

Trong làn sóng bùng nổ của trí tuệ nhân tạo tạo sinh, những cái tên như ChatGPT, Claude hay Gemini đã trở thành biểu tượng cho sức mạnh của các mô hình ngôn ngữ lớn (LLM). Tuy nhiên, có một sự thật mà các chuyên gia AI luôn nhấn mạnh: Một mô hình mạnh đến đâu cũng sẽ trở nên vô dụng nếu không được tiếp nhận nguồn dữ liệu chất lượng. Nếu LLM là bộ não, thì dữ liệu chính là tri thức và kinh nghiệm được nạp vào bộ não đó.
Tuy nhiên, việc chuẩn bị dữ liệu cho LLM không giống như việc lập bảng biểu cho các mô hình Machine Learning truyền thống. Chúng ta không còn đối mặt với các con số khô khan trong hàng và cột, mà là hàng triệu trang tài liệu văn bản, tệp PDF, email và log hệ thống.
Pipeline dữ liệu cho LLM ra đời như một dây chuyền tinh luyện, giúp chuyển hóa đống dữ liệu phi cấu trúc khổng lồ đó thành một kho tri thức tinh khiết, sẵn sàng để mô hình truy xuất và trả lời câu hỏi. Bài viết này sẽ đi sâu vào cấu trúc của một pipeline dữ liệu hiện đại cho Generative AI và cách bạn có thể tối ưu hóa nó để xây dựng các ứng dụng AI thông minh nhất.
Mục lục
1. Pipeline dữ liệu cho LLM là gì?
Pipeline dữ liệu cho LLM là một quy trình kỹ thuật khép kín bao gồm thu thập, làm sạch, chia nhỏ và chuyển đổi dữ liệu văn bản thành định dạng mà các mô hình ngôn ngữ lớn có thể hiểu và tìm kiếm được.
Khác với các pipeline dữ liệu thông thường chỉ dừng lại ở việc đổ dữ liệu vào kho lưu trữ, pipeline dành cho LLM (đặc biệt là trong hệ thống RAG – Retrieval-Augmented Generation) tập trung vào việc bảo toàn ngữ nghĩa. Theo tài liệu từ NVIDIA, mục tiêu của pipeline này là tạo ra một “External Memory” (Bộ nhớ ngoài) cho AI, giúp nó có thể tra cứu thông tin mới nhất mà không cần phải huấn luyện lại toàn bộ mô hình vốn cực kỳ tốn kém.
2. Vì sao LLM cần một pipeline dữ liệu chuyên biệt?
Nhiều người lầm tưởng rằng chỉ cần đẩy toàn bộ file PDF vào chatbot là xong. Thực tế, dữ liệu cho LLM có những đặc thù rất khác biệt so với Machine Learning truyền thống.
| Đặc điểm | Machine Learning truyền thống | Generative AI (LLM) |
| Loại dữ liệu | Dữ liệu bảng (Tabular), con số. | Văn bản, mã nguồn, dữ liệu phi cấu trúc. |
| Quy mô | Dataset nhỏ đến trung bình. | Dataset khổng lồ, hàng tỷ token. |
| Kỹ thuật chính | Feature Engineering (Chọn đặc trưng). | Text Preprocessing & Embedding. |
| Cấu trúc | Có cấu trúc rõ ràng (Hàng/Cột). | Phi cấu trúc, giàu ngữ cảnh. |
LLM pipeline phải đối mặt với thách thức về “Context Window” (Cửa sổ ngữ cảnh) – giới hạn về lượng thông tin mà mô hình có thể đọc trong một lần. Nếu bạn đưa một cuốn sách 500 trang vào, LLM sẽ “quên” đoạn đầu khi đọc đến đoạn cuối. Pipeline dữ liệu phải giải quyết bài toán này bằng cách cắt nhỏ tài liệu nhưng vẫn giữ được sợi dây liên kết ý tưởng.
3. Các nguồn dữ liệu “đầu vào” cho hệ thống Enterprise AI
Trong môi trường doanh nghiệp, dữ liệu không nằm ở một chỗ. Một pipeline mạnh mẽ phải có khả năng kết nối và thu nạp từ nhiều nguồn không đồng nhất:
- Tài liệu nội bộ: Quy định công ty, quy trình vận hành (SOP), hướng dẫn sử dụng sản phẩm lưu trong Wiki hoặc SharePoint.
- Cơ sở dữ liệu khách hàng: Thông tin phản hồi, lịch sử hỗ trợ từ CRM (Salesforce, Hubspot).
- Website và Blog: Các bài viết chuyên môn, tin tức thị trường được thu thập qua kỹ thuật Web Scraping.
- Tệp tin rời rạc: PDF, DOCX, Markdown nằm trong các kho lưu trữ đám mây như Google Drive hay Dropbox.
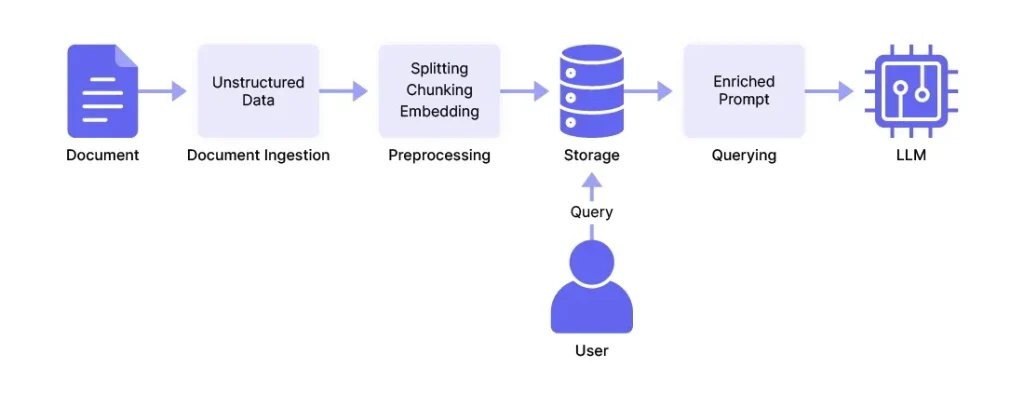
4. Kiến trúc tổng thể của Pipeline dữ liệu LLM
Để một hệ thống Generative AI vận hành ổn định, pipeline dữ liệu không chỉ đơn thuần là một đường ống dẫn, mà là một quy trình tinh luyện đa tầng. Kiến trúc này đảm bảo dữ liệu thô (Raw Data) được chuyển hóa thành các vector số (Embeddings) – định dạng duy nhất mà máy tính có thể dùng để so sánh ý nghĩa ngữ nghĩa.
Một kiến trúc chuẩn thường bao gồm 4 giai đoạn chính:
- Lớp Thu nạp (Ingestion Layer): Kết nối với các nguồn như SharePoint, S3, hay SQL để lấy dữ liệu.
- Lớp Tiền xử lý (Processing Layer): Thực hiện làm sạch, loại bỏ nhiễu và chia nhỏ văn bản (Chunking).
- Lớp Biến đổi (Transformation Layer): Sử dụng các mô hình Embedding để chuyển văn bản thành không gian vector.
- Lớp Lưu trữ & Truy xuất (Storage & Retrieval Layer): Lưu vào Vector Database và thiết lập cơ chế tìm kiếm tương đồng (Similarity Search).
Sự phối hợp nhịp nhàng giữa các lớp này giúp hệ thống RAG (Retrieval-Augmented Generation) có thể phản hồi người dùng trong thời gian thực với độ chính xác cao.

5. Chi tiết các bước triển khai pipeline dữ liệu cho LLM
Để xây dựng một pipeline đạt chuẩn, bạn cần đi qua 6 bước kỹ thuật quan trọng sau:
Bước 1: Data Ingestion (Thu nạp dữ liệu)
Đây là bước “mở cổng” để đón nhận dữ liệu. Tùy vào tính chất, bạn có thể chọn thu nạp theo lô (Batch) đối với các tài liệu tĩnh, hoặc thu nạp dòng (Streaming) đối với các dữ liệu thay đổi liên tục như tin nhắn hỗ trợ khách hàng.
Bước 2: Data Cleaning (Làm sạch dữ liệu)
Văn bản thô thường chứa rất nhiều “rác” như thẻ HTML, các ký tự lạ hoặc định dạng thừa từ file PDF. Việc làm sạch ở bước này cực kỳ quan trọng vì nếu bạn nạp dữ liệu rác, LLM sẽ trả về kết quả rác. Các kỹ thuật phổ biến bao gồm loại bỏ nội dung trùng lặp, chuẩn hóa phông chữ và loại bỏ các đoạn văn bản không mang giá trị ngữ nghĩa (như quảng cáo xen kẽ trong bài viết).
Bước 3: Text Chunking (Chia nhỏ văn bản)
Đây là bước nghệ thuật nhất trong pipeline. Vì LLM có giới hạn về token, chúng ta phải chia văn bản dài thành các đoạn nhỏ (Chunk).
- Nếu chunk quá nhỏ: Đoạn văn mất đi ngữ cảnh (Ví dụ: “Anh ấy nói…” nhưng không biết “anh ấy” là ai).
- Nếu chunk quá lớn: Thông tin bị loãng và gây tốn chi phí cho mỗi lần AI xử lý.
Thông thường, các kỹ sư sẽ dùng kỹ thuật Recursive Character Splitting để chia đoạn khoảng 300-500 token và có một phần nội dung gối đầu (overlap) giữa các đoạn để giữ tính liên tục của ý nghĩa.
Bước 4: Embedding (Nhúng dữ liệu)
Đây là lúc phép màu toán học xảy ra. Mỗi đoạn văn bản (chunk) sẽ được đưa qua một Embedding Model (như text-embedding-3-small của OpenAI) để biến thành một dãy số (vector). Các vector này có đặc điểm là: những đoạn văn có nghĩa giống nhau sẽ nằm gần nhau trong không gian toán học.
Bước 5: Lưu trữ trong Vector Database
Sau khi có vector, chúng ta cần một nơi lưu trữ chuyên dụng. Các cơ sở dữ liệu truyền thống như MySQL không thể tìm kiếm theo “ý nghĩa”. Bạn cần một Vector Database như Pinecone, Weaviate hoặc Milvus. Tại đây, dữ liệu được tổ chức để phục vụ việc tìm kiếm tương đồng (Similarity Search) cực nhanh.
Bước 6: Retrieval (Truy xuất)
Khi người dùng đặt câu hỏi, pipeline sẽ biến câu hỏi đó thành vector, tìm trong Vector Database các đoạn văn bản có vector gần nhất, sau đó gửi các đoạn đó kèm câu hỏi tới LLM. Đây chính là xương sống của kiến trúc RAG.
6. Pipeline dữ liệu cho hệ thống RAG hoạt động ra sao?
Hệ thống RAG (Retrieval-Augmented Generation) là ứng dụng phổ biến nhất của pipeline này. Hãy tưởng tượng bạn xây dựng một chatbot cho một ngân hàng.
- Người dùng hỏi: “Lãi suất tiết kiệm kỳ hạn 6 tháng là bao nhiêu?”
- Hệ thống: Tìm trong Vector Database các đoạn văn bản liên quan đến “lãi suất 6 tháng”.
- Kết quả: Tìm thấy 3 đoạn văn trong thông báo mới nhất của ngân hàng.
- LLM: Tổng hợp 3 đoạn đó và trả lời: “Theo quy định mới nhất ngày hôm qua, lãi suất là 6.5%.”
Nhờ pipeline này, LLM không còn “nói dối” (hallucination) vì nó luôn dựa trên dữ liệu thực tế được truy xuất từ kho tài liệu.
7. Lợi ích vượt trội khi sở hữu một pipeline dữ liệu chuẩn
Việc đầu tư vào pipeline dữ liệu mang lại 4 lợi ích sống còn cho doanh nghiệp:
- Giảm thiểu Hallucination: AI sẽ trả lời dựa trên “bằng chứng” có thực thay vì tự sáng tạo thông tin.
- Cập nhật kiến thức tức thì: Thay vì phải huấn luyện lại model mất hàng tuần, bạn chỉ cần nạp tài liệu mới vào Vector Database trong vài giây.
- Bảo mật dữ liệu: Bạn có thể kiểm soát được AI đang đọc tài liệu nào, đảm bảo thông tin nhạy cảm không bị lộ ra ngoài.
- Tiết kiệm chi phí: Thay vì gửi toàn bộ tài liệu cho LLM (rất đắt), bạn chỉ gửi đúng vài đoạn văn bản cần thiết nhất.
8. Những thách thức thường gặp và cách khắc phục
Mặc dù lý thuyết khá rõ ràng, nhưng khi triển khai thực tế, bạn sẽ gặp phải các “hố đen”:
- Chất lượng Embedding: Một số model embedding không hiểu tốt tiếng Việt chuyên ngành. Giải pháp là thử nghiệm nhiều model hoặc fine-tune nhẹ cho embedding.
- Chi phí lưu trữ Vector: Với hàng tỷ vector, chi phí cloud sẽ tăng cao. Hãy sử dụng kỹ thuật nén vector (Product Quantization) để tối ưu.
- Dữ liệu lỗi thời: Tài liệu cũ vẫn tồn tại trong Vector Database sẽ khiến AI trả lời sai. Cần có cơ chế TTL (Time To Live) hoặc đánh dấu phiên bản cho tài liệu.
9. Best Practices khi xây dựng pipeline cho LLM
Theo kinh nghiệm triển khai từ Pinecone, hãy ghi nhớ các nguyên tắc:
- Luôn chuẩn hóa dữ liệu: Xóa bỏ các ký tự rác trước khi embedding để tăng độ chính xác lên 20-30%.
- Chiến lược Chunking linh hoạt: Đừng chỉ cắt theo số ký tự cố định, hãy cố gắng cắt theo tiêu đề hoặc đoạn văn hoàn chỉnh.
- Đánh giá thường xuyên: Sử dụng các bộ công cụ như RAGAS để đo lường xem hệ thống đang truy xuất đúng dữ liệu hay không.
Kết luận
Pipeline dữ liệu cho LLM chính là nền móng để xây dựng bất kỳ ứng dụng Generative AI thành công nào. Trong một thế giới mà các mô hình ngôn ngữ đang dần trở nên bão hòa về sức mạnh, thì sự khác biệt nằm ở chính dữ liệu bạn cung cấp và cách bạn tổ chức nó. Một pipeline hiệu quả không chỉ giúp AI của bạn thông minh hơn mà còn biến nó thành một chuyên gia thực thụ trong lĩnh vực của doanh nghiệp.
INDA Academy tự hào là đơn vị tiên phong trong việc đào tạo phân tích dữ liệu và AI chuyên sâu, đặc biệt cho khối ngành Ngân hàng – Tài chính – Bảo hiểm tại Việt Nam. Sau hơn 12 năm “thực chiến” cùng những dòng chảy dữ liệu khổng lồ, chúng tôi đã xây dựng nên một hệ sinh thái đào tạo toàn diện, giúp hàng nghìn học viên chuyển mình từ người mới bắt đầu trở thành những chuyên gia lành nghề, sẵn sàng đáp ứng tiêu chuẩn khắt khe của các doanh nghiệp lớn.
Điểm khác biệt lớn nhất tại INDA chính là triết lý đào tạo dựa trên các dự án thực tế (Project-based) và lộ trình cá nhân hóa nhờ ứng dụng AI. Chúng tôi không chỉ dạy bạn cách sử dụng công cụ, mà còn truyền tải tư duy khai phá giá trị từ dữ liệu để đưa ra quyết định kinh doanh chính xác.
Tìm hiểu thêm về các khóa học TẠI ĐÂY:
Lộ trình đào tạo Data Engineer
Lộ trình đào tạo Data Analyst
Lộ trình đào tạo Tester
Khóa học Data Engineer nâng cao – Thực chiến 5 dự án doanh nghiệp
Khóa học Data Analyst nâng cao – Thực chiến 5 dự án doanh nghiệp
