

Trong giới dữ liệu, có một câu nói nổi tiếng: “Dữ liệu là dầu mỏ mới, nhưng nếu không có hệ thống lọc, nó chỉ là đống bùn đen không giá trị”. Công việc của một Data Engineer trong một Project ETL thực tế chính là xây dựng nhà máy lọc dầu đó. Tuy nhiên, khoảng cách giữa một bài tập thực hành trên lớp và một dự án chạy trong môi trường doanh nghiệp (Production) là rất lớn.
Một dự án ETL chuẩn Portfolio không chỉ đơn thuần là chuyển dữ liệu từ điểm A sang điểm B. Nó là một bài toán về kỹ thuật hệ thống, nơi bạn phải đối mặt với sự bất ổn của hạ tầng, sự lộn xộn của dữ liệu người dùng và áp lực về tính chính xác của con số báo cáo. Bài viết này sẽ hướng dẫn bạn cách xây dựng một dự án ETL với mindset của một kỹ sư thực thụ.
Mục lục
1. Bản Chất Của ETL Project: Tại Sao Lại Cần Kiến Trúc Phân Lớp?
Nhiều người mới bắt đầu thường gộp chung tất cả các bước vào một file script duy nhất. Điều này cực kỳ nguy hiểm vì khi có lỗi xảy ra, bạn không biết dữ liệu bị sai từ khâu nào. Trong thực tế, các hệ thống lớn luôn tuân thủ nguyên tắc “Chia để trị” (Divide and Conquer).
Kiến trúc phân lớp giúp bạn module hóa hệ thống. Nếu nguồn dữ liệu thay đổi cấu trúc, bạn chỉ cần sửa phần Extract. Nếu sếp thay đổi cách tính lợi nhuận, bạn chỉ cần sửa phần Transform. Việc tách biệt này đảm bảo rằng hệ thống của bạn không bị sụp đổ dây chuyền khi có một thay đổi nhỏ. Theo các tiêu chuẩn từ Data Engineering Cookbook (tham khảo link sau: https://github.com/prmohanty/AI-ML-DL-Resources/blob/master/The%20Data%20Engineering%20Cookbook.pdf), việc thiết kế các “trạm dừng chân” cho dữ liệu là yếu tố tiên quyết để đảm bảo khả năng gỡ lỗi (Debug) và tái sử dụng mã nguồn.
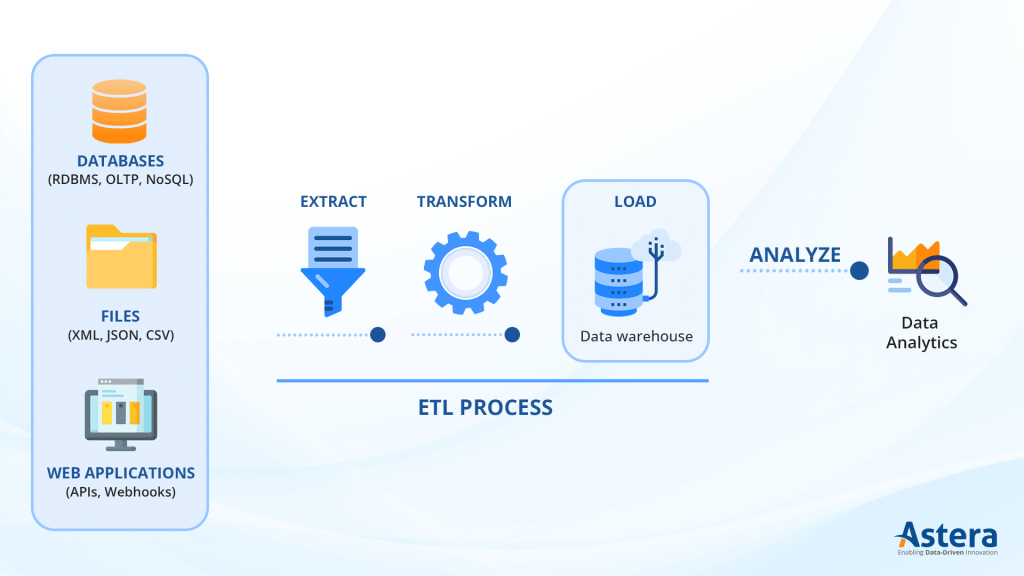
2. Case Study: Hệ Thống Phân Tích Hiệu Quả Marketing Đa Kênh
Để dự án của bạn có sức nặng trong mắt nhà tuyển dụng, nó cần giải quyết một bài toán kinh doanh cụ thể. Chúng ta sẽ chọn bối cảnh: Xây dựng hệ thống báo cáo ROI (Lợi nhuận trên chi phí quảng cáo) cho một doanh nghiệp bán lẻ.
Dữ liệu thô sẽ đến từ các nguồn có đặc thù hoàn toàn khác nhau:
- Dữ liệu đơn hàng: Trích xuất từ Database hệ thống (SQL). Dữ liệu này thường rất chuẩn mực nhưng khối lượng cực lớn.
- Chi phí quảng cáo: Lấy từ API của Facebook/Google Ads. Đây là nguồn dữ liệu “khó chiều” nhất vì thường xuyên gặp lỗi kết nối và giới hạn tần suất truy cập.
- Dữ liệu khuyến mãi: Các file Excel/CSV từ bộ phận vận hành. Đây là nguồn dữ liệu “bẩn” nhất với định dạng không nhất quán và nhiều sai sót do nhập liệu thủ công.
3. Extract – Chiến Thuật “Đánh Chiếm” Dữ Liệu Thông Minh
Trong một Project ETL thực tế, việc lấy dữ liệu (Extract) là một nghệ thuật về sự kiên nhẫn và tối ưu hóa.
Kỹ thuật Incremental Load vs Full Load
Bạn không thể tải lại toàn bộ 10 năm lịch sử đơn hàng mỗi ngày. Điều đó làm tốn băng thông, chậm Database nguồn và tăng chi phí Cloud. Kỹ thuật chuyên nghiệp nhất là Incremental Load. Bạn cần thiết lập một hệ thống “Ghi nhớ” (State Management). Pipeline sẽ ghi lại thời điểm cuối cùng nó chạy thành công vào một bảng Metadata. Lần sau, nó chỉ lấy những bản ghi có thời gian cập nhật lớn hơn mốc đó.
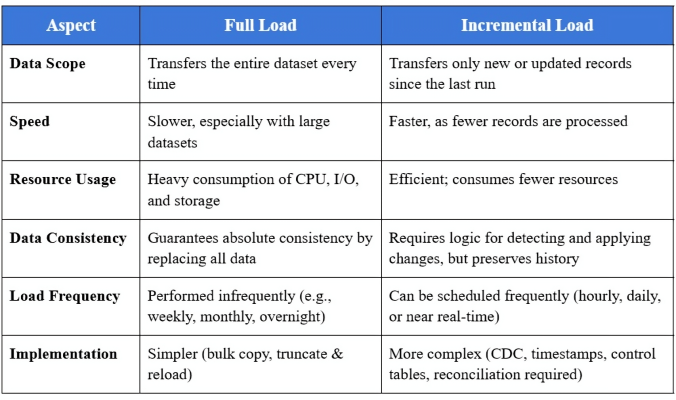
Xử lý sự bất ổn của API
API là một nguồn dữ liệu không đáng tin cậy. Nó có thể trả về lỗi 500 bất cứ lúc nào. Một Data Engineer giỏi sẽ cài đặt cơ chế Exponential Backoff. Thay vì thử lại ngay lập tức và tiếp tục bị chặn, hệ thống sẽ đợi 1 giây, rồi 5 giây, rồi 30 giây… Sự tinh tế này trong code cho thấy bạn có tư duy bảo vệ hạ tầng và hiểu biết sâu sắc về môi trường mạng.
4. Staging Layer – “Vùng Đệm” Lưu Trữ Và Đối Soát
Đây là phần mà 90% các tutorial bỏ qua nhưng lại là thứ nhà tuyển dụng tìm kiếm. Staging là nơi bạn lưu trữ dữ liệu gốc ngay sau khi lấy về mà chưa qua bất kỳ chỉnh sửa nào.
Tại sao không biến đổi ngay?
Hãy tưởng tượng sau một tuần, sếp phát hiện ra logic tính thuế bị sai. Nếu bạn đã biến đổi dữ liệu ngay từ đầu và xóa bỏ bản gốc, bạn sẽ phải chạy lại toàn bộ quy trình lấy dữ liệu từ API (rất tốn kém và mất thời gian). Nếu có lớp Staging, bạn chỉ việc thay đổi logic code và chạy lại từ vùng đệm này.
Định dạng lưu trữ chuyên sâu
Trong thực tế, người ta dùng định dạng Parquet hoặc Avro thay vì CSV tại lớp này. Parquet lưu trữ theo cột, giúp nén dữ liệu cực tốt và hỗ trợ “schema evolution” (khả năng thích ứng khi dữ liệu nguồn thêm cột mới). Việc chọn Parquet thay vì CSV chứng minh bạn quan tâm đến bài toán chi phí lưu trữ và tốc độ xử lý dữ liệu lớn (Big Data).
5. Transform – “Lò Luyện” Dữ Liệu Theo Mô Hình Medallion
Giai đoạn Transform là nơi thể hiện sự nhạy bén về nghiệp vụ. Để quản lý chất lượng, các kỹ sư thường chia Transform thành các tiểu tầng:
- Tầng Bronze (Raw): Chuyển đổi dữ liệu từ Staging vào bảng, giữ nguyên định dạng để dễ truy vấn SQL.
- Tầng Silver (Cleanse & Join): Tại đây, bạn thực hiện “phẫu thuật” dữ liệu. Bạn loại bỏ các bản ghi trùng lặp (Deduplication), chuẩn hóa đơn vị tiền tệ, xử lý múi giờ và kết nối bảng Đơn hàng với bảng Chi phí quảng cáo.
- Tầng Gold (Aggregated): Đây là tầng phục vụ báo cáo. Dữ liệu được tổng hợp sẵn (Pre-aggregated). Thay vì lưu chi tiết từng đơn hàng, bạn lưu tổng doanh thu theo ngày, theo khu vực. Điều này giúp các Dashboard trên Power BI hay Tableau load “vù vù” thay vì xoay vòng tròn chờ đợi.
6. Load – Đưa Dữ Liệu Vào Warehouse Và Xử Lý Trùng Lặp
Khi đẩy dữ liệu vào Data Warehouse, thách thức lớn nhất là tránh trùng lặp nếu pipeline phải chạy lại nhiều lần (do lỗi giữa chừng).
Kỹ thuật mà bạn nên sử dụng là Idempotent Load. Bạn không dùng lệnh INSERT đơn thuần, mà dùng MERGE hoặc UPSERT. Nếu bản ghi đã tồn tại, hãy cập nhật thông tin mới nhất; nếu chưa có, hãy thêm mới. Điều này đảm bảo rằng dù hệ thống có gặp sự cố và phải chạy lại 10 lần, con số cuối cùng trên Dashboard vẫn luôn chính xác tuyệt đối. Tính nhất quán này là sự khác biệt lớn nhất giữa một dự án nghiệp dư và chuyên nghiệp.
7. Điều Phối (Orchestration) – Nhạc Trưởng Apache Airflow
Một Project ETL thực tế không bao giờ chạy bằng tay. Bạn cần một bộ máy điều phối như Apache Airflow.
Airflow giúp bạn quản lý các tác vụ dưới dạng DAG (Đồ thị có hướng). Bạn có thể thiết lập những logic phức tạp như: “Nếu dữ liệu API Facebook bị lỗi, hãy tạm dừng bước tính ROI nhưng vẫn cho phép bước báo cáo đơn hàng chạy bình thường”. Việc đưa Airflow vào dự án thể hiện bạn có kỹ năng quản lý quy trình công việc (Workflow Management), biết cách xử lý các sự phụ thuộc chéo (Dependencies) trong một hệ thống dữ liệu phức tạp.
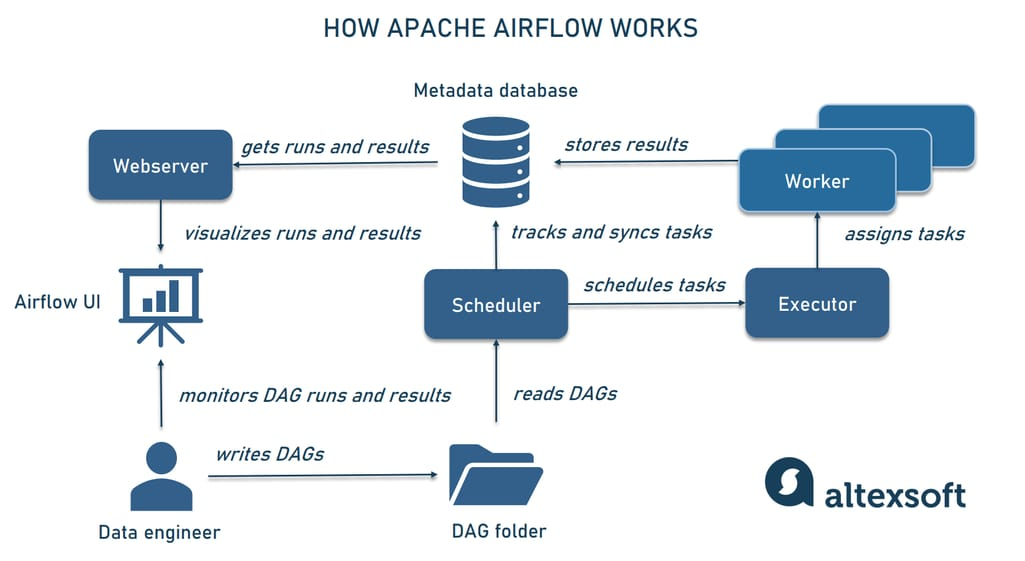
8. Logging, Monitoring và Alerting – Hệ Thần Kinh Của Pipeline
Trong môi trường Production, không ai ngồi canh màn hình terminal để xem code chạy. Bạn cần một cơ chế tự báo cáo:
- Logging: Ghi lại chi tiết mỗi bước chạy. Nếu thất bại, lỗi nằm ở dòng code nào? Do dữ liệu hay do mạng?
- Monitoring: Theo dõi sức khỏe hệ thống. Pipeline hôm nay chạy mất bao lâu? Có tốn nhiều RAM hơn hôm qua không?
- Alerting: Tích hợp thông báo qua Slack hoặc Telegram. Mỗi khi một Job bị fail, hệ thống phải tự động “kêu cứu” kèm theo mã lỗi để kỹ sư kịp thời xử lý.
Một dự án Portfolio có đính kèm hình ảnh bot Slack thông báo tình trạng Pipeline mỗi ngày sẽ có sức thuyết phục mạnh mẽ hơn bất kỳ lời mô tả nào.
9. Data Quality – “Người Gác Cổng” Tận Tụy
Dữ liệu có thể về đầy đủ nhưng vẫn sai. Hãy cài đặt các bài kiểm tra chất lượng (Data Quality Checks) tự động:
- Kiểm tra tính duy nhất: Đảm bảo không có hai đơn hàng trùng ID.
- Kiểm tra miền giá trị: Giá tiền không được bằng 0, tỷ lệ chuyển đổi không được lớn hơn 100%.
- Kiểm tra logic: Ngày giao hàng không được trước ngày đặt hàng.
Nếu dữ liệu không vượt qua các bài kiểm tra này, Pipeline phải tự động ngắt (Circuit Breaker) để ngăn chặn dữ liệu rác tràn vào kho chứa, làm hỏng báo cáo của doanh nghiệp.
10. Những Sai Lầm “Xương Máu” Cần Tránh Khi Làm Project
Dưới đây là những lỗi mà các nhà tuyển dụng sẽ dùng để “bắt bẻ” bạn trong buổi phỏng vấn:
- Hard-coding: Để lộ mật khẩu Database hoặc link API ngay trong code. Hãy sử dụng biến môi trường hoặc các công cụ quản lý bí mật.
- Thiếu Documentation: Một dự án không có file README hướng dẫn cài đặt và giải thích kiến trúc là một dự án “chết”.
- Không quan tâm đến Performance: Query hàng triệu dòng dữ liệu mà không có Index hoặc Partition.
- Làm project quá “sạch”: Nếu dữ liệu của bạn quá hoàn hảo, nhà tuyển dụng sẽ biết đó là dữ liệu giả. Hãy cho thấy cách bạn xử lý dữ liệu lỗi, dữ liệu thiếu.
11. Cách Đưa Project ETL Vào Portfolio Để “Bách Chiến Bách Thắng”
Đừng chỉ đưa link GitHub. Hãy viết một bài Case Study chi tiết:
- Thử thách: Mô tả độ phức tạp của dữ liệu nguồn và những khó khăn bạn gặp phải.
- Giải pháp kỹ thuật: Giải thích tại sao bạn chọn Airflow, tại sao dùng Parquet thay vì CSV.
- Xử lý sự cố: Kể lại một lần Pipeline bị lỗi do thay đổi Schema và cách bạn đã sửa nó. Đây là phần nhà tuyển dụng thích nghe nhất vì nó cho thấy kinh nghiệm thực tế.
- Giá trị mang lại: Hệ thống đã giúp tự động hóa bao nhiêu giờ làm báo cáo thủ công mỗi tuần?
12. Kết Luận: Mindset Của Một Data Engineer Thực Thụ
Xây dựng một Project ETL thực tế không phải là cuộc đua về việc sử dụng công cụ mới nhất hay hào nhoáng nhất. Đó là cuộc đua về độ bền bỉ, tính chính xác và khả năng quản lý rủi ro. Khi bạn coi trọng từng dòng Log, chăm chút cho từng bước kiểm tra dữ liệu và luôn sẵn sàng cho kịch bản hệ thống bị lỗi, đó chính là lúc bạn đã sẵn sàng bước chân vào những dự án dữ liệu tầm cỡ tại các doanh nghiệp lớn.
Hãy bắt đầu ngay hôm nay bằng việc chọn một bộ dữ liệu “bẩn” nhất mà bạn có thể tìm thấy, và xây dựng một “nhà máy lọc dữ liệu” chuyên nghiệp cho riêng mình!
FAQ (Câu Hỏi Thường Gặp)
Q: Tôi có cần mua Server để chạy Project này không?
A: Hoàn toàn không cần. Bạn có thể sử dụng Docker để giả lập toàn bộ môi trường (Postgres, Airflow, Spark) ngay trên máy tính cá nhân.
Q: Data Analyst có nên làm Project ETL không?
A: Rất nên. Việc hiểu cách dữ liệu được nhào nặn giúp bạn có cái nhìn sâu sắc hơn khi phân tích và có thể tự mình xử lý dữ liệu mà không cần đợi bộ phận kỹ thuật.Q: Nên dùng Python thuần hay dùng Spark cho dự án Portfolio?
A: Nếu dữ liệu của bạn dưới vài triệu dòng, Python thuần là đủ và chứng minh được kỹ năng lập trình cơ bản tốt. Nếu muốn hướng tới các Big Data role, hãy tích hợp thêm PySpark.
INDA Academy tự hào là đơn vị tiên phong trong việc đào tạo phân tích dữ liệu và AI chuyên sâu, đặc biệt cho khối ngành Ngân hàng – Tài chính – Bảo hiểm tại Việt Nam. Sau hơn 12 năm “thực chiến” cùng những dòng chảy dữ liệu khổng lồ, chúng tôi đã xây dựng nên một hệ sinh thái đào tạo toàn diện, giúp hàng nghìn học viên chuyển mình từ người mới bắt đầu trở thành những chuyên gia lành nghề, sẵn sàng đáp ứng tiêu chuẩn khắt khe của các doanh nghiệp lớn.
Điểm khác biệt lớn nhất tại INDA chính là triết lý đào tạo dựa trên các dự án thực tế (Project-based) và lộ trình cá nhân hóa nhờ ứng dụng AI. Chúng tôi không chỉ dạy bạn cách sử dụng công cụ, mà còn truyền tải tư duy khai phá giá trị từ dữ liệu để đưa ra quyết định kinh doanh chính xác.
Tìm hiểu thêm về các khóa học TẠI ĐÂY:
Lộ trình đào tạo Data Engineer
Lộ trình đào tạo Data Analyst
Lộ trình đào tạo Tester
Khóa học Data Engineer nâng cao – Thực chiến 5 dự án doanh nghiệp
Khóa học Data Analyst nâng cao – Thực chiến 5 dự án doanh nghiệp
Bài viết liên quan:
 Data Backfill: Khi Pipeline cần “ngược dòng thời gian” xử lý dữ liệu lịch sử
Data Backfill: Khi Pipeline cần “ngược dòng thời gian” xử lý dữ liệu lịch sử
 Data Engineer và Data Analyst Khác Nhau Thế Nào? So Sánh Dễ Hiểu Cho Sinh Viên Năm 3–4
TOP 5 CÔNG CỤ MÀ DATA ENGINEER CẦN BIẾT
Data Engineer và Data Analyst Khác Nhau Thế Nào? So Sánh Dễ Hiểu Cho Sinh Viên Năm 3–4
TOP 5 CÔNG CỤ MÀ DATA ENGINEER CẦN BIẾT
 Sự khác biệt giữa ETL và ELT
Sự khác biệt giữa ETL và ELT
 Data Engineer là gì? Những thông tin bạn cần nắm rõ về Data Engineer
ETL Testing: Hỏi và Đáp (Cập nhật 2026)
Data Engineer là gì? Những thông tin bạn cần nắm rõ về Data Engineer
ETL Testing: Hỏi và Đáp (Cập nhật 2026)