

Trong giới công nghệ, có một câu nói nổi tiếng: “Xây dựng mô hình Machine Learning chỉ chiếm 5% công sức, 95% còn lại nằm ở hệ thống vận hành xung quanh nó.” Thực tế, một dự án trí tuệ nhân tạo thành công không chỉ dừng lại ở việc các kỹ sư viết ra một đoạn mã thuật toán thông minh. Để mô hình đó thực sự tạo ra giá trị – chẳng hạn như dự đoán chính xác khách hàng nào sắp rời bỏ dịch vụ hay gợi ý đúng món đồ người dùng muốn mua – nó cần một “dây chuyền sản xuất” chuyên nghiệp.
Dây chuyền đó chính là ML Pipeline. Nếu không có một quy trình tự động và nhất quán, các mô hình AI sẽ mãi nằm trong phòng thí nghiệm và nhanh chóng trở nên lỗi thời khi dữ liệu thực tế thay đổi. Bài viết này sẽ dẫn bạn đi qua toàn bộ vòng đời của một hệ thống Machine Learning end-to-end, từ khâu thu thập dữ liệu thô cho đến khi mô hình hoạt động ổn định trên môi trường thực tế.
Mục lục
1. ML Pipeline là gì? “Dây chuyền sản xuất” của trí tuệ nhân tạo
ML Pipeline (Machine Learning Pipeline) là một chuỗi các bước xử lý dữ liệu và huấn luyện mô hình được tổ chức thành một quy trình tự động hóa hoàn toàn. Hãy tưởng tượng nó giống như dây chuyền lắp ráp ô tô trong nhà máy: dữ liệu thô đi vào ở đầu này, trải qua các công đoạn gọt giũa, kiểm tra, lắp ráp, và cuối cùng một mô hình AI hoàn chỉnh “lăn bánh” ra ở đầu kia để phục vụ người dùng.
Theo định nghĩa từ Google Cloud, ML Pipeline giúp đóng gói toàn bộ quy trình công việc (workflow) thành một thực thể duy nhất có thể tái sử dụng. Thay vì các kỹ sư dữ liệu phải thực hiện thủ công việc làm sạch dữ liệu hay huấn luyện lại mô hình mỗi khi có thông tin mới, Pipeline sẽ tự động kích hoạt các bước này theo một trình tự logic đã định sẵn. Điều này đảm bảo tính nhất quán tuyệt đối: dù bạn chạy quy trình hôm nay hay một năm sau, kết quả xử lý dữ liệu vẫn tuân thủ cùng một quy tắc nghiêm ngặt.
2. Vì sao ML Pipeline là “xương sống” của các dự án AI thực chiến?
Trong giai đoạn học tập hoặc nghiên cứu, bạn có thể thực hiện mọi bước trên một file Jupyter Notebook duy nhất. Nhưng khi đưa vào môi trường kinh doanh thực tế (production), mọi thứ phức tạp hơn rất nhiều.
Quản trị quy trình phức tạp và tránh lỗi thủ công
Một dự án Machine Learning thực tế bao gồm hàng trăm thao tác nhỏ từ trích xuất dữ liệu, xử lý nhiễu, chuẩn hóa đơn vị cho đến lựa chọn tham số. Nếu làm thủ công, chỉ cần một sai sót nhỏ trong khâu tiền xử lý dữ liệu cũng có thể khiến mô hình đưa ra những dự đoán sai lệch nghiêm trọng. Pipeline giúp tổ chức các bước này một cách khoa học, biến các thao tác rời rạc thành một khối thống nhất.
Khả năng tự động huấn luyện lại (Retraining)
Dữ liệu trong thế giới thực luôn biến động. Một mô hình dự đoán xu hướng thời trang của năm ngoái chắc chắn sẽ thất bại trong năm nay. Theo Microsoft Azure, ML Pipeline cho phép hệ thống tự động nhận diện khi hiệu suất mô hình giảm sút và kích hoạt quy trình huấn luyện lại với dữ liệu mới nhất mà không cần sự can thiệp trực tiếp của con người.
Tăng khả năng tái sử dụng và mở rộng
Khi doanh nghiệp phát triển từ việc phục vụ 1.000 khách hàng lên 1 triệu khách hàng, lượng dữ liệu sẽ bùng nổ. ML Pipeline được thiết kế để hoạt động trên các hạ tầng điện toán đám mây, giúp hệ thống dễ dàng mở rộng quy mô xử lý mà không phải xây dựng lại từ đầu. Các module trong Pipeline (như module làm sạch dữ liệu) cũng có thể được tái sử dụng cho nhiều dự án khác nhau trong cùng một tổ chức.
3. Quy trình chi tiết của một ML Pipeline end-to-end
Để xây dựng một hệ thống Machine Learning hoàn chỉnh, chúng ta cần đi qua 7 bước cốt lõi. Mỗi bước đóng vai trò như một mắt xích không thể tách rời.
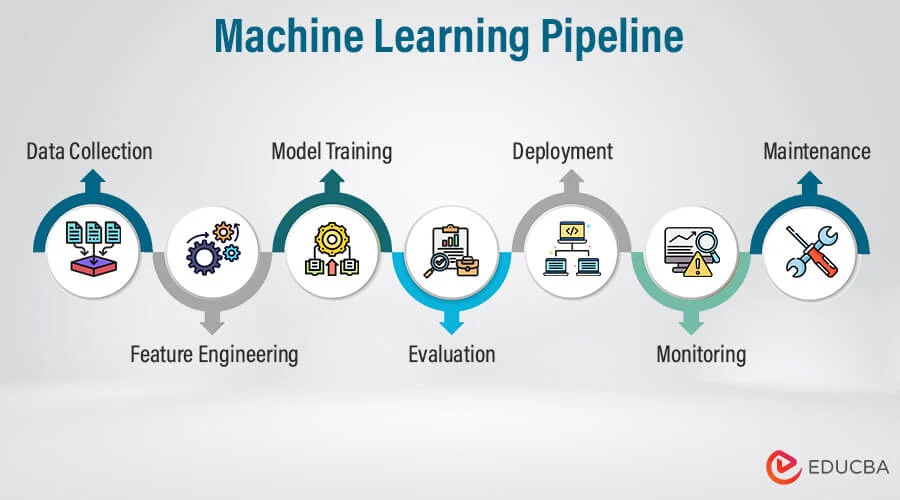
Bước 1: Thu nhận dữ liệu (Data Ingestion)
Mọi thứ bắt đầu từ nguồn dữ liệu. Dữ liệu có thể nằm rải rác ở nhiều nơi: các cơ sở dữ liệu SQL truyền thống, các kho dữ liệu lớn (Data Warehouse), thông qua API từ bên thứ ba hoặc các bản ghi log trực tiếp từ hệ thống.
Ở bước này, Pipeline cần xác định cách thức thu nhận. Batch ingestion thường dùng cho các tác vụ không yêu cầu tốc độ tức thời (ví dụ: báo cáo doanh thu hàng ngày), trong khi Streaming ingestion là bắt buộc cho các hệ thống thời gian thực như phát hiện gian lận thẻ tín dụng, nơi mà mỗi giây trễ đều gây thiệt hại.
Bước 2: Tiền xử lý dữ liệu (Data Preprocessing)
Dữ liệu thô thường rất “bẩn” và lộn xộn. Nó có thể chứa các giá trị bị thiếu (missing values), các bản ghi trùng lặp hoặc định dạng không đồng nhất. Khâu tiền xử lý sẽ làm nhiệm vụ dọn dẹp: điền giá trị trung bình vào những ô trống, loại bỏ các điểm dữ liệu dị biệt (outliers) và đưa tất cả về một định dạng chuẩn mà máy tính có thể đọc được.
Bước 3: Kỹ thuật đặc trưng (Feature Engineering)
Đây là khâu quan trọng nhất để tạo nên sự đột phá cho mô hình. Feature Engineering là quá trình biến đổi các thuộc tính thô thành những thông tin giàu ý nghĩa hơn.
Ví dụ: Từ một dấu mốc thời gian (timestamp) đơn thuần như 2024-03-10 10:00:00, chúng ta có thể tạo ra các đặc trưng mới như: “Ngày trong tuần”, “Giờ cao điểm” hay “Kỳ nghỉ lễ”.
Trong các hệ thống lớn của Uber hay Airbnb, các đặc trưng này thường được lưu trữ trong một Feature Store tập trung để toàn bộ công ty có thể dùng chung, tránh việc mỗi team lại phải tính toán lại từ đầu.
Bước 4: Huấn luyện mô hình (Model Training)
Tại bước này, thuật toán Machine Learning sẽ “ngấu nghiến” dữ liệu đã được gọt giũa để học các quy luật ngầm định. Tùy vào mục tiêu kinh doanh mà chúng ta chọn loại mô hình phù hợp:
- Classification: Phân loại khách hàng tiềm năng hay không tiềm năng.
- Regression: Dự báo giá nhà hoặc biến động chứng khoán.
- Recommendation: Gợi ý sản phẩm phù hợp dựa trên sở thích cá nhân.
Bước 5: Đánh giá mô hình (Model Evaluation)
Chúng ta không thể tin tưởng một mô hình ngay khi nó vừa học xong. Nó cần được “thi sát hạch” trên một tập dữ liệu mà nó chưa từng thấy trước đó. Các chỉ số như Accuracy (độ chính xác), Precision (độ chuẩn), hay RMSE (sai số bình phương trung bình) sẽ được tính toán. Mục tiêu tối thượng của bước này là đảm bảo mô hình không bị “học vẹt” (overfitting) và có khả năng ứng dụng thực tế tốt nhất.
Bước 6: Triển khai mô hình (Model Deployment)
Sau khi vượt qua kỳ thi sát hạch, mô hình sẽ được đưa vào môi trường sản xuất. Có nhiều hình thức triển khai khác nhau tùy vào nhu cầu sử dụng:
- Batch Inference: Hệ thống chạy dự đoán theo lô (ví dụ: mỗi đêm tính toán điểm tín dụng cho tất cả khách hàng).
- Real-time Inference: Mô hình được đóng gói dưới dạng một API, sẵn sàng trả về kết quả ngay lập tức khi người dùng click vào trang web.

Bước 7: Giám sát và Tự động huấn luyện lại (Monitoring & Retraining)
Công việc của một kỹ sư ML không kết thúc sau khi deploy. Khi dữ liệu thực tế thay đổi (hiện tượng Data Drift), hiệu suất của mô hình sẽ giảm dần theo thời gian. Pipeline cần tích hợp các công cụ giám sát để theo dõi xem mô hình có còn dự đoán chính xác hay không. Nếu phát hiện sai số vượt ngưỡng, Pipeline sẽ tự động kích hoạt khâu huấn luyện lại với bộ dữ liệu mới nhất.
4. Phân biệt ML Pipeline và AI Pipeline
Mặc dù thường được dùng thay thế cho nhau, nhưng có một sự khác biệt tinh tế về phạm vi giữa hai khái niệm này.
ML Pipeline tập trung sâu vào vòng đời của một thuật toán học máy cụ thể: từ xử lý dữ liệu đến huấn luyện và triển khai mô hình. Trong khi đó, AI Pipeline mang nghĩa rộng hơn. Một AI Pipeline có thể bao gồm nhiều ML Pipeline bên trong, kết hợp với các công cụ xử lý ngôn ngữ tự nhiên (NLP), thị giác máy tính, và thậm chí là các giao diện người dùng hoàn chỉnh. Theo NVIDIA, ML Pipeline thường là một thành phần cốt lõi, đóng vai trò “cơ bắp” cho toàn bộ hệ thống AI tổng thể.
| Tiêu chí | ML Pipeline | AI Pipeline |
| Phạm vi | Huấn luyện và triển khai một mô hình ML. | Xây dựng toàn bộ trải nghiệm AI hoàn chỉnh. |
| Thành phần | Data processing, Training, Evaluation. | ML models, LLMs, UI/UX, Logic ứng dụng. |
| Mục tiêu | Tối ưu hóa độ chính xác của mô hình. | Giải quyết bài toán kinh doanh tổng thể. |
5. Những “trợ thủ” đắc lực để xây dựng ML Pipeline
Để triển khai các hệ thống phức tạp này, giới công nghệ thường sử dụng các công cụ chuyên dụng thay vì tự xây dựng từ con số không:
- Apache Airflow: Công cụ hàng đầu để điều phối (orchestration) các workflow phức tạp. Nó cho phép bạn lập lịch và theo dõi các bước trong Pipeline một cách trực quan.
- Kubeflow: Một nền tảng dành riêng cho Machine Learning trên môi trường Kubernetes, cực kỳ mạnh mẽ trong việc quản lý và mở rộng quy mô.
- MLflow: Giúp bạn quản lý toàn bộ vòng đời của mô hình, từ việc ghi lại các thí nghiệm (experiment tracking) đến việc lưu trữ các phiên bản mô hình (model registry).
- Apache Spark: “Gã khổng lồ” trong việc xử lý dữ liệu lớn ở tốc độ cao, thường được dùng ở các bước đầu tiên của Pipeline.
6. Những thách thức khi vận hành ML Pipeline thực tế
Triển khai một Pipeline thành công là một thành tựu, nhưng duy trì nó là một thử thách khác. Thách thức lớn nhất chính là Chất lượng dữ liệu (Data Quality). Nếu dữ liệu đầu vào bị sai lệch hoặc không nhất quán giữa môi trường huấn luyện và môi trường thực tế (Training-Serving Skew), toàn bộ hệ thống sẽ sụp đổ.
Ngoài ra, tính Tái lập (Reproducibility) cũng rất quan trọng. Bạn cần đảm bảo rằng nếu chạy lại Pipeline với cùng một bộ dữ liệu và tham số, kết quả mô hình thu được phải hoàn toàn giống nhau. Điều này đòi hỏi việc quản lý phiên bản (versioning) cực kỳ chặt chẽ cho cả mã nguồn, dữ liệu và môi trường thực thi.
Kết luận
Xây dựng một ML Pipeline bền vững là chìa khóa để chuyển đổi từ các thử nghiệm AI rời rạc sang một hệ thống trí tuệ nhân tạo có khả năng tự vận hành và tạo ra giá trị kinh doanh lâu dài. Quy trình này không chỉ giúp giảm bớt gánh nặng thủ công cho các kỹ sư mà còn đảm bảo rằng các mô hình luôn được cập nhật, chính xác và sẵn sàng đối mặt với sự biến động không ngừng của dữ liệu thực tế.
Trong kỷ nguyên AI hiện đại, ML Pipeline không còn là một lựa chọn “có thì tốt” mà đã trở thành tiêu chuẩn bắt buộc cho mọi tổ chức muốn ứng dụng Machine Learning ở quy mô lớn.
INDA Academy tự hào là đơn vị tiên phong trong việc đào tạo phân tích dữ liệu và AI chuyên sâu, đặc biệt cho khối ngành Ngân hàng – Tài chính – Bảo hiểm tại Việt Nam. Sau hơn 12 năm “thực chiến” cùng những dòng chảy dữ liệu khổng lồ, chúng tôi đã xây dựng nên một hệ sinh thái đào tạo toàn diện, giúp hàng nghìn học viên chuyển mình từ người mới bắt đầu trở thành những chuyên gia lành nghề, sẵn sàng đáp ứng tiêu chuẩn khắt khe của các doanh nghiệp lớn.
Điểm khác biệt lớn nhất tại INDA chính là triết lý đào tạo dựa trên các dự án thực tế (Project-based) và lộ trình cá nhân hóa nhờ ứng dụng AI. Chúng tôi không chỉ dạy bạn cách sử dụng công cụ, mà còn truyền tải tư duy khai phá giá trị từ dữ liệu để đưa ra quyết định kinh doanh chính xác.
Tìm hiểu thêm về các khóa học TẠI ĐÂY:
Lộ trình đào tạo Data Engineer
Lộ trình đào tạo Data Analyst
Lộ trình đào tạo Tester
Khóa học Data Engineer nâng cao – Thực chiến 5 dự án doanh nghiệp
Khóa học Data Analyst nâng cao – Thực chiến 5 dự án doanh nghiệp
Bài viết liên quan:
 AI-102 vs AI-103: Cuộc cách mạng hóa tiêu chuẩn Kỹ sư AI trên Microsoft Azure
AI-102 vs AI-103: Cuộc cách mạng hóa tiêu chuẩn Kỹ sư AI trên Microsoft Azure
 Top 12 chứng chỉ AI quốc tế đáng học nhất năm 2026: Đâu là tấm vé vàng cho sự nghiệp của bạn?
Top 12 chứng chỉ AI quốc tế đáng học nhất năm 2026: Đâu là tấm vé vàng cho sự nghiệp của bạn?
 Doanh nghiệp nên đào tạo AI theo phòng ban hay theo bài toán?
Đào tạo AI cho doanh nghiệp: Cần đo lường hiệu quả như thế nào để không biến thành phong trào?
Đào tạo AI theo nhu cầu doanh nghiệp khác gì so với khóa học AI đại trà?
Doanh nghiệp nên đào tạo AI theo phòng ban hay theo bài toán?
Đào tạo AI cho doanh nghiệp: Cần đo lường hiệu quả như thế nào để không biến thành phong trào?
Đào tạo AI theo nhu cầu doanh nghiệp khác gì so với khóa học AI đại trà?
 Lợi ích của AI: Khám phá ưu điểm và giá trị mà trí tuệ nhân tạo mang lại
Lợi ích của AI: Khám phá ưu điểm và giá trị mà trí tuệ nhân tạo mang lại