi đã xây dựng nên một hệ sinh thái đào tạo toàn diện, giúp hàng nghìn học viên chuyển mình từ người mới bắt đầu trở thành những chuyên gia lành nghề, sẵn sàng đáp ứng tiêu chuẩn khắt khe của các doanh nghiệp lớn.
Điểm khác biệt lớn nhất tại INDA chính là triết lý đào tạo dựa trên các dự án thực tế (Project-based) và lộ trình cá nhân hóa nhờ ứng dụng AI. Chúng tôi không chỉ dạy bạn cách sử dụng công cụ, mà còn truyền tải tư duy khai phá giá trị từ dữ liệu để đưa ra quyết định kinh doanh chính xác.
Tìm hiểu thêm về các khóa học TẠI ĐÂY:
Lộ trình đào tạo Data Engineer
Lộ trình đào tạo Data Analyst
Lộ trình đào tạo Tester
Khóa học Data Engineer nâng cao – Thực chiến 5 dự án doanh nghiệp
Khóa học Data Analyst nâng cao – Thực chiến 5 dự án doanh nghiệp
Bài viết liên quan:
 Metadata-Driven Data Pipeline: Kiến trúc pipeline hiện đại trong Data Engineering
Metadata-Driven Data Pipeline: Kiến trúc pipeline hiện đại trong Data Engineering
 Data Pipeline Debugging: Nghệ Thuật Tìm Root Cause Khi Hệ Thống Dữ Liệu “Gãy Đổ”
Data Pipeline Debugging: Nghệ Thuật Tìm Root Cause Khi Hệ Thống Dữ Liệu “Gãy Đổ”
 Data Incident Management: Khi Dashboard không còn nói lời thật lòng
Data Incident Management: Khi Dashboard không còn nói lời thật lòng
 Late-arriving Data: Khi dữ liệu “đi lạc” và bài toán về tính chính xác trong Data Warehouse
Late-arriving Data: Khi dữ liệu “đi lạc” và bài toán về tính chính xác trong Data Warehouse
 Data Backfill: Khi Pipeline cần “ngược dòng thời gian” xử lý dữ liệu lịch sử
Data Backfill: Khi Pipeline cần “ngược dòng thời gian” xử lý dữ liệu lịch sử
 Data Engineer và Data Analyst Khác Nhau Thế Nào? So Sánh Dễ Hiểu Cho Sinh Viên Năm 3–4
Data Engineer và Data Analyst Khác Nhau Thế Nào? So Sánh Dễ Hiểu Cho Sinh Viên Năm 3–4