
Doanh nghiệp hoàn toàn có thể sở hữu những insights sâu sắc và phong phú hơn nếu tận dụng và phân tích được tất cả dữ liệu từ các nguồn của doanh nghiệp. Tuy nhiên, lượng dữ liệu này là khổng lồ và không được sắp xếp theo bất kỳ cấu trúc nào.
Để phân tích lượng dữ liệu này, doanh nghiệp phải tập hợp tất cả dữ liệu của mình từ các silo khác nhau và tổng hợp tất cả dữ liệu đó ở một vị trí, gọi là data lake, để thực hiện phân tích và máy học (ML) trực tiếp trên đó. Ngoài ra, doanh nghiệp cũng sử dụng dịch vụ data warehouse để nhận kết quả nhanh chóng cho các truy vấn phức tạp về dữ liệu có cấu trúc hoặc dịch vụ tìm kiếm để nhanh chóng tìm kiếm và phân tích log data để theo dõi tình trạng của hệ thống sản xuất.
Mục lục
Cách tiếp cận Lakehouse
Là một kiến trúc dữ liệu hiện đại, phương pháp Lakehouse không chỉ là tích hợp mà còn là kết nối data lake, data warehouse và tất cả các dịch vụ được xây dựng có mục đích khác thành một tổng thể thống nhất.
Data lake là nơi duy nhất mà bạn có thể chạy phân tích trên hầu hết dữ liệu của mình trong khi các dịch vụ phân tích được xây dựng để cung cấp tốc độ bạn cần cho các trường hợp sử dụng cụ thể như real-time dashboards và log analytics.
Phương pháp tiếp cận Lakehouse này bao gồm các yếu tố chính sau:
- Data Lake có thể mở rộng
- Dịch vụ dữ liệu được xây dựng có mục đích
- Di chuyển dữ liệu liền mạch
- Quản trị thống nhất
- Năng lực và Tối ưu chi phí
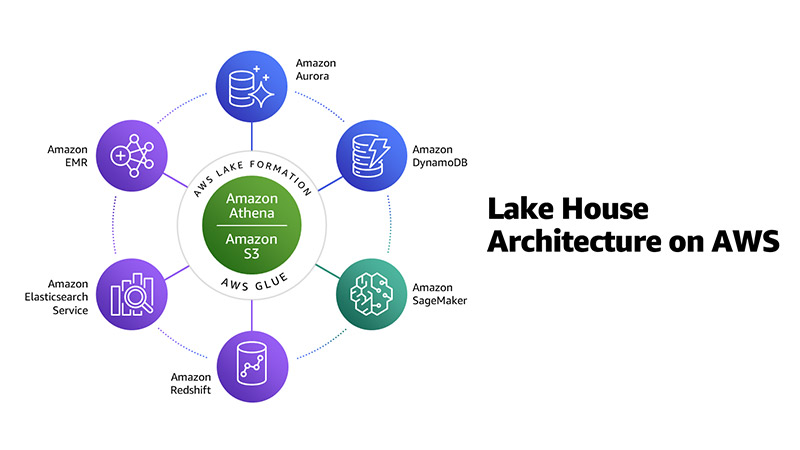
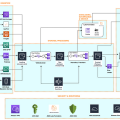
Sơ đồ sau minh họa phương pháp tiếp cận Lakehouse này về dữ liệu khách hàng trong thế giới thực và sự di chuyển dữ liệu cần thiết giữa tất cả các dịch vụ phân tích dữ liệu và data warehouse, từ trong ra ngoài, từ ngoài vào trong và xung quanh chu vi:

Kiến trúc phân tích dữ liệu phân layer và được thành phần hóa cho phép doanh nghiệp sử dụng công cụ phù hợp cho đúng công việc và cung cấp khả năng nhanh chóng để xây dựng kiến trúc theo từng bước.
Bạn có được sự linh hoạt để phát triển Lakehouse nhằm đáp ứng nhu cầu hiện tại và tương lai khi thêm các nguồn dữ liệu mới, khám phá các trường hợp sử dụng mới, đồng thời phát triển các phương pháp phân tích mới hơn.
Đối với Kiến trúc Lakehouse này, bạn có thể tổ chức nó như một mô hình năm layer hợp lý, trong đó mỗi layer bao gồm nhiều thành phần được xây dựng có mục đích giải quyết các yêu cầu cụ thể.

Trước khi đi sâu vào 5 layer, hãy nói về các nguồn cung cấp cho Kiến trúc Lakehouse.
1. Data Sources
Kiến trúc Lakehouse cho phép bạn nhập và phân tích dữ liệu từ nhiều nguồn khác nhau. Nhiều nguồn trong số này chẳng hạn như ứng dụng dòng doanh nghiệp (LOB), ứng dụng ERP và ứng dụng CRM tạo ra các lô dữ liệu có cấu trúc cao ở những khoảng thời gian cố định.
Ngoài các nguồn nội bộ, bạn có thể nhận dữ liệu từ các nguồn hiện đại như ứng dụng web, thiết bị di động, cảm biến, luồng video và phương tiện truyền thông xã hội. Các nguồn hiện đại này thường tạo ra dữ liệu bán cấu trúc và phi cấu trúc, thường là các luồng liên tục.
2. Data Ingestion Layer
Ingestion layer trong Kiến trúc Lakehouse chịu trách nhiệm nhập dữ liệu vào layer lưu trữ Lakehouse. Nó cung cấp khả năng kết nối với các nguồn dữ liệu bên trong và bên ngoài qua nhiều giao thức khác nhau. Nó có thể nhập và cung cấp dữ liệu phát trực tuyến hàng loạt cũng như thời gian thực vào data warehouse cũng như các thành phần data lake của layer lưu trữ Lakehouse.
3. Data Storage Layer
Data storage layer chịu trách nhiệm cung cấp các thành phần bền bỉ, có thể mở rộng và hiệu quả chi phí cao để lưu trữ và quản lý số lượng lớn dữ liệu. Trong Kiến trúc Lakehouse, data warehouse và data lake được tích hợp nguyên bản để cung cấp một layer lưu trữ tích hợp hiệu quả về chi phí hỗ trợ dữ liệu không có cấu trúc cũng như dữ liệu có cấu trúc và mô hình cao. layer lưu trữ có thể lưu trữ dữ liệu ở các trạng thái sẵn sàng khác nhau, bao gồm cả raw, trusted-conformed, enriched, và modeled.

3.1. Lưu trữ dữ liệu có cấu trúc trong data warehouse
Data warehouse lưu trữ dữ liệu phù hợp với có độ tin cậy cao, được cấu trúc thành star, snowflake, data vault, hoặc highly denormalized schemas. Dữ liệu được lưu trữ trong kho thường được lấy từ các nguồn bên trong và bên ngoài có cấu trúc cao như hệ thống giao dịch, cơ sở dữ liệu quan hệ và các nguồn hoạt động có cấu trúc khác, thường theo nhịp thông thường.
Các data warehouse cloud-native hiện đại thường có thể lưu trữ dữ liệu quy mô petabyte trong dung lượng lưu trữ hiệu suất cao được tích hợp sẵn ở định dạng cột, nén. Thông qua các công cụ MPP và lưu trữ đính kèm nhanh chóng, một data warehouse cloud-native hiện đại cung cấp khả năng quay vòng độ trễ thấp cho các truy vấn SQL phức tạp.
Để cung cấp dữ liệu được sắp xếp, tuân thủ cao và đáng tin cậy, trước khi lưu trữ dữ liệu trong kho, bạn cần đưa dữ liệu nguồn qua một lượng đáng kể preprocessing, validation, và transformation bằng cách sử dụng extract, transform, load (ETL) hoặc extract, load, transform pipelines (ELT). Tất cả các thay đổi đối với dữ liệu data warehouse và schema đều được quản lý và xác thực chặt chẽ để cung cấp dataset đáng tin cậy trên các business domains.

3.2. Lưu trữ dữ liệu có cấu trúc và không có cấu trúc trong Kiến trúc Lakehouse
Data Lake là data warehouse tập trung lưu trữ tất cả dữ liệu của tổ chức. Nó hỗ trợ lưu trữ dữ liệu ở các định dạng có cấu trúc, bán cấu trúc và phi cấu trúc. Nó cung cấp khả năng lưu trữ theo tầng được tối ưu hóa về chi phí và có thể tự động mở rộng quy mô để lưu trữ exabyte dữ liệu.
Thông thường, một data lake được phân đoạn thành các vùng landing, raw, trusted, và curated để lưu trữ dữ liệu tùy thuộc vào mức độ sẵn sàng của nó. Dữ liệu được nhập và lưu trữ như trong data lake (mà không cần phải xác định schema trước) để tăng tốc quá trình nhập và giảm thời gian cần thiết cho việc chuẩn bị trước khi dữ liệu có thể được khám phá.
Data lake cho phép phân tích các dataset đa dạng bằng cách sử dụng các phương pháp đa dạng, bao gồm cả xử lý dữ liệu lớn và ML. Tích hợp gốc giữa data lake và data warehouse cũng làm giảm chi phí lưu trữ bằng cách cho phép bạn tải một lượng lớn historical data từ kho lưu trữ.
4. Catalog Layer
Layer danh mục chịu trách nhiệm lưu trữ metadata kinh doanh và kỹ thuật về các tập dữ liệu được lưu trữ trong layer lưu trữ Lakehouse. Trong Kiến trúc Lakehouse, danh mục được chia sẻ bởi cả data lake và data storage, đồng thời cho phép viết các truy vấn kết hợp dữ liệu được lưu trữ trong data lake cũng như data warehouse trong cùng một SQL.
Nó cho phép bạn theo dõi các phiên bản schema và thông tin phân vùng chi tiết của các tập dữ liệu. Khi số lượng tập dữ liệu tăng lên, layer này cung cấp khả năng tìm kiếm giúp phát hiện các tập dữ liệu trong Lakehouse.
5. Lakehouse Interface
Trong Kiến trúc Lakehouse, data warehouse và data lake được tích hợp nguyên bản tại các layer lưu trữ cũng như các layer danh mục chung để đưa ra một giao diện Lakehouse thống nhất cho các layer xử lý và tiêu thụ.
Sau đó, các thành phần của layer xử lý và tiêu thụ Lakehouse có thể sử dụng tất cả dữ liệu được lưu trữ trong layer lưu trữ Lakehouse (được lưu trữ trong cả data warehouse và data lake) thông qua một giao diện Lakehouse thống nhất duy nhất như SQL hoặc Spark.
Bạn không cần phải di chuyển dữ liệu giữa data warehouse và data lake theo cả hai hướng để cho phép truy cập vào tất cả dữ liệu trong bộ lưu trữ Lakehouse.
Tích hợp gốc giữa data warehouse và data lake cung cấp cho bạn sự linh hoạt để thực hiện những việc sau:
- Lưu trữ exabyte dữ liệu có cấu trúc và không có cấu trúc trong bộ lưu trữ data lake hiệu quả về chi phí cao dưới dạng dữ liệu có cấu trúc được quản lý, mô hình hóa và phù hợp cao trong lưu trữ data warehouse nóng
- Tận dụng một khung xử lý đơn lẻ như Spark có thể kết hợp và phân tích tất cả dữ liệu trong một đường dẫn duy nhất, cho dù đó là dữ liệu phi cấu trúc trong data lake hay dữ liệu có cấu trúc trong data warehouse
- Xây dựng pipelines ETL hoặc ELT gốc của data warehouse dựa trên SQL có thể kết hợp dữ liệu flat relational trong kho với dữ liệu có cấu trúc phân cấp, phức tạp trong data lake

6. Data Processing Layer
Các thành phần trong lớp xử lý dữ liệu của Kiến trúc Lakehouse chịu trách nhiệm chuyển đổi dữ liệu sang trạng thái có thể tiêu thụ được thông qua xác thực, dọn dẹp, chuẩn hóa, chuyển đổi và làm giàu dữ liệu. Lớp xử lý cung cấp các thành phần được xây dựng theo mục đích để thực hiện nhiều loại chuyển đổi, bao gồm SQL kiểu data warehouse, xử lý dữ liệu lớn và near-real-time ETL.
Lớp xử lý cung cấp thời gian nhanh nhất để tiếp thị bằng cách cung cấp các thành phần được xây dựng theo mục đích phù hợp với các đặc điểm của tập dữ liệu phù hợp (kích thước, định dạng, schema, tốc độ), tác vụ xử lý trong tầm tay và các tập kỹ năng có sẵn (SQL, Spark).
Lớp xử lý có thể mở rộng quy mô hiệu quả về chi phí để xử lý khối lượng dữ liệu lớn và cung cấp các thành phần để hỗ trợ schema-on-write, schema-on-read, dataset được phân vùng và các định dạng dữ liệu đa dạng. Lớp xử lý có thể truy cập các giao diện lưu trữ thống nhất của Lakehouse và danh mục chung, do đó truy cập tất cả dữ liệu và metadata trong Lakehouse. Điều này có những lợi ích sau:
- Tránh dư thừa dữ liệu, di chuyển dữ liệu không cần thiết và trùng lặp mã ETL có thể xảy ra khi xử lý riêng một data lake và data warehouse
- Giảm thời gian ra thị trường
7. Data Consumption Layer
Lớp tiêu thụ dữ liệu (hay còn gọi là Data Consumption Layer) của Kiến trúc Lakehouse chịu trách nhiệm cung cấp các thành phần có thể mở rộng và hiệu suất sử dụng giao diện Lakehouse thống nhất để truy cập vào tất cả dữ liệu được lưu trữ trong bộ lưu trữ Lakehouse và tất cả metadata được lưu trữ trong danh mục Lakehouse.
Nó cung cấp các thành phần được xây dựng nhằm kích hoạt các phương pháp phân tích, bao gồm các truy vấn SQL tương tác, phân tích kiểu kho, bảng điều khiển BI và ML, cho phép dân chủ hóa phân tích và đảm báo các cá nhân trong một tổ chức đều tiếp cận được.
Các thành phần trong consumption layer hỗ trợ những điều sau:
- Viết truy vấn cũng như phân tích và ML giúp truy cập và kết hợp dữ liệu từ các schema chiều của data warehouse truyền thống cũng như các bảng được lưu trữ trong data lake (yêu cầu schema-on-read)
- Xử lý các tập dữ liệu được lưu trữ trong data lake được lưu trữ bằng nhiều định dạng tệp mở như Avro, Parquet hoặc ORC
- Tối ưu hóa hiệu suất và chi phí thông qua việc cắt bớt phân vùng khi đọc các tập dữ liệu lớn, được phân vùng được lưu trữ trong data lake
Tiếp theo
Vừa rồi là cách tiếp cận đầu tiên tới kiến trúc Lakehouse, để tiếp tục chuỗi chủ đề này, trong các phần tiếp theo, chúng tôi sẽ đi sâu vào kiến trúc tham chiếu sử dụng các dịch vụ AWS để tạo từng layer được mô tả trong kiến trúc logic Lakehouse. Đọc thêm tại đây.
Bài viết liên quan:
 11 bước để Triển khai kho dữ liệu
11 bước để Triển khai kho dữ liệu
 Data warehouse là gì? Những lợi ích của kho dữ liệu
Data warehouse là gì? Những lợi ích của kho dữ liệu
 Data Lake là gì? Lợi ích của Data Lake là gì?
Data Lake là gì? Lợi ích của Data Lake là gì?
 Mô hình quan hệ dữ liệu – DBMS Relational Data Model
Mô hình quan hệ dữ liệu – DBMS Relational Data Model
 Kiến trúc Lakehouse trên AWS (Phần 2)
Kiến trúc Lakehouse trên AWS (Phần 2)
 Top 27 thuật ngữ quan trọng về kho dữ liệu cho dân data
Top 27 thuật ngữ quan trọng về kho dữ liệu cho dân data
Powered by YARPP.