

Trong giới Data Engineer, có một câu nói đùa nhưng cực kỳ thực tế: “Pipeline không bao giờ chạy hoàn hảo 100% vào lần đầu tiên”. Cho dù bạn dùng những công cụ hiện đại nhất như Airflow, Spark hay dbt, thực tế vận hành luôn khắc nghiệt hơn lý thuyết. Một ngày đẹp trời, mạng chập chờn, database nguồn quá tải, hay đơn giản là một đoạn mã biến đổi bị lỗi khiến job dừng lại ở con số 90%.
Lúc này, câu hỏi quan trọng nhất không phải là “Làm sao để pipeline không bao giờ fail?”, mà là: “Khi nhấn nút chạy lại (rerun), dữ liệu của bạn sẽ ra sao?”. Nếu câu trả lời là dữ liệu bị nhân đôi, báo cáo tài chính sai lệch, thì bạn đang đối mặt với một hệ thống thiếu tính Idempotency.
Mục lục
I. Nỗi ám ảnh mang tên “Rerun” và những hệ lụy
Trong môi trường sản xuất, việc pipeline phải chạy lại là chuyện diễn ra như cơm bữa. Có vô vàn tình huống đẩy chúng ta vào thế phải nhấn nút rerun:
- Job bị đứt gánh giữa đường: Đang load nửa chừng thì mất kết nối database.
- Hệ thống nguồn bị lỗi: Dữ liệu nguồn hôm trước bị sai, đối tác yêu cầu chúng ta xóa đi nạp lại.
- Backfill dữ liệu cũ: Bạn cần tính toán lại chỉ số của cả năm ngoái vì logic kinh doanh thay đổi.
- Cơ chế tự động của Orchestrator: Airflow hay Dagster thường được cấu hình tự động retry. Nếu job fail, nó sẽ tự chạy lại mà không cần hỏi ý kiến bạn.
Vấn đề lớn nếu pipeline không có tính lũy đẳng
Nếu một pipeline “cứ có gì là insert nấy”, việc chạy lại sẽ gây ra thảm họa trùng lặp dữ liệu (duplicate). Một đơn hàng 100 USD sau hai lần chạy sẽ biến thành 200 USD trên báo cáo của sếp. Niềm tin của người dùng vào dữ liệu sẽ sụt giảm ngay lập tức khi họ thấy các con số nhảy múa vô lý.
Vì vậy, một pipeline chuẩn mực bắt buộc phải đảm bảo: Dù chạy một lần hay một trăm lần với cùng một đầu vào, kết quả cuối cùng tại đích đến phải hoàn toàn giống nhau. Đây chính là nguyên tắc Idempotency.
II. Idempotency là gì và nó khác gì với Exactly-once?
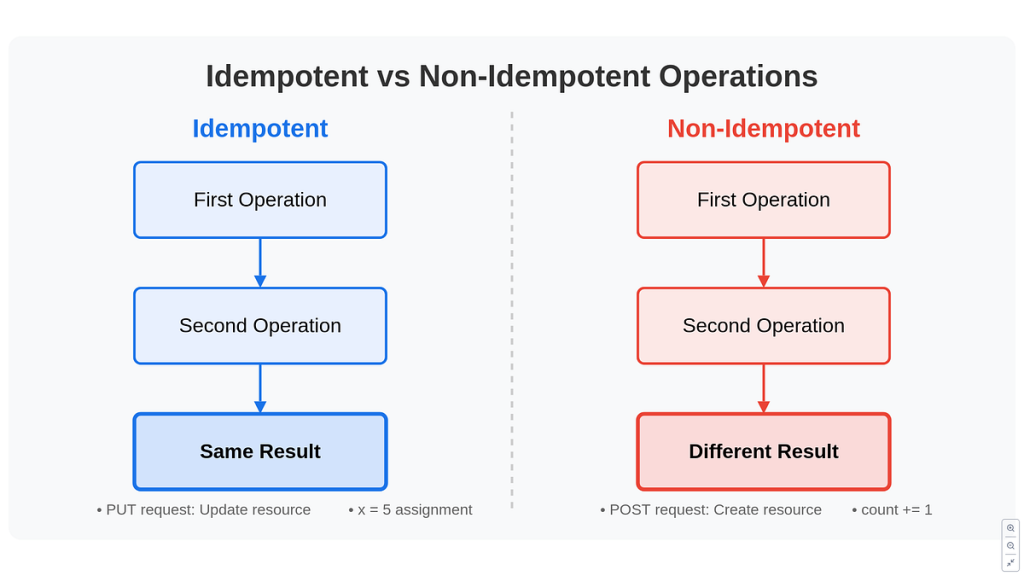
Khái niệm Idempotency (tính lũy đẳng) xuất phát từ toán học. Trong tin học, một thao tác được gọi là idempotent nếu việc thực hiện nó nhiều lần không làm thay đổi trạng thái hệ thống vượt quá lần thực hiện đầu tiên.
1. Ví dụ để phân biệt nhanh
- Non-idempotent: Sử dụng lệnh INSERT INTO sales SELECT * FROM staging;. Chạy lần 1 có 100 dòng, chạy lần 2 thành 200 dòng.
- Idempotent: Sử dụng lệnh MERGE hoặc UPSERT. Nếu đơn hàng đã tồn tại, hệ thống chỉ cập nhật; nếu chưa có, nó mới thêm vào. Chạy bao nhiêu lần thì bảng vẫn chỉ có đúng 100 dòng đó.
2. Idempotency vs Exactly-once
Nhiều người thường nhầm lẫn hai khái niệm này. Exactly-once (xử lý đúng một lần) là một thử thách kỹ thuật cực khó và tốn kém tài nguyên để đảm bảo mọi bản ghi chỉ đi qua hệ thống đúng một lần duy nhất.
Trong khi đó, Idempotency thực tế và dễ triển khai hơn. Chúng ta chấp nhận việc hệ thống có thể xử lý một bản ghi nhiều lần (do retry), nhưng thiết kế sao cho kết quả cuối cùng không bị sai lệch.
III. Tại sao Idempotency là “xương sống” của hệ thống dữ liệu?
1. Đối phó với lỗi hệ thống và mạng lưới
Trong production, lỗi là “đặc sản”. Cluster có thể sập, API có thể trả về lỗi 500. Khi các công cụ như Airflow tự động thực hiện lệnh retry, Idempotency là lớp màng bảo vệ giúp việc tự phục hồi này không vô tình làm hỏng dữ liệu.
2. Phục vụ việc sửa lỗi và chạy lại lịch sử (Backfill)
Khi phát hiện logic tính toán cũ bị sai (ví dụ tính thiếu thuế cho cả quý trước), bạn chỉ cần sửa code và nhấn chạy lại cho khoảng thời gian đó. Nếu pipeline idempotent, nó sẽ tự động ghi đè các bản ghi cũ bằng số liệu mới chính xác mà không làm bảng Warehouse bị “phình” ra vô tội vạ.
3. “Tự vệ” trước nguồn dữ liệu không đáng tin cậy
Đôi khi chính nguồn dữ liệu (như Kafka stream hay API bên thứ ba) đã gửi trùng bản ghi do lỗi hệ thống của họ. Một pipeline tốt phải có khả năng lọc bỏ những thứ trùng lặp này thông qua cơ chế so khớp khóa (Key matching).
IV. 5 kỹ thuật triển khai Idempotency thực chiến
Để biến một pipeline bình thường thành Idempotent, các kỹ sư thường áp dụng một hoặc kết hợp các kỹ thuật sau:
1. Upsert (MERGE)
Đây là cách phổ biến nhất trong SQL. Thay vì dùng INSERT, chúng ta dùng lệnh MERGE ( Snowflake, BigQuery) hoặc INSERT … ON CONFLICT (Postgres). Hệ thống dựa trên một Unique Key để quyết định: Đã có thì UPDATE, chưa có thì INSERT.
2. Partition Overwrite
Trong các Data Lake (như S3) hoặc bảng phân vùng, kỹ thuật này cực kỳ hiệu quả. Nếu bạn chạy lại dữ liệu ngày 01/03, hệ thống sẽ thực hiện: “Xóa sạch phân vùng ngày 01/03 và ghi đè dữ liệu mới vào”. Cách này nhanh và không cần so khớp từng dòng.
3. Kiến trúc Staging Area
Luồng dữ liệu chuẩn thường đi qua 3 bước:
- Bản nháp (Staging): Load dữ liệu thô vào bảng tạm.
- Làm sạch (Deduplicate): Dùng các hàm như ROW_NUMBER() để loại bỏ trùng lặp ngay tại Staging.
- Đích đến (Warehouse): Merge dữ liệu sạch từ Staging vào bảng chính.
4. Checkpoint và Offset Tracking
Đối với các hệ thống streaming (Spark, Flink), Idempotency được duy trì bằng cách lưu lại “dấu chân” (checkpoint). Hệ thống ghi nhớ mình đã xử lý đến đâu để khi restart, nó không nạp lại những gì đã xong.
V. Những sai lầm phổ biến cần tránh
- Chỉ lọc trùng ở bước cuối (Downstream): Nhiều người để mặc pipeline nạp dữ liệu rác rồi hy vọng lúc làm báo cáo sẽ dùng DISTINCT để lọc lại. Đây là cách làm cực kỳ lãng phí tài nguyên và làm chậm báo cáo.
- Không thiết kế Unique Key ngay từ đầu: Một bảng dữ liệu không có khóa duy nhất (như ID đơn hàng) là một “bom hẹn giờ”. Bạn sẽ không thể triển khai được bất kỳ cơ chế Idempotency nào nếu không biết dòng nào ứng với dòng nào.
- Tin tưởng tuyệt đối vào hệ thống điều phối: Nhớ rằng Airflow chỉ giúp bạn chạy lại, còn việc dữ liệu có bị trùng hay không hoàn toàn nằm ở logic code của bạn.
VI. Kết luận
Trong kỷ nguyên Big Data, độ tin cậy (Reliability) luôn quan trọng hơn tốc độ. Một hệ thống có thể chạy chậm một chút, nhưng tuyệt đối không được đưa ra con số sai.Theo tài liệu về vận hành dữ liệu của Google Cloud Architecture Framework, Idempotency là cột trụ để đạt được sự ổn định. Khi bạn thiết kế một pipeline an toàn khi chạy lại, bạn không chỉ bảo vệ dữ liệu mà còn đang bảo vệ chính sự an tâm của mình. Bạn có thể tự tin rằng: Dù hệ thống có fail nửa đêm, thì sau một lệnh rerun, mọi thứ sẽ lại chính xác và nhất quán.
INDA Academy tự hào là đơn vị tiên phong trong việc đào tạo phân tích dữ liệu và AI chuyên sâu, đặc biệt cho khối ngành Ngân hàng – Tài chính – Bảo hiểm tại Việt Nam. Sau hơn 12 năm “thực chiến” cùng những dòng chảy dữ liệu khổng lồ, chúng tôi đã xây dựng nên một hệ sinh thái đào tạo toàn diện, giúp hàng nghìn học viên chuyển mình từ người mới bắt đầu trở thành những chuyên gia lành nghề, sẵn sàng đáp ứng tiêu chuẩn khắt khe của các doanh nghiệp lớn.
Điểm khác biệt lớn nhất tại INDA chính là triết lý đào tạo dựa trên các dự án thực tế (Project-based) và lộ trình cá nhân hóa nhờ ứng dụng AI. Chúng tôi không chỉ dạy bạn cách sử dụng công cụ, mà còn truyền tải tư duy khai phá giá trị từ dữ liệu để đưa ra quyết định kinh doanh chính xác.
Tìm hiểu thêm về các khóa học TẠI ĐÂY:
Lộ trình đào tạo Data Engineer
Lộ trình đào tạo Data Analyst
Lộ trình đào tạo Tester
Khóa học Data Engineer nâng cao – Thực chiến 5 dự án doanh nghiệp
Khóa học Data Analyst nâng cao – Thực chiến 5 dự án doanh nghiệp

