

Trong kỷ nguyên của phần mềm hiện đại, có một quy luật bất thành văn mà mọi kỹ sư dữ liệu đều phải đối mặt: “Sự thay đổi là hằng số duy nhất”. Hãy tưởng tượng hệ thống dữ liệu của bạn như một sinh vật sống, không ngừng tiến hóa để đáp ứng nhu cầu kinh doanh. Hôm nay, bộ phận sản phẩm quyết định thêm một tính năng “giảm giá hội viên”, ngày mai bộ phận marketing muốn thu thập thêm thông tin về “loại thiết bị” người dùng.
Nếu hệ thống của bạn được xây dựng như một khối bê tông cứng nhắc, mọi thay đổi nhỏ từ phía thượng nguồn (upstream) đều có thể trở thành một “cú sốc” làm gãy đổ toàn bộ các đường ống dẫn dữ liệu (pipeline) hạ nguồn. Khi đó, thay vì phân tích dữ liệu, bạn sẽ phải dành cả ngày để đi “vá” lỗi. Schema Evolution (Tiến hóa cấu trúc dữ liệu) chính là bộ kỹ năng giúp hệ thống của bạn không chỉ tồn tại mà còn thích nghi mạnh mẽ, biến những thay đổi bất ngờ thành một phần của quy trình vận hành trơn tru.
Mục lục
I. Khi cấu trúc dữ liệu không còn là một “bản cam kết” vĩnh viễn
Trong cách làm truyền thống, chúng ta thường bắt đầu bằng việc thiết kế một bảng dữ liệu với các cột và kiểu dữ liệu cố định (Schema). Mọi thứ chạy rất tốt cho đến khi hệ thống nguồn đột ngột thay đổi. Một cột bị đổi tên, một kiểu dữ liệu từ số nguyên chuyển sang số thập phân, hoặc một trường thông tin quan trọng bị xóa bỏ.
Vấn đề thực sự phát sinh khi các pipeline ingestion được lập trình một cách quá máy móc. Khi cấu trúc đầu vào không còn khớp với cấu trúc định sẵn, hệ thống thường chọn cách an toàn nhất nhưng cũng gây đau đầu nhất: Dừng hoạt động. Một schema change không được kiểm soát có thể khiến Dashboard của giám đốc hiển thị thông báo lỗi, các mô hình học máy đưa ra dự báo sai lệch, và tồi tệ nhất là dữ liệu mới bị thất lạc vĩnh viễn vì không thể nạp vào kho.
II. Schema Evolution: Khả năng “tự chữa lành” của dữ liệu
Schema Evolution có thể hiểu là khả năng của một hệ thống dữ liệu trong việc thích ứng với những thay đổi về cấu trúc theo thời gian mà không làm gián đoạn các tiến trình xử lý hiện tại. Điều này bao gồm việc xử lý thông minh các hành động như thêm cột, xóa cột, đổi tên hay thay đổi kiểu dữ liệu.
Mục tiêu cốt lõi của Schema Evolution là đảm bảo hai tính chất quan trọng:
- Tính tương thích ngược (Backward Compatibility): Code mới hoặc cấu trúc dữ liệu mới vẫn có thể đọc và hiểu được dữ liệu cũ đã lưu trữ trước đó.
- Tính tương thích xuôi (Forward Compatibility): Code cũ vẫn có thể chạy bình thường khi gặp dữ liệu mới có cấu trúc đã thay đổi (thường bằng cách bỏ qua các trường thông tin mà nó không nhận diện được).
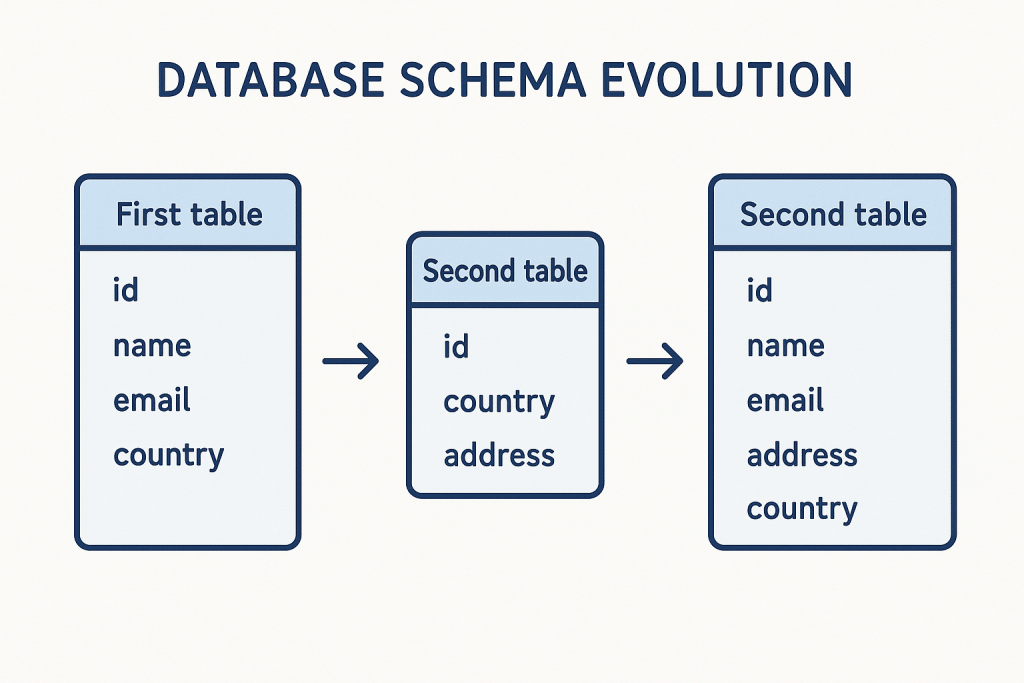
Hãy lấy ví dụ về một bảng thông tin người dùng. Ở phiên bản đầu tiên, chúng ta chỉ lưu user_id và email. Sang phiên bản thứ hai, hệ thống thêm cột phone. Một hệ thống có khả năng tiến hóa tốt sẽ cho phép bạn truy vấn đồng thời cả dữ liệu cũ (với giá trị phone là NULL) và dữ liệu mới một cách nhất quán mà không cần phải can thiệp thủ công vào từng bản ghi cũ.
III. Phân loại những “biến số” trong cấu trúc dữ liệu
Không phải mọi sự thay đổi đều mang tính chất phá hủy như nhau. Trong kỹ thuật dữ liệu, chúng ta phân loại chúng để có chiến lược ứng phó phù hợp.
1. Thêm cột mới (Add Column): Đây là loại thay đổi “hiền lành” nhất. Phần lớn các Data Warehouse hiện đại đều có thể tự động nhận diện và bổ sung cột mới vào bảng hiện có. Các downstream pipeline thường sẽ bỏ qua cột này cho đến khi bạn thực sự cần dùng đến nó.
2. Xóa hoặc đổi tên cột (Remove/Rename Column): Đây là những thay đổi mang tính “phá vỡ” (breaking changes). Nếu một Dashboard đang dựa vào cột price để tính doanh thu, nhưng hệ thống nguồn lại đổi tên nó thành order_price hoặc xóa bỏ nó, câu lệnh truy vấn chắc chắn sẽ thất bại. Đây là kịch bản đòi hỏi sự phối hợp chặt chẽ giữa các đội ngũ phát triển.
3. Thay đổi kiểu dữ liệu (Change Data Type): Việc chuyển đổi từ INT sang FLOAT thường an toàn vì không làm mất dữ liệu. Tuy nhiên, chuyển từ STRING sang TIMESTAMP hoặc ngược lại thường dẫn đến lỗi parsing nghiêm trọng nếu dữ liệu không tuân thủ định dạng mới.
4. Thay đổi cấu trúc lồng (Nested Schema Change): Trong các tệp tin JSON hoặc sự kiện từ Event Tracking, dữ liệu thường có cấu trúc phức tạp. Việc thay đổi một trường nằm sâu bên trong cấu trúc lồng có thể khó phát hiện hơn nhiều so với các cột phẳng thông thường.
IV. Các chiến lược xử lý Schema Evolution thực chiến
Để quản lý sự tiến hóa này một cách chuyên nghiệp, các hệ thống dữ liệu lớn thường áp dụng một hoặc kết hợp các chiến lược sau:
1. Sử dụng Schema Registry
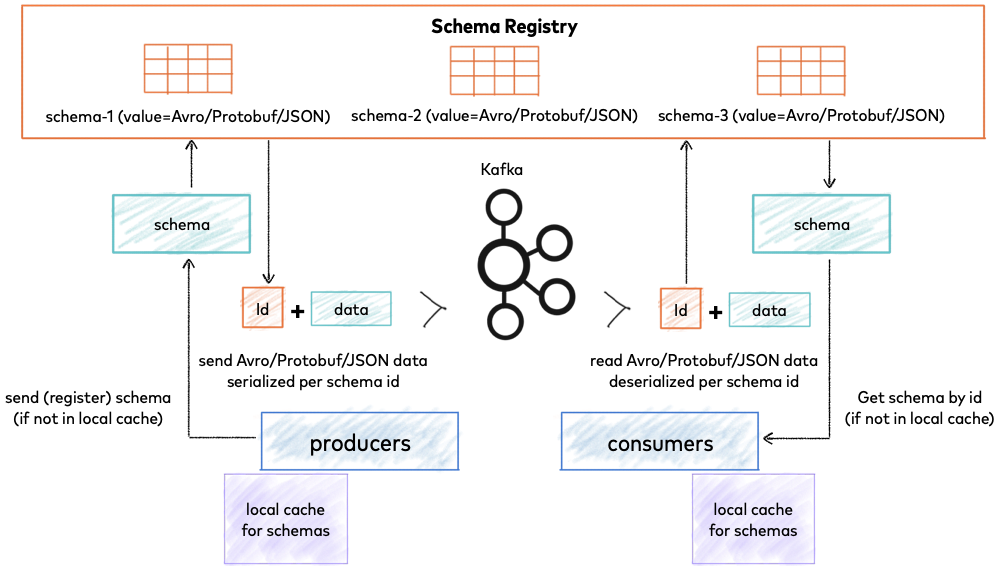
Trong các hệ thống streaming như Apache Kafka, Schema Registry đóng vai trò như một thư viện lưu trữ toàn bộ các phiên bản cấu trúc dữ liệu (v1, v2, v3…). Khi một ứng dụng gửi dữ liệu đi, nó sẽ đính kèm một ID tương ứng với phiên bản schema đó. Ứng dụng nhận sẽ kiểm tra Registry để biết cách giải mã dữ liệu chính xác. Theo tài liệu từ Confluent về Schema Registry, đây là cách tốt nhất để thực thi các quy tắc tương thích giữa các đội ngũ phát triển độc lập.
2. Hệ thống Schema linh hoạt (Flexible Schema)
Các hệ thống như Data Lake (S3/GCS kết hợp với Parquet/Avro) hay Document Database (MongoDB) cho phép lưu trữ dữ liệu mà không cần định nghĩa cứng nhắc từ đầu. Dữ liệu có cấu trúc khác nhau có thể nằm chung trong một “thư mục”. Chỉ khi dữ liệu được đọc ra để phân tích, schema mới được áp dụng (Schema-on-read). Điều này mang lại sự linh hoạt tối đa cho việc ingestion nhưng đòi hỏi người làm analytics phải xử lý dữ liệu thô kỹ hơn.
3. Tự động hóa tiến hóa (Auto-Evolution)
Các nền tảng hiện đại như Delta Lake hoặc Google BigQuery hỗ trợ tính năng tự động cập nhật bảng đích khi phát hiện dữ liệu nguồn có thêm cột mới. Điều này giúp giảm tải đáng kể công việc vận hành cho kỹ sư dữ liệu, cho phép các thay đổi an toàn diễn ra một cách thầm lặng mà không cần viết lại code ETL.
V. Schema Evolution trong chuỗi cung ứng dữ liệu
Để thiết kế một hệ thống bền bỉ, chúng ta cần xem xét schema evolution tại từng lớp dữ liệu khác nhau:
- Lớp dữ liệu thô (Raw Layer): Tại đây, chúng ta nên ưu tiên sự linh hoạt. Dữ liệu nên được lưu ở định dạng nguyên bản (như JSON hoặc Avro) để bảo tồn mọi thông tin, kể cả khi cấu trúc thay đổi bất ngờ. Đừng bao giờ áp dụng các quy tắc schema quá khắt khe tại lớp này vì nó có thể làm mất dữ liệu.
- Lớp chuẩn hóa (Staging/Curated Layer): Đây là nơi chúng ta bắt đầu làm sạch và cấu trúc lại dữ liệu. Schema ở đây cần được kiểm soát chặt chẽ hơn thông qua các bộ lọc và kiểm tra (Validation).
- Lớp kho dữ liệu (Warehouse/Analytics Layer): Đây là tầng phục vụ người dùng cuối. Schema ở đây phải cực kỳ ổn định. Mọi thay đổi lớn tại tầng này cần được thông báo trước và có kế hoạch chuyển đổi rõ ràng để tránh làm hỏng các báo cáo quan trọng.
VI. Best Practices: Xây dựng hệ thống “bất biến” trước sự thay đổi
Để không bao giờ phải thức trắng đêm vì một lỗi “Missing Column”, hãy áp dụng các nguyên tắc thiết kế sau:
- Ưu tiên thêm, hạn chế sửa: Thay vì thay đổi logic của một cột cũ, hãy thêm một cột mới với phiên bản mới. Điều này đảm bảo tính tương thích ngược cho các hệ thống cũ vẫn đang sử dụng dữ liệu đó.
- Thiết lập Data Contracts (Hợp đồng dữ liệu): Hãy coi cấu trúc dữ liệu là một bản hợp đồng giữa đội ngũ phần mềm (người tạo dữ liệu) và đội ngũ dữ liệu (người tiêu thụ). Mọi thay đổi phá vỡ hợp đồng cần được thảo luận và kiểm thử trước khi đẩy lên môi trường sản xuất.
- Sử dụng Metadata Versioning: Luôn đính kèm thông tin phiên bản schema vào mỗi bản ghi dữ liệu. Điều này cực kỳ hữu ích khi bạn cần thực hiện Data Backfill hoặc debug các vấn đề liên quan đến sự sai lệch dữ liệu giữa các thời kỳ.
- Giám sát Schema Drift: Sử dụng các công cụ Data Observability để nhận cảnh báo ngay khi có sự thay đổi cấu trúc ở nguồn. Phát hiện sớm một cột mới được thêm vào luôn tốt hơn việc phát hiện ra nó sau khi đã bỏ lỡ dữ liệu của cả tháng trời.
VII. Kết luận
Schema Evolution không chỉ là một vấn đề kỹ thuật; nó phản ánh sự vận động không ngừng của doanh nghiệp. Một hệ thống dữ liệu “khỏe mạnh” không phải là hệ thống không bao giờ thay đổi, mà là hệ thống có thể tiến hóa cùng với những bước đi của doanh nghiệp đó.
Bằng cách xây dựng các pipeline linh hoạt, sử dụng các công cụ quản lý schema hiện đại và thiết lập những quy trình giao tiếp chặt chẽ giữa các đội ngũ, bạn sẽ biến những thay đổi cấu trúc dữ liệu từ nỗi lo sợ thành một lợi thế cạnh tranh, giúp doanh nghiệp luôn có được cái nhìn chính xác và kịp thời nhất, bất kể thế giới dữ liệu ngoài kia có biến động ra sao.
INDA Academy tự hào là đơn vị tiên phong trong việc đào tạo phân tích dữ liệu và AI chuyên sâu, đặc biệt cho khối ngành Ngân hàng – Tài chính – Bảo hiểm tại Việt Nam. Sau hơn 12 năm “thực chiến” cùng những dòng chảy dữ liệu khổng lồ, chúng tôi đã xây dựng nên một hệ sinh thái đào tạo toàn diện, giúp hàng nghìn học viên chuyển mình từ người mới bắt đầu trở thành những chuyên gia lành nghề, sẵn sàng đáp ứng tiêu chuẩn khắt khe của các doanh nghiệp lớn.
Điểm khác biệt lớn nhất tại INDA chính là triết lý đào tạo dựa trên các dự án thực tế (Project-based) và lộ trình cá nhân hóa nhờ ứng dụng AI. Chúng tôi không chỉ dạy bạn cách sử dụng công cụ, mà còn truyền tải tư duy khai phá giá trị từ dữ liệu để đưa ra quyết định kinh doanh chính xác.
Tìm hiểu thêm về các khóa học TẠI ĐÂY:
Lộ trình đào tạo Data Engineer
Lộ trình đào tạo Data Analyst
Lộ trình đào tạo Tester
Khóa học Data Engineer nâng cao – Thực chiến 5 dự án doanh nghiệp
Khóa học Data Analyst nâng cao – Thực chiến 5 dự án doanh nghiệp
