

Trong công việc của một Data Engineer, việc xây dựng một pipeline để chuyển dữ liệu từ điểm A sang điểm B thường không khó. Thử thách thực sự chỉ xuất hiện sau một thời gian vận hành trên môi trường thực tế: dữ liệu bị trùng lặp do job chạy lại, hệ thống hạ nguồn bị treo vì dữ liệu nguồn thay đổi cấu trúc đột ngột, hay chi phí vận hành tăng vọt khi khối lượng dữ liệu lớn dần.
Thực tế, phần lớn thời gian bảo trì hệ thống thường đổ dồn vào việc giải quyết những vấn đề mang tính lặp lại. Để không phải xử lý sự cố theo kiểu “đụng đâu vá đó”, việc áp dụng các Design Patterns (mô hình thiết kế) chuẩn ngay từ đầu là điều bắt buộc. Đây không phải là những lý thuyết xa rời thực tế, mà là những bộ khung kiến trúc giúp pipeline giữ được sự ổn định ngay cả khi dữ liệu biến động.
Mục lục
1. Mở bài: Vì sao Data Pipeline cần Design Patterns?
Hầu hết chúng ta đều bắt đầu với một pipeline đơn giản: đọc dữ liệu từ một API hoặc Database, biến đổi một chút rồi đẩy vào kho lưu trữ. Pipeline đó có thể chạy rất mượt với dữ liệu mẫu, nhưng khi đưa vào production, các vấn đề bắt đầu lộ diện.
Những vấn đề phổ biến khi xây dựng pipeline
Vấn đề đầu tiên là sự “giòn” (brittle) của hệ thống. Pipeline có thể hoạt động tốt hôm nay, nhưng chỉ cần phía upstream (nguồn dữ liệu) thay đổi một kiểu dữ liệu hoặc thêm một cột mới, toàn bộ luồng xử lý phía sau sẽ đổ vỡ. Tiếp theo là vấn đề bảo trì. Một pipeline được viết theo kiểu “mì ăn liền” thường cực kỳ khó debug khi có lỗi. Kỹ sư phải tốn hàng giờ đồng hồ chỉ để tìm xem dữ liệu bị sai ở bước nào.
Ngoài ra, các hệ thống thiếu thiết kế chuẩn thường xử lý rất kém các tình huống:
- Retry: Khi job fail giữa chừng, việc chạy lại dẫn đến duplicate dữ liệu.
- Late data: Dữ liệu đến muộn sau khi job đã chốt sổ.
- Schema change: Cấu trúc dữ liệu nguồn thay đổi không báo trước.
Thực tế trong hệ thống dữ liệu phát triển
Khi một doanh nghiệp phát triển, hệ thống dữ liệu không đứng yên. Số lượng nguồn dữ liệu (Data Source) tăng lên từ vài cái đến vài chục cái; khối lượng dữ liệu (Volume) tăng từ Gigabytes lên Terabytes. Nếu không có các design pattern chuẩn, hệ thống sẽ trở nên cực kỳ phức tạp và dễ lỗi (brittle), khó debug và gần như không thể mở rộng (scale).
Design Patterns sinh ra để chuẩn hóa cách chúng ta xây dựng pipeline, giúp giảm thiểu lỗi chủ quan và tạo ra một ngôn ngữ chung cho đội ngũ kỹ sư. Trong bài viết này, chúng ta sẽ đi sâu vào 8 pattern phổ biến nhất mà bất kỳ Data Platform nào cũng cần đến.
2. Design Pattern trong Data Pipeline là gì?
Hiểu một cách đơn giản, Design Pattern trong data pipeline là những mô hình kiến trúc được tái sử dụng để giải quyết các vấn đề lặp đi lặp lại trong quá trình xử lý dữ liệu. Thay vì mỗi kỹ sư tự nghĩ ra một cách xử lý lỗi khác nhau, chúng ta áp dụng một khuôn mẫu đã được chứng minh hiệu quả.
Các loại vấn đề mà pattern thường giải quyết
Chúng ta có thể chia các vấn đề trong data pipeline thành 5 nhóm chính:
| Nhóm vấn đề | Ví dụ cụ thể |
| Reliability (Độ tin cậy) | Xử lý retry, chống trùng lặp dữ liệu (duplicate). |
| Scalability (Khả năng mở rộng) | Đảm bảo hệ thống vẫn chạy tốt khi dữ liệu tăng nhanh. |
| Maintainability (Khả năng bảo trì) | Cấu trúc code và luồng đi rõ ràng, dễ sửa chữa. |
| Data Correctness (Tính chính xác) | Xử lý dữ liệu đến muộn, chạy lại dữ liệu lịch sử (backfill). |
| Observability (Khả năng quan sát) | Giám sát sức khỏe và chất lượng dữ liệu của pipeline. |
Thông thường, các pattern này sẽ được phân loại dựa trên giai đoạn của dữ liệu như: Ingestion (thu thập), Processing (xử lý), Quality (chất lượng) và Operation (vận hành).
3. Các Data Pipeline Design Patterns phổ biến
Trong quá trình xây dựng hệ thống dữ liệu, data engineer thường sử dụng các data pipeline design patterns nhằm giải quyết những bài toán phổ biến như xử lý dữ liệu quy mô lớn, tối ưu độ trễ hoặc đảm bảo khả năng mở rộng của hệ thống. Các pattern này đóng vai trò như những mô hình kiến trúc đã được kiểm chứng, giúp đội ngũ kỹ thuật thiết kế pipeline dữ liệu hiệu quả và dễ bảo trì hơn.
Tùy vào mục tiêu của hệ thống – chẳng hạn như phân tích dữ liệu lịch sử, xử lý dữ liệu thời gian thực hoặc xây dựng nền tảng dữ liệu hiện đại – các tổ chức có thể lựa chọn những pattern khác nhau. Dưới đây là một số design pattern phổ biến thường được sử dụng trong các hệ thống data pipeline hiện nay.
Nguồn: Monte Carlo Data, GeeksforGeeks
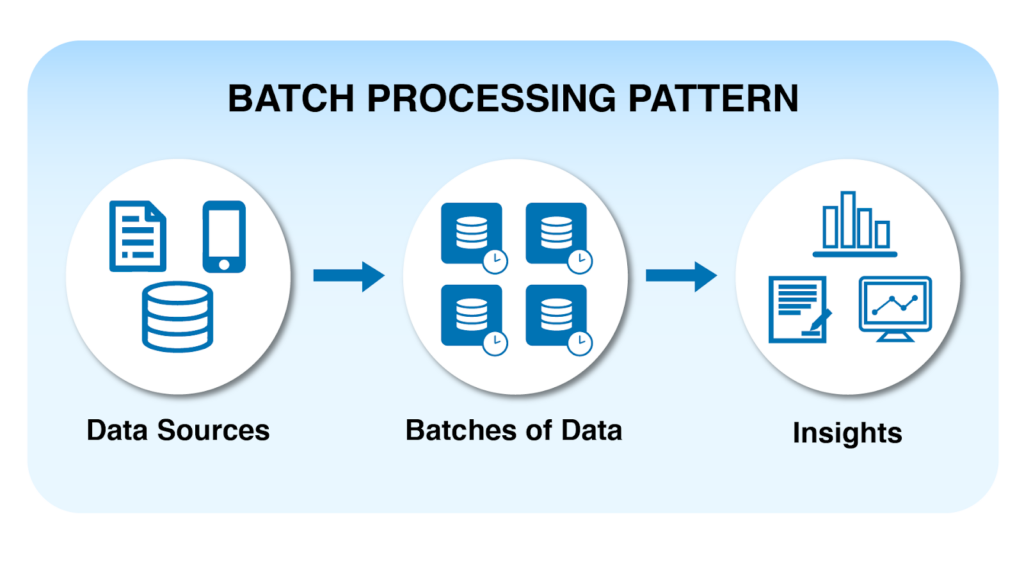
Batch Processing
Batch processing là mô hình xử lý dữ liệu theo từng lô. Trong cách tiếp cận này, dữ liệu được thu thập trong một khoảng thời gian nhất định và được xử lý định kỳ thông qua các job theo lịch. Đây là mô hình phổ biến trong các hệ thống data warehouse truyền thống, nơi dữ liệu thường được xử lý hàng giờ hoặc hàng ngày để phục vụ các báo cáo và phân tích dữ liệu lịch sử.
Ưu điểm của batch processing là triển khai tương đối đơn giản và chi phí vận hành thấp. Tuy nhiên, do dữ liệu chỉ được xử lý theo từng đợt nên độ trễ thường cao và không phù hợp với các ứng dụng cần dữ liệu theo thời gian thực.
Nguồn: Monte Carlo Data
Stream Processing
Stream processing là mô hình xử lý dữ liệu theo thời gian thực. Trong pipeline streaming, dữ liệu được xử lý ngay khi nó được tạo ra thay vì chờ gom lại thành batch. Cách tiếp cận này giúp hệ thống phản ứng nhanh với các sự kiện mới và cung cấp dữ liệu gần realtime cho các ứng dụng.
Stream processing thường được sử dụng trong các hệ thống như phân tích hành vi người dùng, phát hiện gian lận giao dịch hoặc monitoring hệ thống. Tuy nhiên, so với batch processing, các hệ thống streaming thường phức tạp hơn và yêu cầu hạ tầng xử lý dữ liệu mạnh hơn.
Nguồn: Monte Carlo Data
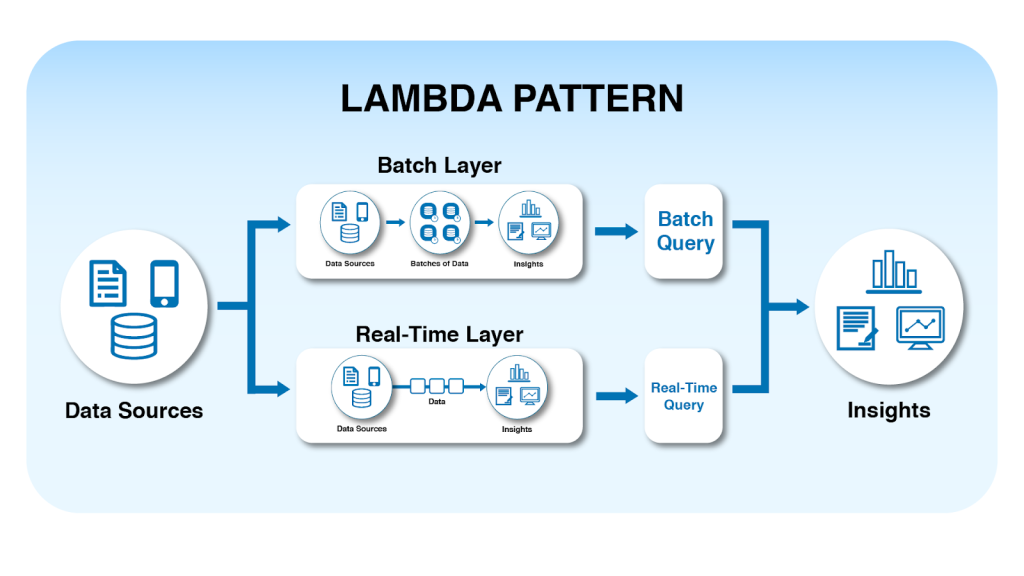
Lambda Architecture
Lambda Architecture là một mô hình kiến trúc kết hợp cả batch processing và stream processing nhằm tận dụng ưu điểm của hai cách tiếp cận này. Trong kiến trúc Lambda, dữ liệu được xử lý qua hai pipeline khác nhau: một pipeline batch để đảm bảo tính chính xác của dữ liệu lịch sử và một pipeline streaming để cung cấp dữ liệu gần realtime.
Sau khi được xử lý, dữ liệu từ hai pipeline này sẽ được hợp nhất tại serving layer để phục vụ truy vấn và phân tích. Mặc dù mang lại độ chính xác cao và khả năng xử lý dữ liệu realtime, Lambda Architecture thường bị đánh giá là khá phức tạp do phải duy trì hai pipeline riêng biệt.
Nguồn: Monte Carlo Data, GeeksforGeeks
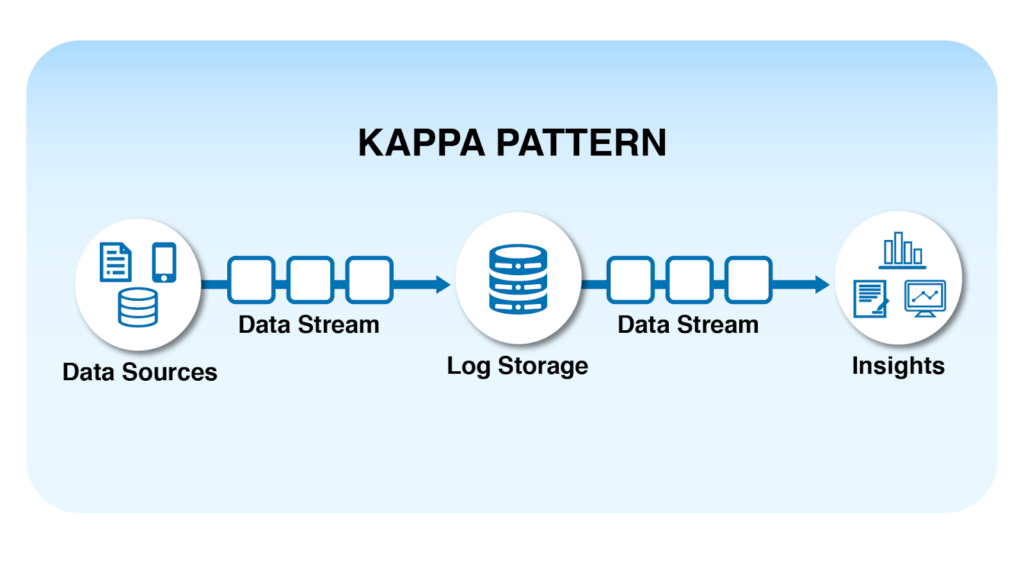
Kappa Architecture
Kappa Architecture được thiết kế nhằm đơn giản hóa Lambda Architecture bằng cách chỉ sử dụng một pipeline streaming duy nhất để xử lý toàn bộ dữ liệu. Trong mô hình này, dữ liệu được lưu trữ dưới dạng log sự kiện và được xử lý thông qua hệ thống stream processing.
Khi cần xử lý lại dữ liệu lịch sử, hệ thống có thể phát lại các sự kiện từ log để thực hiện lại các bước xử lý. Nhờ vậy, kiến trúc Kappa giúp giảm độ phức tạp của hệ thống so với Lambda Architecture, đặc biệt trong các hệ thống realtime analytics hoặc event-driven architecture.
Nguồn: Monte Carlo Data, GeeksforGeeks
ETL và ELT
ETL (Extract – Transform – Load) là pattern truyền thống trong các hệ thống data warehouse. Trong quy trình này, dữ liệu được trích xuất từ nhiều nguồn khác nhau, sau đó được làm sạch và transform trước khi được nạp vào hệ thống lưu trữ.
Trong khi đó, ELT (Extract – Load – Transform) là cách tiếp cận hiện đại hơn, trong đó dữ liệu được nạp trực tiếp vào hệ thống lưu trữ trước và quá trình transform sẽ được thực hiện bên trong data warehouse. Cách tiếp cận này tận dụng sức mạnh tính toán của các hệ thống dữ liệu hiện đại như cloud data warehouse, giúp pipeline linh hoạt và dễ mở rộng hơn.
Nguồn: Monte Carlo Data
Data Mesh
Data Mesh là một mô hình kiến trúc dữ liệu phân tán, trong đó quyền sở hữu dữ liệu được phân chia theo từng domain trong tổ chức. Thay vì một data team trung tâm quản lý toàn bộ pipeline, mỗi domain sẽ chịu trách nhiệm xây dựng và vận hành pipeline dữ liệu của riêng mình.
Cách tiếp cận này giúp tăng khả năng mở rộng của hệ thống dữ liệu và giảm bottleneck trong các tổ chức lớn. Tuy nhiên, Data Mesh cũng đòi hỏi cơ chế quản trị dữ liệu (data governance) mạnh để đảm bảo tính nhất quán của dữ liệu trên toàn hệ thống.
Nguồn: Monte Carlo Data
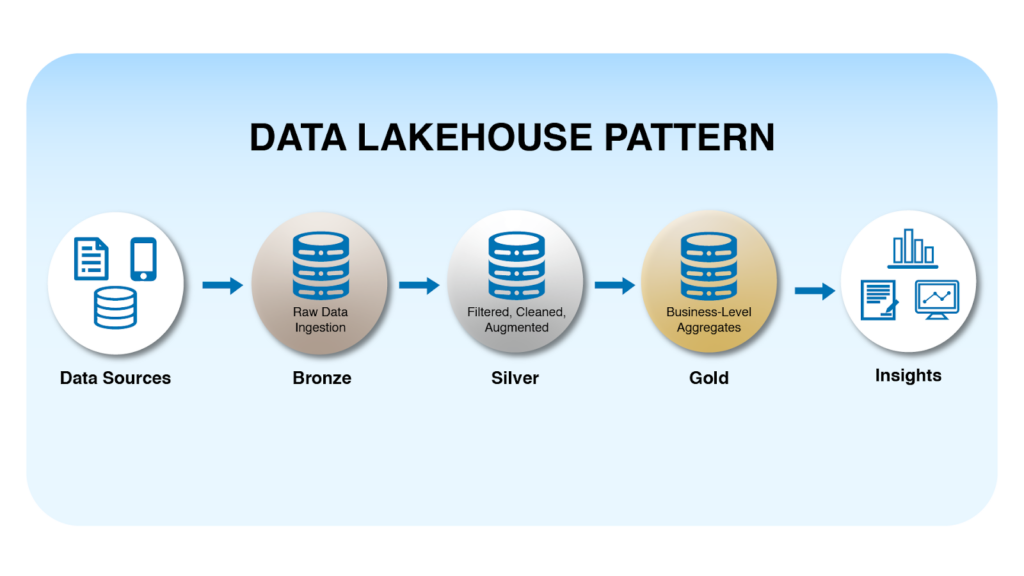
Data Lakehouse
Data Lakehouse là một kiến trúc dữ liệu hiện đại kết hợp ưu điểm của data lake và data warehouse. Trong mô hình này, dữ liệu thô được lưu trữ trong data lake nhưng vẫn có thể được truy vấn và xử lý hiệu quả giống như trong data warehouse.
Các pipeline lakehouse thường được tổ chức theo ba tầng dữ liệu: Bronze (dữ liệu thô), Silver (dữ liệu đã được làm sạch) và Gold (dữ liệu đã được tối ưu cho phân tích). Kiến trúc này ngày càng phổ biến vì nó có thể hỗ trợ cả phân tích dữ liệu truyền thống lẫn các ứng dụng machine learning và AI.
Nguồn: Monte Carlo Data
Bảng tóm tắt các Data Pipeline Design Patterns
| Pattern | Mục đích chính | Độ trễ | Độ phức tạp |
| Batch Processing | Phân tích dữ liệu định kỳ | Cao | Thấp |
| Stream Processing | Xử lý dữ liệu realtime | Thấp | Cao |
| Lambda Architecture | Kết hợp batch và streaming | Thấp | Rất cao |
| Kappa Architecture | Streaming đơn giản hóa Lambda | Thấp | Trung bình |
| ETL | Chuẩn hóa dữ liệu trước khi lưu | Trung bình | Trung bình |
| ELT | Transform trong data warehouse | Trung bình | Thấp |
| Data Mesh | Phân quyền quản lý dữ liệu | Phụ thuộc hệ thống | Cao |
| Data Lakehouse | Thống nhất data lake và warehouse | Trung bình | Trung bình |
4. Kiến trúc Data Pipeline tổng thể
Trong thực tế, một pipeline chuẩn sẽ không dùng đơn lẻ một pattern mà là sự kết hợp của nhiều mô hình. Luồng đi điển hình sẽ như sau:
- Ingestion: Dữ liệu đi qua lớp bảo vệ của Data Contract.
- Staging: Dữ liệu được nạp vào lớp tạm thời bằng cơ chế Idempotent để chống trùng lặp.
- Transformation: Xử lý Incremental để tiết kiệm tài nguyên, kết hợp với xử lý Late-arriving data.
- Storage: Dữ liệu được lưu vào kho theo chiến lược Partitioning khoa học.
- Monitoring: Toàn bộ quá trình được giám sát bởi hệ thống Observability.
5. Best Practices khi áp dụng Design Pattern
Mặc dù các pattern này rất hữu ích, nhưng việc áp dụng chúng cũng cần sự cân nhắc:
- Không áp dụng quá sớm (Overengineering): Nếu bạn chỉ xử lý vài nghìn bản ghi mỗi ngày, có lẽ bạn chưa cần đến một hệ thống CDC hay Data Contract phức tạp. Hãy để nhu cầu thực tế dẫn dắt kiến trúc.
- Ưu tiên Reliability trước Performance: Một pipeline chạy nhanh nhưng hay ra kết quả sai thì vô giá trị. Hãy đảm bảo tính chính xác và khả năng chạy lại (Idempotency) trước khi tìm cách tối ưu tốc độ.
- Thiết kế để luôn có thể rerun: Hãy luôn giả định rằng pipeline sẽ hỏng vào một lúc nào đó. Khi nó hỏng, việc sửa chữa và chạy lại phải thật đơn giản.
6. Kết luận
Xây dựng data pipeline không chỉ là viết code để chuyển đổi dữ liệu, mà là thiết kế một hệ thống có khả năng chịu lỗi, dễ bảo trì và sẵn sàng mở rộng. Hiểu và áp dụng đúng 8 design pattern trên – từ Idempotency, Incremental Processing cho đến Data Contract – chính là nền tảng để bạn tạo ra những hệ thống dữ liệu đạt chuẩn production-grade.
Đầu tư vào kiến trúc ngay từ đầu có thể tốn thêm một chút thời gian, nhưng nó sẽ giúp bạn tiết kiệm hàng trăm giờ debug và hàng ngàn USD chi phí vận hành sau này.
INDA Academy tự hào là đơn vị tiên phong trong việc đào tạo phân tích dữ liệu và AI chuyên sâu, đặc biệt cho khối ngành Ngân hàng – Tài chính – Bảo hiểm tại Việt Nam. Sau hơn 12 năm “thực chiến” cùng những dòng chảy dữ liệu khổng lồ, chúng tôi đã xây dựng nên một hệ sinh thái đào tạo toàn diện, giúp hàng nghìn học viên chuyển mình từ người mới bắt đầu trở thành những chuyên gia lành nghề, sẵn sàng đáp ứng tiêu chuẩn khắt khe của các doanh nghiệp lớn.
Điểm khác biệt lớn nhất tại INDA chính là triết lý đào tạo dựa trên các dự án thực tế (Project-based) và lộ trình cá nhân hóa nhờ ứng dụng AI. Chúng tôi không chỉ dạy bạn cách sử dụng công cụ, mà còn truyền tải tư duy khai phá giá trị từ dữ liệu để đưa ra quyết định kinh doanh chính xác.
Tìm hiểu thêm về các khóa học TẠI ĐÂY:
Lộ trình đào tạo Data Engineer
Lộ trình đào tạo Data Analyst
Lộ trình đào tạo Tester
Khóa học Data Engineer nâng cao – Thực chiến 5 dự án doanh nghiệp
Khóa học Data Analyst nâng cao – Thực chiến 5 dự án doanh nghiệp
Bài viết liên quan:
 [Series: Checklist Ra Quyết Định] Bài 2: Bạn Đã Thực Sự Sẵn Sàng Học Data Engineer?
[Series: Những hiểu lầm về nghề Data] Bài 2: Những hiểu lầm về Data Engineer khiến người mới chọn sai nghề
Data Engineer và Data Analyst Khác Nhau Thế Nào? So Sánh Dễ Hiểu Cho Sinh Viên Năm 3–4
Kỹ Năng Mềm Cho Data Engineer: Những Kỹ Năng Mềm Cơ Bản Nhất Để Giao Tiếp Hiệu Quả Với Product Manager và Data Scientist
Hướng Dẫn Viết CV Data Engineer Đúng Chuẩn 2026
[Series: Checklist Ra Quyết Định] Bài 2: Bạn Đã Thực Sự Sẵn Sàng Học Data Engineer?
[Series: Những hiểu lầm về nghề Data] Bài 2: Những hiểu lầm về Data Engineer khiến người mới chọn sai nghề
Data Engineer và Data Analyst Khác Nhau Thế Nào? So Sánh Dễ Hiểu Cho Sinh Viên Năm 3–4
Kỹ Năng Mềm Cho Data Engineer: Những Kỹ Năng Mềm Cơ Bản Nhất Để Giao Tiếp Hiệu Quả Với Product Manager và Data Scientist
Hướng Dẫn Viết CV Data Engineer Đúng Chuẩn 2026
 Data Analyst, Data Engineer và Tester: Khác nhau điểm nào và ai phù hợp? (Cập nhật 2026)
Data Analyst, Data Engineer và Tester: Khác nhau điểm nào và ai phù hợp? (Cập nhật 2026)