

Trong suốt nhiều thập kỷ, chúng ta đã quá quen thuộc với việc tìm kiếm bằng từ khóa (Keyword Search). Khi bạn gõ “máy chạy bộ”, hệ thống sẽ trả về các kết quả có chứa chính xác cụm từ đó. Tuy nhiên, hãy thử tưởng tượng bạn gõ: “thiết bị tập thể dục tại nhà giúp giảm cân hiệu quả”. Tìm kiếm truyền thống dựa trên từ khóa sẽ bắt đầu lúng túng vì nó không tìm thấy sự trùng khớp tuyệt đối về mặt ký tự giữa câu hỏi và mô tả sản phẩm.
Đây chính là lúc Vector Search (Tìm kiếm Vector) xuất hiện như một cuộc cách mạng. Nó không đi tìm các ký tự trùng khớp; nó đi tìm những khái niệm tương đồng. Công nghệ này chính là “động cơ” đứng sau sự thông minh của ChatGPT, khả năng gợi ý nội dung của TikTok hay tính năng tìm kiếm bằng hình ảnh của Google Lens.
Mục lục
1. Bản chất của Vector Search: Khi ý nghĩa được “số hóa”
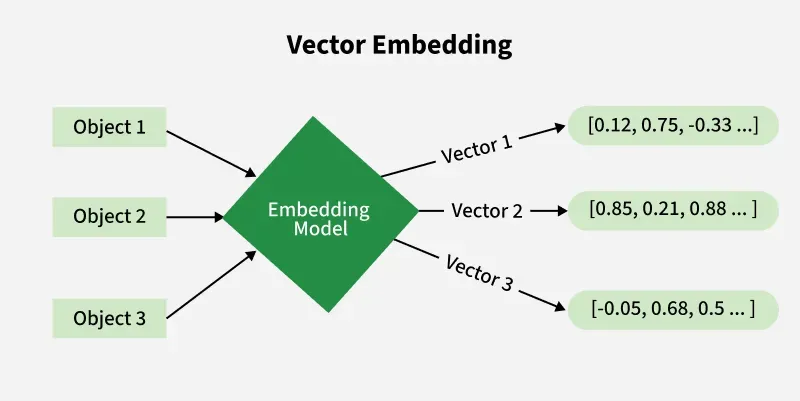
Về cốt lõi, Vector Search là phương pháp tìm kiếm dữ liệu dựa trên độ tương đồng về toán học giữa các thực thể. Thay vì lưu trữ dữ liệu dưới dạng văn bản thuần túy, hệ thống chuyển đổi mọi thông tin – từ một câu nói, một bức ảnh cho đến một đoạn nhạc – thành các dãy số dài trong không gian đa chiều, được gọi là Vector Embeddings.
Để dễ hình dung, hãy coi mỗi Vector như một tọa độ GPS. Trong bản đồ địa lý, những ngôi nhà nằm gần nhau thường có cùng đặc điểm vị trí. Trong bản đồ dữ liệu của Vector Search, những từ ngữ như “xe hơi” và “ô tô” sẽ được cấp cho hai tọa độ nằm sát cạnh nhau trên bản đồ vì chúng cùng chỉ một loại phương tiện, dù mặt chữ hoàn toàn khác biệt. Khả năng này cho phép máy tính xử lý dữ liệu phi cấu trúc – loại dữ liệu chiếm tới 80% lượng thông tin toàn cầu nhưng các cơ sở dữ liệu truyền thống thường bỏ qua.
2. Tại sao tìm kiếm truyền thống (Keyword Search) đang dần hụt hơi?
Tìm kiếm từ khóa dựa trên kỹ thuật lập chỉ mục đảo (Inverted Index), vốn hoạt động cực tốt khi bạn biết chính xác mình cần tìm gì. Tuy nhiên, ngôn ngữ con người vốn phức tạp và đầy sắc thái, khiến phương pháp này bộc lộ nhiều điểm yếu:
- Sự hạn chế về từ đồng nghĩa: Một hệ thống từ khóa sẽ không biết rằng khi người dùng tìm “smartphone”, họ cũng quan tâm đến kết quả về “điện thoại thông minh”. Điều này dẫn đến việc bỏ sót các thông tin giá trị chỉ vì khác biệt cách dùng từ.
- Vấn đề đa nghĩa và ngữ cảnh: Với những từ như “apple”, hệ thống cũ thường trộn lẫn giữa kết quả về trái cây và tập đoàn công nghệ nếu không có bộ lọc thủ công phức tạp.
- Dữ liệu phi văn bản: Bạn không thể dùng từ khóa để tìm một đoạn nhạc có giai điệu sôi động tương tự bài hát bạn đang nghe, hoặc tìm một bức ảnh có bố cục tương tự ảnh chụp sẵn.
Ngược lại, Vector Search giải quyết triệt để vấn đề này bằng cách phân tích ngữ cảnh xung quanh để xác định tọa độ chính xác nhất cho dữ liệu. Theo Algolia, tìm kiếm từ khóa bị giới hạn bởi “vốn từ của người dùng”, trong khi Vector Search mở rộng ra đến tận “ý định của người dùng”.
3. Embedding: Trái tim tạo nên sự thấu hiểu của AI
Làm thế nào để biến một bức ảnh phong cảnh hay một câu triết lý thành một dãy số? Câu trả lời nằm ở các mô hình Embedding. Đây là những mô hình Deep Learning đã được huấn luyện trên hàng tỷ dữ liệu để nhận diện các đặc trưng ngầm định. Khi bạn nạp một câu văn vào, mô hình sẽ phân tích cấu trúc ngữ pháp, tâm trạng và chủ đề để xuất ra một dãy số (thường là 768 hoặc 1536 chiều).
Sự kỳ diệu nằm ở chỗ các khái niệm liên quan sẽ tự động “tụ hội” lại với nhau trong không gian này. Khoảng cách giữa các điểm này chính là thước đo độ liên quan:
- Khu vực dành cho “công nghệ” sẽ chứa các vector của chip bán dẫn, phần mềm và trí tuệ nhân tạo.
- Khu vực “ẩm thực” sẽ chứa các vector của công thức nấu ăn, gia vị và nhà hàng.
- Một vector của từ “Vua” sau khi trừ đi vector “Nam” và cộng thêm vector “Nữ” sẽ cho ra kết quả gần nhất với vector của từ “Nữ hoàng”.
Theo tài liệu từ OpenAI, các mô hình embedding hiện đại đã đạt đến độ tinh vi đủ để phân biệt được cả những sắc thái biểu cảm nhỏ nhất trong ngôn ngữ con người.
4. Quy trình vận hành: Từ dữ liệu thô đến kết quả thông minh
Một hệ thống Vector Search thực tế vận hành qua một chuỗi quy trình khép kín, thường được gọi là Vector Search Pipeline:
- Giai đoạn Ingestion (Nạp dữ liệu): Dữ liệu thô (văn bản, ảnh) được đẩy qua mô hình Embedding để trích xuất tọa độ.
- Giai đoạn Lưu trữ: Các vector được lưu vào Vector Database (như Pinecone, Milvus hoặc Weaviate). Tại đây, hệ thống xây dựng các cấu trúc chỉ mục (Index) chuyên dụng.
- Giai đoạn Truy vấn: Khi người dùng nhập câu hỏi, hệ thống chuyển câu hỏi đó thành một Vector truy vấn bằng chính mô hình đã dùng ở bước 1.
- Giai đoạn So sánh: Hệ thống thực hiện phép toán so sánh như Cosine Similarity (đo góc giữa hai vector) hoặc Euclidean Distance (đo khoảng cách thẳng) để tìm ra những kết quả nằm gần nhất.
5. Thuật toán ANN: Chìa khóa cho tốc độ xử lý hàng tỷ dữ liệu
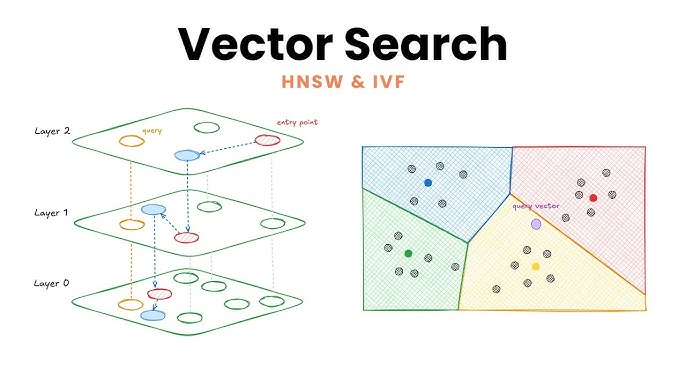
Thách thức lớn nhất khi tìm kiếm trong không gian đa chiều là khối lượng tính toán. Nếu hệ thống phải so sánh câu hỏi của bạn với từng điểm dữ liệu trong một kho chứa 1 tỷ vector, bạn sẽ phải chờ hàng phút. Để giải quyết bài toán tốc độ, các kỹ sư sử dụng thuật toán ANN (Approximate Nearest Neighbor).
ANN không cố gắng tìm kết quả đúng tuyệt đối 100%, mà ưu tiên tìm kết quả “đủ tốt” trong thời gian cực ngắn. Một số thuật toán phổ biến bao gồm:
- HNSW (Hierarchical Navigable Small World): Xây dựng mạng lưới liên kết thông minh, cho phép “nhảy” nhanh qua các tầng dữ liệu để đến vùng kết quả nhanh nhất.
- IVF (Inverted File Index): Chia không gian vector thành các cụm (clusters) và chỉ tìm kiếm trong cụm chứa vector truy vấn.
- PQ (Product Quantization): Nén các vector khổng lồ thành các mã ngắn hơn để tiết kiệm bộ nhớ và tăng tốc độ tính toán.
6. Vector Search và Vector Database khác nhau thế nào?
Dù thường được nhắc cùng nhau, nhưng chúng là hai thực thể khác biệt. Vector Search là thuật toán hoặc kỹ thuật để tìm ra dữ liệu tương đồng. Trong khi đó, Vector Database là một hệ thống quản trị hoàn chỉnh. Nó không chỉ chứa thuật toán tìm kiếm mà còn cung cấp các tính năng như:
- Khả năng mở rộng (Scaling) để chứa hàng tỷ bản ghi.
- Khả năng lọc theo thuộc tính (Metadata Filtering) – ví dụ: Tìm đôi giày tương tự nhưng phải là màu đỏ và có giá dưới 1 triệu đồng.
- Bảo mật, sao lưu và phục hồi dữ liệu.
Theo NVIDIA, một Vector Database tốt phải tích hợp được Vector Search mạnh mẽ kèm theo các tính năng quản lý dữ liệu cấp doanh nghiệp.
7. Ứng dụng thực tế: Động cơ phía sau trải nghiệm người dùng
Ngày nay, Vector Search hiện diện trong mọi ngóc ngách của đời sống số, biến những trải nghiệm phức tạp trở nên đơn giản:
Hệ thống RAG (Retrieval-Augmented Generation): Đây là ứng dụng quan trọng nhất trong doanh nghiệp. AI sẽ dùng Vector Search để lục tìm trong kho tài liệu nội bộ, tìm ra đoạn văn liên quan nhất, sau đó mới đưa thông tin đó cho ChatGPT để trả lời. Điều này giúp AI nói chuyện dựa trên kiến thức thật sự của công ty chứ không phải “đoán mò”.
Semantic Search (Tìm kiếm ngữ nghĩa): Các trang thương mại điện tử lớn giúp khách hàng tìm thấy sản phẩm ngay cả khi họ không biết tên chính xác, chỉ cần mô tả công dụng hoặc phong cách.
Hệ thống gợi ý (Recommendation): Spotify hay Netflix biểu diễn sở thích của bạn thành một vector. Khi bạn xem một bộ phim, tọa độ của bạn dịch chuyển về phía chủ đề đó. Hệ thống chỉ việc tìm các nội dung có tọa độ nằm xung quanh bạn để đưa vào danh sách gợi ý.
Image Search (Tìm kiếm hình ảnh): Cho phép người dùng chụp ảnh một chiếc ghế và tìm những chiếc ghế có kiểu dáng tương tự trong kho hàng dựa trên các vector đặc trưng về hình dáng và màu sắc.
8. Xu hướng Hybrid Search: Tương lai của tìm kiếm
Dù Vector Search rất mạnh về ngữ nghĩa, nhưng nó đôi khi lại bỏ qua những chi tiết cụ thể (như mã SKU sản phẩm). Vì thế, xu hướng hiện nay là Hybrid Search – kết hợp cả Keyword Search và Vector Search.
Trong kiến trúc này, hệ thống sẽ thực hiện cả hai kiểu tìm kiếm song song. Kết quả từ từ khóa đảm bảo tính chính xác cho các tên riêng, mã số; còn kết quả từ vector đảm bảo tính thấu hiểu ý định. Sau đó, một thuật toán xếp hạng (Reciprocal Rank Fusion) sẽ tổng hợp cả hai để đưa ra danh sách kết quả tối ưu nhất cho người dùng.

9. Những thách thức khi triển khai
Việc triển khai Vector Search không hề rẻ. Lưu trữ vector yêu cầu rất nhiều RAM và năng lượng tính toán của CPU/GPU để thực hiện các phép toán khoảng cách. Ngoài ra, việc lựa chọn mô hình Embedding là yếu tố sống còn. Nếu bạn dùng một model không được tối ưu cho tiếng Việt để xây dựng hệ thống cho người Việt, kết quả trả về sẽ rất ngây ngô và thiếu chính xác.
Hơn nữa, việc quản lý Metadata (dữ liệu bổ sung) cũng là một bài toán khó. Các kỹ sư phải thiết kế sao cho việc tìm kiếm vector vẫn có thể kết hợp mượt mà với các bộ lọc logic truyền thống mà không làm tăng độ trễ của hệ thống.
Kết luận
Vector Search không chỉ là một công nghệ tìm kiếm mới; nó là lớp hạ tầng cơ bản nhất để máy tính có thể thực sự thấu hiểu thế giới của con người. Việc làm chủ công nghệ này giúp doanh nghiệp chuyển mình từ việc quản lý dữ liệu sang việc khai phá tri thức, mang lại trải nghiệm khách hàng vượt trội và chính xác hơn bao giờ hết.
INDA Academy tự hào là đơn vị tiên phong trong việc đào tạo phân tích dữ liệu và AI chuyên sâu, đặc biệt cho khối ngành Ngân hàng – Tài chính – Bảo hiểm tại Việt Nam. Sau hơn 12 năm “thực chiến” cùng những dòng chảy dữ liệu khổng lồ, chúng tôi đã xây dựng nên một hệ sinh thái đào tạo toàn diện, giúp hàng nghìn học viên chuyển mình từ người mới bắt đầu trở thành những chuyên gia lành nghề, sẵn sàng đáp ứng tiêu chuẩn khắt khe của các doanh nghiệp lớn.
Điểm khác biệt lớn nhất tại INDA chính là triết lý đào tạo dựa trên các dự án thực tế (Project-based) và lộ trình cá nhân hóa nhờ ứng dụng AI. Chúng tôi không chỉ dạy bạn cách sử dụng công cụ, mà còn truyền tải tư duy khai phá giá trị từ dữ liệu để đưa ra quyết định kinh doanh chính xác.
Tìm hiểu thêm về các khóa học TẠI ĐÂY:
Lộ trình đào tạo Data Engineer
Lộ trình đào tạo Data Analyst
Lộ trình đào tạo Tester
Khóa học Data Engineer nâng cao – Thực chiến 5 dự án doanh nghiệp
Khóa học Data Analyst nâng cao – Thực chiến 5 dự án doanh nghiệp

