

Trong giới kỹ thuật dữ liệu, có một câu nói đầy cay đắng: “Pipeline báo xanh không có nghĩa là dữ liệu đúng”. Bạn có thể thức dậy vào một buổi sáng thứ Hai, kiểm tra hệ thống điều phối và thấy tất cả các task đều hiển thị màu xanh lục hoàn hảo, nhưng ngay sau đó là hàng loạt tin nhắn từ bộ phận Business Intelligence phàn nàn rằng doanh thu trên Dashboard bị sụt giảm 90% hoặc dữ liệu khách hàng bị nhân đôi một cách vô lý.
Xây dựng một Data Pipeline mà không có chiến lược monitoring (giám sát) bài bản giống như việc lái máy bay trong sương mù mà không có bảng điều khiển. Bạn vẫn đang di chuyển, nhưng không biết mình đang ở đâu, liệu động cơ có đang quá nhiệt hay không, và quan trọng nhất là bạn có đang đi đúng hướng. Monitoring không chỉ là việc kiểm tra xem “job có chạy không”, mà là bảo chứng cho niềm tin của toàn bộ doanh nghiệp vào dữ liệu.
Mục lục
I. Bản chất của Monitoring: Từ trạng thái hệ thống đến sức khỏe dữ liệu
Trong kỷ nguyên Big Data, một pipeline hiện đại là sự kết hợp phức tạp của hàng trăm công đoạn: từ nạp dữ liệu (Ingestion), chuẩn hóa (Staging) đến biến đổi chuyên sâu (Transformation). Mỗi bước này đều tiềm ẩn những rủi ro thầm lặng. Một hệ thống monitoring chiến lược không nên chỉ dừng lại ở việc báo cáo “thành công” hay “thất bại”, mà phải đóng vai trò như một hệ thống phản ứng nhanh, giúp phát hiện các lỗi dữ liệu trước khi chúng kịp lan tới người dùng cuối.
Để làm được điều này, chúng ta cần phân tách monitoring thành hai cấp độ cốt lõi:
- Pipeline Monitoring (Giám sát dòng chảy kỹ thuật): Tập trung vào việc đảm bảo các job thực thi đúng giờ, không bị sập và tài nguyên hạ tầng ổn định.
- Data Monitoring (Giám sát chất lượng nội dung): Trả lời cho câu hỏi quan trọng nhất: “Dữ liệu được nạp vào có đúng logic và đáng tin hay không?”.
Sự kết hợp giữa hai lớp này tạo nên một hệ sinh thái giám sát toàn diện, giúp đội ngũ kỹ sư chuyển từ thế bị động (chờ người dùng báo lỗi) sang thế chủ động (phát hiện và xử lý lỗi trước khi người dùng nhận ra).
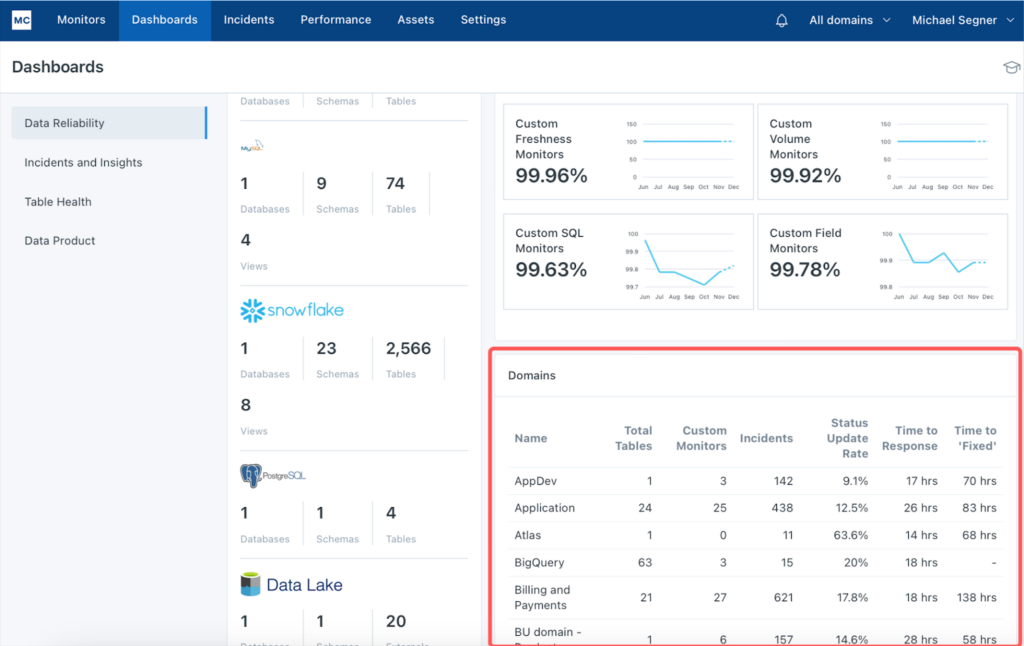
II. Tại sao các hệ thống giám sát truyền thống thường thất bại?
Sai lầm phổ biến nhất của các đội ngũ dữ liệu là đánh đồng giữa Trạng thái Task và Sức khỏe Dữ liệu. Một task ETL có thể thực thi hoàn hảo (Status: Success) đơn giản vì nó đã hoàn thành việc đọc dữ liệu từ nguồn và ghi vào kho mà không gặp lỗi cú pháp. Tuy nhiên, nếu API nguồn gặp lỗi logic và chỉ trả về 10 bản ghi thay vì 10.000, hoặc một thay đổi về Schema ở thượng nguồn khiến một cột quan trọng bị chuyển thành NULL, pipeline vẫn sẽ “báo xanh”.
Đây chính là kịch bản “thất bại trong thầm lặng” (Silent Failure). Khi đó, monitoring truyền thống dựa trên log hệ thống trở nên vô dụng vì nó không thể nhìn thấy sự bất thường về mặt nội hàm. Một chiến lược giám sát thực thụ phải có khả năng “soi” vào bên trong dữ liệu để nhận diện những thay đổi bất thường về khối lượng (Volume), phân phối (Distribution) và độ tươi (Freshness).
III. Các lớp giám sát đa tầng trong một Pipeline hiện đại
Để bảo vệ toàn diện hệ thống, chúng ta cần triển khai giám sát ở nhiều lớp khác nhau, tạo thành một mạng lưới an toàn đa tầng.
1. Giám sát hạ tầng và thực thi (Infrastructure & Execution)
Đây là lớp nền tảng, theo dõi các tài nguyên kỹ thuật như CPU, RAM, bộ nhớ đệm và băng thông mạng. Tại đây, chúng ta tập trung vào các chỉ số:
- Duration (Thời gian chạy): Nếu một job thường xuyên chạy trong 10 phút nhưng đột ngột kéo dài đến 2 giờ, đó là dấu hiệu của tắc nghẽn hoặc dữ liệu đầu vào tăng đột biến.
- Retry Count (Số lần thử lại): Việc một job phải thử lại nhiều lần trước khi thành công thường báo hiệu sự không ổn định của hệ thống nguồn hoặc kết nối mạng.
2. Giám sát chất lượng dữ liệu (Data Quality)
Lớp này đi sâu vào kiểm tra tính toàn vẹn của dữ liệu thông qua các bộ quy tắc (Rules) nghiêm ngặt. Các chỉ số như tỷ lệ dữ liệu trống (Null rate), tỷ lệ trùng lặp (Duplicate rate) và sự phù hợp về kiểu dữ liệu phải được kiểm tra sau mỗi bước biến đổi. Việc áp dụng các “chốt chặn” ngay trong pipeline giúp ngăn chặn dữ liệu bẩn (dirty data) lan truyền sâu hơn vào hệ thống.
3. Giám sát độ tươi (Data Freshness)
Trong kinh doanh, dữ liệu cũ đôi khi nguy hiểm hơn dữ liệu sai. Monitoring độ tươi đảm bảo rằng báo cáo phản ánh đúng thực tại. Bằng cách theo dõi giá trị lớn nhất của cột thời gian (max(updated_at)), hệ thống sẽ cảnh báo nếu dữ liệu của một bảng quan trọng đã quá thời hạn cập nhật cam kết (SLA).
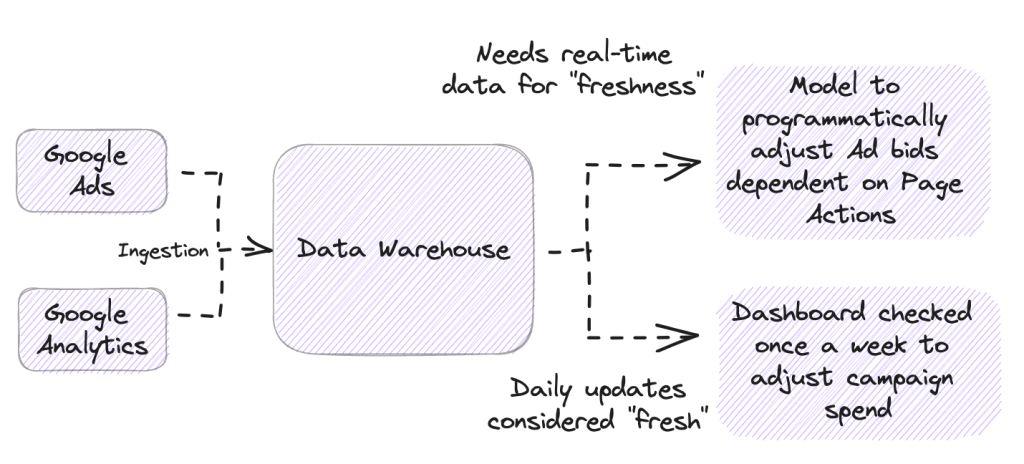
IV. Bước tiến từ Monitoring sang Data Observability
Trong những năm gần đây, khái niệm Data Observability (Khả năng quan sát dữ liệu) đã mở ra một chương mới. Khác với monitoring truyền thống vốn chỉ báo lỗi dựa trên các quy tắc cứng nhắc, Observability sử dụng Machine Learning để tự động phát hiện các điểm bất thường (Anomaly Detection).
Hệ thống Observability sẽ tự học hành vi của pipeline theo thời gian. Nó hiểu rằng vào ngày cuối tuần, lượng đơn hàng thường giảm 30%, do đó nó sẽ không gửi cảnh báo sai. Nhưng nếu lượng đơn hàng giảm 90% vào một ngày làm việc bình thường, hệ thống sẽ ngay lập tức kích hoạt báo động. Khả năng này giúp đội ngũ kỹ sư giảm thiểu tình trạng “mệt mỏi vì cảnh báo” (Alert Fatigue) và tập trung vào những vấn đề thực sự nghiêm trọng.
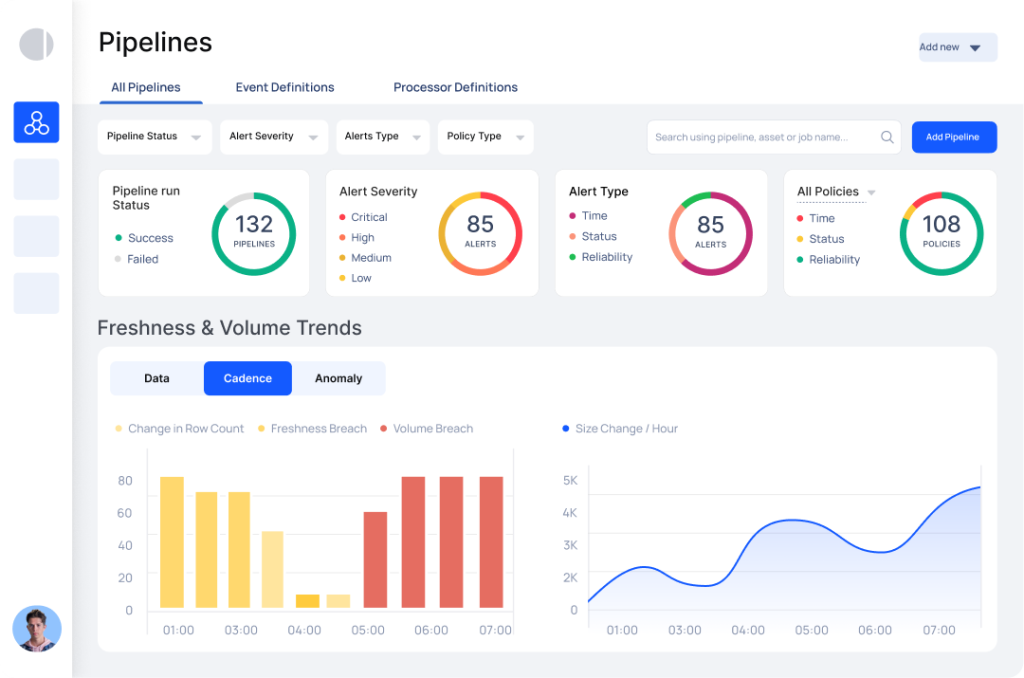
V. Các Metrics chiến lược cần theo dõi
Để xây dựng một hệ thống giám sát hiệu quả, bạn cần tập trung vào các nhóm chỉ số mang tính chiến lược sau:
- Volume (Khối lượng): Theo dõi số lượng dòng dữ liệu được nạp vào. Sự sụt giảm đột ngột thường là dấu hiệu của lỗi nạp dữ liệu, trong khi sự tăng vọt có thể là dấu hiệu của việc nhân đôi dữ liệu (duplication).
- Distribution (Phân phối): Theo dõi sự biến động của các giá trị bên trong một cột. Nếu tỷ lệ đơn hàng “Hủy” đột ngột tăng từ 5% lên 50%, có thể logic xử lý trạng thái đơn hàng đã bị lỗi.
- Schema Drift (Sự trôi dạt cấu trúc): Theo dõi việc thêm, xóa hoặc đổi tên cột ở hệ thống nguồn. Đây là “sát thủ” thầm lặng gây sập các pipeline ETL cổ điển.
- Lineage (Truy vết nguồn gốc): Hiểu rõ dữ liệu đi từ đâu đến đâu. Khi phát hiện sai sót ở tầng báo cáo, Lineage giúp bạn nhanh chóng truy ngược lại xem lỗi bắt nguồn từ bước transform nào hay từ file thô nào ở thượng nguồn.
VI. Chiến lược cảnh báo (Alerting) thông minh
Monitoring chỉ có giá trị nếu nó đưa ra cảnh báo đúng người, đúng lúc. Một chiến lược cảnh báo hiệu quả cần tuân thủ nguyên tắc phân cấp độ nghiêm trọng:
- Mức độ Cảnh báo (Warning): Dành cho các vấn đề nhỏ, chưa ảnh hưởng ngay đến kinh doanh (ví dụ: dữ liệu chậm 15 phút). Cảnh báo này chỉ cần gửi vào kênh Slack nội bộ để team theo dõi.
- Mức độ Nghiêm trọng (Critical): Dành cho các lỗi làm sập pipeline hoặc sai số liệu Dashboard doanh thu. Cảnh báo này cần kết nối với các công cụ gọi điện trực tiếp cho kỹ sư trực ca (On-call).
- Bối cảnh hóa cảnh báo: Thay vì chỉ gửi mã lỗi khô khan, cảnh báo nên chứa thông tin về mức độ ảnh hưởng: “Job A thất bại – Dashboard Tài chính hôm nay chưa có dữ liệu mới”.
VII. Những thách thức thực tế và Best Practices
Nhiều doanh nghiệp đổ rất nhiều tiền vào công cụ đắt đỏ nhưng vẫn không kiểm soát được lỗi dữ liệu. Lý do thường nằm ở việc họ bỏ qua tính Idempotency (tính nhất quán khi chạy lại). Khi monitoring phát hiện lỗi, bạn phải có cách thức an toàn để chạy lại pipeline mà không làm trùng lặp dữ liệu cũ.
Các quy tắc vàng cho Monitoring:
- Giám sát từ hạ nguồn lên thượng nguồn: Đừng chỉ nhìn vào nguồn, hãy monitor cả những bảng cuối cùng phục vụ báo cáo.
- Tích hợp kiểm thử vào CI/CD: Mỗi khi cập nhật code, hãy chạy các bộ test chất lượng dữ liệu tự động để đảm bảo logic mới không phá vỡ dữ liệu hiện tại.
- Xây dựng cơ chế tự phục hồi (Self-healing): Thiết lập cơ chế tự động thử lại (Retry) thông minh cho những lỗi tạm thời trước khi làm phiền đến con người.
VIII. Kết luận
Monitoring chiến lược không phải là một dự án làm một lần, mà là văn hóa vận hành. Một Data Pipeline bền bỉ không phải là không bao giờ lỗi, mà là có khả năng tự phát hiện lỗi và cảnh báo ngay lập tức.
Bằng cách kết hợp giữa giám sát hạ tầng, kiểm soát chất lượng dữ liệu và ứng dụng các nền tảng Observability hiện đại, bạn không chỉ bảo vệ được hệ thống kỹ thuật mà còn xây dựng được tài sản quý giá nhất: Sự tin tưởng tuyệt đối của doanh nghiệp vào từng con số dữ liệu.
INDA Academy tự hào là đơn vị tiên phong trong việc đào tạo phân tích dữ liệu và AI chuyên sâu, đặc biệt cho khối ngành Ngân hàng – Tài chính – Bảo hiểm tại Việt Nam. Sau hơn 12 năm “thực chiến” cùng những dòng chảy dữ liệu khổng lồ, chúng tôi đã xây dựng nên một hệ sinh thái đào tạo toàn diện, giúp hàng nghìn học viên chuyển mình từ người mới bắt đầu trở thành những chuyên gia lành nghề, sẵn sàng đáp ứng tiêu chuẩn khắt khe của các doanh nghiệp lớn.
Điểm khác biệt lớn nhất tại INDA chính là triết lý đào tạo dựa trên các dự án thực tế (Project-based) và lộ trình cá nhân hóa nhờ ứng dụng AI. Chúng tôi không chỉ dạy bạn cách sử dụng công cụ, mà còn truyền tải tư duy khai phá giá trị từ dữ liệu để đưa ra quyết định kinh doanh chính xác.
Tìm hiểu thêm về các khóa học TẠI ĐÂY:
Lộ trình đào tạo Data Engineer
Lộ trình đào tạo Data Analyst
Lộ trình đào tạo Tester
Khóa học Data Engineer nâng cao – Thực chiến 5 dự án doanh nghiệp
Khóa học Data Analyst nâng cao – Thực chiến 5 dự án doanh nghiệp


