

Bạn đã bao giờ rơi vào tình cảnh này chưa: Bạn nhận được một yêu cầu phân tích dữ liệu bán hàng theo vùng miền và thời gian. Bạn tự tin mở SQL lên, nhưng rồi nhận ra để lấy được cái “doanh thu” chết tiệt đó, bạn phải JOIN liên tục 12 cái bảng khác nhau. Query chạy mất 10 phút, còn bạn thì ngồi nhìn màn hình xoay vòng trong vô vọng.
Đó là hệ quả của việc thiết kế database chỉ để “đúng sách giáo khoa” mà quên mất một điều cốt lõi: Trong hệ thống dữ liệu, database sinh ra là để phục vụ truy vấn, không phải để trưng bày lý thuyết chuẩn hóa.
Nếu bạn đang tiếp cận việc thiết kế database bằng cách bắt đầu với 1NF, 2NF hay 3NF một cách máy móc, hãy dừng lại một chút. Đối với một Data Engineer, thiết kế database không chỉ là tạo ra các bảng, mà là xây dựng một “nhà kho” thông minh, nơi dữ liệu được sắp xếp để pipeline chảy mượt nhất và Dashboard load nhanh nhất.
Mục lục
Database trong hệ thống dữ liệu: Không chỉ là nơi chứa
Nhiều người lầm tưởng rằng database của Backend và database cho Data Engineer là một. Thực tế, chúng là hai thế giới khác biệt. Nếu database của Backend (OLTP) ưu tiên việc ghi dữ liệu nhanh (Insert/Update) để người dùng đặt hàng không bị lag, thì database trong hệ thống dữ liệu (thường là OLAP hoặc Data Warehouse) lại ưu tiên việc đọc (Select).
Hãy tưởng tượng luồng đi của dữ liệu: Data Source → Pipeline (ETL/ELT) → Database/Warehouse → Dashboard. Ở đây, database đóng vai trò là “trạm trung chuyển” chiến lược. Nếu trạm này được thiết kế tồi, pipeline của bạn sẽ tắc nghẽn, và các công cụ BI như Power BI hay Tableau sẽ trở thành những “con rùa” công nghệ. Một database tốt cho Data Engineer phải đảm bảo được ba yếu tố: Schema rõ ràng, Query hiệu quả dưới áp lực dữ liệu lớn, và khả năng mở rộng linh hoạt.
Bước 1: Xác định mục tiêu – Đừng thiết kế khi chưa biết ai sẽ dùng
Sai lầm lớn nhất của các kỹ sư dữ liệu mới vào nghề là nhảy vào tạo bảng ngay lập tức. Hãy lùi lại và đặt câu hỏi: Ai là người sẽ query dữ liệu này?
Một Database phục vụ cho việc báo cáo tài chính sẽ khác hoàn toàn với một Database phục vụ cho việc tracking hành vi người dùng trên website theo thời gian thực.
- Nếu là e-commerce: Bạn cần trả lời được doanh thu theo ngày, top sản phẩm bán chạy, khách hàng trung thành là ai.
- Nếu là hệ thống IoT: Bạn cần ưu tiên việc lưu trữ chuỗi thời gian (time-series) và khả năng nén dữ liệu.
Theo các chuyên gia từ Google Cloud Architecture Framework, việc hiểu rõ “Access Pattern” (mẫu truy cập dữ liệu) quyết định đến 70% sự thành công của cấu trúc schema.
Bước 2: Xác định Entity – Tư duy theo hướng kinh doanh
Thay vì hỏi “Bảng này đã chuẩn hóa chưa?”, hãy hỏi: “Bảng này giúp trả lời câu hỏi kinh doanh nào?”.
Trong một hệ thống bán hàng, chúng ta thường có 3 thực thể (Entity) gốc:
- Orders (Đơn hàng): Trung tâm của mọi sự kiện.
- Customers (Khách hàng): Ai là người tạo ra sự kiện đó?
- Products (Sản phẩm): Đối tượng nào được giao dịch?
Tư duy đúng ở đây là xác định mối quan hệ giữa chúng một cách thực tế nhất. Đừng cố gắng chia nhỏ dữ liệu ra quá nhiều bảng phụ (over-normalization) nếu bạn biết chắc rằng mỗi lần lấy dữ liệu, bạn đều phải JOIN chúng lại với nhau.
Bước 3: Thiết kế Schema – Từ lý thuyết đến thực tế
Hãy nhìn vào một ví dụ schema tối giản nhưng cực kỳ hiệu quả cho mục đích phân tích dữ liệu e-commerce sau đây:
Table: Customers
- customer_id (Integer – PK)
- name (String)
- region (String)
- signup_date (Date)
Table: Products
- product_id (Integer – PK)
- product_name (String)
- category (String)
Table: Orders
- order_id (Integer – PK)
- customer_id (Integer – FK)
- product_id (Integer – FK)
- order_date (Date)
- revenue (Numeric)
Đây là cấu trúc “phẳng” hơn một chút so với database vận hành. Tại sao? Vì trong phân tích, chúng ta cần tốc độ. Việc giữ region ngay trong bảng Customers thay vì tách ra một bảng Regions riêng biệt giúp giảm bớt một bước JOIN không cần thiết khi làm báo cáo doanh thu theo khu vực.
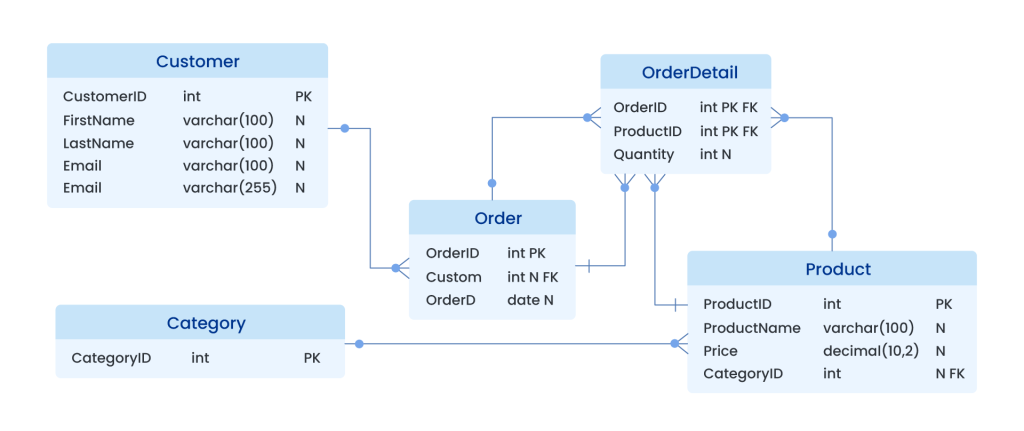
Thiết kế quan hệ: Luôn giữ vững “kỷ luật” khóa
Dù bạn có muốn tối ưu đến đâu, có hai nguyên tắc “bất di bất dịch” trong thiết kế database quan hệ: Primary Key (Khóa chính) và Foreign Key (Khóa ngoại).
Một sai lầm phổ biến là bỏ qua việc khai báo Foreign Key để “tăng tốc độ nạp dữ liệu”. Điều này cực kỳ nguy hiểm trong hệ thống dữ liệu. Không có khóa ngoại đồng nghĩa với việc bạn có thể có những đơn hàng (Orders) của một khách hàng không tồn tại (Customer_id ảo). Điều này dẫn đến dữ liệu “rác” và làm sai lệch hoàn toàn kết quả báo cáo trên Dashboard. Một query JOIN chuẩn mực luôn phải dựa trên các khóa đã được định nghĩa rõ ràng.
Tư duy Data Engineer: Star Schema và sự lên ngôi của Fact/Dimension
Đây chính là điểm giao thoa nơi bạn tách biệt mình khỏi một Backend Developer. Trong thế giới phân tích dữ liệu chuyên nghiệp, Star Schema (Mô hình sao) là “vị vua” không ngai.
Theo giáo trình kinh điển về Data Warehouse của Ralph Kimball, dữ liệu nên được chia thành hai loại bảng:
- Fact Table (Bảng sự thật): Nằm ở tâm của ngôi sao. Nó chứa các định lượng (metric) như doanh thu, số lượng, giá tiền. Ví dụ: Bảng Orders.
- Dimension Tables (Bảng chiều): Các cánh tay của ngôi sao. Nó chứa các thông tin ngữ cảnh như thông tin khách hàng, chi tiết sản phẩm, thời gian.
Tại sao lại là Star Schema? Vì nó cực kỳ dễ hiểu đối với các công cụ BI và giúp SQL của bạn ngắn gọn hơn rất nhiều. Khi bạn muốn tính tổng doanh thu theo loại sản phẩm trong tháng 3, bạn chỉ cần JOIN bảng Fact với 2 bảng Dimension tương ứng.
Tối ưu hóa Database: Khi dữ liệu không còn là “vài nghìn dòng”
Một thiết kế database đẹp trên giấy sẽ đổ vỡ khi dữ liệu lên tới hàng trăm triệu record. Lúc này, Data Engineer cần dùng đến các “vũ khí” hạng nặng:
- Partitioning (Phân vùng): Thay vì để một bảng Orders khổng lồ, hãy chia nó theo order_date. Khi bạn query dữ liệu tháng 4/2026, database chỉ cần quét vùng dữ liệu của tháng đó thay vì đọc toàn bộ lịch sử 10 năm của công ty.
- Indexing (Đánh chỉ mục): Hãy đặt Index lên các cột thường xuyên dùng để JOIN hoặc Filter như customer_id hay product_id. Tuy nhiên, đừng lạm dụng, vì quá nhiều Index sẽ làm chậm quá trình nạp dữ liệu (ETL).
- Clustering (Gom cụm): Sắp xếp dữ liệu vật lý trên ổ đĩa theo các nhóm liên quan (ví dụ theo category). Điều này giúp giảm thiểu việc đọc đĩa (I/O) và tăng tốc truy vấn đáng kể.
Những “vết xe đổ” thường gặp
Trong quá trình làm việc thực tế, tôi nhận thấy có 3 sai lầm mà ngay cả các Senior đôi khi vẫn mắc phải:
- Over-normalization (Quá lạm dụng chuẩn hóa): Chia dữ liệu ra quá nhiều bảng nhỏ khiến query trở thành một “mớ bòng bong” của JOIN. Trong Data Engineering, đôi khi Denormalization (phi chuẩn hóa) lại là một nghệ thuật để đổi lấy hiệu năng.
- Bỏ quên Query Pattern: Thiết kế một schema rất chuẩn nhưng không ai dùng đến, trong khi những query thực tế hàng ngày lại phải tính toán quá phức tạp trên schema đó.
- Không dự phòng khả năng thay đổi (Schema Evolution): Kinh doanh luôn thay đổi. Hôm nay bạn chỉ bán sản phẩm vật lý, ngày mai công ty bán thêm gói dịch vụ (subscription). Nếu database thiết kế quá cứng nhắc, việc thêm một cột hoặc đổi format dữ liệu có thể làm sập toàn bộ pipeline.
Checklist thiết kế Database chuẩn Data Engineer
Trước khi “vẽ” bảng, hãy tự kiểm tra qua danh sách này:
- [ ] Schema đã phản ánh đúng các câu hỏi kinh doanh chưa?
- [ ] Mọi bảng đều có Primary Key chưa?
- [ ] Các quan hệ giữa Fact và Dimension đã rõ ràng chưa?
- [ ] Đã cấu hình Partition cho các bảng dữ liệu lớn (Big Table) chưa?
- [ ] Các cột thường xuyên JOIN đã được đánh Index chưa?
- [ ] Cấu trúc này có dễ dàng tích hợp vào pipeline ETL hiện tại không?
- [ ] Schema có đủ linh hoạt để thêm trường dữ liệu mới trong tương lai không?
Kết nối với Pipeline và BI: Bức tranh toàn cảnh
Hãy nhớ rằng, Database không đứng một mình. Nó là layer trung gian cực kỳ quan trọng.
- Dữ liệu từ Source được Pipeline xử lý, làm sạch và nạp vào Database.
- Sau đó, các công cụ BI (Power BI, Tableau) sẽ kết nối vào Database này để vẽ nên những biểu đồ nghìn tỷ.
Nếu Database của bạn được thiết kế tốt, việc Transform dữ liệu trong Pipeline sẽ nhàn hơn, và các Dashboard sẽ mượt mà, giúp lãnh đạo đưa ra quyết định chính xác và kịp thời.
FAQ – Giải đáp nhanh về thiết kế Database
1. Data Engineer có thực sự cần thiết kế database không hay đó là việc của Database Administrator (DBA)? Trong kỷ nguyên hiện đại, ranh giới này rất mờ nhạt. DBA thường lo về hạ tầng và bảo mật, trong khi Data Engineer là người hiểu dữ liệu nhất để thiết kế cấu trúc logic (schema) phục vụ pipeline. Vậy nên, đây là kỹ năng bắt buộc của DE.
2. Khi nào nên dùng Star Schema, khi nào dùng Snowflake Schema? Star Schema ưu tiên tốc độ và sự đơn giản (ít JOIN). Snowflake Schema chuẩn hóa các bảng Dimension hơn (chia nhỏ Dimension thành các bảng phụ), giúp tiết kiệm bộ nhớ nhưng làm query phức tạp hơn. Trong Data Warehouse hiện đại, Star Schema thường được ưu tiên hơn.
3. Database cho Analytics khác gì database Backend? Database Backend (OLTP) tối ưu cho các giao dịch đơn lẻ (ví dụ: 1 khách hàng mua 1 món đồ). Database Analytics (OLAP) tối ưu cho việc tính toán trên tập dữ liệu lớn (ví dụ: tính tổng doanh thu của 1 triệu khách hàng).
Lời kết
Thiết kế database không phải là một bộ môn khoa học khô khan chỉ có đúng và sai. Nó là sự cân bằng giữa lý thuyết chuẩn hóa và hiệu năng thực tế. Đừng cố gắng tạo ra một database “đúng sách giáo khoa” nhất, hãy tạo ra một database “dễ dùng” nhất cho hệ thống của bạn.
Nếu bạn muốn tiến xa trên con đường trở thành một Data Engineer thực thụ, hãy bắt đầu tư duy về dữ liệu dưới góc nhìn của người dùng cuối. Một schema thông minh chính là nền móng vững chắc nhất cho mọi hệ thống AI và Big Data sau này.
INDA Academy tự hào là đơn vị tiên phong trong việc đào tạo phân tích dữ liệu và AI chuyên sâu, đặc biệt cho khối ngành Ngân hàng – Tài chính – Bảo hiểm tại Việt Nam. Sau hơn 12 năm “thực chiến” cùng những dòng chảy dữ liệu khổng lồ, chúng tôi đã xây dựng nên một hệ sinh thái đào tạo toàn diện, giúp hàng nghìn học viên chuyển mình từ người mới bắt đầu trở thành những chuyên gia lành nghề, sẵn sàng đáp ứng tiêu chuẩn khắt khe của các doanh nghiệp lớn.
Điểm khác biệt lớn nhất tại INDA chính là triết lý đào tạo dựa trên các dự án thực tế (Project-based) và lộ trình cá nhân hóa nhờ ứng dụng AI. Chúng tôi không chỉ dạy bạn cách sử dụng công cụ, mà còn truyền tải tư duy khai phá giá trị từ dữ liệu để đưa ra quyết định kinh doanh chính xác.
Tìm hiểu thêm về các khóa học TẠI ĐÂY:
Lộ trình đào tạo Data Engineer
Lộ trình đào tạo Data Analyst
Lộ trình đào tạo Tester
Khóa học Data Engineer nâng cao – Thực chiến 5 dự án doanh nghiệp
Khóa học Data Analyst nâng cao – Thực chiến 5 dự án doanh nghiệp
Bài viết liên quan:
 Late-arriving Data: Khi dữ liệu “đi lạc” và bài toán về tính chính xác trong Data Warehouse
Late-arriving Data: Khi dữ liệu “đi lạc” và bài toán về tính chính xác trong Data Warehouse
 Data Backfill: Khi Pipeline cần “ngược dòng thời gian” xử lý dữ liệu lịch sử
Data Backfill: Khi Pipeline cần “ngược dòng thời gian” xử lý dữ liệu lịch sử
 [Series: Checklist Ra Quyết Định] Bài 2: Bạn Đã Thực Sự Sẵn Sàng Học Data Engineer?
Data Engineer và Data Analyst Khác Nhau Thế Nào? So Sánh Dễ Hiểu Cho Sinh Viên Năm 3–4
Hướng Dẫn Viết CV Data Engineer Đúng Chuẩn 2026
[Series: Checklist Ra Quyết Định] Bài 2: Bạn Đã Thực Sự Sẵn Sàng Học Data Engineer?
Data Engineer và Data Analyst Khác Nhau Thế Nào? So Sánh Dễ Hiểu Cho Sinh Viên Năm 3–4
Hướng Dẫn Viết CV Data Engineer Đúng Chuẩn 2026
 Data Analyst, Data Engineer và Tester: Khác nhau điểm nào và ai phù hợp? (Cập nhật 2026)
Data Analyst, Data Engineer và Tester: Khác nhau điểm nào và ai phù hợp? (Cập nhật 2026)