

Hãy tưởng tượng bạn bước vào một thư viện khổng lồ chứa hàng tỷ cuốn sách, nhưng tất cả được xếp lộn xộn trong một căn phòng duy nhất. Để tìm một tờ hóa đơn từ ngày 12/03/2026, bạn buộc phải lật giở từng trang của mọi cuốn sách trong thư viện đó. Đó chính là kịch bản của một Data Warehouse không được thiết kế phân vùng (Partitioning).
Trong kỷ nguyên dữ liệu lớn, một bảng sự kiện (events) có thể dễ dàng chạm mốc hàng trăm Terabyte. Nếu không có một chiến lược phân vùng thông minh, mỗi câu lệnh truy vấn đơn giản sẽ trở thành một cuộc “càn quét” tài nguyên khủng khiếp, ngốn hàng nghìn USD chi phí tính toán và khiến các nhà phân tích phải chờ đợi hàng giờ liền. Partition Strategy không chỉ là một kỹ thuật tối ưu hóa; nó là nền móng giúp kho dữ liệu của bạn có khả năng mở rộng (scale) và duy trì sự nhạy bén trước sức ép của dữ liệu khổng lồ.
Mục lục
I. Partition: Khi “chia nhỏ” là chìa khóa của sự tốc độ
Về cốt lõi, Partition là kỹ thuật chia một bảng dữ liệu khổng lồ thành nhiều phần nhỏ (gọi là các phân vùng) dựa trên một tiêu chí cụ thể – thường là một cột dữ liệu. Thay vì lưu trữ toàn bộ dữ liệu trong một khối duy nhất, hệ thống sẽ tổ chức chúng thành các “ngăn kéo” riêng biệt.
Lợi ích lớn nhất mà kỹ thuật này mang lại chính là Partition Pruning (Cắt tỉa phân vùng). Khi bạn thực hiện một câu lệnh SELECT kèm điều kiện lọc, công cụ truy vấn (Query Engine) sẽ đủ thông minh để nhận ra nó chỉ cần mở đúng ngăn kéo chứa dữ liệu liên quan và bỏ qua hoàn toàn phần còn lại. Nếu bạn chỉ cần dữ liệu của ngày hôm nay, tại sao phải scan dữ liệu của mười năm trước? Việc giảm lượng dữ liệu cần quét từ 100 TB xuống còn vài GB không chỉ giúp query chạy trong tích tắc mà còn cắt giảm hóa đơn compute của bạn một cách ngoạn mục.
II. Các chiến lược phân vùng kinh điển trong thực chiến
Không có một công thức chung cho mọi bảng dữ liệu. Mỗi chiến lược phân vùng cần được “đo ni đóng giày” dựa trên đặc tính của dữ liệu và cách thức người dùng truy vấn.
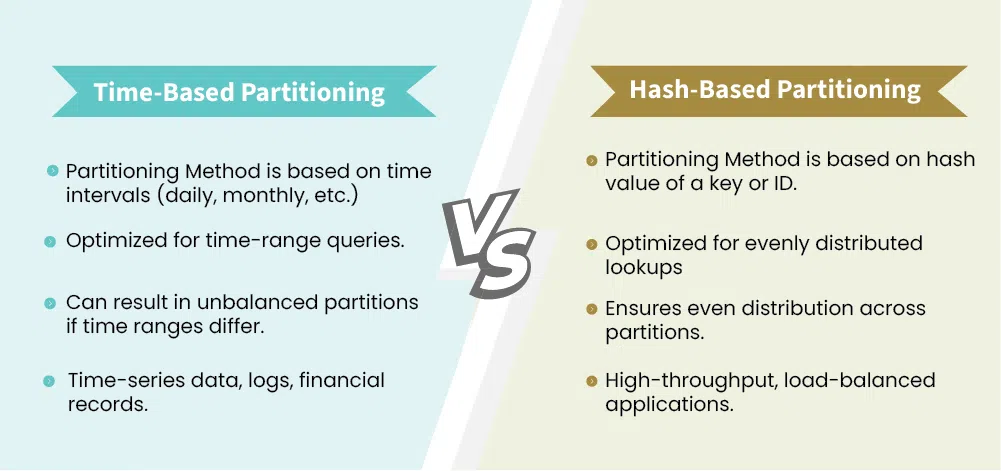
1. Phân vùng theo thời gian (Time-based Partitioning): Đây là chiến lược “vàng” và phổ biến nhất. Hầu hết các dữ liệu sự kiện như Clickstream, Log hay Giao dịch đều có tính chất thời gian rất mạnh. Việc chia dữ liệu theo ngày, tháng hoặc giờ giúp các báo cáo hàng ngày chạy cực nhanh. Theo tài liệu từ BigQuery của Google, việc phân vùng theo thời gian giúp tối ưu hóa cả hiệu suất lẫn chi phí lưu trữ vì dữ liệu cũ có thể được chuyển sang các lớp lưu trữ rẻ hơn (Cold storage) một cách dễ dàng.
2. Phân vùng theo băm (Hash Partitioning): Để tránh tình trạng “lệch dữ liệu” (Data Skew) – nơi một vài phân vùng quá lớn trong khi các phân vùng khác quá nhỏ – kỹ thuật Hash được sử dụng. Hệ thống sẽ áp dụng một hàm băm lên cột dữ liệu (như customer_id) để phân tán dữ liệu đồng đều vào một số lượng phân vùng cố định. Đây là lựa chọn hàng đầu cho các tác vụ Join lớn trong các hệ thống xử lý phân tán.
3. Phân vùng theo phạm vi (Range Partitioning): Thay vì thời gian, dữ liệu được chia theo các khoảng giá trị số. Ví dụ, bạn có thể chia bảng người dùng dựa trên user_id: từ 1-1 triệu, 1 triệu-2 triệu… Chiến lược này hiệu quả khi dữ liệu phân bố đều theo một dải số định danh, giúp tăng tốc các truy vấn tìm kiếm theo tệp khách hàng.
4. Phân vùng đa cấp (Multi-level Partitioning): Đôi khi một cấp là chưa đủ. Bạn có thể phân vùng theo date, sau đó trong mỗi ngày lại tiếp tục chia theo country. Tuy nhiên, hãy cẩn thận với “lời nguyền” quá nhiều phân vùng (Over-partitioning) khiến hệ thống mất quá nhiều thời gian quản lý metadata thay vì xử lý dữ liệu.
III. Partition vs Clustering: Cặp bài trùng trong tối ưu hóa
Một sai lầm phổ biến là nhầm lẫn giữa Partition và Clustering. Hãy coi Partition là việc chia thư viện thành các phòng theo năm xuất bản sách. Còn Clustering là việc sắp xếp các cuốn sách trong mỗi phòng đó theo bảng chữ cái tên tác giả.
Partition giúp loại bỏ các khối dữ liệu lớn không liên quan, trong khi Clustering giúp sắp xếp dữ liệu bên trong mỗi khối đó để việc tìm kiếm chi tiết trở nên nhanh hơn. Một chiến lược tối ưu thường kết hợp cả hai: Phân vùng theo cột được lọc nhiều nhất (như ngày tháng) và Cluster theo cột thường dùng để Join hoặc lọc chi tiết (như ID khách hàng).
IV. Những “hố đen” cần tránh khi thiết kế phân vùng
Thiết kế phân vùng sai cách đôi khi còn tệ hơn là không làm gì cả. Dưới đây là những sai lầm mà các Data Engineer thường mắc phải:
- Chọn cột lọc ít dùng: Nếu bạn phân vùng theo status của đơn hàng, nhưng 99% các truy vấn của người dùng lại lọc theo order_date, hệ thống vẫn sẽ phải scan toàn bộ bảng.
- Phân vùng quá vụn (Granularity quá nhỏ): Việc phân vùng đến tận mức “giây” (timestamp) sẽ tạo ra hàng triệu file nhỏ. Điều này khiến Query Engine bị “ngộp” bởi metadata và làm giảm hiệu suất nghiêm trọng. Theo kinh nghiệm thực tế, kích thước lý tưởng cho mỗi phân vùng nên nằm trong khoảng từ vài trăm MB đến vài GB tùy thuộc vào nền tảng bạn sử dụng.
- Bỏ qua hiện tượng lệch dữ liệu (Data Skew): Nếu bạn phân vùng theo country và 90% dữ liệu của bạn đến từ một quốc gia duy nhất, phân vùng đó sẽ trở thành “nút thắt cổ chai” khiến các truy vấn không thể thực hiện song song hiệu quả.
V. Triển khai Partition trên các nền tảng phổ biến
Mỗi “ông lớn” trong ngành Data Warehouse có một cách tiếp cận riêng với phân vùng:
- Google BigQuery: Hỗ trợ phân vùng theo thời gian nạp dữ liệu (Ingestion time) hoặc theo một cột DATE/TIMESTAMP cụ thể. BigQuery rất khắt khe về giới hạn số lượng phân vùng (thường là 4.000), buộc bạn phải tính toán kỹ lưỡng.
- Snowflake: Sử dụng khái niệm Micro-partitioning. Khác với cách truyền thống, Snowflake tự động quản lý việc chia nhỏ dữ liệu thành các micro-partition mà người dùng không cần can thiệp thủ công. Tuy nhiên, bạn vẫn cần định nghĩa các Clustering Keys để tối ưu hóa hiệu quả cho các bảng lớn.
- Databricks / Delta Lake: Kết hợp phân vùng thư mục truyền thống với kỹ thuật Z-Order (một dạng clustering nâng cao) để mang lại hiệu năng truy vấn đa chiều vượt trội.
VI. Mối liên kết với vòng đời dữ liệu
Chiến lược phân vùng không tồn tại độc lập. Nó liên quan chặt chẽ đến cách bạn nạp dữ liệu (Incremental Processing) và cách bạn sửa sai dữ liệu (Backfill). Một pipeline nạp dữ liệu theo ngày sẽ hoạt động hoàn hảo nhất trên một bảng được phân vùng theo ngày. Khi cần xóa hoặc nạp lại dữ liệu cho một tuần cụ thể, bạn chỉ cần tác động lên đúng các phân vùng đó mà không làm ảnh hưởng đến tính toàn vẹn của toàn bộ kho dữ liệu.
VII. Kết luận
Partition Strategy là nghệ thuật cân bằng giữa cấu trúc dữ liệu và hành vi truy vấn của người dùng. Một chiến lược phân vùng tốt không chỉ giúp “giải cứu” hiệu năng của những câu lệnh SQL mà còn là chìa khóa để kiểm soát chi phí trong kỷ nguyên điện toán đám mây.
Hãy bắt đầu bằng việc hiểu rõ hành vi của người dùng: Họ thường lọc dữ liệu theo tiêu chí nào? Khoảng thời gian nào? Khi bạn trả lời được những câu hỏi đó, chiến lược phân vùng sẽ tự khắc trở thành “đòn bẩy” mạnh mẽ nhất để nâng tầm hệ thống Data Warehouse của bạn.
INDA Academy tự hào là đơn vị tiên phong trong việc đào tạo phân tích dữ liệu và AI chuyên sâu, đặc biệt cho khối ngành Ngân hàng – Tài chính – Bảo hiểm tại Việt Nam. Sau hơn 12 năm “thực chiến” cùng những dòng chảy dữ liệu khổng lồ, chúng tôi đã xây dựng nên một hệ sinh thái đào tạo toàn diện, giúp hàng nghìn học viên chuyển mình từ người mới bắt đầu trở thành những chuyên gia lành nghề, sẵn sàng đáp ứng tiêu chuẩn khắt khe của các doanh nghiệp lớn.
Điểm khác biệt lớn nhất tại INDA chính là triết lý đào tạo dựa trên các dự án thực tế (Project-based) và lộ trình cá nhân hóa nhờ ứng dụng AI. Chúng tôi không chỉ dạy bạn cách sử dụng công cụ, mà còn truyền tải tư duy khai phá giá trị từ dữ liệu để đưa ra quyết định kinh doanh chính xác.
Tìm hiểu thêm về các khóa học TẠI ĐÂY:
Lộ trình đào tạo Data Engineer
Lộ trình đào tạo Data Analyst
Lộ trình đào tạo Tester
Khóa học Data Engineer nâng cao – Thực chiến 5 dự án doanh nghiệp
Khóa học Data Analyst nâng cao – Thực chiến 5 dự án doanh nghiệp


