

Trong vài năm trở lại đây, sự bùng nổ của các mô hình ngôn ngữ lớn (LLM) như ChatGPT đã tạo nên một cơn địa chấn trong giới công nghệ. Tuy nhiên, ít ai biết rằng để những “bộ não nhân tạo” này có thể truy xuất thông tin chính xác và hiểu được ngữ cảnh phức tạp của con người, chúng cần một loại kho lưu trữ hoàn toàn mới. Đó chính là Vector Database (Cơ sở dữ liệu Vector).
Nếu các cơ sở dữ liệu truyền thống là những thư viện lưu trữ sách theo bảng chữ cái cứng nhắc, thì Vector Database giống như một mạng lưới thần kinh, nơi thông tin được kết nối với nhau bằng ý nghĩa và cảm xúc. Bài viết này sẽ dẫn bạn đi từ những khái niệm cơ bản nhất đến những ứng dụng thực tế đang thay đổi cách chúng ta tương tác với máy tính.
Mục lục
1. Vector Database là gì? Cách AI “nhìn” thế giới
Để hiểu Vector Database, trước tiên chúng ta phải chấp nhận một sự thật: Máy tính không hiểu ngôn ngữ như con người. Đối với máy tính, từ “Yêu” hay “Ghét” chỉ là những chuỗi ký tự vô hồn. Để máy tính “hiểu” được, chúng ta phải chuyển đổi những khái niệm này thành thứ mà nó giỏi nhất: Những con số.
Khái niệm về Vector trong không gian đa chiều
Hãy tưởng tượng bạn đang mô tả một quả táo cho một người chưa bao giờ thấy nó. Bạn sẽ dùng các thuộc tính:
- Độ ngọt: 8/10
- Độ đỏ: 9/10
- Độ giòn: 7/10
Khi đó, quả táo được đại diện bởi một bộ số [8, 9, 7]. Trong toán học, đây gọi là một Vector. Trong thực tế AI, một từ hay một bức ảnh có thể được đại diện bởi một vector có hàng nghìn con số (hàng nghìn chiều), mô tả mọi khía cạnh tinh vi nhất của đối tượng đó.
Vector Database chính là hệ thống chuyên biệt để lưu trữ hàng tỷ bộ số này. Thay vì tìm kiếm theo kiểu “tên bài hát có chữ ‘Mưa’ không?”, nó sẽ tìm theo kiểu “tọa độ của bài hát này có nằm gần khu vực của những bài hát buồn không?”.
2. Embedding: Phép thuật chuyển hóa ý nghĩa thành tọa độ
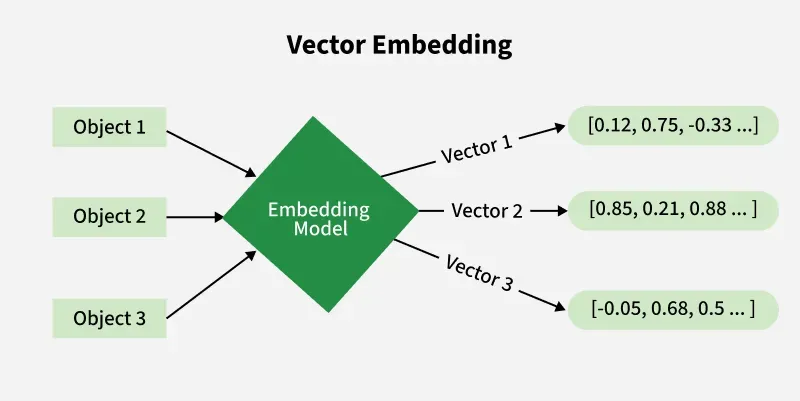
Làm sao chúng ta biến một đoạn văn dài hay một bức ảnh phong cảnh thành một chuỗi số? Đó là nhờ vào một quy trình gọi là Embedding.
Quá trình “phiên dịch” của AI
Embedding giống như một bộ lọc thông minh. Khi bạn đưa một dữ liệu thô vào (ví dụ: một câu nói), một mô hình AI (như BERT hoặc OpenAI’s text-embedding-3) sẽ phân tích câu nói đó dựa trên ngữ cảnh và kinh nghiệm mà nó đã học được từ hàng tỷ văn bản trước đó.
Ví dụ, hai câu:
- “Tôi muốn mua một chiếc điện thoại mới.”
- “Tìm cho tôi một thiết bị di động đời mới.”
Về mặt chữ cái, hai câu này không có từ nào chung (trừ từ “một”). Nhưng qua bộ lọc Embedding, chúng sẽ được cấp cho hai tọa độ cực kỳ sát nhau trong không gian Vector vì chúng có cùng ý định (intent).
Tại sao không dùng Database truyền thống?
Các cơ sở dữ liệu như MySQL hay SQL Server được thiết kế để xử lý dữ liệu có cấu trúc — tức là dữ liệu có thể bỏ gọn vào các hàng và cột. Chúng rất giỏi trong việc trả lời câu hỏi: “Tổng doanh thu tháng 5 là bao nhiêu?”.
Nhưng chúng lại cực kỳ “vụng về” khi gặp dữ liệu phi cấu trúc. Nếu bạn yêu cầu một database truyền thống tìm kiếm hình ảnh một con mèo đang ngủ, nó sẽ phải quét qua từng dòng mô tả văn bản của ảnh. Ngược lại, Vector Database chỉ cần nhìn vào “tọa độ ảnh” và tìm những điểm dữ liệu có tọa độ tương tự. Đây là sự khác biệt giữa việc tra từ điển thủ công và việc dùng GPS để định vị.
3. Cơ chế vận hành bên trong của một Vector Database
Một Vector Database không hoạt động giống như một kho lưu trữ tĩnh. Nó là một cỗ máy xử lý tốc độ cao với ba giai đoạn chính:
Bước 1: Tiếp nhận và Lập chỉ mục (Indexing)
Khi dữ liệu được nạp vào, hệ thống không chỉ lưu vector đó lại. Nó sử dụng các thuật toán đặc biệt để “vẽ bản đồ” cho dữ liệu. Bước này gọi là lập chỉ mục (Indexing). Thay vì xếp hàng dài, dữ liệu được gom thành từng cụm lân cận. Điều này cực kỳ quan trọng vì khi bạn tìm kiếm, hệ thống sẽ biết ngay cần phải nhìn vào “vùng đất” nào thay vì quét toàn bộ hệ thống.
Bước 2: Tìm kiếm láng giềng gần nhất (Nearest Neighbor Search)
Đây là lúc phép màu xảy ra. Khi bạn nhập một câu lệnh tìm kiếm, câu lệnh đó cũng được chuyển thành một Vector. Database sẽ thực hiện phép tính khoảng cách (Distance Metrics) để tìm ra những “người hàng xóm” gần nhất.
- Cosine Similarity: Đo góc giữa hai vector để xem chúng “hướng” về cùng một ý nghĩa hay không.
- Euclidean Distance: Đo khoảng cách vật lý giữa hai điểm tọa độ.
Bước 3: Thuật toán ANN – Chìa khóa của tốc độ
Trong một database có 1 tỷ vector, việc đo khoảng cách chính xác đến từng điểm là không khả thi (mất quá nhiều thời gian). Vì vậy, Vector Database sử dụng thuật toán ANN (Approximate Nearest Neighbor).
Thay vì hứa rằng: “Đây là kết quả đúng 100% nhất”, nó sẽ nói: “Trong thời gian 0.01 giây, đây là những kết quả gần đúng nhất mà tôi tìm thấy”. Với người dùng, sự chênh lệch này là không thể nhận ra, nhưng tốc độ thì nhanh hơn hàng nghìn lần.
4. Ứng dụng đột phá: Tại sao mọi công ty AI đều cần nó?
Vector Database không phải là một công cụ lý thuyết, nó đang hiện diện trong mọi trải nghiệm số hàng ngày của bạn.
RAG (Retrieval-Augmented Generation): Bộ nhớ ngoài cho ChatGPT
Hãy tưởng tượng ChatGPT là một chuyên gia cực kỳ thông minh nhưng… trí nhớ bị giới hạn trong quá khứ (dữ liệu huấn luyện). Khi bạn hỏi về quy trình nội bộ của công ty mình, ChatGPT sẽ “bó tay”.
Lúc này, Vector Database đóng vai trò là một ổ cứng gắn ngoài. Khi người dùng hỏi, hệ thống sẽ:
- Vào Vector Database tìm các tài liệu nội bộ liên quan.
- Trích xuất đoạn văn bản đó ra.
- Đưa cho ChatGPT và nói: “Dựa trên thông tin này, hãy trả lời khách hàng”.
Đây chính là cách các chatbot thông minh của các ngân hàng hay hãng hàng không đang vận hành hiện nay.
Đọc thêm: RAG là gì? “Bộ não ngoài” giúp AI không còn nói dối
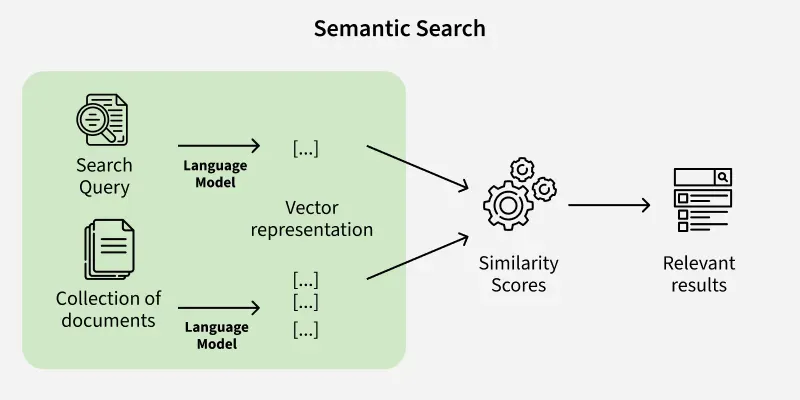
Tìm kiếm ngữ nghĩa (Semantic Search)
Thay vì gõ đúng từ khóa, bạn có thể tìm bằng ý tưởng. Bạn có thể tìm kiếm trên kho ảnh của mình bằng câu lệnh: “Ảnh tôi đi du lịch vùng biển có nhiều dừa” và hệ thống sẽ tự động lọc ra các bức ảnh có tọa độ vector tương đồng với mô tả đó, dù bạn chưa bao giờ đặt tên cho ảnh.
Hệ thống gợi ý cá nhân hóa
Netflix hay TikTok biết bạn thích gì vì họ xây dựng một vector cho mỗi người dùng. Mỗi video bạn xem sẽ kéo tọa độ của bạn về phía một cụm chủ đề nhất định. Khi bạn lướt, hệ thống chỉ việc tìm các video có tọa độ nằm xung quanh “tọa độ sở thích” của bạn.
5. So sánh chi tiết: Vector DB vs Database truyền thống
Để hiểu sâu hơn, hãy nhìn vào bảng so sánh dưới đây dưới góc độ vận hành thực tế:
| Tiêu chí | Database truyền thống (SQL/NoSQL) | Vector Database |
| Loại dữ liệu | Số, văn bản có cấu trúc rõ ràng. | Vector đại diện cho ảnh, văn bản, âm thanh. |
| Cách tìm kiếm | Khớp từ khóa, lọc theo điều kiện (Lớn hơn, nhỏ hơn). | Tìm kiếm tương đồng theo khoảng cách toán học. |
| Độ chính xác | Tuyệt đối (1 là 1, 2 là 2). | Tương đối (Tìm kết quả gần đúng nhất). |
| Khả năng hiểu | Không hiểu ý nghĩa (Chỉ khớp ký tự). | Hiểu được ngữ cảnh và sự liên quan giữa các khái niệm. |
| Tốc độ | Chậm khi tìm kiếm dữ liệu phi cấu trúc lớn. | Cực nhanh nhờ các thuật toán ANN và Indexing chuyên dụng. |
6. Những thách thức khi triển khai Vector Database
Mặc dù mạnh mẽ, nhưng Vector Database không phải là một “viên đạn bạc” giải quyết được mọi thứ mà không có chi phí.
- Chi phí tài nguyên (RAM): Để đạt được tốc độ tìm kiếm mil giây, Vector Database thường phải lưu trữ các chỉ mục (Index) trực tiếp trên RAM. Với hàng tỷ vector, đây là một khoản chi phí hạ tầng không hề nhỏ.
- Lựa chọn mô hình Embedding: “Chất lượng” của database phụ thuộc hoàn toàn vào mô hình bạn dùng để tạo vector. Nếu mô hình phiên dịch kém, các tọa độ sẽ bị sai lệch và kết quả tìm kiếm sẽ không liên quan.
- Quản lý Metadata: Đôi khi bạn không chỉ muốn tìm “ảnh tương tự”, mà còn muốn “ảnh tương tự nhưng phải chụp trong năm 2024”. Việc kết hợp giữa tìm kiếm vector và lọc dữ liệu truyền thống (Filtering) là một bài toán kỹ thuật phức tạp mà các database hiện nay vẫn đang hoàn thiện.
7. Các công cụ hàng đầu và lộ trình bắt đầu
Nếu bạn là một marketer, quản lý dự án hoặc lập trình viên mới bắt đầu, bạn nên biết về những hệ sinh thái này:
- Pinecone: Đây là lựa chọn “mì ăn liền” tốt nhất. Nó là một dịch vụ đám mây (SaaS), bạn không cần cài đặt server phức tạp, chỉ cần đẩy dữ liệu lên và dùng.
- Chroma: Một thư viện mã nguồn mở cực kỳ nhẹ, cho phép bạn chạy ngay trên máy tính cá nhân để thử nghiệm các dự án AI nhỏ.
- Milvus: Được mệnh danh là “con quái vật” về hiệu năng, phù hợp cho các tập đoàn lớn cần lưu trữ hàng nghìn tỷ vector.
Kết luận
Vector Database chính là mảnh ghép cuối cùng để biến AI từ một công cụ “biết nói” thành một hệ thống “biết tuệ”. Nó giúp thu hẹp khoảng cách giữa cách con người tư duy và cách máy tính lưu trữ thông tin. Việc hiểu về Vector Database không chỉ giúp bạn nắm bắt được cốt lõi của các hệ thống AI hiện đại mà còn mở ra tư duy mới về cách quản trị dữ liệu: Dữ liệu không chỉ để lưu trữ, dữ liệu là để kết nối ý nghĩa.
INDA Academy tự hào là đơn vị tiên phong trong việc đào tạo phân tích dữ liệu và AI chuyên sâu, đặc biệt cho khối ngành Ngân hàng – Tài chính – Bảo hiểm tại Việt Nam. Sau hơn 12 năm “thực chiến” cùng những dòng chảy dữ liệu khổng lồ, chúng tôi đã xây dựng nên một hệ sinh thái đào tạo toàn diện, giúp hàng nghìn học viên chuyển mình từ người mới bắt đầu trở thành những chuyên gia lành nghề, sẵn sàng đáp ứng tiêu chuẩn khắt khe của các doanh nghiệp lớn.
Điểm khác biệt lớn nhất tại INDA chính là triết lý đào tạo dựa trên các dự án thực tế (Project-based) và lộ trình cá nhân hóa nhờ ứng dụng AI. Chúng tôi không chỉ dạy bạn cách sử dụng công cụ, mà còn truyền tải tư duy khai phá giá trị từ dữ liệu để đưa ra quyết định kinh doanh chính xác.
Tìm hiểu thêm về các khóa học TẠI ĐÂY:
Lộ trình đào tạo Data Engineer
Lộ trình đào tạo Data Analyst
Lộ trình đào tạo Tester
Khóa học Data Engineer nâng cao – Thực chiến 5 dự án doanh nghiệp
Khóa học Data Analyst nâng cao – Thực chiến 5 dự án doanh nghiệp

